데이터공부
1.[데이콘]Summer - Basic 쇼핑몰 지점별 매출액 예측
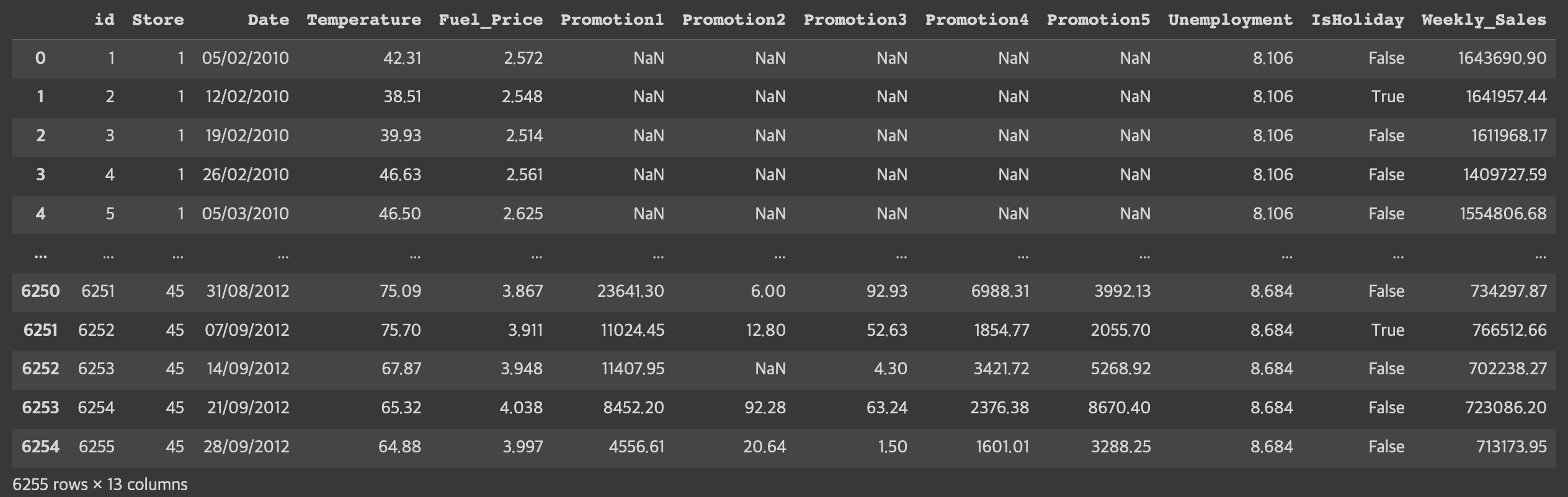
데이콘 입문에 도전해보았다내가 알고 있는것과 아는 것을 활용하는 것은 상당히 다르다는 것을 아주 확실히 깨달았다 ㅎㅋ코드내용을 정리하며 다른 유저분들이 올려주신 코드 공유본도 참고하여 부족한 부분을 깨달았다다음엔 더 잘해봐야겠다train 데이터를 보았을때 Promoti
2.클러스터링 평가지표 - 실루엣 계수(Silhouette Coefficient)

클러스터링을 평가할때 얼마나 군집화가 잘되었는지 평가하는 일반적인 지표 중 하나로 실루엣 계수가 있다. 실루엣 계수란 하나의 군집들안에서 데이터들이 얼마나 잘 모여있는지, 각 다른 군집들에선 군집들이 얼마나 잘 분리되어있는지 평가하는 지표이다.
3.[Numpy] 넘파이 기본 문법 정리
파이썬에 리스트, 튜플 , 딕셔너리와 같은 기본 데이터 타입이 있는 것처럼 넘파이에는 다차원 배열을 위한 ndarray 클래스를 제공1차원 리스트를 넘파이의 array 함수에 전달하면 쉽게 ndarray 객체로 변환 가능1차원 리스트를 넘파이의 array 함수에 전달하
4.[금융 데이터 분석] 코스피 데이터 수익률 계산
주가 지수는 상장된 종목들의 평균적인 움직임을 의미, 지수에 투자했을때의 수익률은 지수수익률 혹은 시장수익률이라고 정의하며 이는 최소한의 기대치로 다른 알고리즘과의 수익률을 비교하는 벤치마크로 사용→ 투자 결과 10%의 이익을 얻었더라도 시장 수익률이 20%이면 기대에
5.[Pandas] 시리즈(Series) 기본 문법 정리
판다스의 시리즈는 일차원 데이터를 관리하는 자료구조로, 데이터와 함께 인덱스를 사용하여 데이터에 레이블을 달아둘 수 있다. 리스트와 튜플의 장점을 섞어 놓은 것과 같이 동작한다.0 101 202 30dtype: int64→ 파이썬 리스트를 활용하여 시리
6.[SQL] SQL 기본 문법 정리
WHERE 절을 사용하여 특정 조건에 해당하는 데이터만 조회할 수 있음관계 연산자 / 논리 연산자 가능함🟧 AND 와 OR여러 조건이 필요한 경우에는 논리 연산자 사용MySQL은 &&나 ||도 가능함🟧 BETWEEN - 범위 표현식특정 범위에 해당하는 데이터를 조
7.[Mac OS] PostgreSQL 설치 및 접속 + DBeaver 와 연결하기

다운로드 사이트에 들어가서 OS 환경에 맞는 버전으로 다운로드 해주었다.하지만 Mac OS 는 homebrew 를 통해 많이 설치하는 것 같다설치 환경 : macOSPostgreSQL 설치 페이지위 링크를 타고 들어가서 버튼 쭉쭉 누르고 설치하면 완료!사용자 확인pos
8.하둡(Hadoop)이란?

하나의 성능 좋은 컴퓨터를 이용하여 데이터를 처리하는 대신 적당한 성능의 컴퓨터 여러 대를 클러스터화하고 큰 크기의 데이터를 클러스터에서 병렬로 동시에 처리하여 처리 속도를 높이는 것을 목적으로 하는 분산처리를 위한 오픈소스 프레임워크하둡 소프트웨어 라이브러리는 간단한
9.[Kaggle] 자전거 수요 예측
Datetime : 시간(YYYY-MM-DD 00:00:00)Season : 봄(1), 여름(2), 가을(3), 겨울(4)Holiday : 공휴일(1),그외 (0)Workingday : 근무일(1), 그외(0)Weather : 아주 깨끗한 날씨(1), 안개와구름(2)