본 lecture에서는 다음과 같은 순서로 강의가 진행됩니다.
- RNN language models
- Other uses of RNNs
- Exploding and vanishing gradients
- LSTMs
0. RNN language models
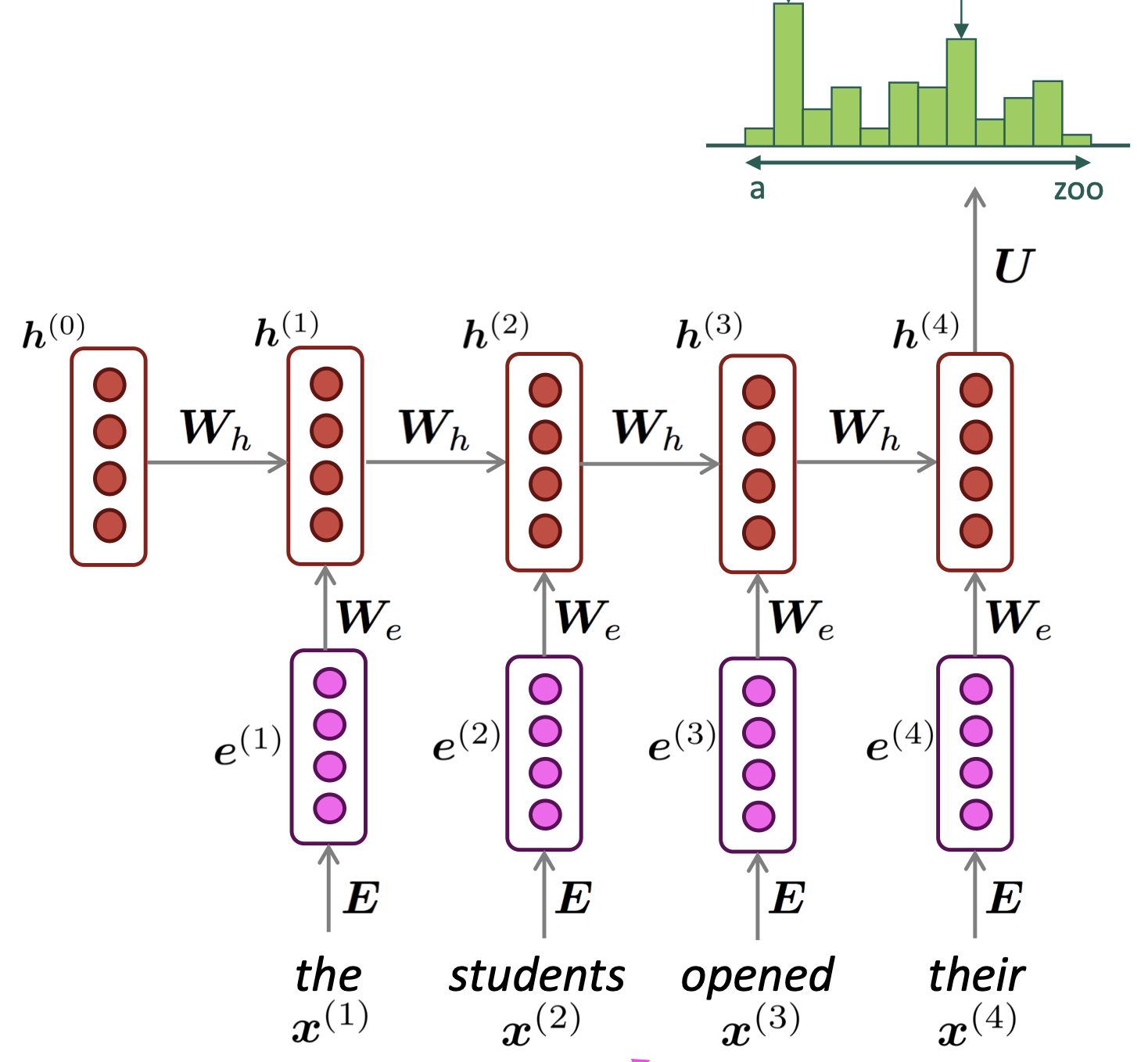
RNN 모델은 input으로는 vocab size만큼의 차원을 가지는 one-hot vector로 그 문자에 해당하는 index만 1인 값이 들어가게 됩니다.
그리고 해당 vector는 embedding matrix와 연산을 하여 embedding represent vector를 생성하게 됩니다.
앞서 계산된 embedding vector와 이전 timp stepdml hidden state vector의 연산으로 현재 시점의 hidde state를 계산합니다.
이렇게 계산된 hidden state에 가중치 행렬 와 곱한 뒤 softmax 함수를 취하여 vocab size만큼의 output vector를 반환합니다. Output vector값은 각각 해당 단어가 등장할 확률값을 의미합니다.
0.1 Training an RNN Language Model
t시점에서의 RNN의 loss function은 아래와 같습니다.
Loss function은 실제 다음 단어와 예측한 단어의 결과의 cross-entropy입니다.
Overall loss는 모든 시점에서의 loss값을 구하고 이의 평균입니다.
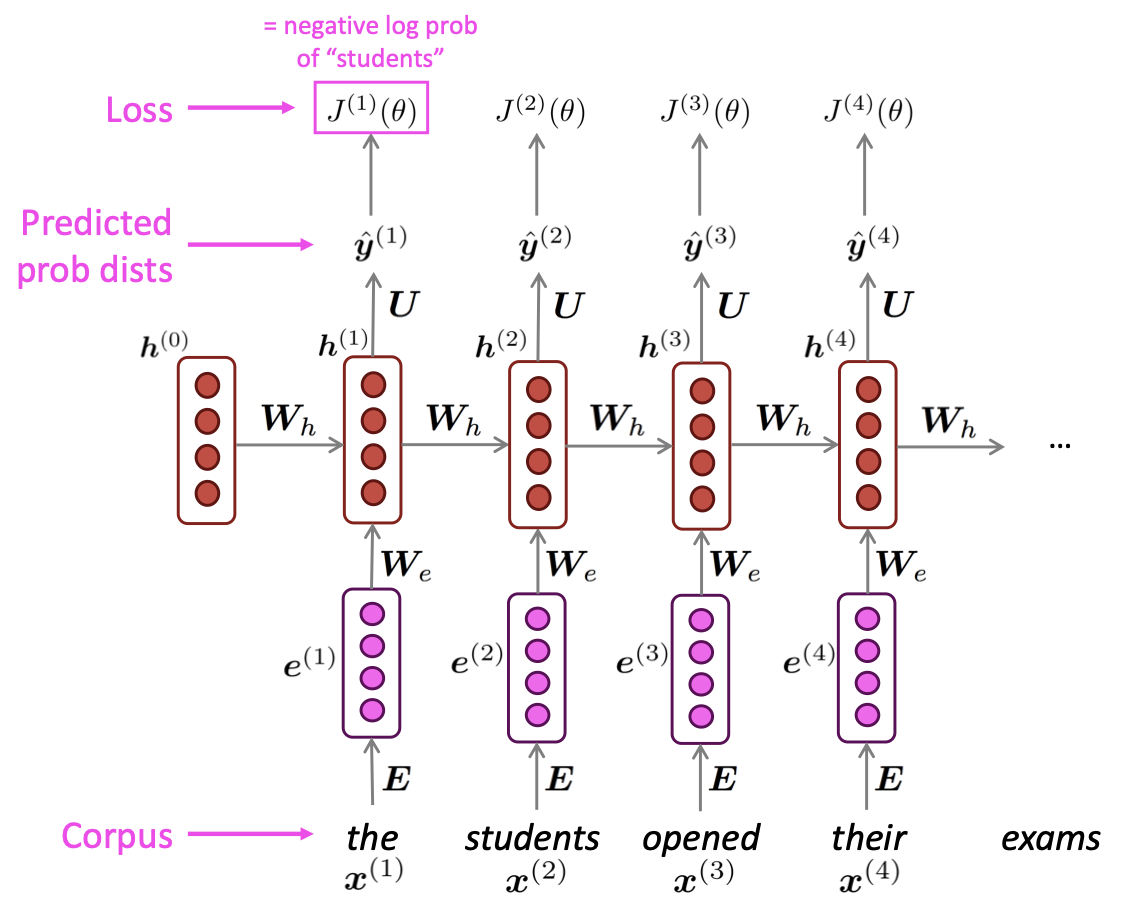
위 그림은 전체 input sequence에 대해 loss와 gradient를 계산하는 과정입니다. RNN은 매 time step의 loss를 계산하고 gradient를 업데이트 해야하므로 많은 시간과 연산이 필요합니다.
