Introduction
먼저 해당 lecture에서는 5가지의 질문을 던지면서 시작합니다.
- Which transfer learning methods work best, and what happens when we scale them up?
어떠한 전이학습 방법이 제일 좋고, 크기를 키우면 어떻게 작용할것인가?
- What about non-English pre-trained models?
영어가 아닌 언어로 사전학습하는것은 어떤가?
- How much knowledge does the model learn during pre-training?
Model이 사전학습을 하면서 얼만큼의 정보를 학습할 수 있는가?
- Does the model memorize data during pre-traing?
Model이 사전학습을 하면서 얼만큼의 data를 기억할 수 있는가?
- Which Transformer modifications work best?
Tranformer를 수정한 model 중 어떤것이 성능이 제일 좋은가?
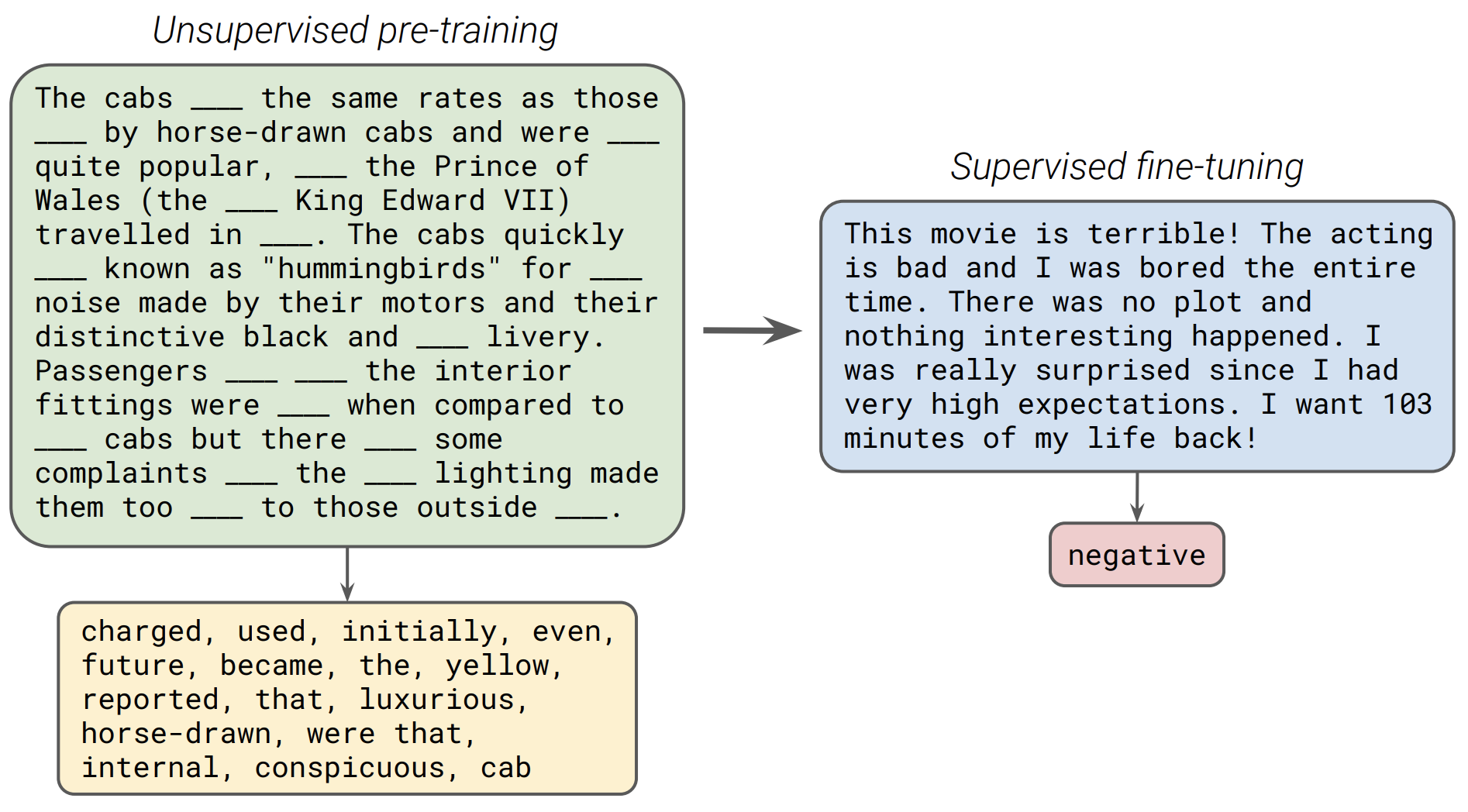
앞선 lecture에 대한 간단한 복습입니다. 자연어처리에서의 transfer-learning이란, unsupervised objective을 통해 pretrain을 진행합니다. 위의 그림을 보시다시피, 특정 단어를 masking 처리를 하여 어떠한 단어가 들어갈것인지를 objective function으로 설정하여 pretrain을 진행하고 downstream supervised task에 맞게 fine-tuning을 진행합니다.
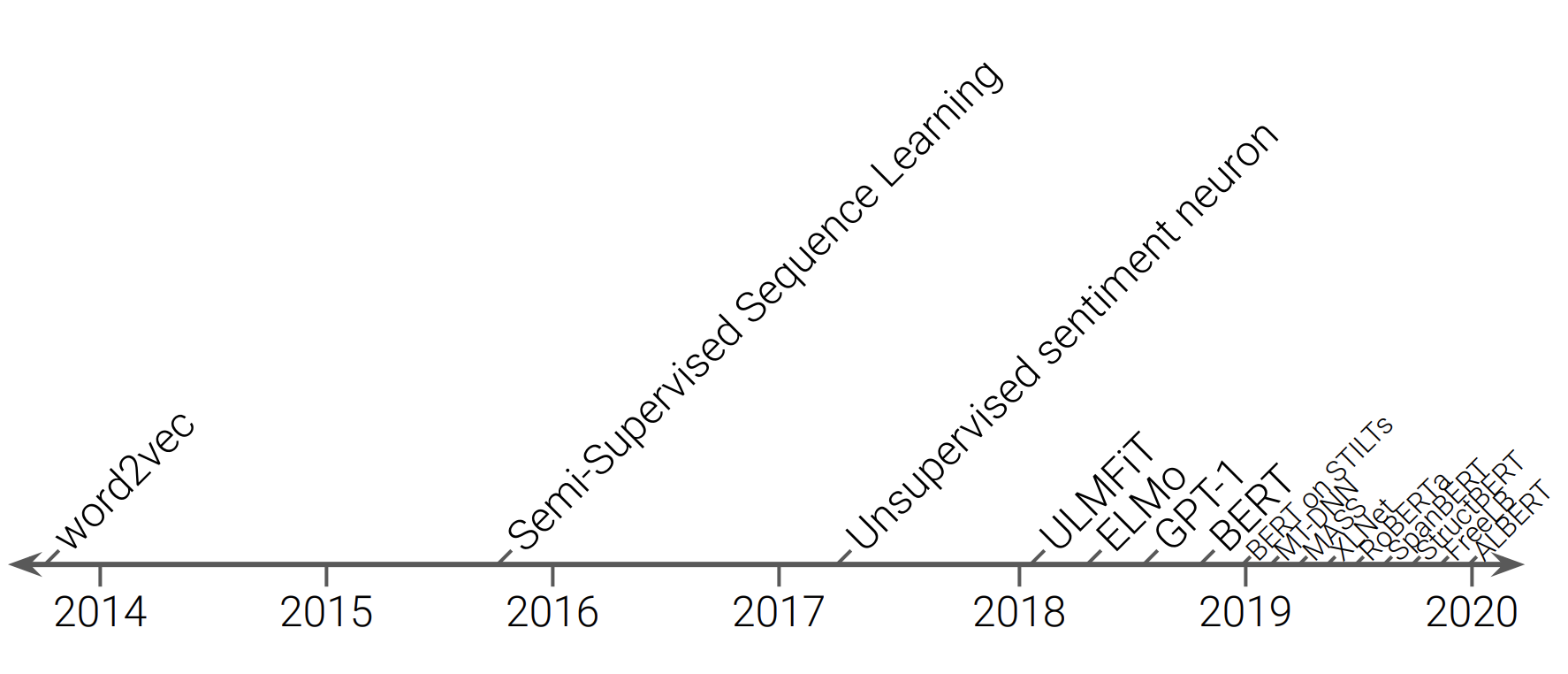
위의 그림에서 보시다시피 2018년 이후로는 수많은 language model이 쏟아져 나오고 있습니다. 그 중 몇가지 model에 대해 간략하게 설명하겠습니다.
ELMO
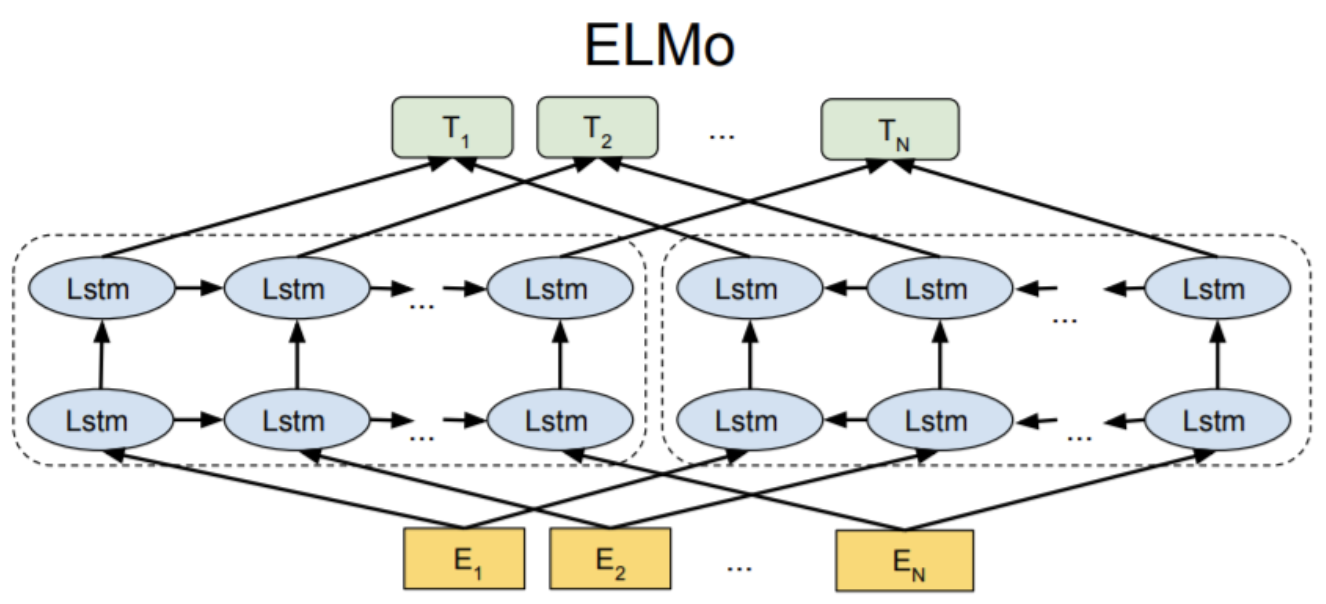
먼저 ELMO(Embedding from Language Models)에 대해 알아보겠습니다. ELMO가 발표되기 전 당시, GloVe, FastText, Word2Vec,등 word embedding 방법들은 주변 context words를 학습할 때만 고려할 뿐, 다른 model에 input으로 사용할 때는 고려하지 않았습니다. 예를 들어, word embedding을 통해 '사랑'이라는 단어에 대해 하나의 vector를 mapping되고 학습이 잘되었다면 vector가 문맥에 맞는 다양한 의미를 가지고 있을것입니다. '사랑'이라는 의미는 주변 단어의 문맥에 대해 변할 수 있고 문맥에 맞지 않는 의미는 불필요하게 됩니다. 그러나 기존 방법으로는 하나의 vector로space에 mapping되기 때문에 어느 의미를 내포하는지 알 수 없습니다.
ELMO는 word embedding을 사용할 때, vector가 주변 단어와 맞는, 문맥 정보에 따라 변할 수 있도록 할 수 있게 해서 Contextualized Word Embedding이라는 표현을 쓰게 됩니다.
