데이콘 입문에 도전해보았다
내가 알고 있는것과 아는 것을 활용하는 것은 상당히 다르다는 것을 아주 확실히 깨달았다 ㅎㅋ
코드내용을 정리하며 다른 유저분들이 올려주신 코드 공유본도 참고하여 부족한 부분을 깨달았다
다음엔 더 잘해봐야겠다
쇼핑몰 지점별 매출액 예측
데이터 불러오기
import pandas as pd
train = pd.read_csv('/content/drive/MyDrive/데이콘/Data/train.csv')
test =pd.read_csv('/content/drive/MyDrive/데이콘/Data/test.csv')
sample_submission = pd.read_csv('/content/drive/MyDrive/데이콘/Data/sample_submission.csv')데이터 전처리
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
train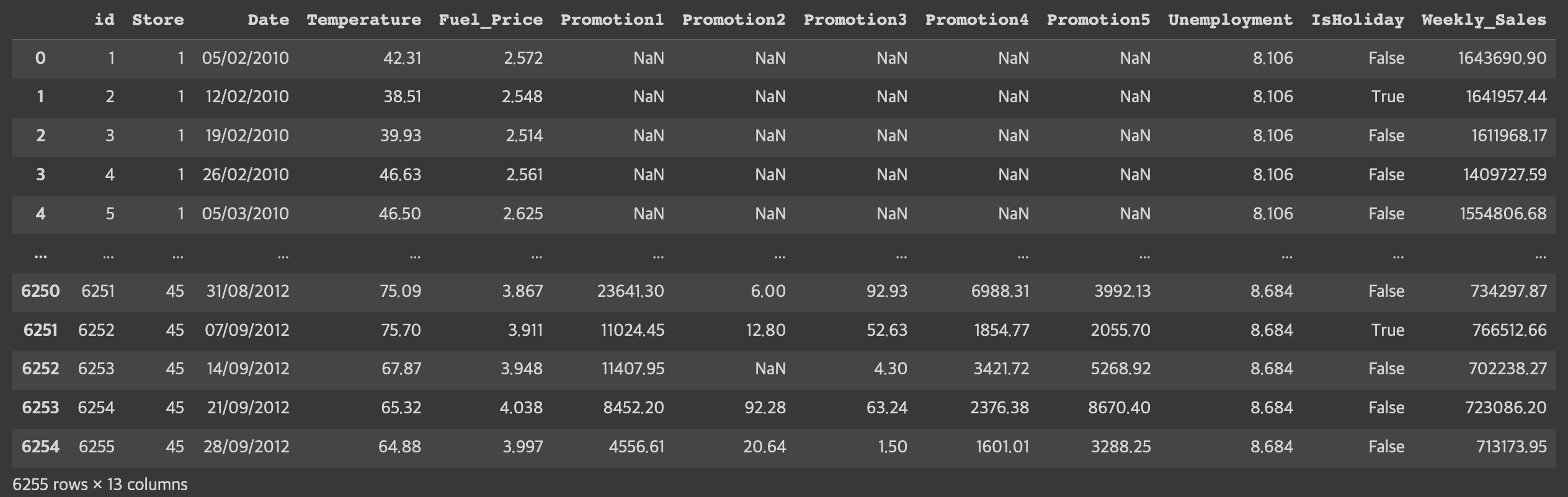
train 데이터를 보았을때 Promotion 컬럼들은 꽤 많은 널값을 가지고 있는것을 확인할 수 있다
train.info()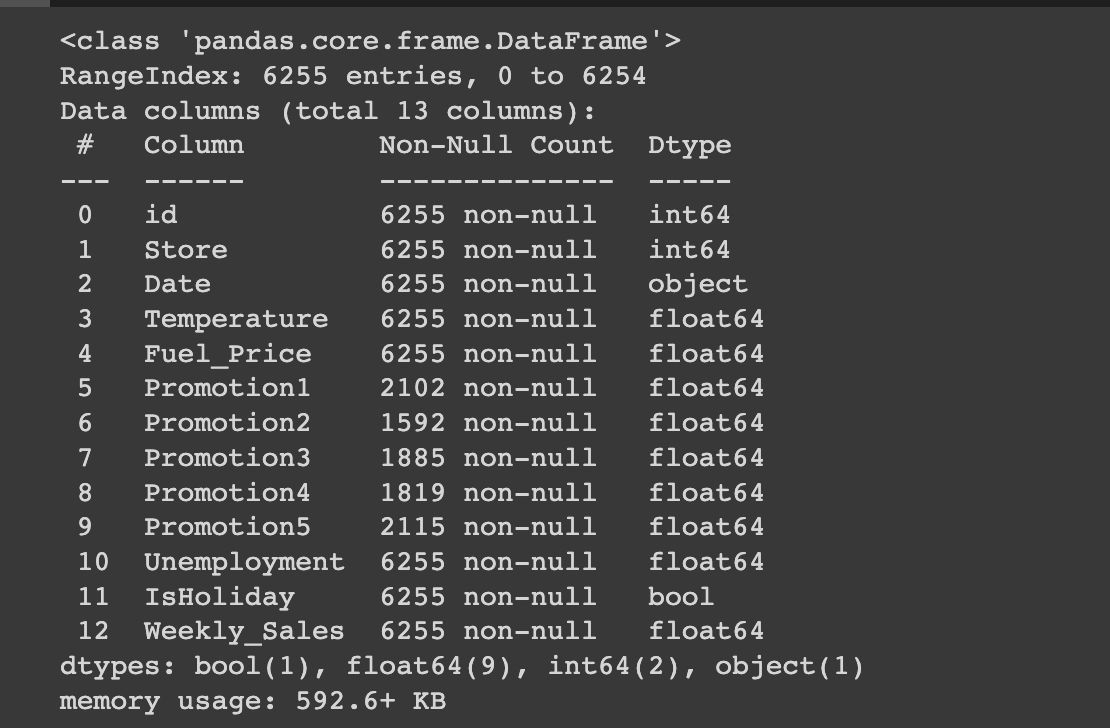
train 데이터를 보았을 때 전체 데이터는 6255, 이고
Promotion1,2,3,4,5 에 널값이 여러게 존재하는 것을 확인하였다.
Is Holiday-> 보기 편하게 T/F대신 1/0으로 변환한다
train.loc[train['IsHoliday']==True,'IsHoliday'] = 1
train.loc[train['IsHoliday']==False,'IsHoliday']=0
train = train.astype({'IsHoliday':'Int64'})날짜 컬럼을 그룹으로 묶어 넣어주었다
