0. ABSTRACT
- 기존 Masked Language Model(MLM)처럼 input을 masking하여 [MASK] token 대신 generator network를 통해 replace token을 생성하여 해당 token이 생성된 token인지 original인지 예측하는 discriminator model를 학습한다.
- 모든 input token의 판별을 예측하는 model이기 때문에 기존 MLM보다 더 효율적이고 같은 model size, data, compute에서 BERT 및 XLnet과 같은 model보다 우수함.
1. INTRODUCTION
- 기존 Language에서 SOTA를 달성한 model들은 denoising autoencoder방식으로 학습했지만 MLM은 input에서 [MASK]를 씌운 15%의 token들만 학습하기 때문에 계산적인 비용을 낭비함.
- 이에 대한 대안으로 replaced token detection task를 제안, [MASK] token 대신 생성된 replace 단어를 넣어줌으로써 input 값을 corrupt하고 모든 token에 대해서 진짜인지 가짜인지 판별하는 과정을 discrimiator를 통해 pre-training함.
- GAN과 비슷해 보일 수 있지만, generator가 정답과 유사한 token을 생성했을 때, fake가 아닌 real로 사용하고 maximum likelihood로 학습한다는점이 다름.
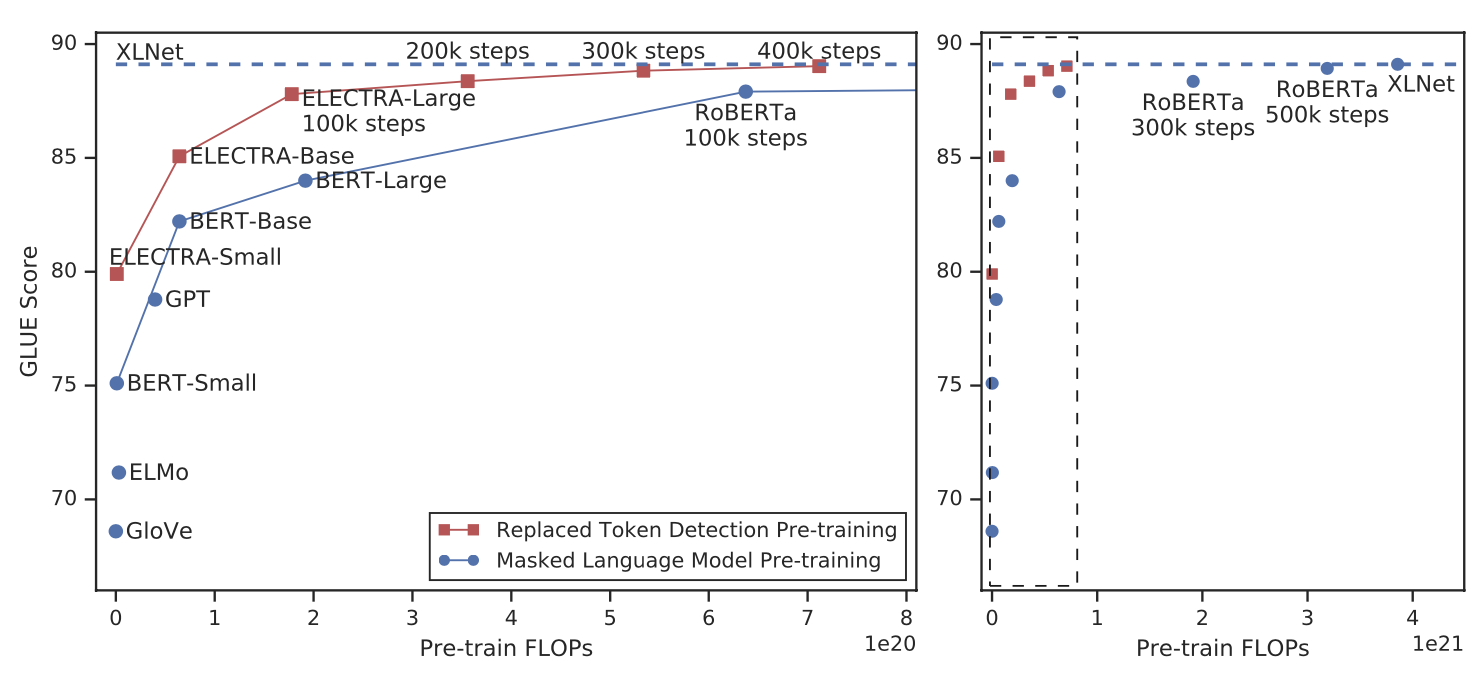
- ELECTRA-Small의 경우 4일만에 학습됨(BERT-Large에 비해 parameter의 개수는 1/20이고 compute는 1/35)
- BERT-small과 비교했을 때, 5 score더 높고 GPT model을 뛰어넘음. RoBERTa의 1/4정도의 compute만 사용했을 때 일치함.