GPT
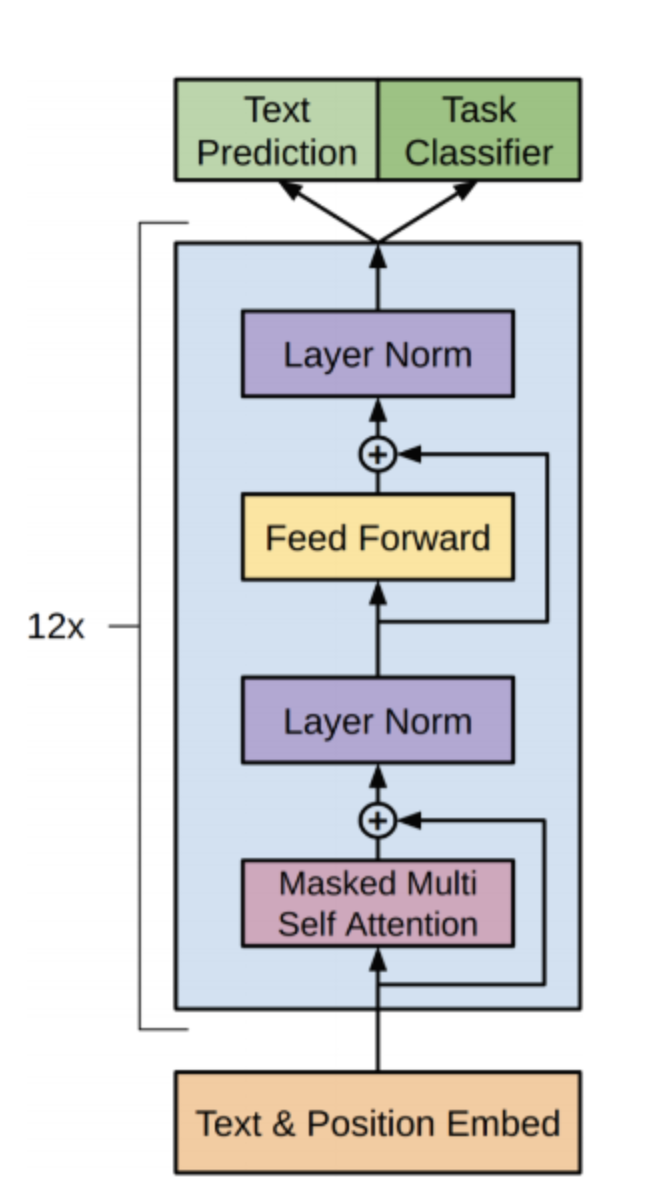
다음은 Open-AI에서 발표한 GPT(Generative Pre-Training)입니다. 현재 GPT2, GPT3까지 size가 커진 model이 발표가 되었습니다. GPT는 unlabeled corpus를 pre-train하고 각 task에 맞게 fine-tuning을 하는 language model입니다. GPT의 특징으로는 transformer의 decoder 구조만을 가지고 있어 auto-regressive하다는 점입니다.
BERT
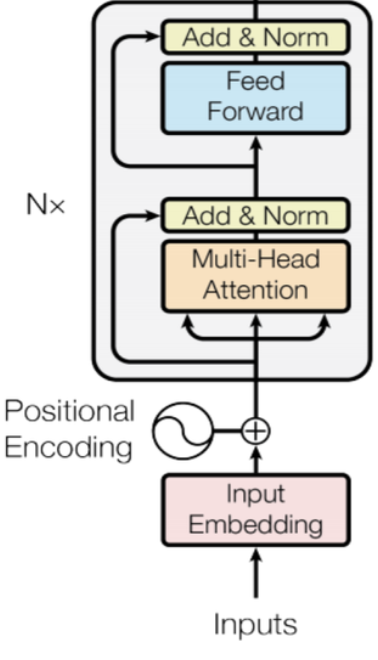
다음은 google에서 발표한 BERT(Bidirectional Encoder Representations from Transformers)입니다. BERT는 GPT와 같이 다량의 unlabeled corpus를 통해 사전학습을 하고 task에 맞게 fine-tuning을 합니다. 그러나 BERT는 transformer의 encoder로만 구성되어 있고 양방향으로 학습하여 auto encoding한 성격을 가지고 있습니다. 그리고 BERT의 pre-train obejective function으로는 MLM(Masked Language Model)과 NSP(Next Sentence Prediction)를 이용합니다.
그리고 현재 수많은 LM이 등장했습니다. (RoBERTa, MASS, XLNet, BART, ...)
본 lecture에서는 "Given the current landscape of transfer learning for NLP, what works best? And how far can we push the tools we already have?" 에 대한 답으로 T5(Text-to-Text Transfer Transformer)에 대한 여러 실험을 통해 알 수 있다고 했습니다.
T5
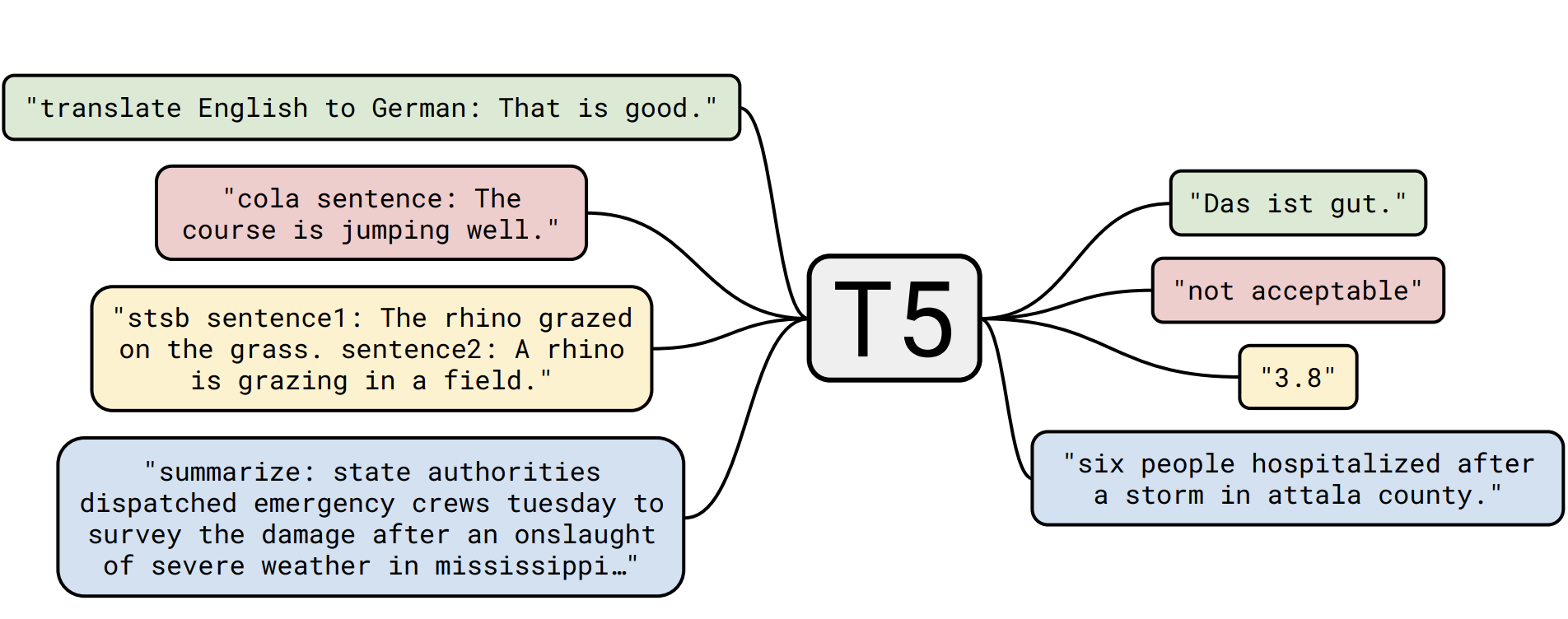
위 그림에서 같은 색깔로 이루어진 text는 모두 같은 task로 처리된것을 의미합니다. 즉, T5는 하나의 framework를 통해 여러 task를 처리할 수 있습니다.
T5 architecture
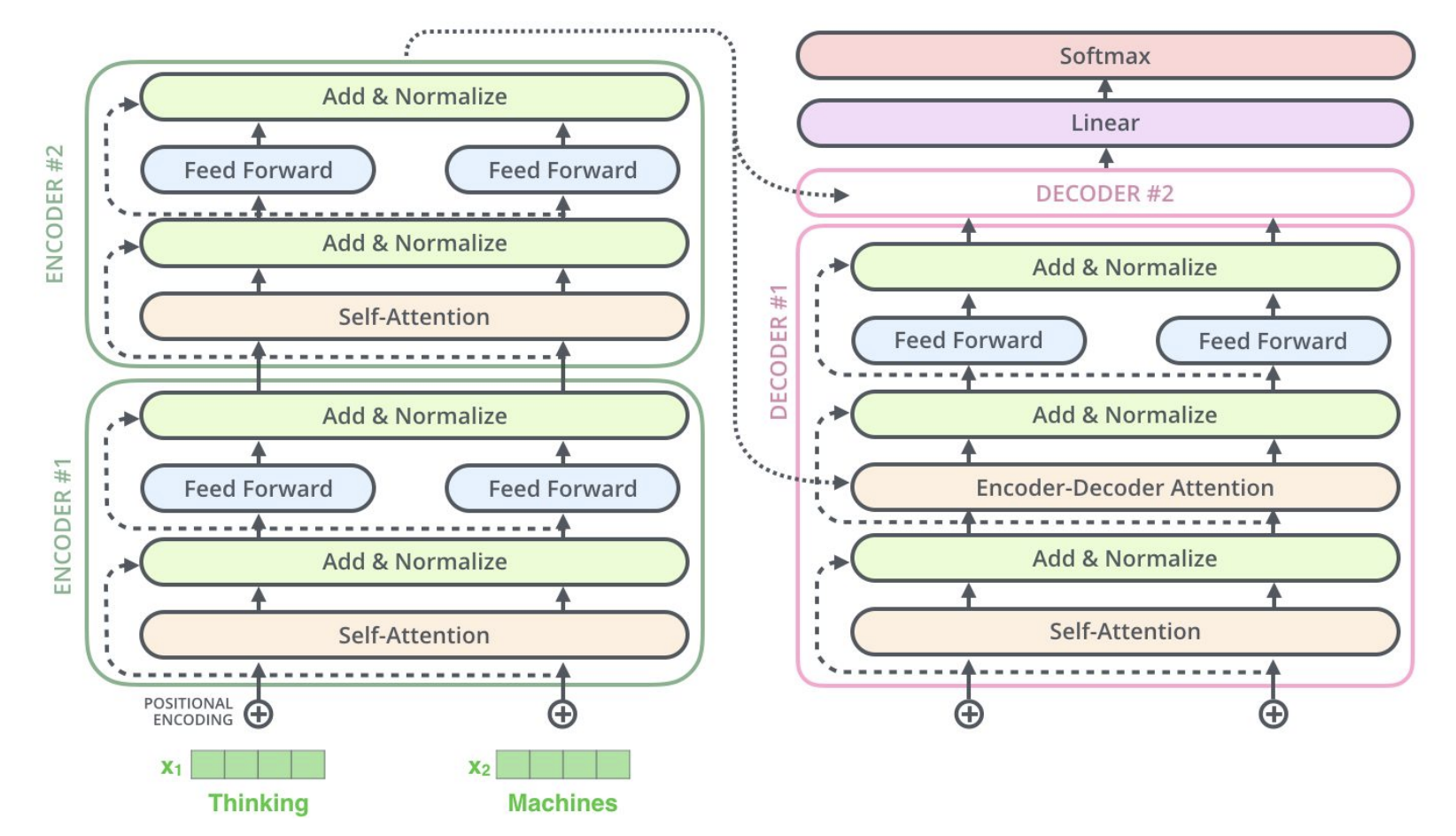
T5는 위와 같이 transformer encoder-decoder 구조를 가지고 있습니다. Encoder, decoder 모두 multi-head self-attention과 feed forward network 및 residual skip connection, dropout 기법을 사용하고 있습니다. 그리고 input token에 relative positional encoding을 사용했다는 점이 다릅니다. Relative positional encoding이란 input으로 들어오는각 token의 위치 별로 동일한 encoding 값을 부여하고 attention 계산을 하는것이 아니라, self-attention 계산할 때 일정 범위 내의 token들에 relative positional encoding 값을 줍니다, 예를 들어 offset = 2라면
- 0 : i번째 token의 왼쪽 2번째 token
- 1 : i번째 token의 왼쪽 1번째 token
- 2 : i번째 token
- 3 : i번째 token의 오른쪽 1번째 token
- 4 : i번째 token의 오른쪽 2번째 token
'I think therefore I am'이라는 문장에 relative positional encoding을 사용하여 self-attention layer를 통과시키면 아래와 같습니다.
