🟨 워드 임베딩 (Word Embedding)
- 텍스트를 컴퓨터가 이해하고, 효율적으로 처리하기 위해서는 컴퓨터가 이해할 수 있도록 적절히 숫자로 변환해야 한다. 따라서 각 단어를 인공 신경망 학습을 통해 벡터화하는 워드 임베딩 방법이 많이 사용되고 있다.
워드 임베딩(Word Embedding)은 단어를 벡터로 표현하는 방법으로, 단어를 밀집 표현으로 변환한다.
⇒ 단어의 벡터화 방식은 희소표현 (Sparse Representation) 과 밀집표현 (Dense Representation) 이 있다. One-Hot Encoding 으로 대표되는 희소표현 방식을 사용할 시 단어 수 증가에 따라 벡터 차원이 무한정 커지는 공간 낭비를 해결하기 위해 Word Embedding 으로 대표되는 Dense Representation 방식을 사용한다.
🟠 다시 말해, 워드 임베딩이란
단어간 유사도 및 중요도 파악을 위해 단어를 저차원의 실수 벡터로 맵핑하여 의미적으로 비슷한 단어를 가깝게 배치하는 자연어 처리 모델링 기술
🔶 횟수 기반 임베딩(Frequency Based Embedding)
BOW(Bag Of Words)
- 단어의 출연 빈도만으로 단어 사전 생성
- 각 단어 인덱싱 기반 사전으로 만들어 자동 분류
Count Vector
- 모든 문서의 단어 학습 후 문서마다 단어 횟수를 파악
- 각 문서 별 고유 토큰 수 기반 행렬로 표현
🔸 TF - IDF (단어 빈도 - 역 문서 빈도 ,Term Frequency Inverse Document Frequency)
핵심어 추출을 위해 단어의 특정 문서 내 중요도 산출- TF: 단어의 문서내 빈도
- IDF : 문서 빈도 수(DF 의 역수)
문서를 d, 단어를 t, 문서의 총 개수를 n이라고 표현할 때 ,
(1) tf(d,t) : 특정 문서 d 에서 특정 단어 t의 등장 횟수
(2) df(t) : 특정 단어 t 가 등장한 문서의 수
(3) idf(d,t) : df(t) 에 반비례하는 수
⇒ TF - IDF 는 모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단하며, 특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단한다. TF - IDF 값이 낮으면 중요도가 낮은 것이며, TF - IDF 값이 크면 중요도가 크다. 따라서 the 나 a 와 같은 불용어는 모든 문서에서 자주 등장하기 때문에 다른 단어에 비해 TF - IDF의 값이 낮아진다.
◽️ TF - IDF 파이썬으로 구현
N = len(docs)
def tf(t,d):
return d.count(t)
def idf(t):
df = 0
for doc in docs:
df += t in doc
return log(N/(df+1))
def tfidf(t,d):
return tf(t,d) * idf(t)◽️ 사이킷런을 이용한 DTM 과 TF - IDF 실습
from sklearn.featrue_extraction.text import TfidfVectorizer
corpus = [
'you know I want your love',
'I like you',
'what should I do',
]
tfidfv = TfidfVectorizer().fit(corpus)
print(tfidfv.transform(corpus).toarray())
print(tfidfv.vocabulary_)
🔶 추론 기반 임베딩 (Prediction Based Embedding)
Context (문맥)
: 컨텍스트란, CBOW 와 Skip - Gram 모델에서 사용하는 용어로 “ 계산이 이루어지는 단어들 “ 을 뜻함.