2. Method
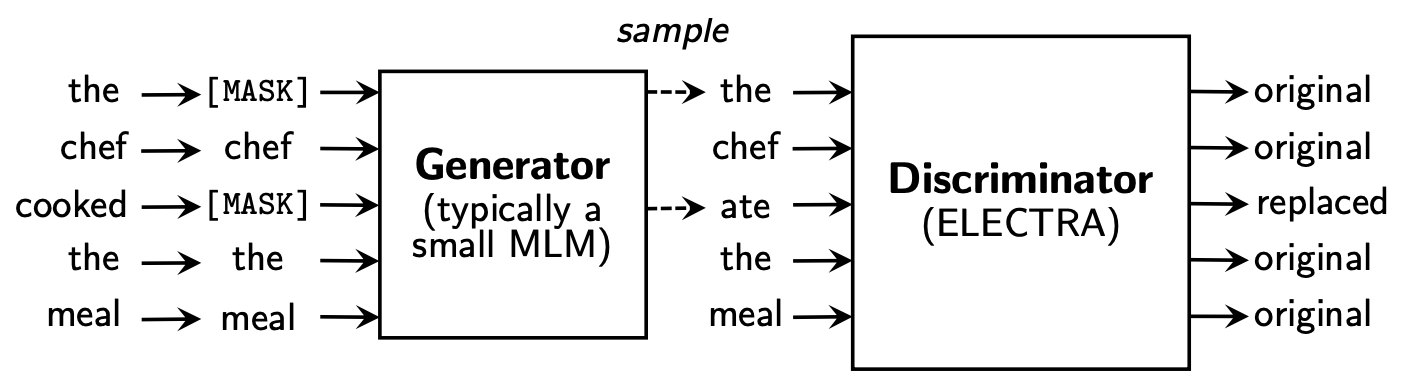
- generator(G)와 discrimiator(D)를 train, 각 network는 transformerexp의 encoder로 구성되어있음.
- [MASK] token 자리에 generator를 이용하여 replace 단어를 생성
- position 에 대해 generator는 softmax layer로 token 를 generation할 확률을 출력.
- 는 token embedding
- position 에 대해 discriminator는 token 가 fake인지, 다시말하면 data distribution이 아닌 generator를 통해 생성된 token인지를 layer를 통해서 예측
-
generator는 MLM을 수행하도록 train
-
input 이 주어질 때, 를 masking 하기 위해 random set of position을 선택
-
선택된 position의 token을 [MASK] token으로 replace.
-
generator는 의 maximum likelihood를 구하도록 train
-
discriminator는 data의 token을 generator로 replace된 token인지 real token인지 구별하도록 train
token을 generator의 sampling을 통하여 replace하여 corrupted 를 생성하고 discriminator는 의 token이 real인지 fake인지 판별하도록 train.
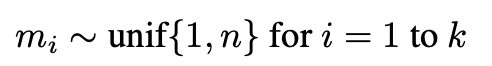
- masking position은 1과 사이의 정수
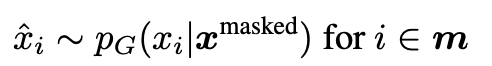
- [MASK] token에 의해 generator에서 추론된 값
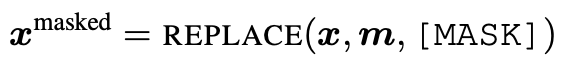
- 이렇게 masking된 input은 위와 같이 표시함.

- generator가 생성한 token으로 replace한 input을 위와 같이 표기.
discrimiator는 이 real인지 fake인지 판별해야한다. 일반적으로 = [0.15], 15%를 masking한다.
Loss 함수는 다음과 같다.