0.2 Backpropagation for RNNs
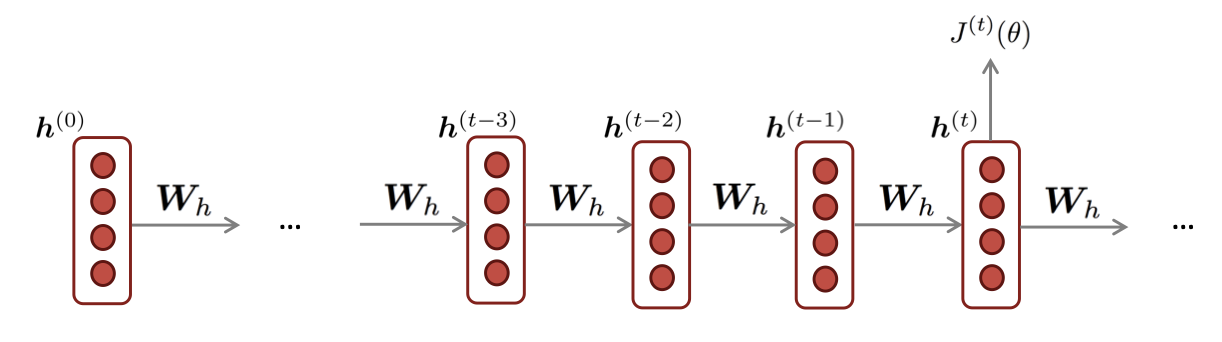
RNN의 backpropagation은 기존 MLP와의 backpropagation과정이 다르지 않지만 각 time-step에서 input과 output을 가지고 있고 각 output을 계산하는데 사용되는 weight matrix가 time-step마다 연결되어 있기 때문에 이를 반영해야합니다.
RNN의 역전파과정은 다음 페이지에 정리했습니다.
https://velog.io/@jody1188/BPTT
0.3 Generating text with a RNN language Model
다음은 RNN language model을 통하여 text를 생성하는 내용에 대해 설명드리겠습니다.
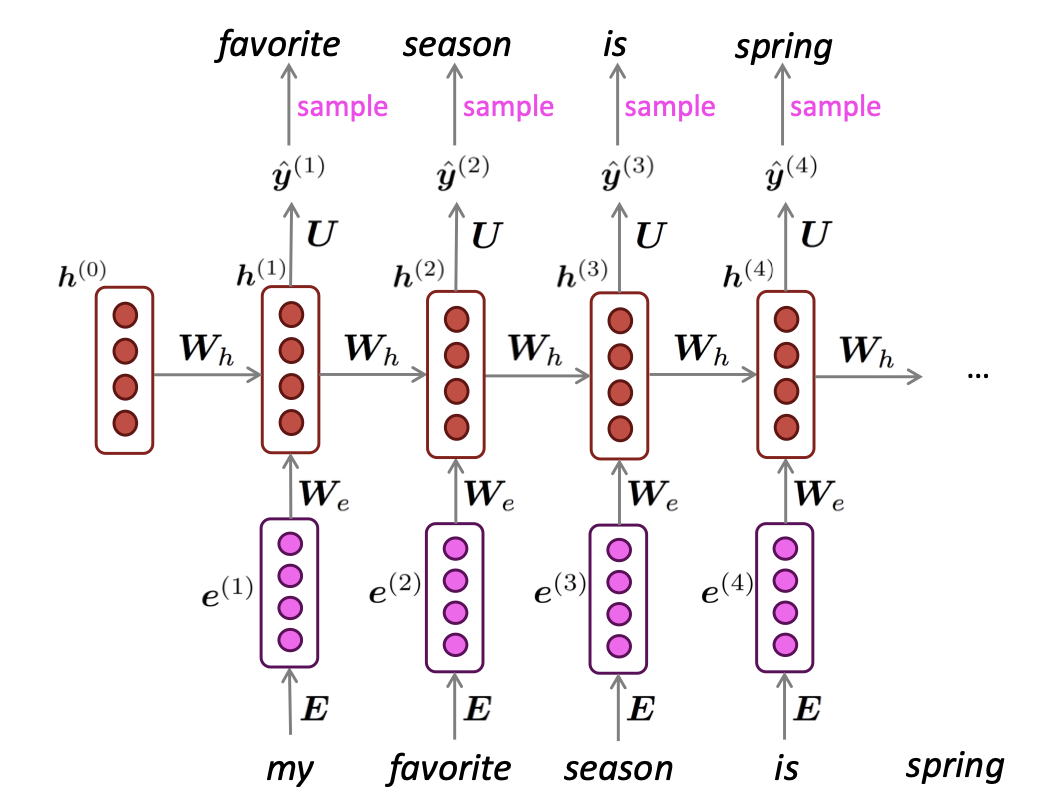
N-gram language model과 같이 RNN Language Model은 각 time step별로 sampling을 반복하면서 output, text를 생성합니다.
Example


위의 example을 통해 text-style에 맞게 text가 생성된것을 확인할 수 있습니다.
0.4 Evaluating Language Models
Language Model의 가장 대표적인 평가지표는 perplexity입니다.
Perplexity
Perplexity는 단어 그대로 '헷갈린'과 비슷한 의미를 가지고 있습니다. 단순하게 PPL은 점수가 높으면 성능이 낮고, 점수가 낮으면 성능이 높은 평가지표입니다.