Train = [df]
for dataset in Train:
dataset.loc[ dataset['Temperature'] <=20.0, 'Temperature_']=1
dataset.loc[(dataset['Temperature'] > 20.0) & (dataset['Temperature'] <=30.0), 'Temperature_'] = 2
dataset.loc[(dataset['Temperature'] > 30.0) & (dataset['Temperature'] <=40.0), 'Temperature_'] = 3
dataset.loc[(dataset['Temperature'] > 40.0) & (dataset['Temperature'] <=50.0), 'Temperature_'] = 4
dataset.loc[(dataset['Temperature'] > 50.0) & (dataset['Temperature'] <=60.0), 'Temperature_'] = 5
dataset.loc[(dataset['Temperature'] > 60.0) & (dataset['Temperature'] <=70.0), 'Temperature_'] = 6
dataset.loc[(dataset['Temperature'] > 70.0) & (dataset['Temperature'] <=80.0), 'Temperature_'] = 7
dataset.loc[(dataset['Temperature'] > 80.0) & (dataset['Temperature'] <=90.0), 'Temperature_'] = 8
dataset.loc[(dataset['Temperature'] > 90.0), 'Temperature_'] = 9Date 값을 데이터 형식에 맞게 변환하여 준다
날짜 데이터를 '%d%/%m/%Y'를 적용해주어 데이터 포맷을 바꾸어 주고 그 후에 년/월/일로 나누어 각각 컬럼에 저장해주었다
train['Date'] = pd.to_datetime(train['Date'],format='%d/%m/%Y')
import datetime as dt
train['Year'] = train['Date'].dt.year
train['Month'] = train['Date'].dt.month
train['Day'] = train['Date'].dt.day
# test도 동일하게 전처리 진행
test.loc[test['IsHoliday']==True,'IsHoliday']=1
test.loc[test['IsHoliday']==False,'IsHoliday']=0
test['Date'] = pd.to_datetime(test['Date'],format='%d/%m/%Y')
test['Year'] = test['Date'].dt.year
test['Month'] = test['Date'].dt.month
test['Day'] = test['Date'].dt.day
test = test.astype({'IsHoliday':'int64'})각 매장별로 지점별 Weekly Sales 에 대한 추세 그래프를 그렸다
from matplotlib import dates
fig = plt.figure(figsize=(35,35))
fig.set_facecolor('white')
for i in range(1,45):
train2=df[df.Store==i]
train2=train2[['Date','Weekly_Sales']]
ax=fig.add_subplot(8,8,i) ##그림 프레임 생성
plt.title('store_{}'.format(i))