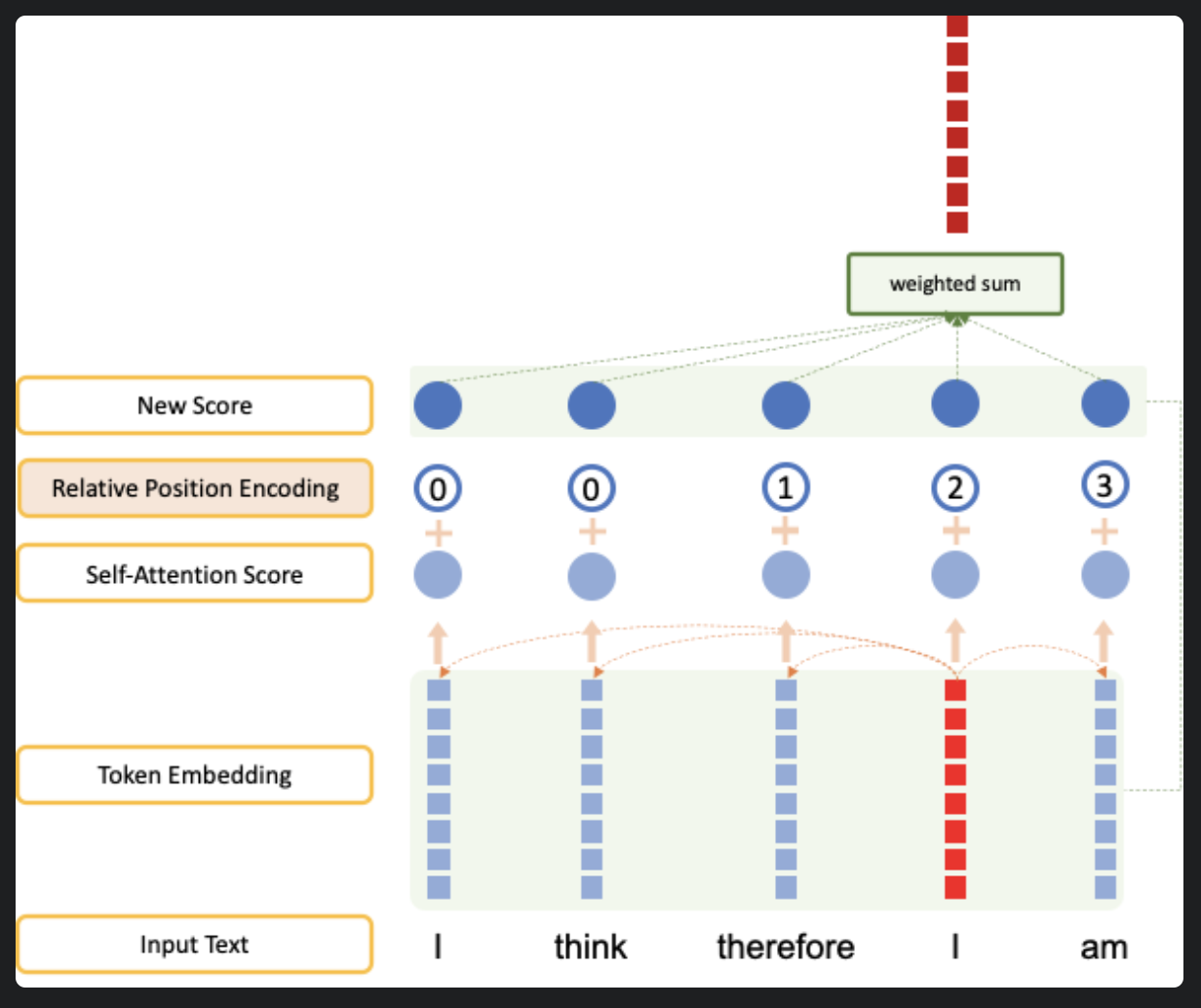
만약 offset = 2라면, offset 범위를 넘어선 token에는 0을 부여합니다.
Common Crawl Web Extracted Text

Transfer-learning을 위한 중요한 요소로는 pre-train에 사용되는 unlabeled corpus dataset입니다. Pre-train할 때 data크기를 키우는 효과를 정확하게 파악하려면 좋은 품질의 data와 여러 domain의 dataset이 필요합니다. 기존 Wikipedia는 품질은 우수한 data지만, 다양성이 부족하고 Common Crawl web scrapping data는 크기가 크고 다양하지만 품질이 낮다는 단점이 존재합니다. 그래서 google에서는 Wikipedia보다 2배 큰 새로운 Common Crawl 버전인 C4(Colossal Clean Crawled Corpus)를 사용했습니다. 그리고 unlabeled data에 대한 여러 실험을 위해 여러 기준에 따라 전처리를 진행했습니다.
Pre-training objective
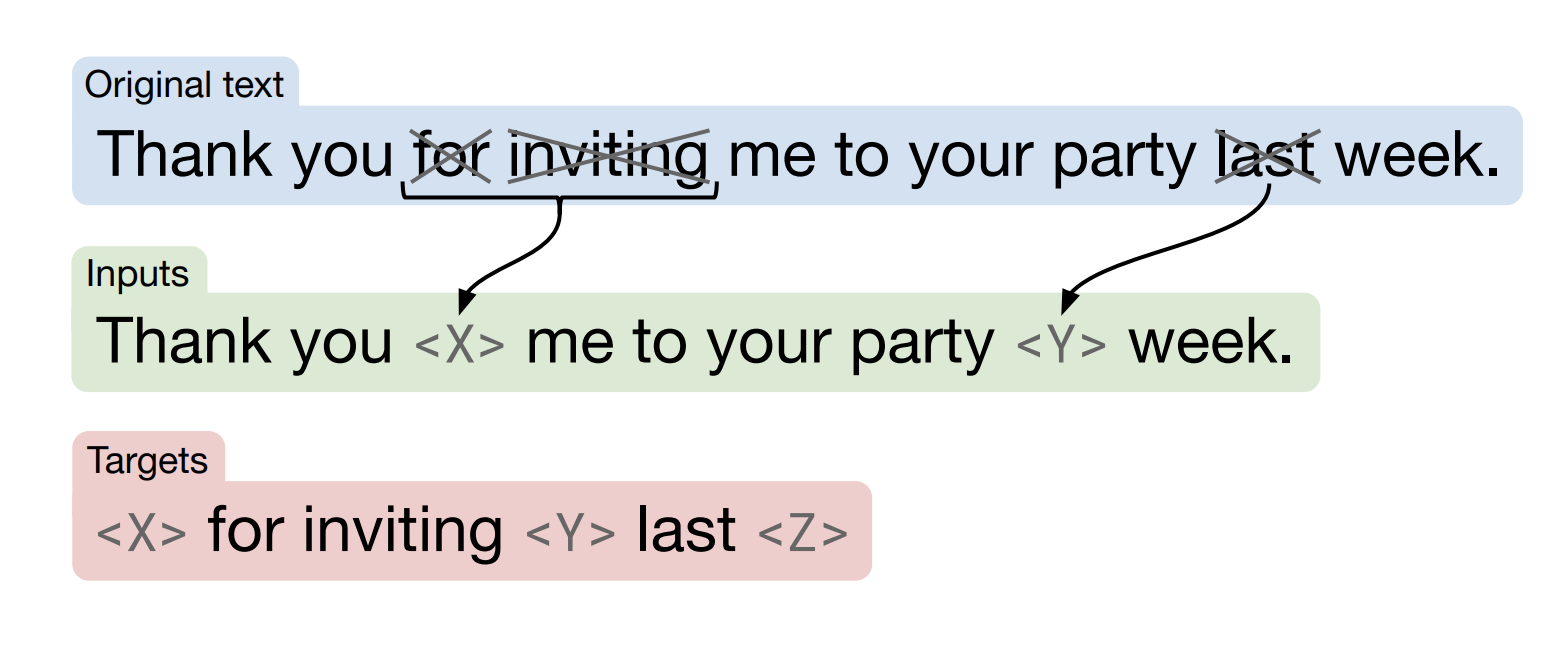
Pre-train에 쓰일 data가 있으므로 그 다음 필요한것은 pre-train에 쓰일 목적함수입니다. 먼저 위와같이 original text가 있을 때, 무작위로 token을 설정하고 masking 처리합니다. BERT와 많이 유사하지만 다른 부분은 하나의 random token을 masking 하는것이 아닌 연속된 token을 하나로 masking 처리합니다. 또한 해당 token을 [MASK]로 변환하는것이 아닌 sentinel ID token으로 대체합니다. 마지막으로 input에서 masking되지 않은 부분을 target에서 맞춰야합니다.
Baseline experimental procedure
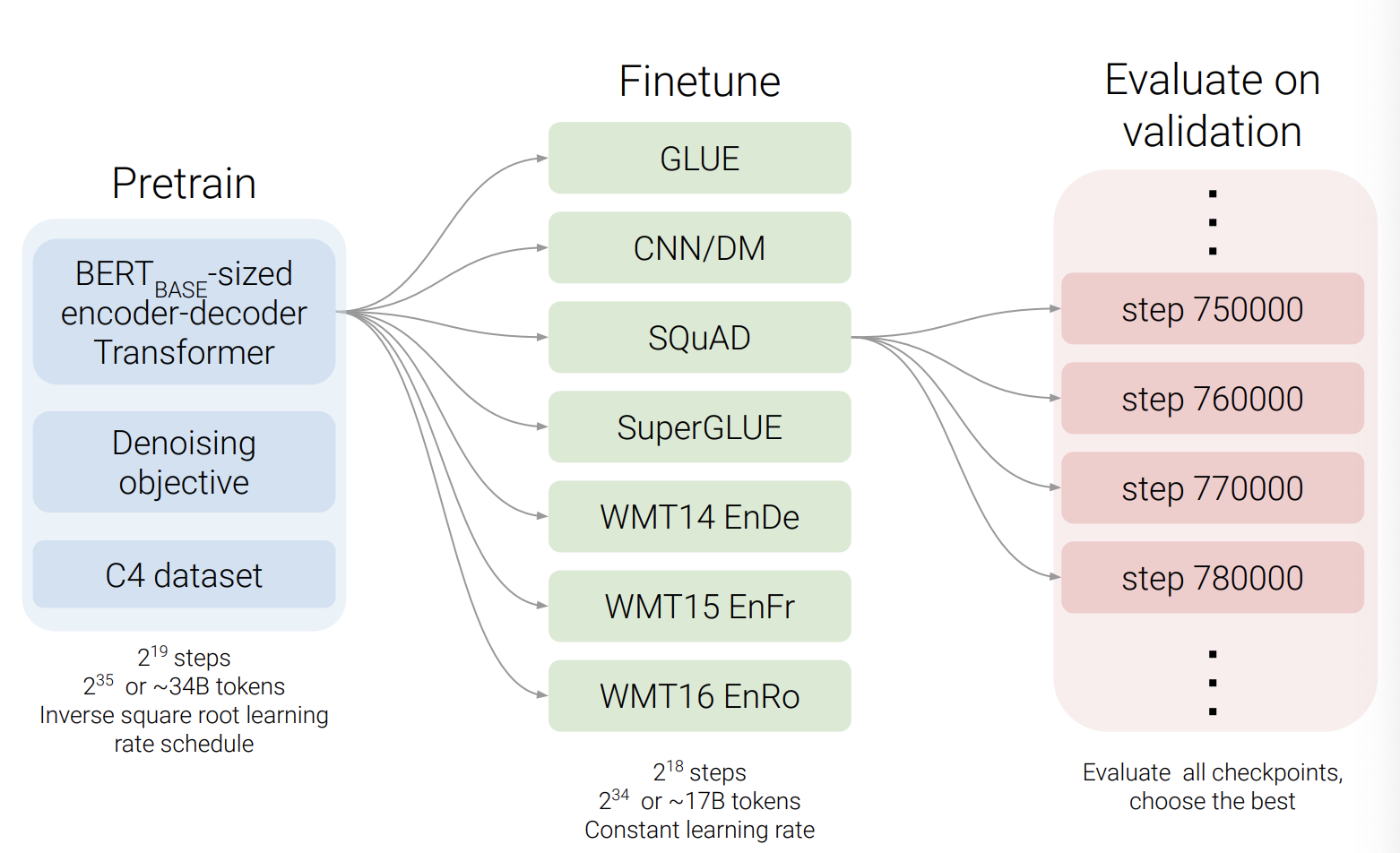
다음은 실험 순서에 대해 설명하겠습니다. 먼저 BERT size의 encoder와 decoder 구조의 transformer를 340억개의 token으로 pre-train을 진행합니다. 훈련시간은 BERT에 비해 약 4분의 1정도라고 합니다. 이렇게 pre-train된 model을 가져와 각 downstream task에 맞게 fine-tuning을 진행합니다. 최대 170억개의 token을 fine-tuning한다고 합니다. 그리고 validation set에 대한 체크포인트를 평가하여 가장 좋은 성능을 보인 model을 찾습니다.