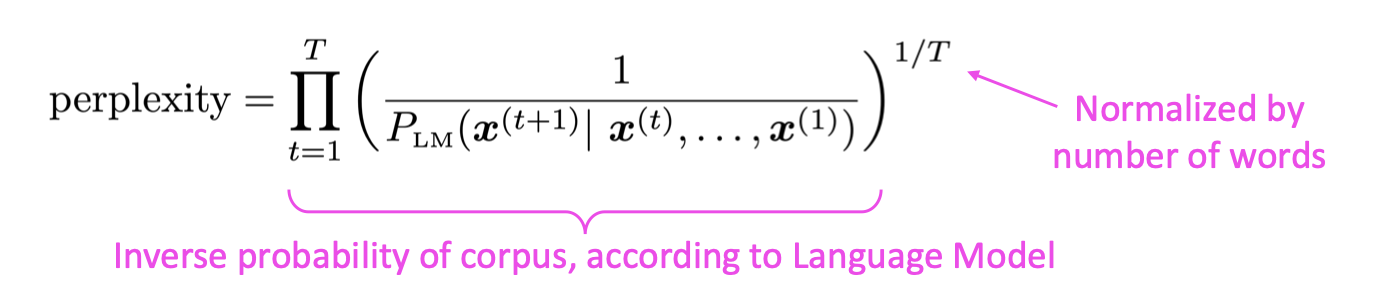
PPL은 문장의 길이 로 정규화된 문장의 확률의 역수입니다.
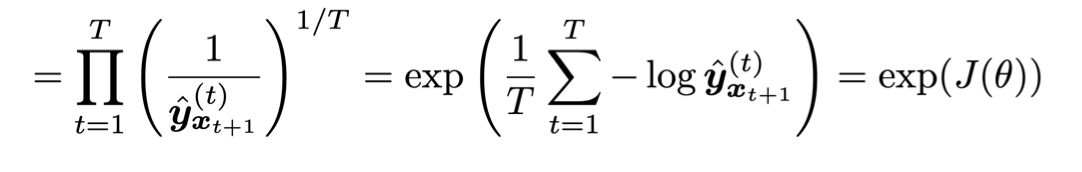
그리고 한 문장에 대한 cross-entropy를 아래와 같이 표현할 수 있습니다.
위에 PPL식과 cross-entropy의 수식이 비슷한 형태를 가지고 있는것을 알 수 있습니다. 그러므로 PPL과 cross-entropy의 관계는 아래와 같이 정리할 수 있습니다.
우리는 반복적인 학습을 통해 parameter 를 학습할 때, cross entropy로 얻은 loss값에 exp함수를 취함으로써, perplexity를 얻어 language model의 성능을 알 수 있습니다.
1. Other uses of RNNs
RNN은 language model으로써 다양한 task를 수행할 수 있습니다.
1.1 Sequence tagging
RNN은 part-of-speech tagging, named entity recognition와 같이 sequence tagging task를 수행할 수 있습니다.
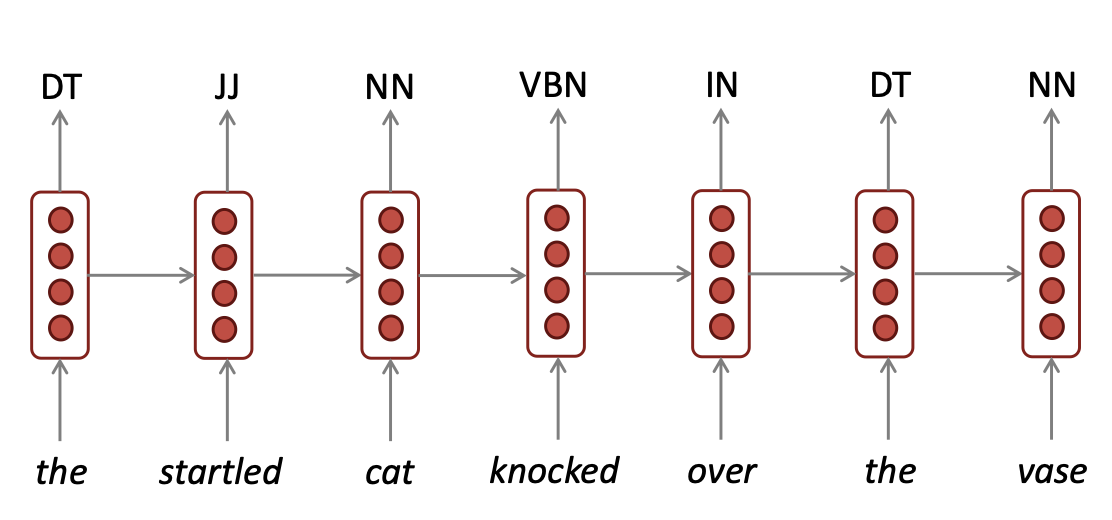
Input이 들어가면서 각 time-step의 출력으로는 품사가 출력됩니다.
1.2 Sentence classification
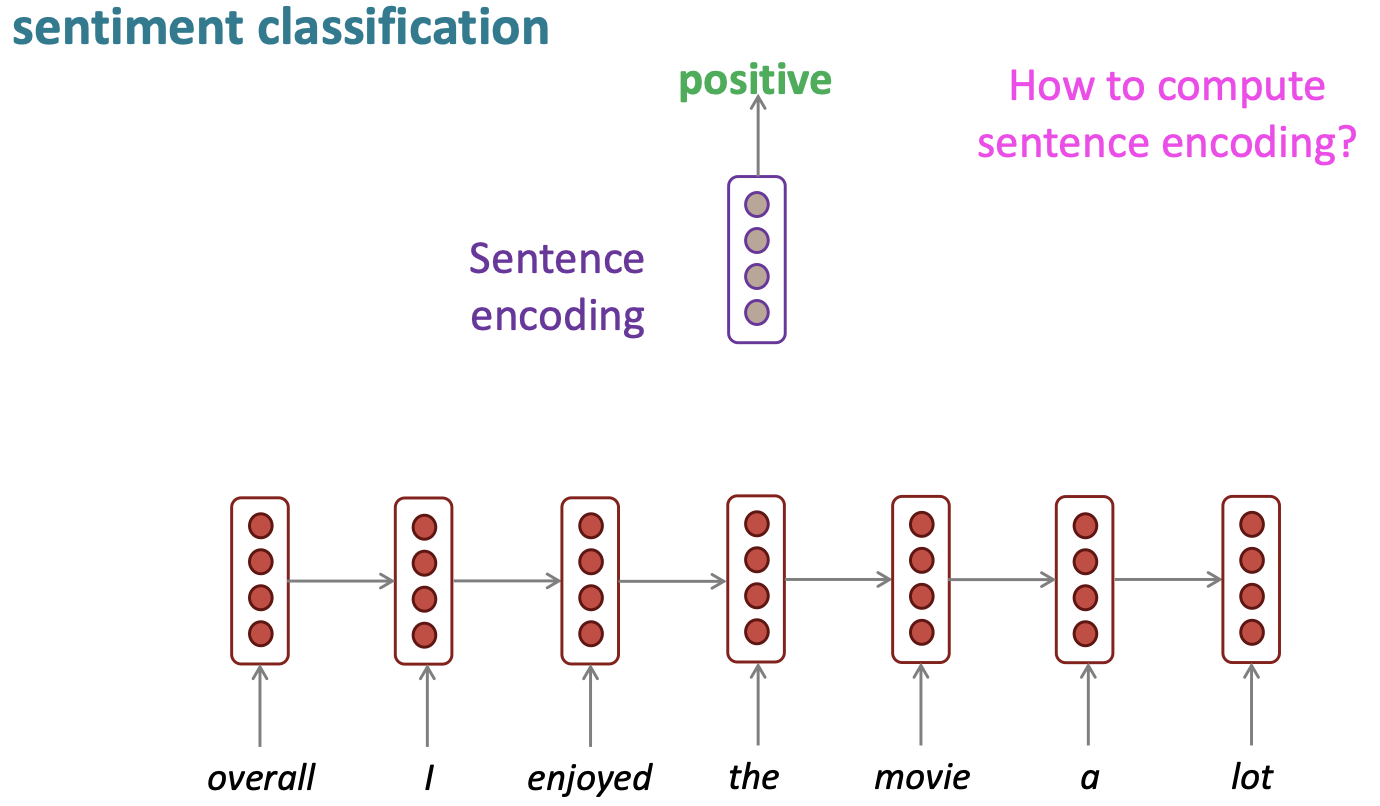
기존 RNN은 input으로 들어온 단어의 embedding을 ㄹ활용하지만 sentence classification task에서는 문장을 표현하기위해 sentence encoding을 활용하고 이를 classification layer로 분류합니다. 또한 마지막 time-step의 hidden state만을 활용하는것이 아닌 각 time-step별 hidden state를 활용하여 성능이 좋았습니다.