plt.ylabel('Weekly_Sales')
plt.xticks(rotation=15)
ax.xaxis.set_major_locator(dates.MonthLocator(interval=2))
ax.plot(train2['Date'],train2['Weekly_Sales'],marker='',label='train',color='blue')
plt.show()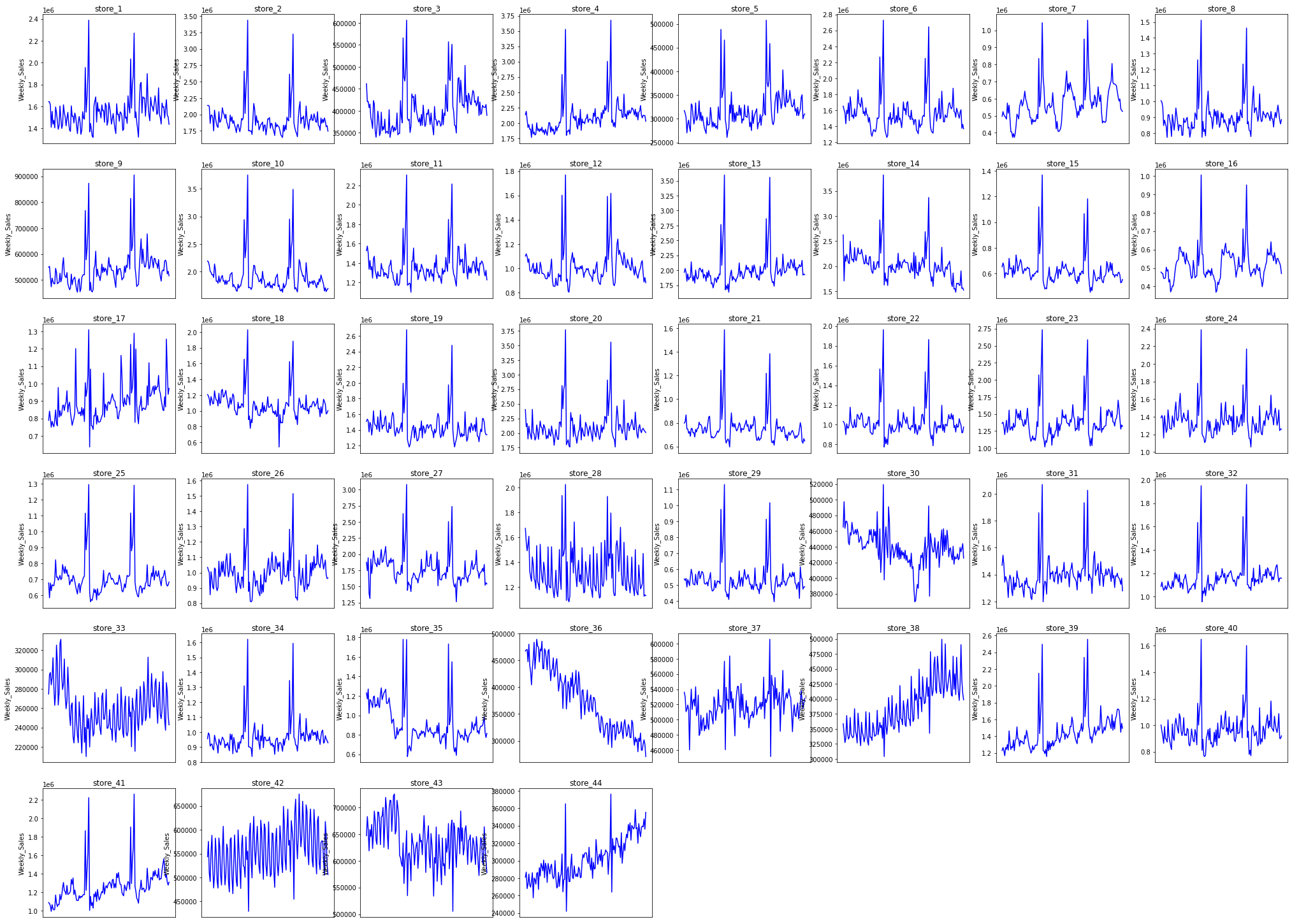
그래프를 돌렸을 때, 28,30,33,36,37,38,42,44 지점은 다른지점들과 추세가 일치하지 않음을 확인할 수 있다
다른 분들은 여기서 추세가 다른 지점별로 모델을 다르게해서 돌리더라구요.. 거기까지 생각못한 나 자신
그 다음 지점들과 컬럼들과의 상관관계를 확인해주었다
corr = []
for num in range(1,46):
co = train[train.Store==num]
co = co.reset_index()
num_corr = co.corr()['Weekly_Sales']
num_corr = num_corr.drop(['index', 'id','Store','Weekly_Sales'])
corr.append(num_corr)
corr_train= pd.concat(corr, axis=1).T
corr_train.index = list(range(1,46))
f, ax = plt.subplots(figsize=(20,8))
plt.title("지점별 매출액과 변수들간의 상관관계", fontsize=15)
sns.heatmap(corr_df.T, cmap=sns.diverging_palette(240,10,as_cmap=True), ax=ax)
plt.xlabel('지점(Store)')