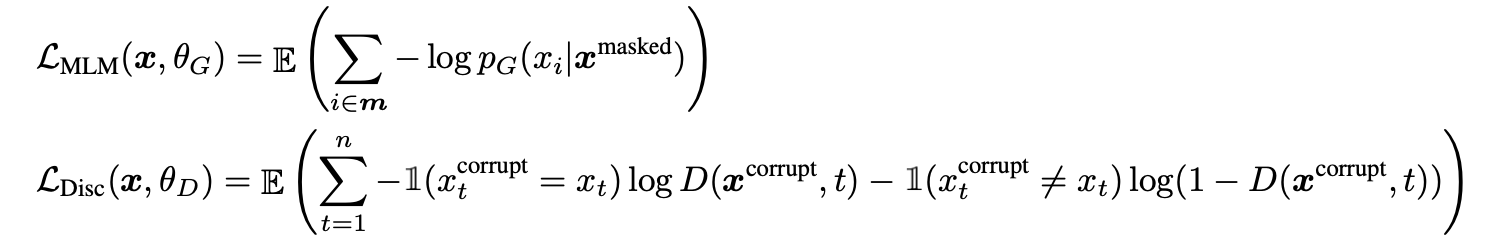
- discriminator loss의 식은 다음과 같이 GAN에서 많이 사용하는 BCE(Binary Cross Entropy) loss를 적용
GAN의 objective function과 비슷해 보이지만 다른점이 있다.
- generation이 token을 생성하면, 그 token은 fake가 아닌 real으로 간주함.
- generation model이 속이려는 방법이 adversarially 하지 않고 maximum likelihood를 통해 학습함. Discriminator의 back-propagation이 generator까지 하지 못함(sampling 때문)
위에서 정의한 두 loss를 하이퍼파라미터 lambda로 가중합한 loss function을 최소하한다.
Pre-training이 끝나면, generator는 더 이상 사용하지 않고 discriminator를 downstream task에 대해 fine-tuning한다.
3. EXPERIMENTS
3.2 Model Extensions
Weight Sharing
- 효율성을 높이기 위해 generator와 discriminator의 weight를 sharing
- generator와 discriminator의 크기가 동일하면 weight sharing이 가능.
- generator에서 input과 output의 token embedding을 tie함.
- small generator가 더 효과적.
- small generator의 경우 token embedding만 sharing
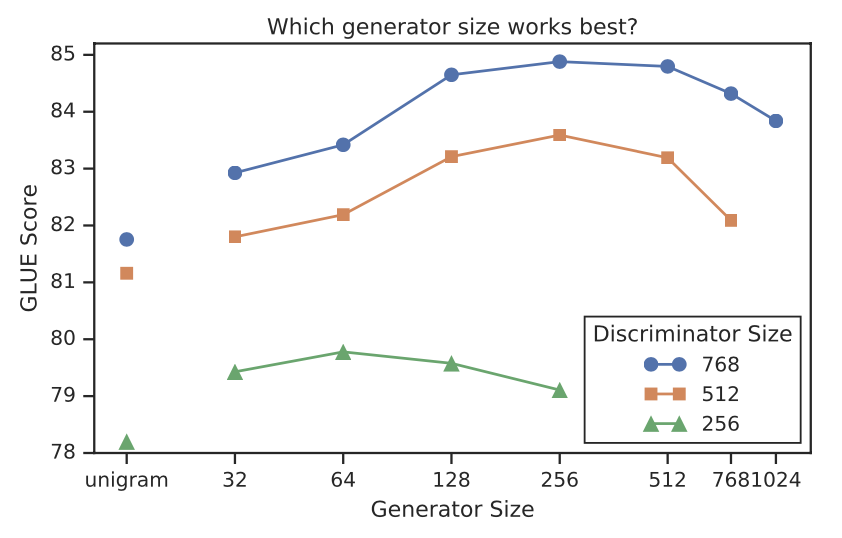
- generator와 discriminator의 크기가 동일할 때, ELECTRA는 MLM보다 약 2배 많은 계산을 수행.
- Hidden dimension에 따른 GLUE score를 살펴보면 generator의 크기를 discriminator의 크기보다 작게 하는것이 성능이 더 좋음.
- 일반적으로, generator의 크기를 discriminator의 1/4 ~ 1/2로 설정할 때 성능이 가장 좋았음.
ELECTRA를 다음과 같은 두가지 단계로 학습했다.