Experiments
본 lecture에서는 T5에 대해 여러가지 실험을 진행했지만 hyper-parameter는 조정하지 않았다고 합니다. 그 이유는 작업에 소모되는 계산 비용이 너무 크다고 주장했고 모두 동일한 framework에서 진행했기 때문에 괜찮을거라고 주장했습니다.
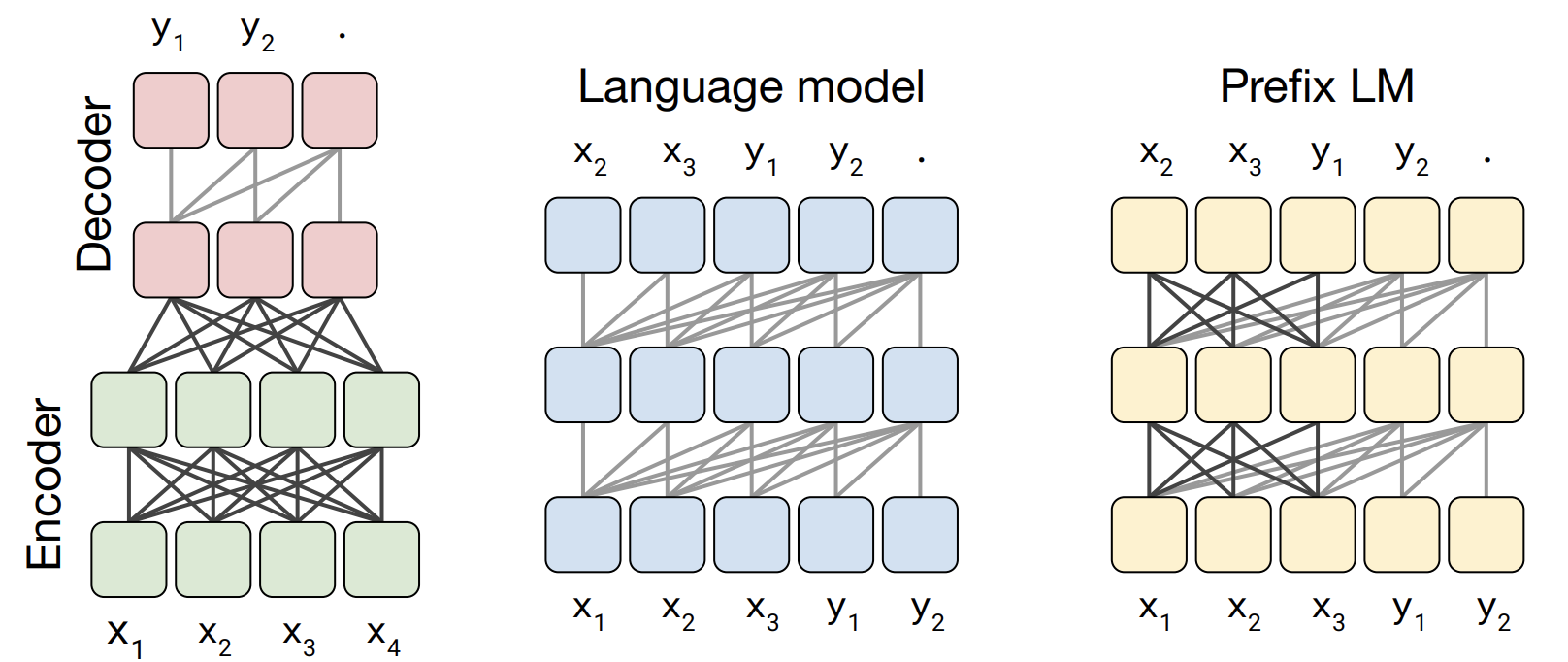
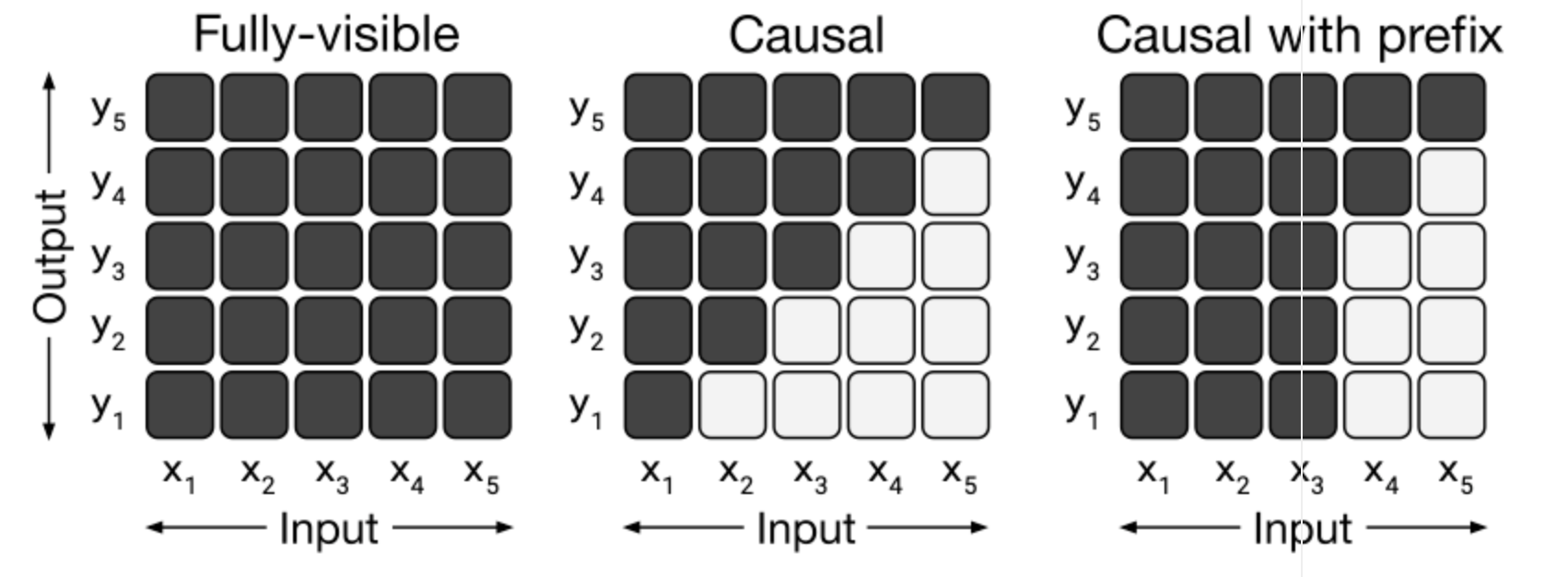
첫 번째 실험은 서로 다른 model 구조를 비교하는 것이었습니다.
- Fully- visible : Query가 모든 Key에 attention 가능
- Casual : Query(현재 time-step)가 이전 time-step의 Key에 attention 가능
- Casual with prefix : Query가 현재와 이전 timstep의 prefix Key에 attention 가능
T5는 3가지 model setup을 모두 실험했습니다. 먼저 encoder는 fully visible하게 attention을 진행하고 decoder의 경우 causal한 방법으로 attention을 진행하는 경우 입니다. 그리고 baseline model의 절반인 6개의 layer만 제한하고 decoder만 존재하는, regressive한 성격을 가지고 있는 GPT와 같은 model로 설정했습니다. 마지막으로 prefix LM으로 encoder에서는 auto-encoder 형식을, 그리고 decoder에서는 auto-regressive 형식을 이용했습니다.

위의 표를 보면 encoder-decoder의 구조를 가진 model이 성능이 제일 좋은것을 알 수 있고 LM이 성능이 가장 좋지 않았습니다. 결국, bi-directional한 구조를 가진 model이 성능이 좋은것을 알 수 있습니다.
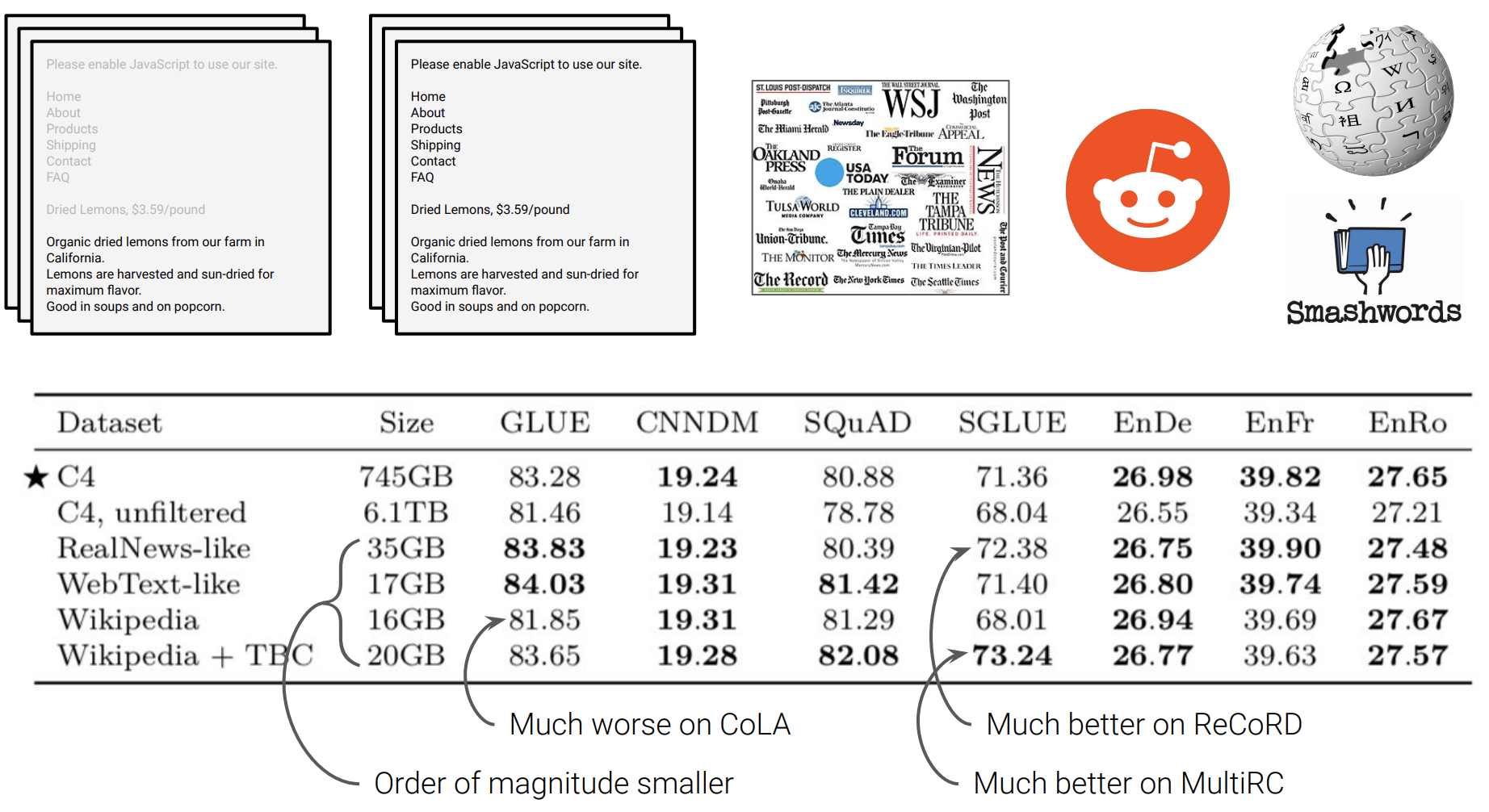
다음 실험은 pre-training한 dataset에 따른 성능 변화입니다. 기존 수집한 C4와 unfiltered C4 그리고 여러 다른 dataset을 가지고 pre-train한 후 여러 task에 대해 성능을 비교했는데 C4를 사용했을 때 성능이 제일 좋았습니다.