1.3 Language encoder module
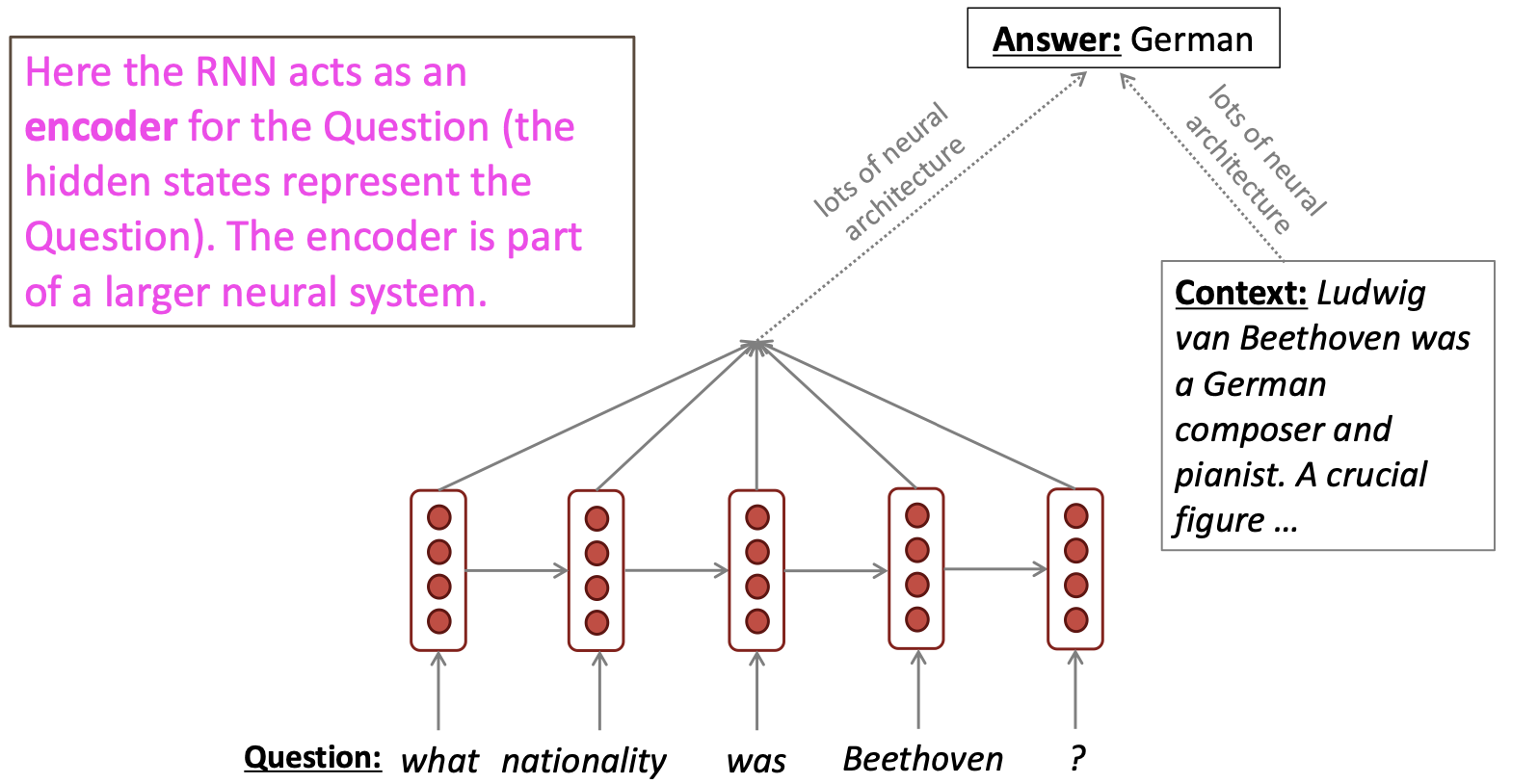
RNN는 input sequence를 encoding하고 출력 된 vector를 이용하여 다른 model input으로 활용하는 task도 수행할 수 있습니다. 이를 통해 question answering과 machine translation뿐만 아닌 여러 다른 task를 수행할 수 있습니다.