plt.show()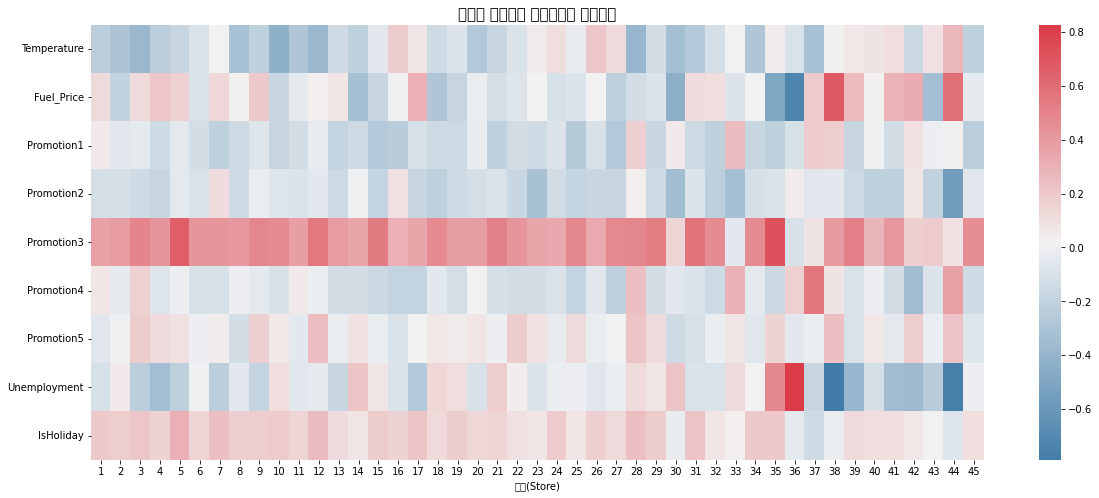
train[train.Store==1].loc[70:100]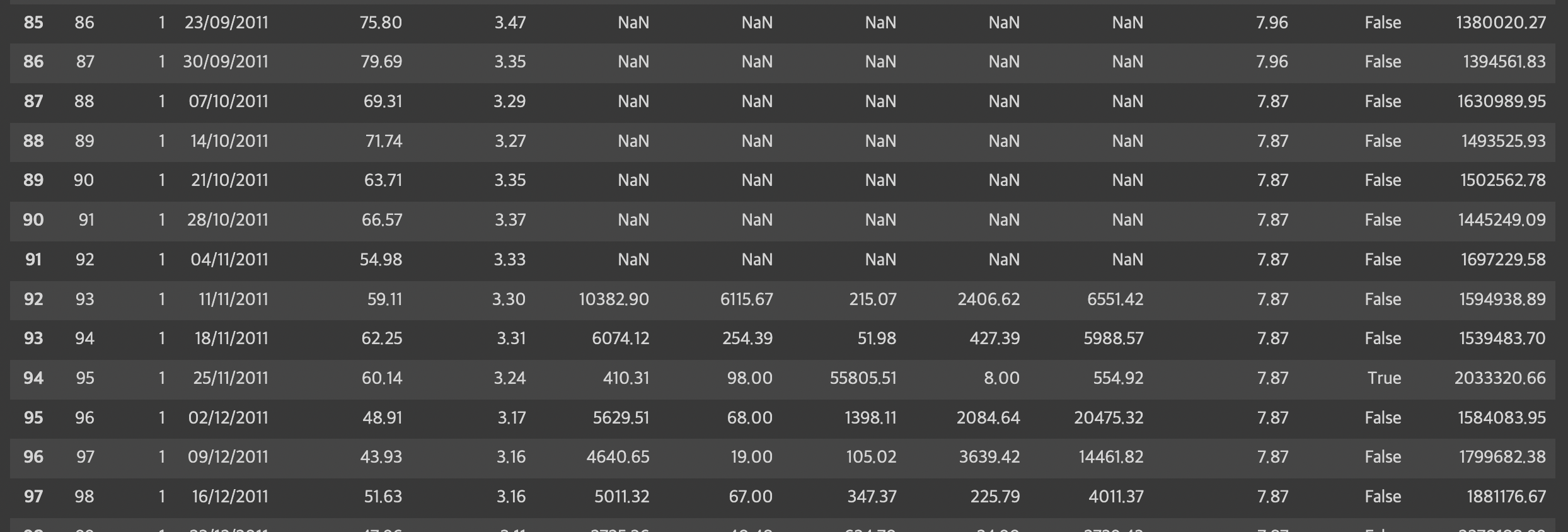
train[train.Store==2].loc[220:]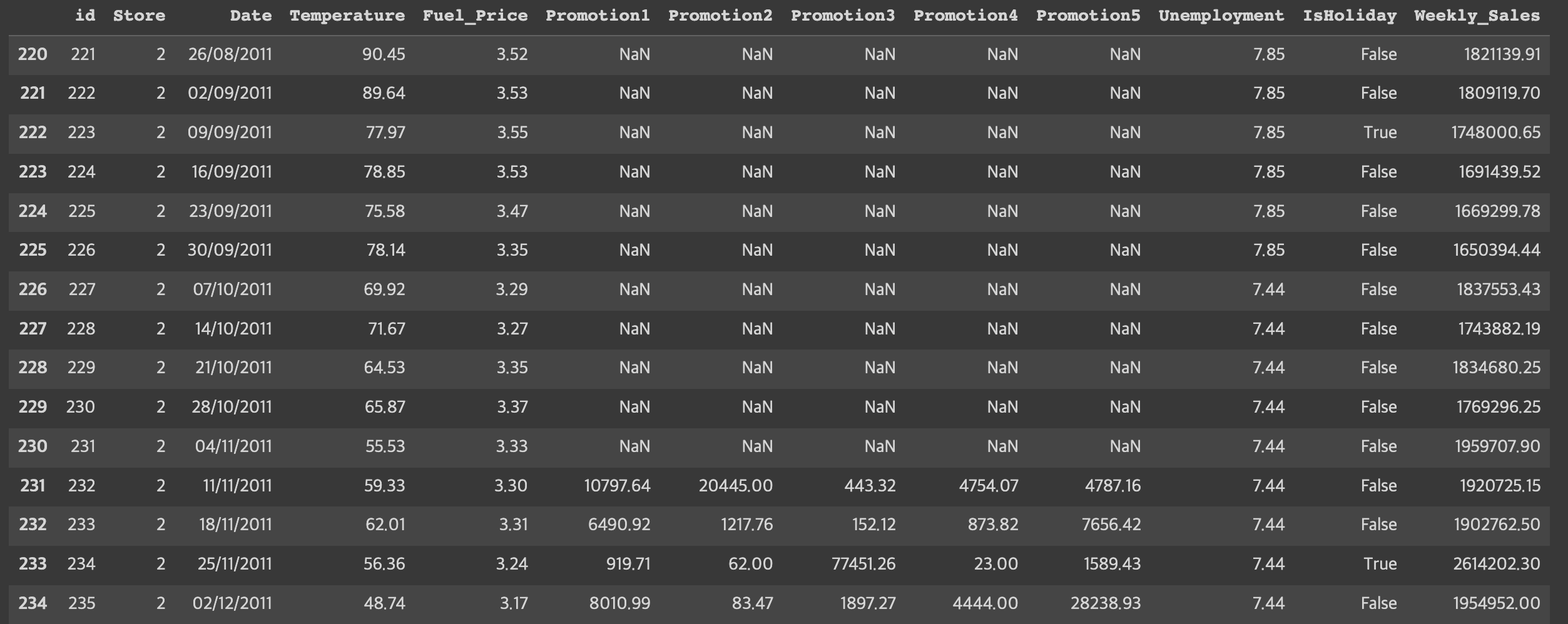
데이터를 살펴 보았을때, Promorion 변수들에 null 값은 전부 2011/11/11 이전이라는 것을 알 수 있고 2011/11/11 이전 데이터 값들이 NaN 임을 확인하여 볼 수 있다. 즉 Promotion 이라는 개념은 이 날짜 이후에 생긴 것 같다
따라서 11월 11일 이전 Promotion은 0으로 대체,나머지는 선형보간법을 이용하여 대치해주었다
for i in range(1,46):
train.loc[:91+(139*(i-1)),nan]=0 #각 지점에 대해 11월 11일 이전의 프로모션은 0으로 바꿈
test.loc[:91+(139*(i-1)),nan]=0
#나머지 결측치는 선형보간법을 활용하여 대치
train=train.interpolate(method='values')
test=test.interpolate(method='values')
- 테스트 데이터를 살펴보면 2012년 10월을 예측하는 것임을 알 수 있음
- 11월과 12월은 크리스마스, 블랙프라이데이 등 연말 행사가 영향을 많이 끼치므로 10월까지의 데이터만 가지고 예측 시도
train = train [train['Month']<=10]
test = test [test['Month']<=10]타겟변수 로그 변환 후 필요없는 변수 제거
train['Weekly_Sales'] = np.log1p(train['Weekly_Sales'])