- MLM Loss를 이용해 n_step동안 generator만 학습
- discriminator의 weight를 generator의 weight로 초기화, generator의 weight를 고정하고 discriminator만 n_step 학습
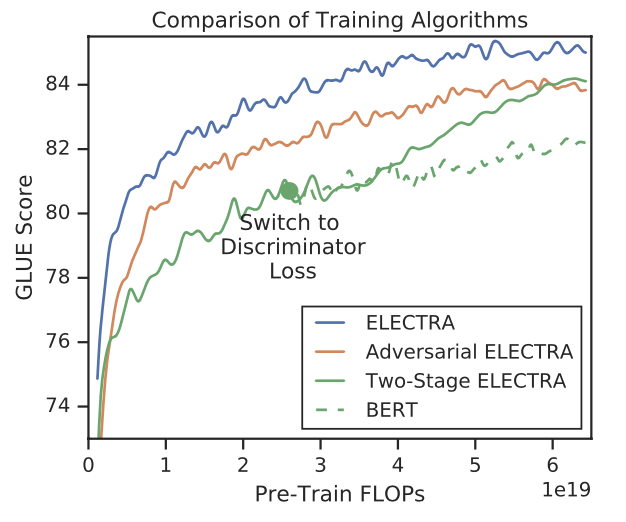
그래프를 보면, generator에서 discriminator로 objective function을 바꿨을 때, GLUE score가 올라간것을 확인할 수 있지만, generator와 discriminator를 같이 학습했을때 보다는 낮았다. Maximum Likelihood가 아닌 GAN과 같은 adversarial training을 한 것도 기존 방법보다 성능이 안좋았다. 모든 접근이 BERT보다 성능이 좋은것을 확인할 수 있다. 본 논문에서는 adversarial
training을 할 때, sample efficiency가 떨어진다고 분석했다.(?)
3.3 Small Models
논문의 주된 purpose는 pre-training의 효율성을 높이는 것이기 때문에, GPU에서 small model을 실험했다. BERT-small은 BERT-base에서 hyper-parameter와 sequence 길이(512 -> 128)를 축소했다. Batch size는 256에서 128로 축소했고 model의 hidden dimension을 768에서 256으로 축소하고 token embedding의 크기도 768에서 128로 축소했다. BERT-small을 150만 step동안 train하였다. ELECTRA는 100만 step을 학습했다.
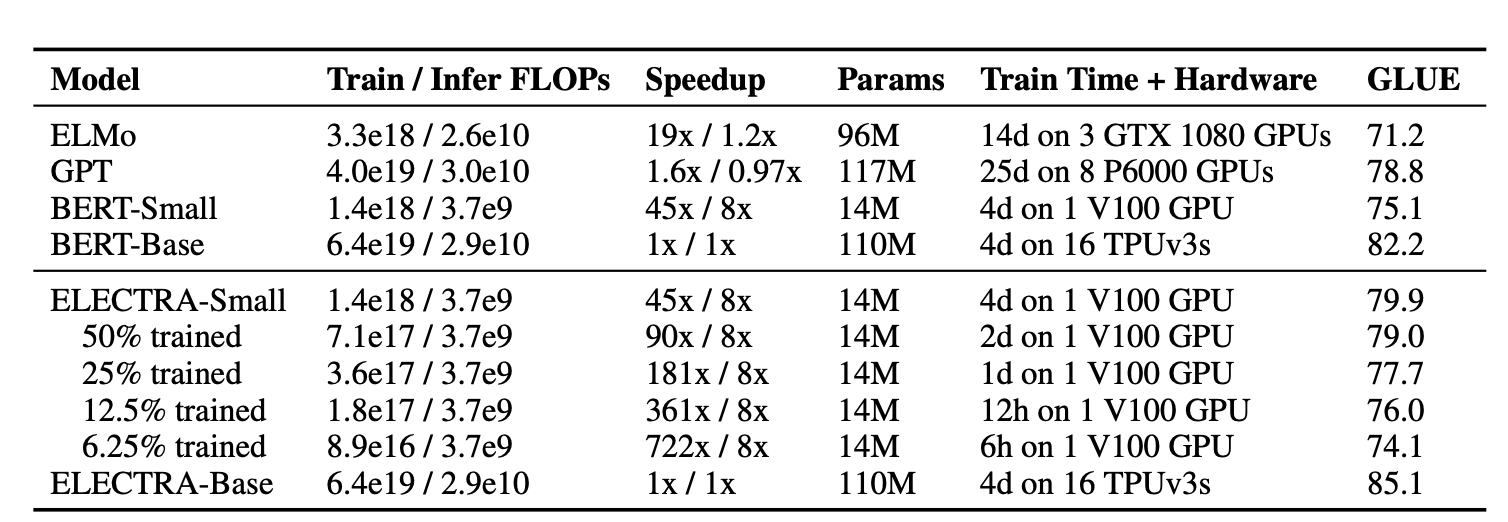
같은 계산량일 때를 비교했을 때, ELECTRA-small이 성능이 더 좋았다.