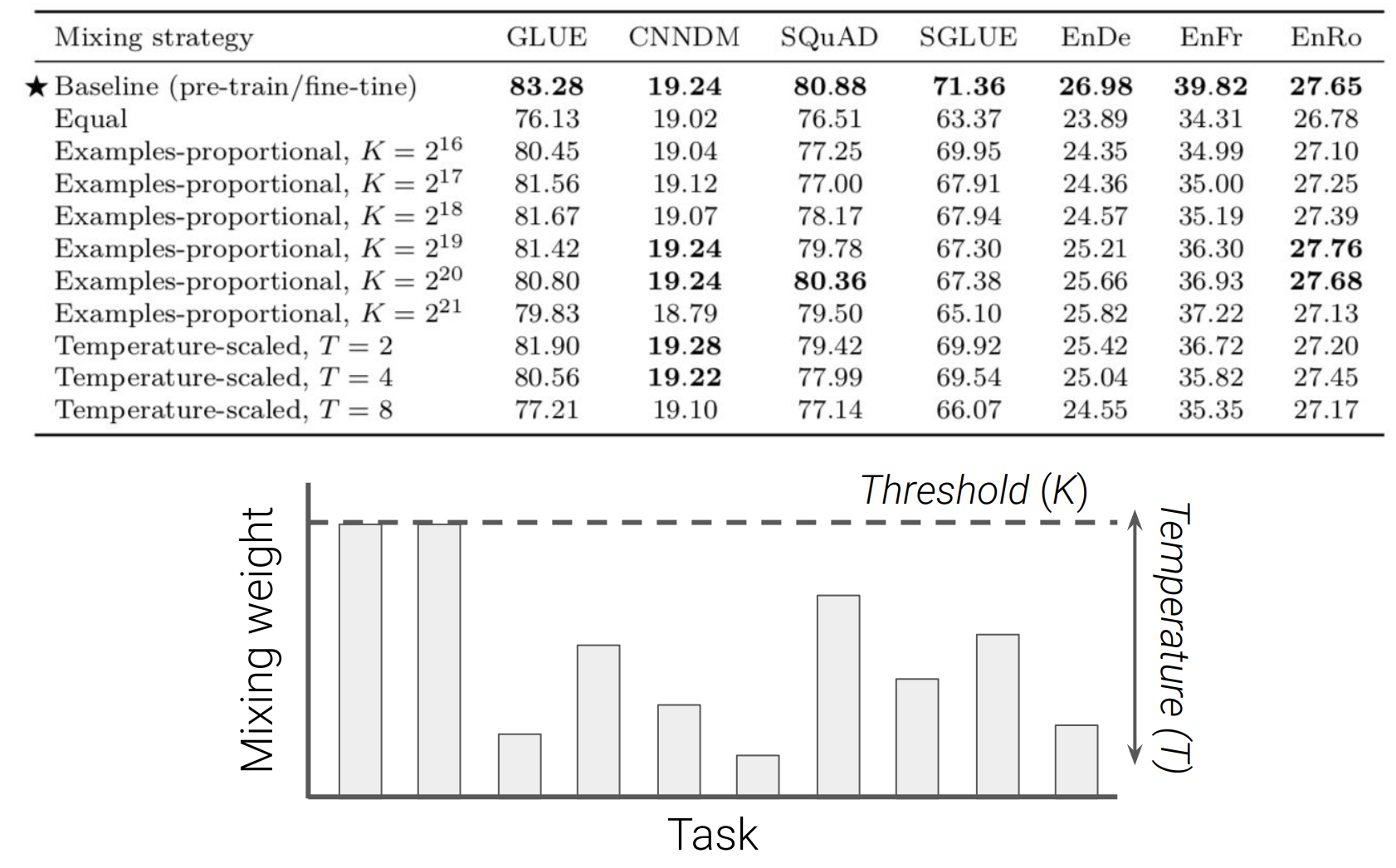
T5는 다양한 task를 가지고 있고 얼만큼 학습하는것이 성능이 좋은지에 대한 실험입니다. Equal의 경우는 task에 상관없이 모두 같은 사이즈의 data를 학습시키는 방식입니다. K는 threshold로 기본적으로 data의 size만큼 학습하고 K이상의 데이터는 K만큼 학습합니다.
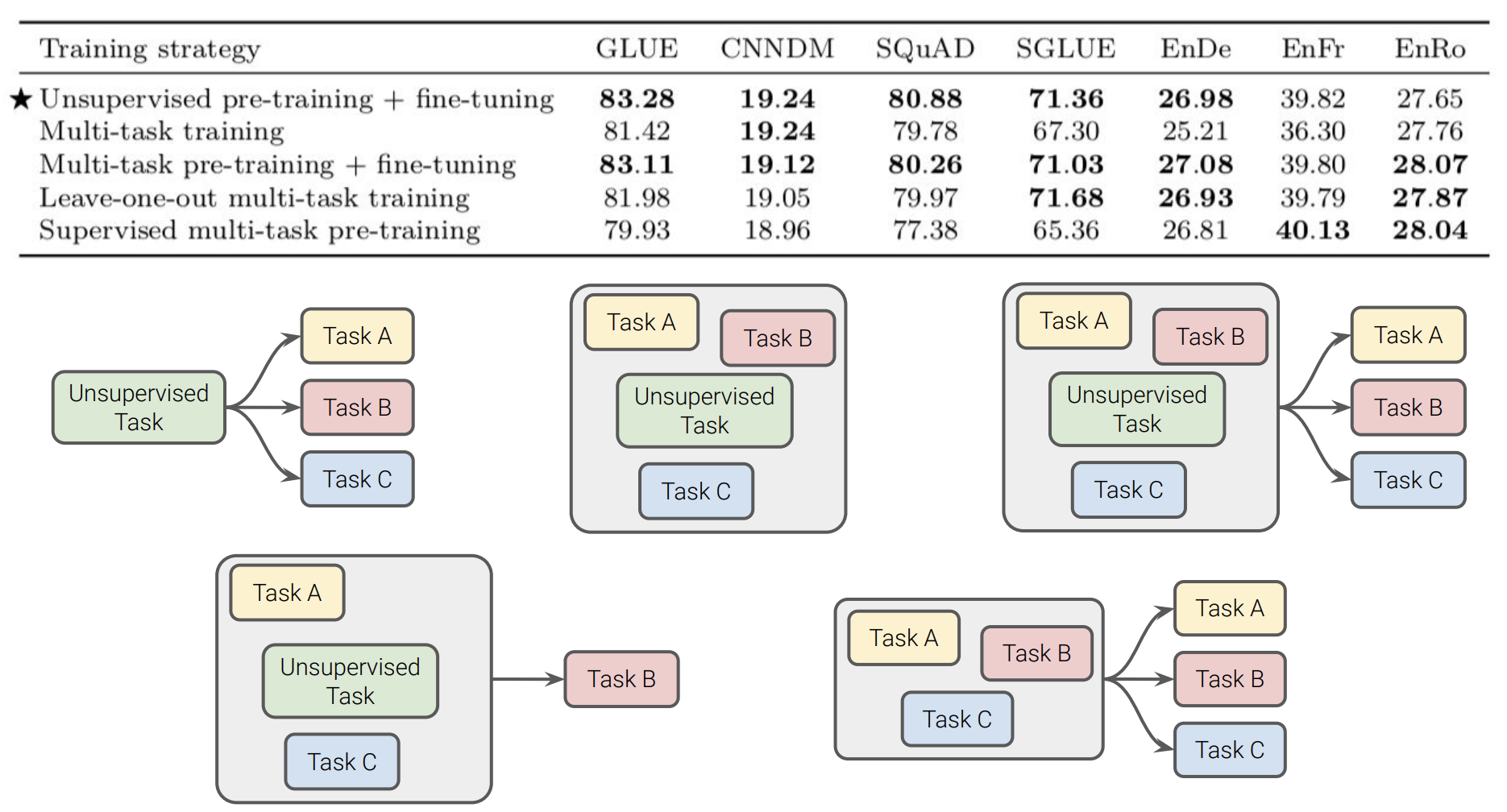
다양한 방식의 조합으로 훈련을 진행하여 성능을 비교했습니다. Pre-training을 진행하고 fine-tuning을 진행한 방식이 제일 성능이 높았습니다.
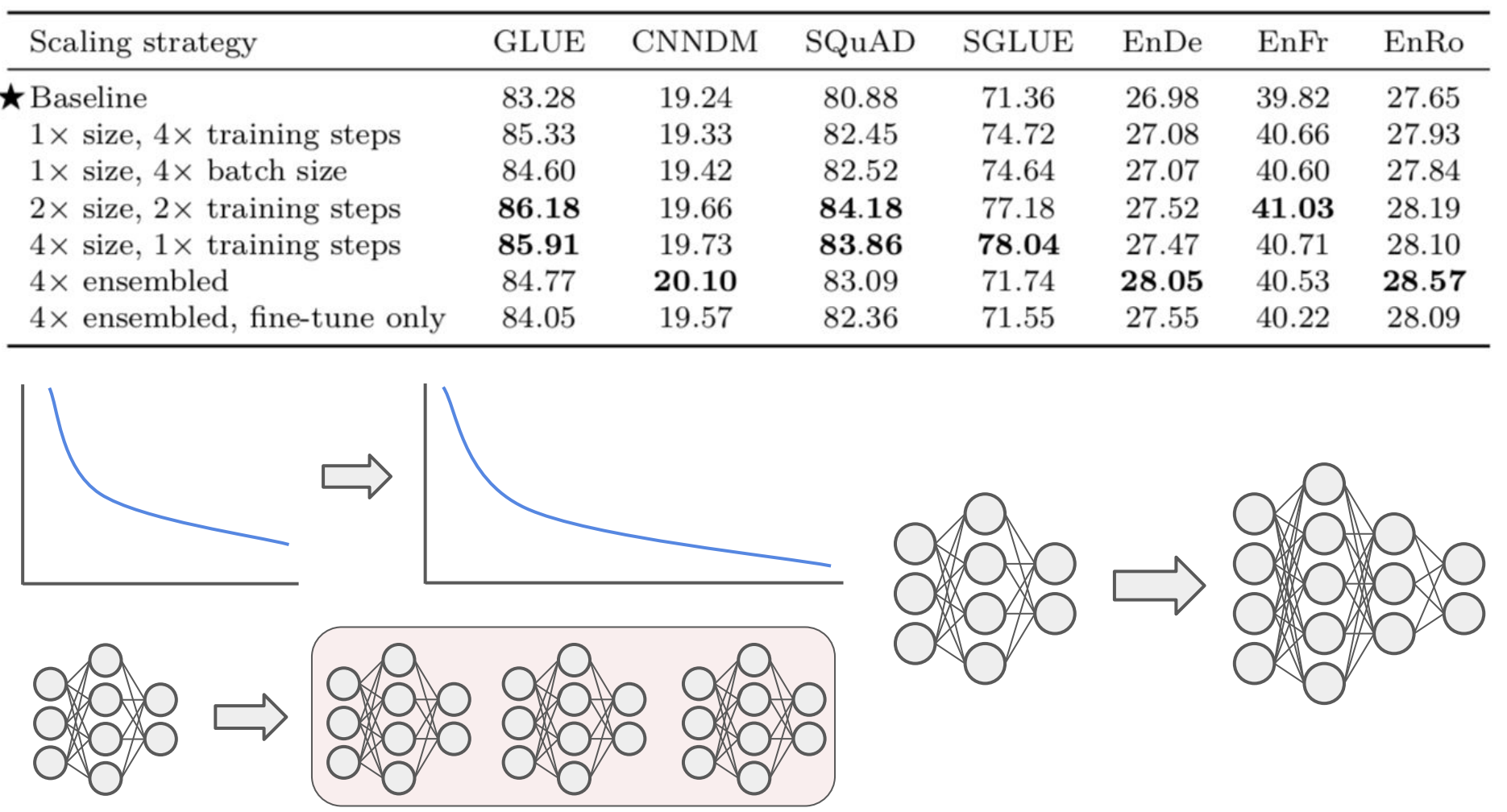
Scale-up을 할 수 있는 hyperparameter의 값을 조절해가면서 실험했습니다. Training steps, batch size, model size를 조절하면서 실험한 결과 training steps를 늘리고 model size를 키웠을 때 성능이 제일 좋았습니다.