구둣점으로 구분되어지는 문장(sentence) 을 의미하는 것이 아니라, 특정 단어 주변에 오는 단어들의 집합을 뜻함
ex) “the cat sits on the” 라는 문장이 있을 경우 , 해당 컨텍스트에서 기준이 되는 단어(target word)를 ‘sits’로 정하고 sits 에 가까운 문맥 단어(context word)를 ‘on the’ 라고 한다면 이 단어를 모두 합친 5개의 단어가 Context가 된다. (Window Size 를 2로 설정하여 목표 단어 양쪽에 2개의 단어만 허용한 경우)
🔸 Word2Vec
: Word2Vec 신경망 연산
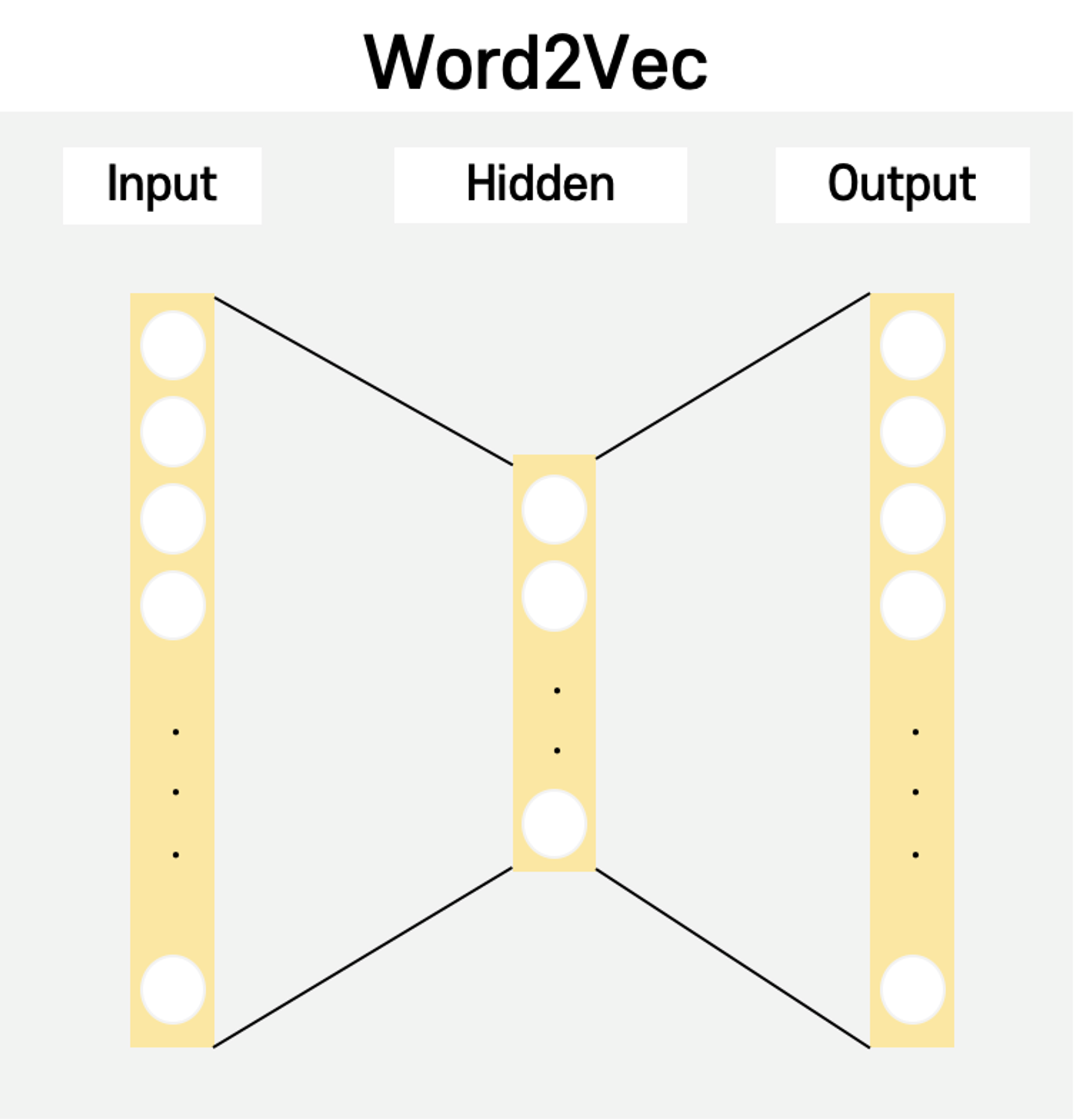
- 단어를 벡터 평면에 배치하여 문맥적 의미 보존하는 워드 임베딩 기법
- 신경망 연산 수행하며 CBOW 와 Skip-gram 모델 적용
🔸 Word2Vec 학습 모델
🔸 CBOW (Continous Bag Of Word)
: 주변 단어를 통해 주어진 단어를 예측 ( 총 단어가 c개라고 할 때 앞뒤로 c/2 개의 단어를 통해 주어진 단어를 예측)
🤔 문맥 단어 → 기준 단어를 예측

- 주변 단어 기반 해당 위치에 나타날 수 있는 단어
- 컨텍스트에서 단어의 평균을 적용하여 Softmax 계산
- 크기가 작은 데이터 셋에 적합

→ ‘I’ 는 ‘like playing’ 에 의해 업데이트 , ‘like’ 는 ‘I’,’playing football’ 에 의해 업데이트.. 된다 (문장의 각 단어는 한 번의 업데이트 기회만 주어진다)