3.4 Large Models
Pre-training할 때, Replaced Token Dectection 과제가 얼마나 효율적이였는지 분석하기 위해 Large model에 대해서도 실험했다. ELECTRA-large와 BERT-larget와 같은 model 크기를 가지고 더 많이 학습했다. ELECTRA-large를 40만 step동안 train, RoBERTa의 1/4정도이고 RoBERTa와 동일하게 학습한 175만 step을 train. XLNet에서 pretrain한 data로 2048 batch train.
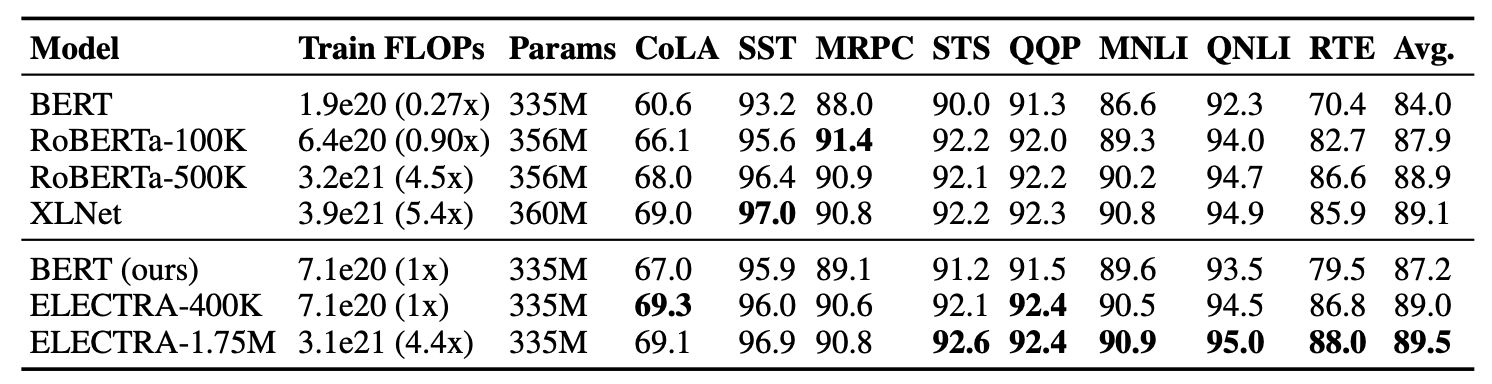
dev_set
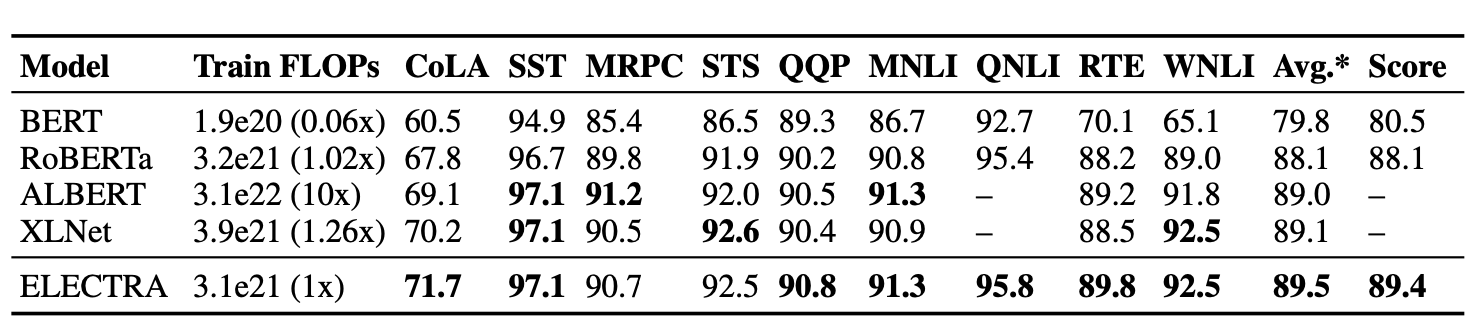
test_set
ELECTRA-400k는 RoBERTa-500k와 XLNet의 1/4 FLOPs으로 비슷한 성능을 보여줬고 더 많이 pre-train한 ELECTRA-1.75M은 더 작은 FLOPs으로 더 좋은 성능을 보여줬다.