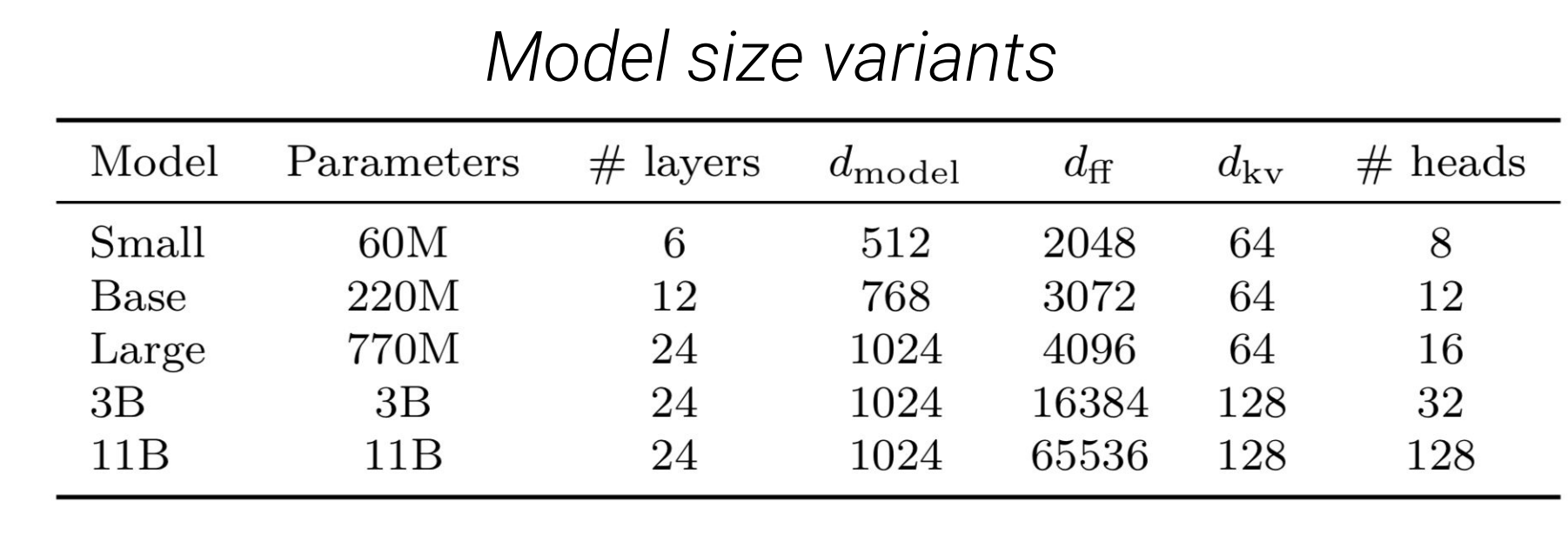
위의 표는 각 model size별 parameter입니다.
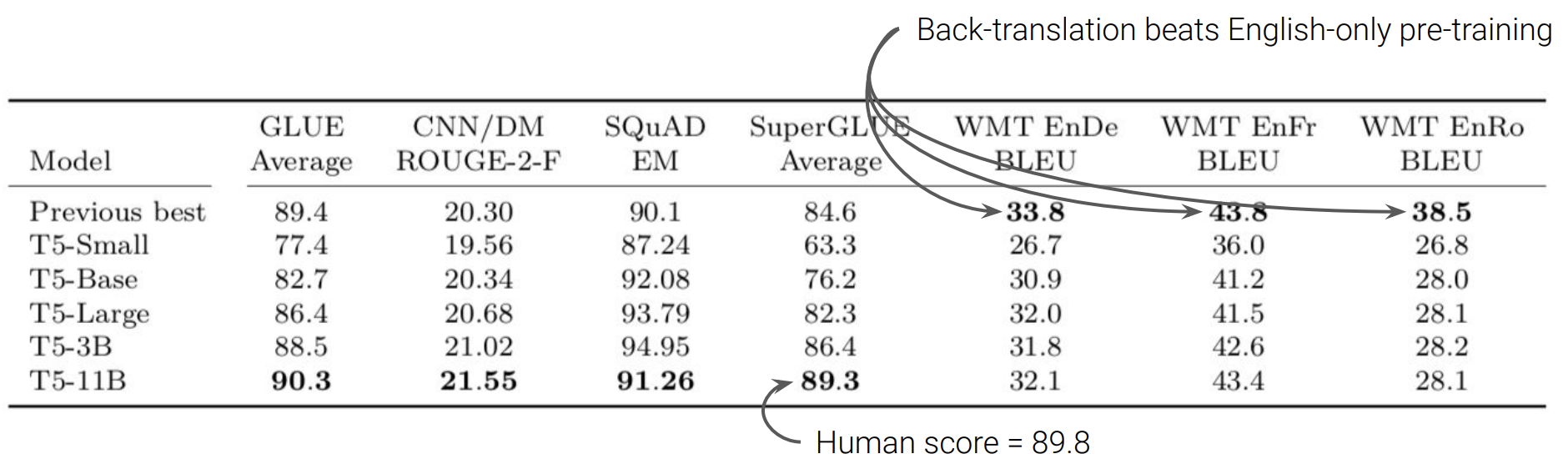
위의 table은 T5가 여러 benchmark에서 SOTA를 달성한 결과를 보여주는데, 번역에서는 모두 SOTA에 비해 점수가 좋지 않았습니다. 본 lecture에서는 SOTA를 달성한 model이 모두 back translation을 진행했기 때문이라고 했습니다.
mT5 - What about all of the other languages?
지금까지는 영어로 pretrained된 model인 T5에 대해서 얘기했고 그렇다면 다른 languages에는 어떻게 적용할까? 그래서 최근에 다국어 T5 model을 도입했다고 합니다.
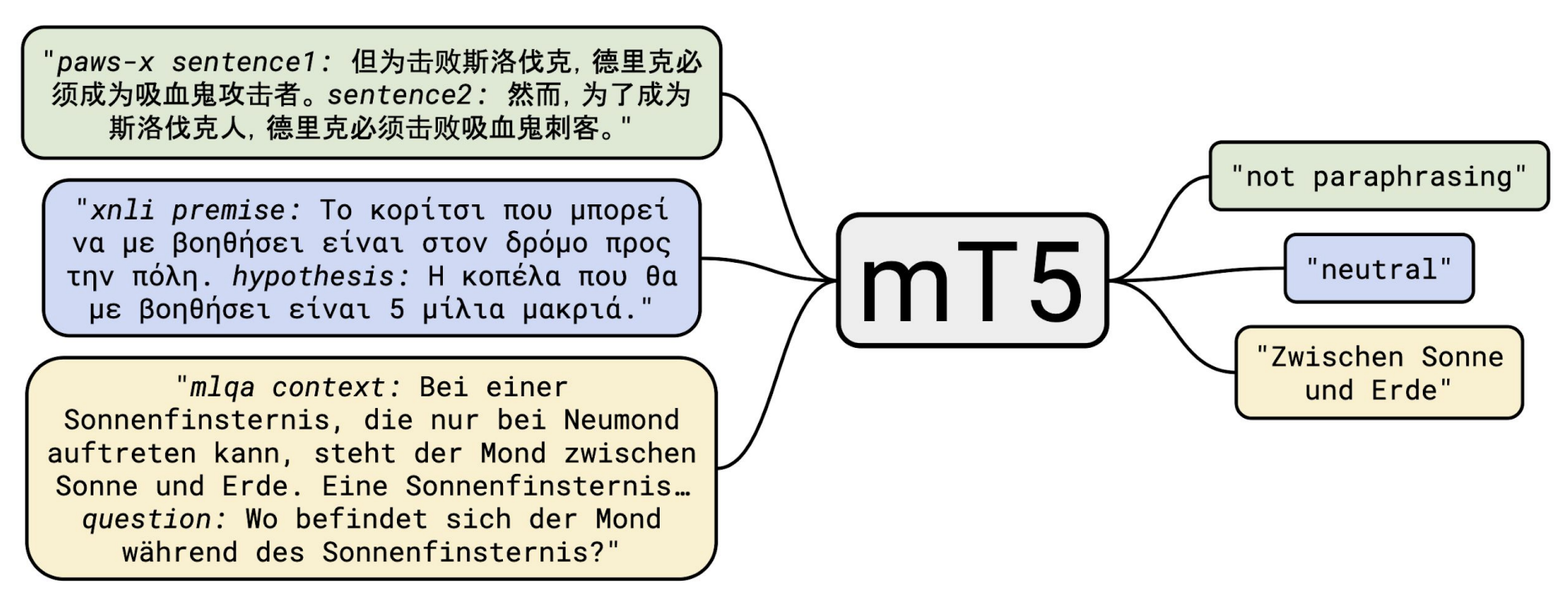
Text-to-text 형식은 그대로 갖고 가지만 input과 output이 다른 언어로 나올 수 있습니다. 그렇다면 이에 적절한 pre-train dataset이 필요한데, 그래서 101개 languages가 포함된 C4 data를 이용했습니다. 또한 질이 좋은 data를 더 얻기 위해 Common Crawl dump에서 data를 추출했습니다.
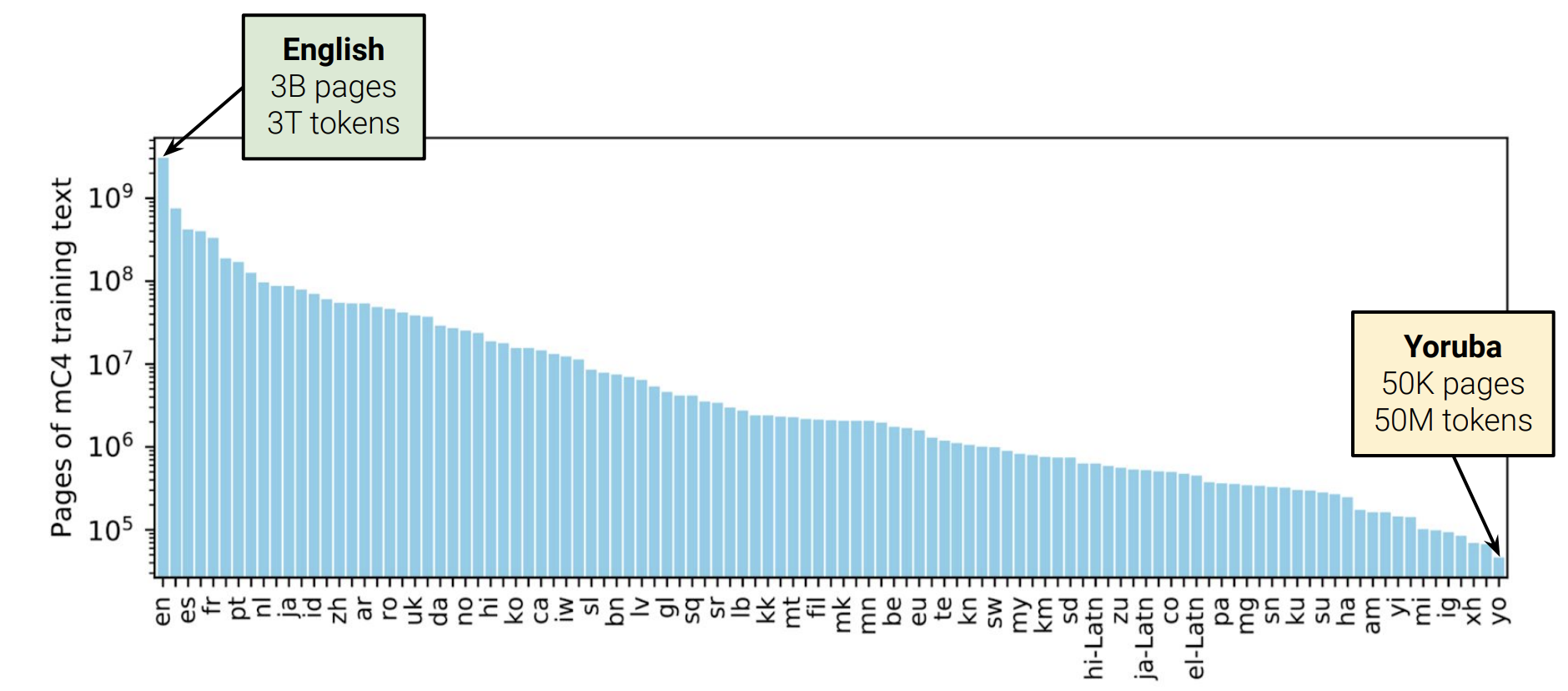
그리고 위 그래프를 통해 language 분포도를 확인할 수 있습니다. 각 language의 양이 많이 차이가 나는것을 확인할 수 있습니다. 이러한 차이를 좁히기 위해 scaling을 진행했다고 합니다.