1.4 Generate text
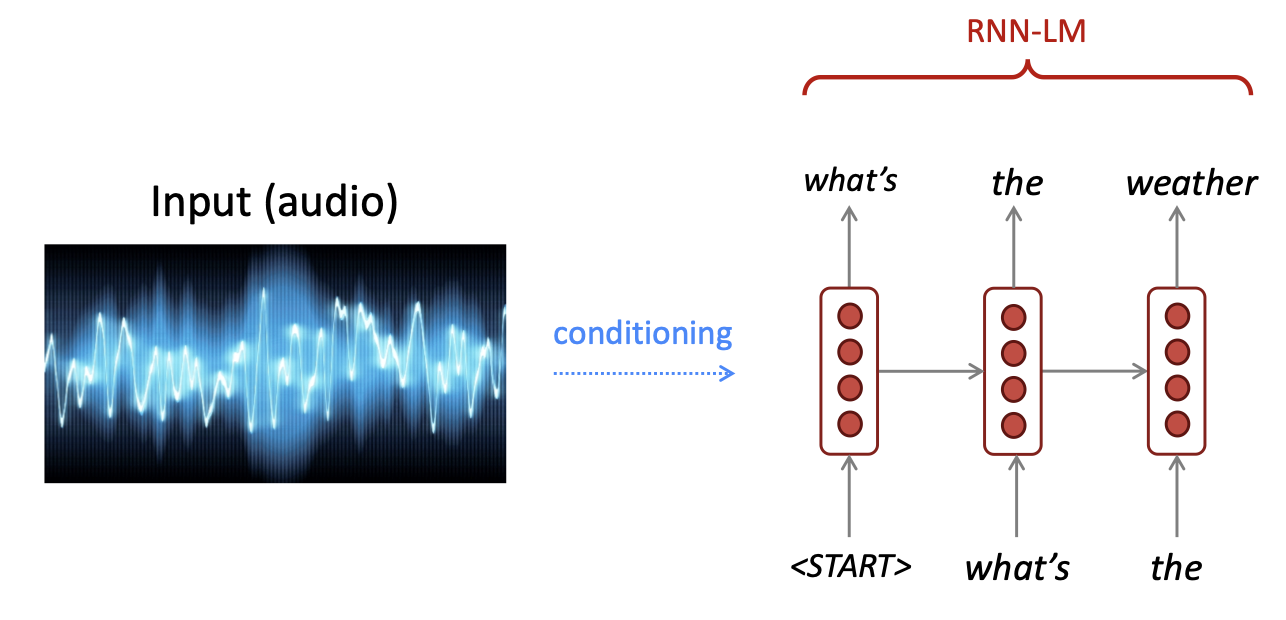
Text가 아닌 input을 원하는 task에 따라 conditioning한 output을 RNN의 input으로 넣어 text를 출력하는 task도 수행 가능합니다.
2. Vanishing and Exploding Gradients
RNN은 각 time-step별로 loss값에 대한 gradient를 chain rule에 의하여 계산합니다. 그러나 chain rule에 의해 gradient가 계속 곱해지면서 폭발하거나 손실되는 문제점을 가지고 있습니다. 또한 input sequence가 길어지면 길어질수록 이 문제점은 더 악화될 수 있습니다.
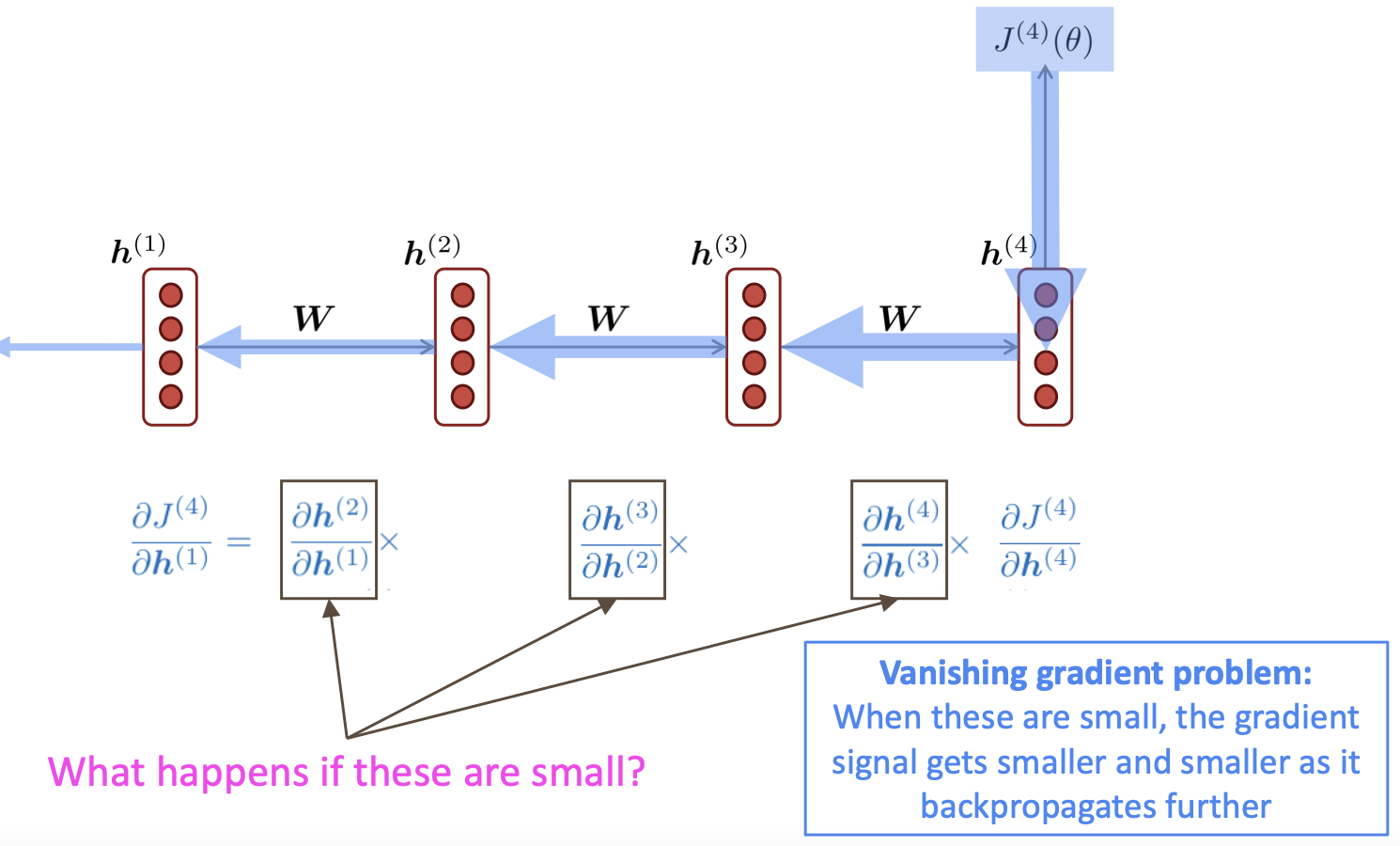
Example
RNN의 t번째 시점의 hidden state는 아래와 같은 수식으로 구할 수 있습니다.
그리고 4번째 time-step의 loss 에 대한 의 gradient는 아래와 같이 구할 수 있습니다.
I번째 시점에서의 loss 에 대한 의 gradient는 아래와 같습니다.
결국 위의 식 i번째 손실값에 대한 j번째 hidden state의 gradient를 표현하면 위와 같고 이 gradient값이 chain rule에 의해 값이 폭발하거나 손실하는지가 중요한 문제입니다.