🔸 Skip - gram
🤔 기준 단어 → 문맥 단어를 예측
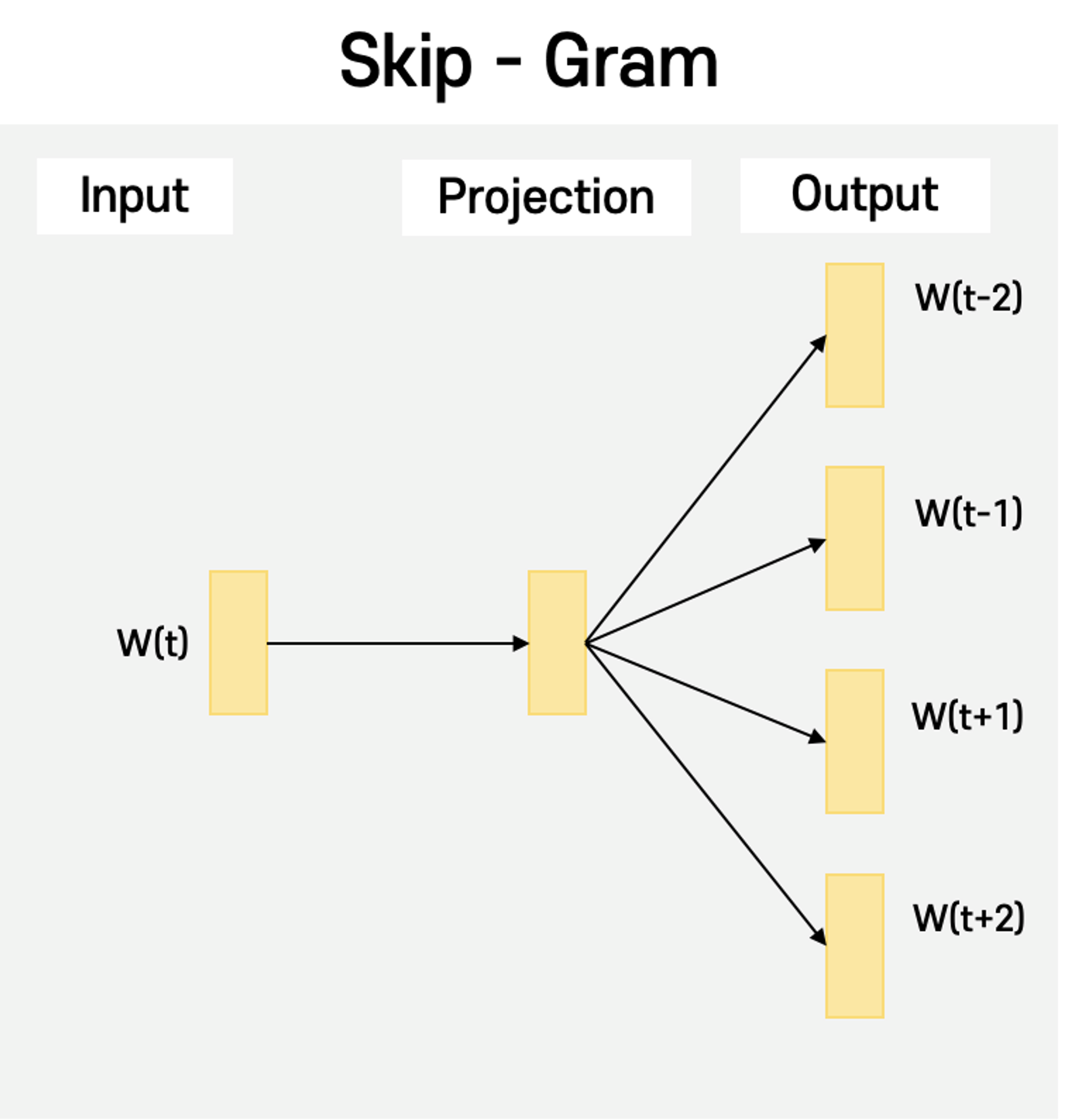
- 입력 단어를 통해 주변에 나타날 수 있는 단어를 추론
- 컨텍스트에서 단어를 1:1로 대응하어 Softmax 계산
- 크기가 큰 데이터 셋에 적합

→ 기준 단어를 입력으로 사용하여 기준 단어에 대해 앞뒤로 N/2개씩 , 총 N개의 문맥단어를 맞추기 위한 네트워크를 생성한다. 문장의 각 단어는 컨텍스트에 따라 여러번의 업데이트 기회가 주어진다.
⬜️ TF-IDF 와 Word2Vec 의 기법 비교
| 비교 항목 | TF-IDF | Word2Vec |
|---|---|---|
| 임베딩 원리 | 횟수(Frequency) 기반 | 추론(Prediction) 기반 |
| 임베딩 방식 | TDM(Term-Document Matrix) 내 중요도 산출 | 단어를 벡터 평면에 배치 및 결과 추론 |
| 연산 대상 | 문서 내 단어 등장 횟수 연산 | 단어 벡터 간 연산 |
| 적용 모델 | TF, DF, IDF, TF x IDF | CBOW, Skip-gram |
| 활용 방안 | 검색 순위, 핵심 단어 추출 | 자연어 문장 생성 |
참조
[DL] Word2Vec, CBOW, Skip-Gram, Negative Sampling
http://blog.skby.net/%EC%9B%8C%EB%93%9C-%EC%9E%84%EB%B2%A0%EB%94%A9word-embedding/