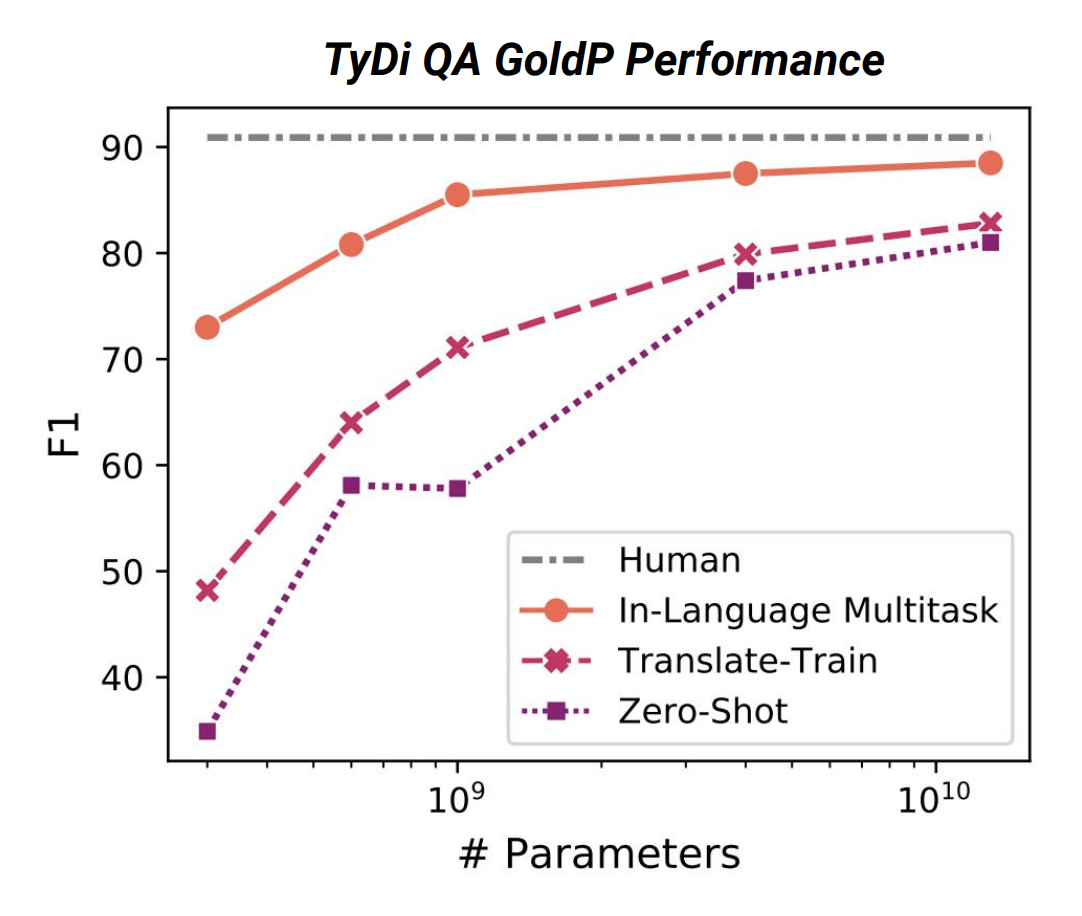
위 그래프는 각기 다른 훈련방법을 통한 성능차이를 보여줍니다. 먼저 zero-shot이란 fine-tuning을 진행하지 않은것이고 translate-train은 영어 corpus로 fine-tuning을 한것입니다. In-Language Multitask는 데이터를 처리할 수 있는 모든 언어의 실측 데이터가 있다는 설정입니다. 그래프가 시사하는 바는 결국 parameter가 많은, 큰 model이 어떠한 환경에서도 더 잘 수행한다는점입니다. (학습하는 언가 많을수록 더 많은 parameter가 필요하기 때문에?)
How much knowledge does a language model pick up during pre-training?
Model이 pre-train하면서 얼마나 많은 지식을 습득할 수 있을까? 이번에는 T5가 reading comprehension에서 어떤 성능을 보여주는지 입니다. Reading comprehesion이란 질문이 주어지고 질문에 대한 답을 찾을 수 있는 knowledge가 주어졌을때, model이 답을 찾을수 있는지에 대한 task입니다.
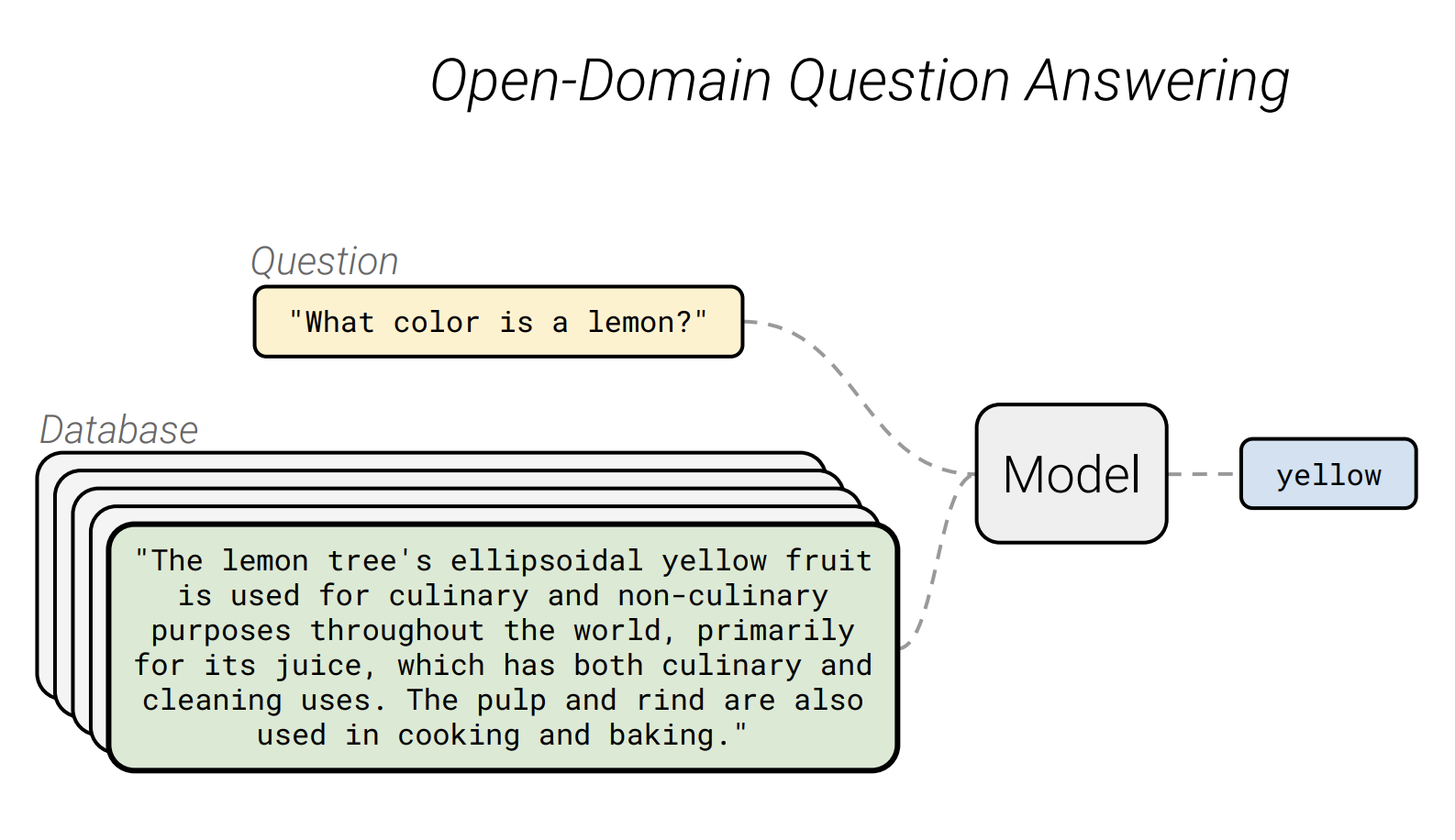
Open-Domain QA는 특정 knowledge에 상관없이 전체적인 모든 질문에 model이 답을 할 수 있는 task입니다.
따라서 질문에 대한 답변을 얻을 수 있는 database를 구축하고 정답을 찾아냅니다.
Closed-book Question Answering
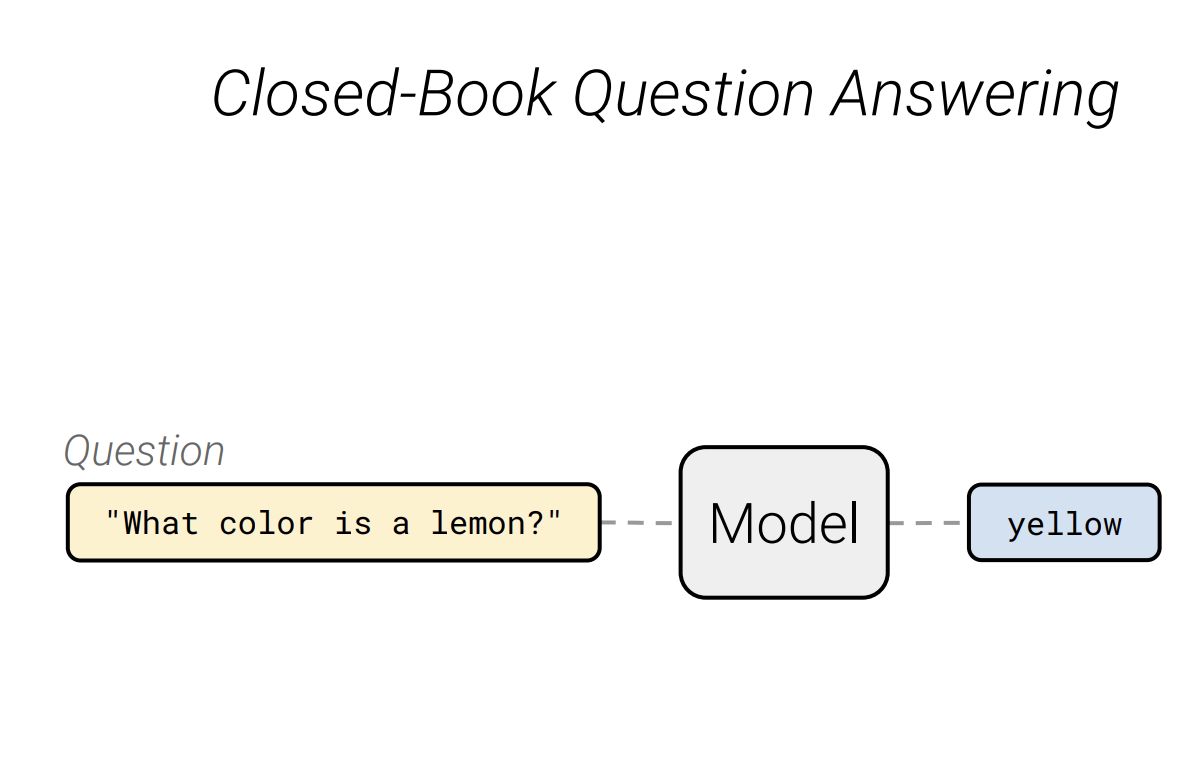
Open-book은 질문과 지문이 주어지고 질문에 맞는 지문을 찾고 model이 해당 지문에서 정답을 찾는 task입니다. Closed-book은 대용량의 data를 학습한 model에 질문을 input으로 넣었을 때, output으로 정답이 나오게되는 task입니다. 이때 model이 얼마나 지식을 잘 기억하는지가 중요합니다.