2.1 Long Term Dependency
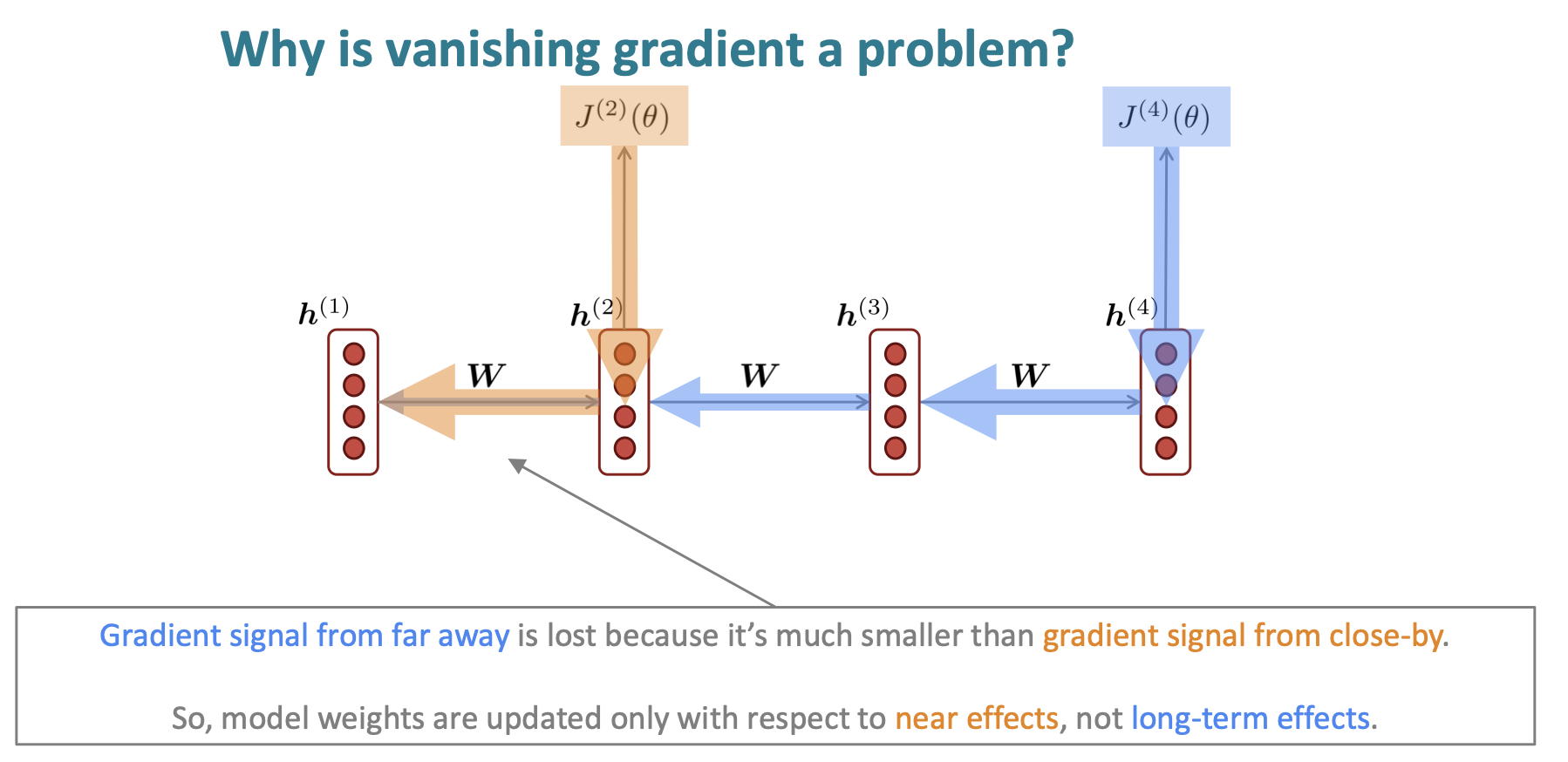
Gradient vanishing이 발생하면 결국에 time-step별로 가까이에 위치한 dependency만 학습되고 멀리위치한 dependency에서는 학습이 잘 되지 않습니다.
반대로 만약 gradient가 exploding되어 너무 커지면 learning rate도 매우 큰 step으로 진행됩니다. 이렇게되면 gradient가 optimum으로 수렴되지 않는 상황이 발생하게 됩니다.
이를 위한 간단한 해결방법으로는 Gradient clipping이 있습니다.
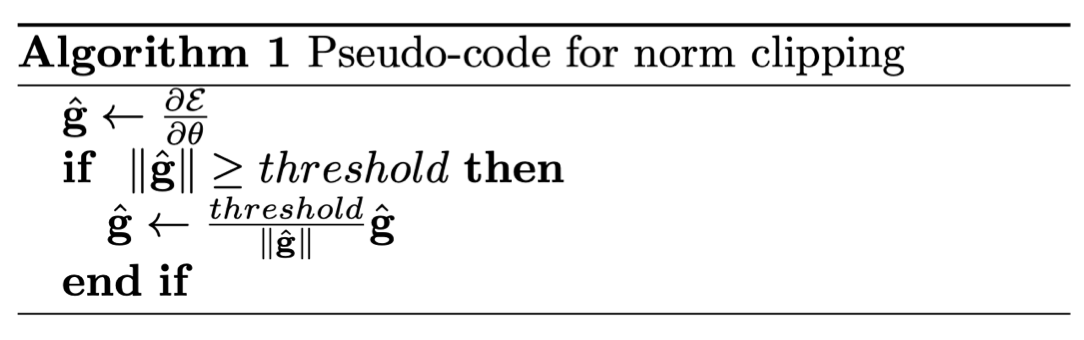
Gradient clipping이란, gradient에 임계치를 설정하여 만약 임계치 이상의 gradient가 update되려고 할 때, 줄여서 같은 방향이지만 더 작은 step로 update하는 알고리즘입니다.
3. Long Short-Term Memory RNNs(LSTM)
RNN의 gradient vanishing 현상으로 인해 발생하는 long-term dependency 문제를 해결하기 위해 RNN에서 memory를 따로 저장하는 cell을 만들어 이전 time step의 data의 정보를 가져오는 model입니다.

LSTM의 주요 방법론은 이전 time step의 정보를 memory cell에 저장해서 모든 시점에서 활용 가능하게 하는것과 현재 시점의 정보를 바탕으로 이전 시점의 정보를 얼마나 잊을지 곱하고, 이 결과에 현재 시점의 정보를 더해서 다음 시점으로 정보를 전달하는 것입니다.