train.drop(['id', 'Date','Temperature','Fuel_Price','Promotion1','Promotion2','Unemployment','Promotion4','Promotion5','IsHoliday'], axis = 1, inplace = True)
test.drop(['id', 'Date','Temperature','Fuel_Price','Promotion1','Promotion2','Unemployment','Promotion4','Promotion5','IsHoliday'], axis = 1, inplace = True)모델링
x_train = train.drop(columns='Weekly_Sales', axis=1)
y_train = train['Weekly_Sales']
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(random_state = 42, n_estimators = 200)
rf.fit(x_train, y_train)
pred = np.expm1(rf.predict(test))아쉬운점
이번에 처음으로 데이콘을 해보며 많은 것을 느꼈다.
첫번째로 아직 더 많이 데이터 분석을 시도해봐야할 것 같고
원 핫 인코딩을 많은 분들이 하시는거 같길래 나도 Store 변수에 대하여 원-핫 인코딩 전처리를 시도해보았는데 내가 시도했던 코드로는 모델의 성능향상은 별로 없었다 . 그리고 추세가 다르면 -> 다른 모델 적용 이것도 기억하고 나중에 꼭 시도해볼것..
RandomForest 말고 다양한 모델을 사용하며 결과를 비교했어야했는데 늦게 시작한 탓에 시간이 부족하여 다른 모델을 적용하지 못했다. CatBoost 등 더 다양한 모델 사용을 시도하여 결과를 확인해봐야겠다 !