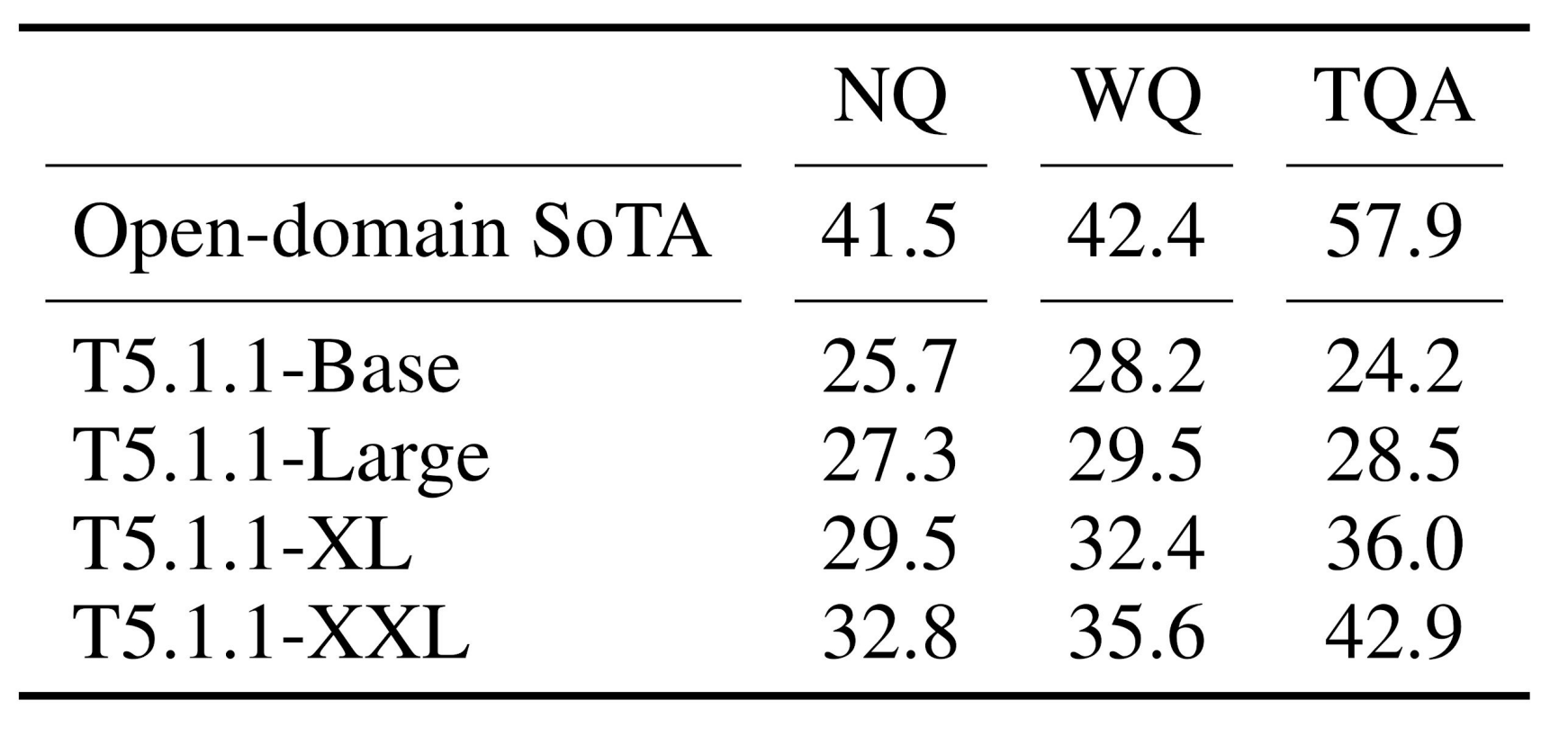
위의 표는 natural question, web question, trivial QA에 대한 성능을 보여줍니다. Open-domain에 대한 SOTA model과 closed-book으로 훈련된 T5를 비교했습니다. Model의 크기가 증가할수록 학습하는 지식의 양이 많아지기 때문에 성능이 증가하지만, SOTA에는 미치지 못한것을 확인할 수 있습니다.
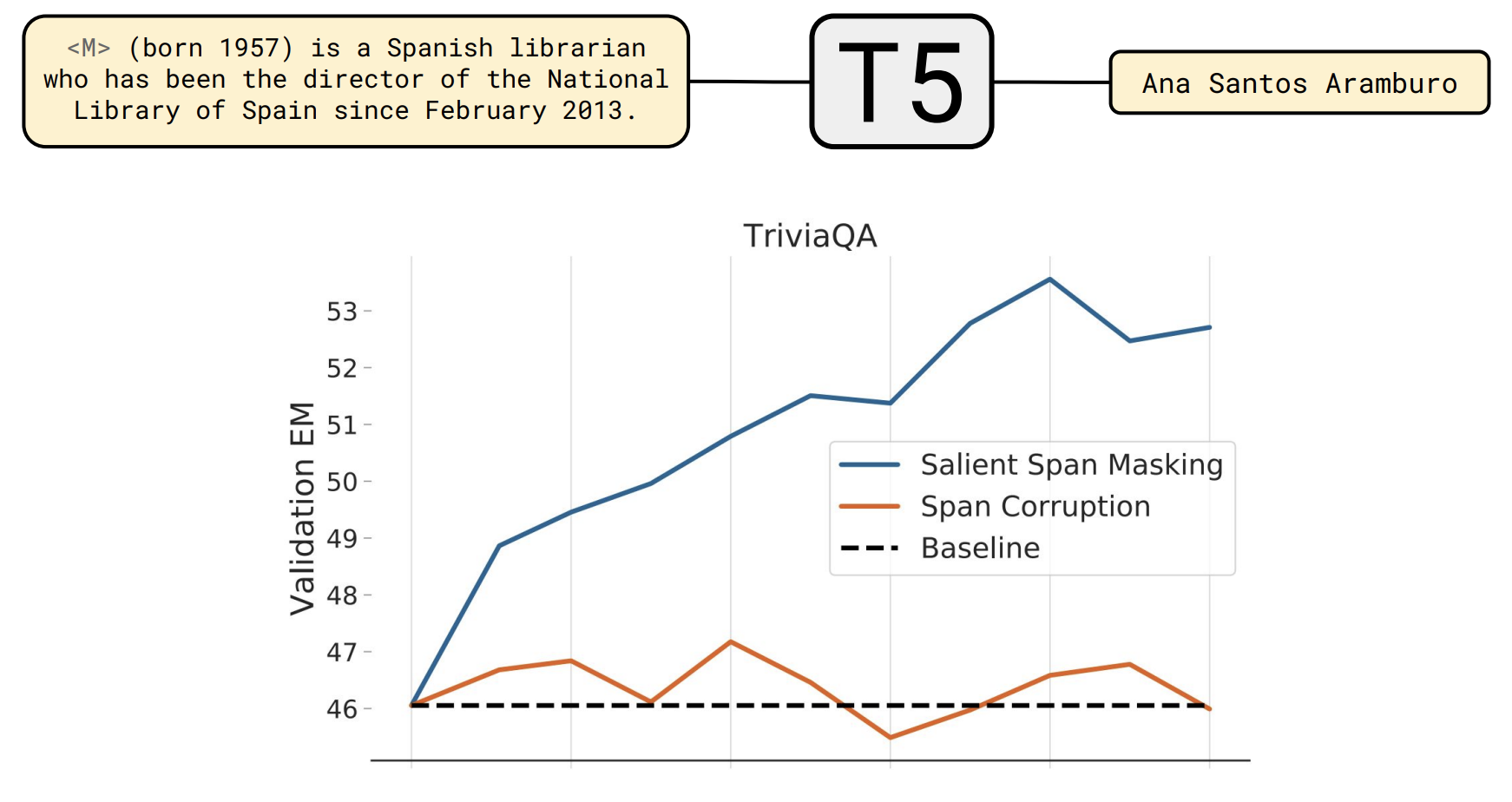
이러한 격차를 좁히기 위해 salient span masking을 도입했습니다. Salient span masking이란 pre-train할 때 random하게 masking을 하는것이 아닌 특정 entity에 masking을 하는것입니다.(사람 이름, 장소, 날짜, ...) 훈련을 하기전 entity recoginzer를 통해 entity를 파악하고 무작위 범위를 채우는 것이 아닌 두드러진 범위를 채우도록 model을 훈련합니다.
Do large language models memorize their training data?
Model이 pre-train할 때, 원하지 않는 정보 까지 기억할까?
대량의 data를 학습할 경우 여러가지 문제가 발생할 수 있는데 그 중 lecture에서는 원하지 않은 개인정보가 training dataset에 포함될 수 있다고 했습니다.
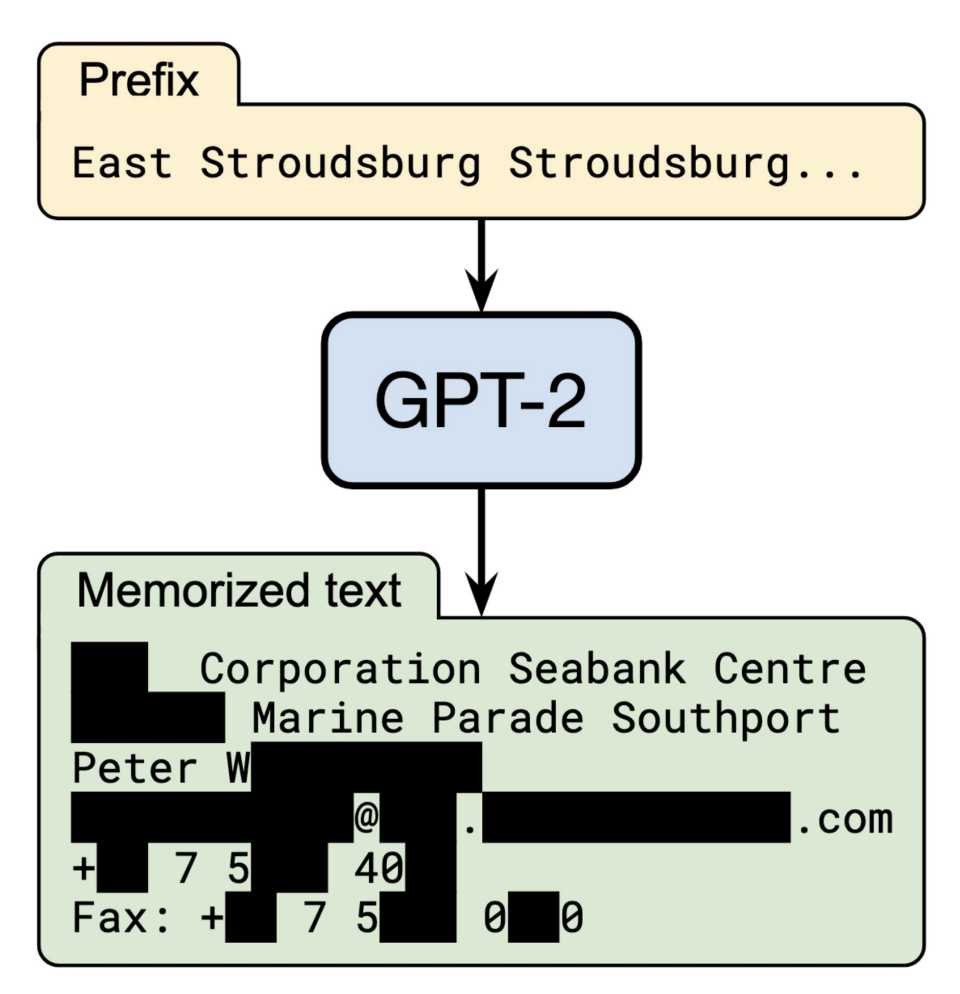
예를 들어, GPT같이 대량의 web기반의 data로 학습된 model이 개인의 신상정보를 generate할 수 있는 문제점이 있습니다. 현재 이러한 이슈가 굉장히 중요한 issue가 된다고 합니다.
Can we close the gap between large and small models by improving the Transformer architecture?
지금까지는 큰 model이 여러 실험과 benchmark에서 더 좋은 성능을 보여줬고 정보를 더 많이 담고 있는것으로 증명이 되었는데, 작은 model도 architecture를 수정하여 큰 model과의 격차를 줄일 수 있을까?
Large model은 성능은 좋지만 돌리는데 드는 시간과 비용이 상당합니다. 그래서 small model로도 격차가 많이 벌어지지 않게 성능을 낼 수 있는지에 대한 여러 방법이 현재까지 제시되었습니다.
- Factorized embeddings
- Shared embedding and softmax layer
- Mixture of Softmaxes, Adaptive softmax
- Different ways of normalizing or initializing (RMSNorm, ReZero, FixUp)
- Different attention mechanisms (Transparent Attention, Lightweight & Dynamic Convolutions, Synthesizer)
- Different structures for the feed-forward layers (Nonlinearities, Mixture of Experts, Switch Transformer)
- Different transformer architecture (Funnel Transformer, Evolved Transformer, Universal Transformer, block sharing ...)