3.1 Forget gate layer
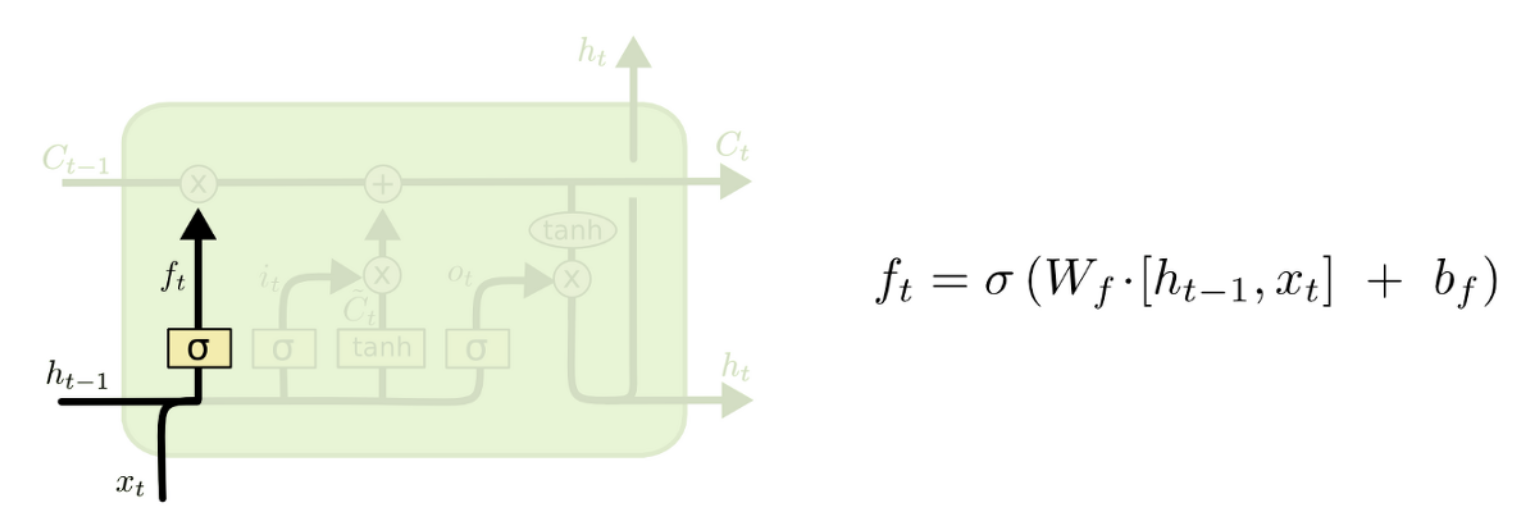
Forget gate는 특정 정보를 잊고 특정 정보를 반영할지를 결정하는 gate입니다. t시점에서 x값과 t-1시점에서의 hidden state를 입력받아 sigmoid activation function을 통해 0부터 1사이의 값을 출력합니다. 만약 출력값이 만약 0에 가깝게 나온다면 정보를 지워버리고 1에 가깝게 나온다면 정보를 많이 반영한다는 의미입니다.
3.2 Input gate layer & Tahn layer
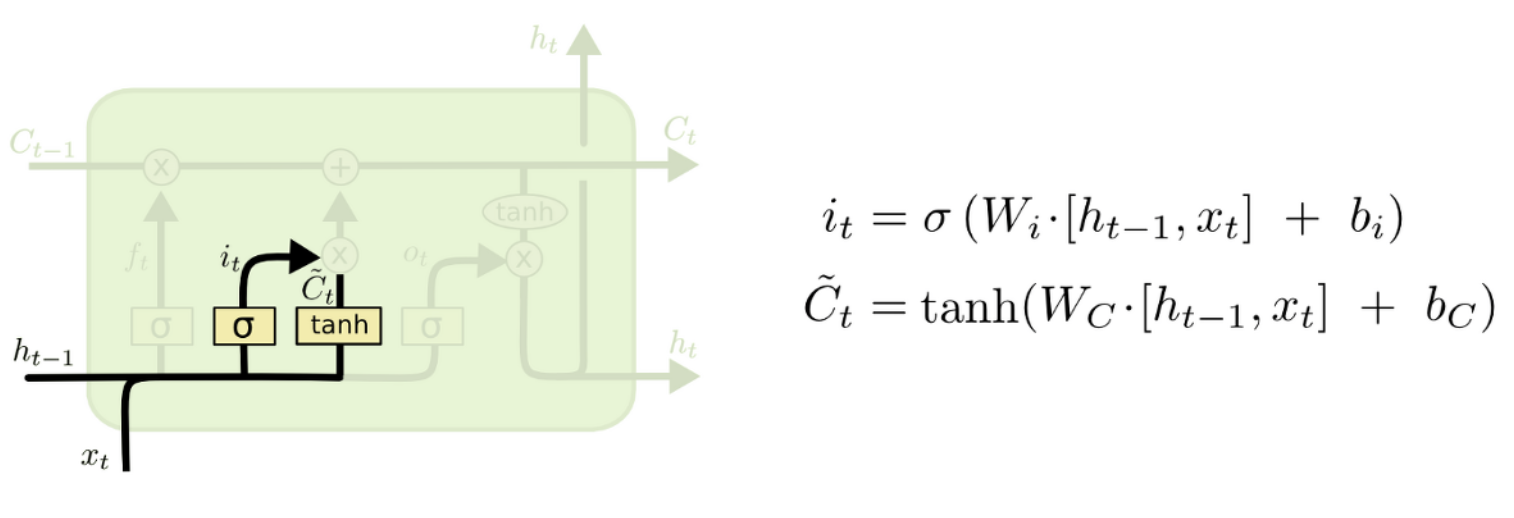
Cell state에 저장할 새로운 정보를 결정하는 gate입니다. Forget gate와 마찬가지로 input으로는 이전 시점의 hidden state와 input x를 받습니다. 여기서 두 단계로 나눠지는데, input gate layer에서는 sigmoid 함수에 의해 0부터 1사이에 값을 출력해서 현재 시점의 정보를 반영할지를 결정합니다. 그리고 update gate에서는 cell state에 추가 될 후보의 vector를 생성하는 layer입니다. 이 두개의 gate에서 output이 곱해짐으로써 현재 시점의 정보를 반영할지를 결정합니다.
3.3 Update Cell state
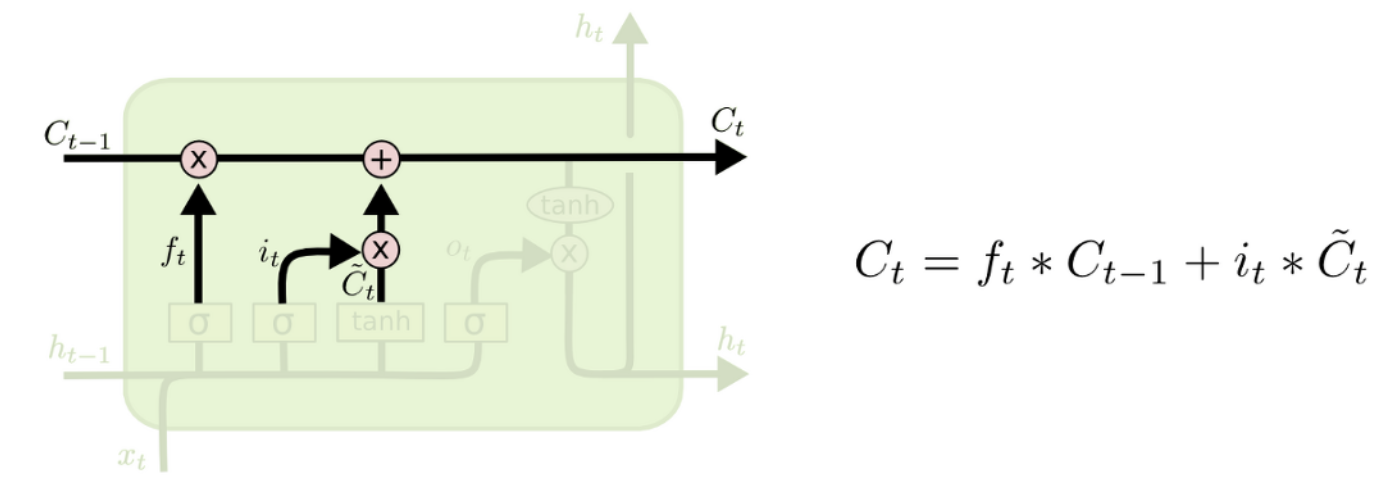
Update cell gate는 forget gate에서 과거의 정보를 삭제할지 유지할것인지에 대한 값과 input gate에서 현재 시점의 값이 반영될지 안될지에 대한 값을 더해서 다음 cell state의 input으로 들어가 update됩니다.