3.5 Efficiency Analysis

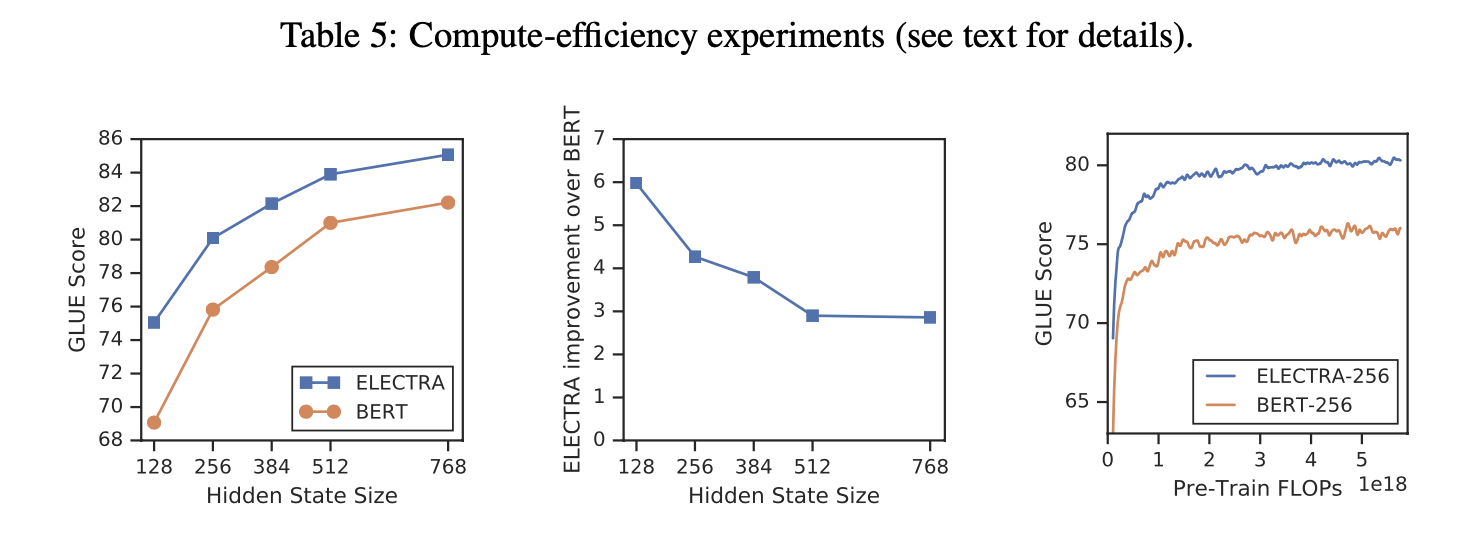
ELECTRA의 성능 향상을 이해하기위해 다른 pre-train obejective와 비교했다.
-
ELECTRA 15% : discriminator loss는 input에서 15%만 masking했다. Token에 대한 학습 효율을 15%와 100%를 비교하기 위해 설정.
-
Replace MLM : discriminator를 MLM으로 train하고 [MASK]로 치환하지 않고 generator가 만든 token으로 치환. Pre-training할때만 사용해서 성능을 비교하기 위해 설정.
-
All-Tokens MLM : Replace MLM과 같은 방식으로 15%가 아닌 모든 token을 generator가 생성한 token으로 치환
4. Conclusion
- 새로운 Self-supervised task로 Replaced Token Detection을 제안
- Generator가 생성한 negative sample을 이용하여 discriminator가 input token과 fake를 구별하도록 학습시킴.
- RTD(Replaced Token Detection)으로 pre-training할 때, compute가 더 효율적이고 성능도 좋음

안녕하세요 질문하나만 드려도될까요?
discriminator에서 sigmoid 함수 안에 있는 w 벡터는 어떤 역할을 하는건지 설명해주실 수 있나요?