3.4 Output Gate Layer
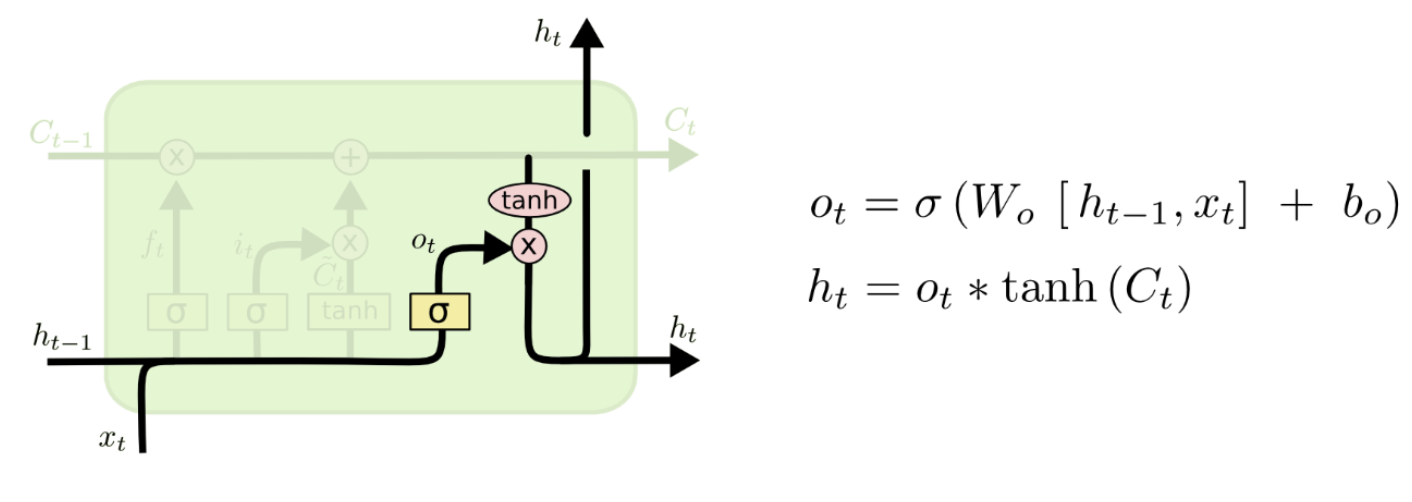
마지막 gate로 output gate layer는 cell state를 통해 output을 생성합니다. 먼저 sigmoid 함수를 통해 0부터 1사이의 값을 출력하고 cell state의 어느 후보를 내보낼지 결정합니다. 그리고 결정 된 cell state가 tahn함수에 들어가서 나온 출력값과 output gate에서 나온 값과 곱해져서 현재 시점의 hidden state를 출력합니다.
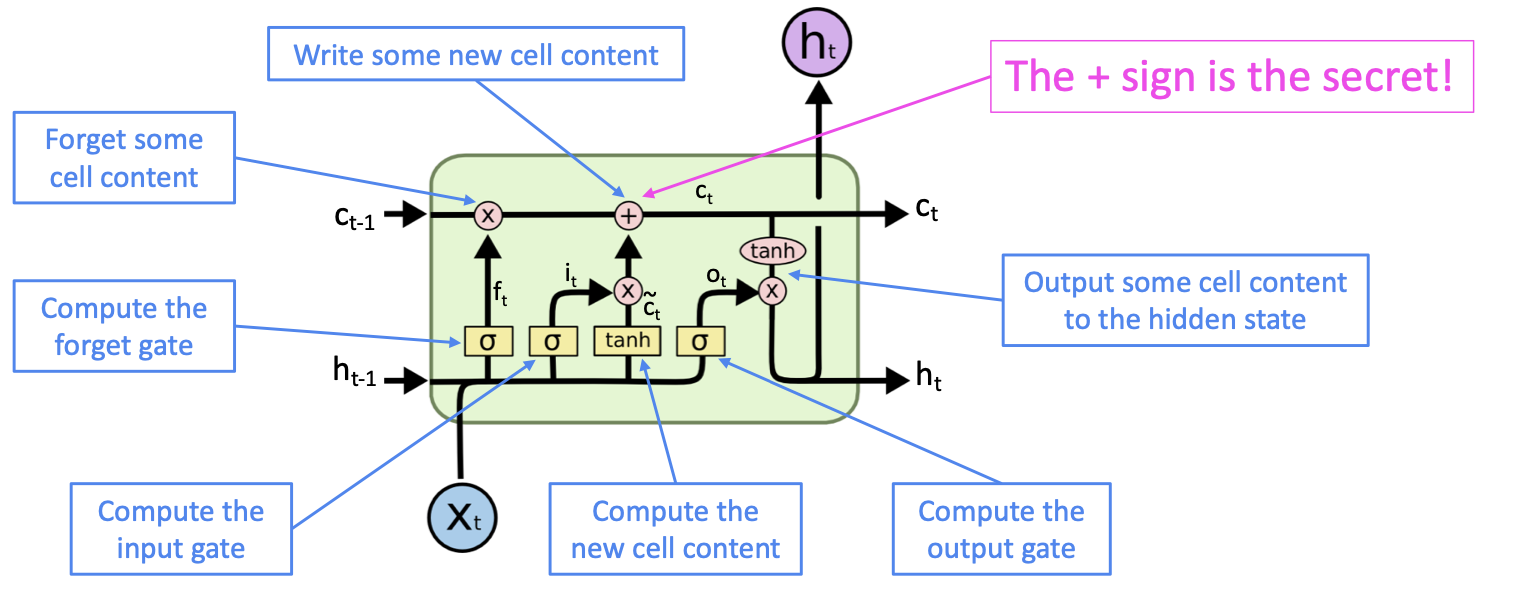
LSTM을 통해 RNN의 한계점인 long-term dependency를 어느정도 극복했지만 완전히 해결했다고 보긴 어렵다고 합니다.
