FastText는 2017년 페이스북에서 발표한 논문이다.
0. Abstract
Distributional representation을 이용한 Word2Vec은 각 단어의 다른 vector를 할당하여 단어의 형태를 무시한다. 그러므로 OOV와 낮은 빈도수로 등장하는 단어에서는 word representation을 얻을 수 없다. 본 논문에서는 Skipgram을 기반으로 단어를 n-grams vector의 조합으로 표현하는 방법을 제시한다. 9개의 언어들에 대해 단어의 유사도와 inference task를 통해 평가했고 SOTA를 달성했다.
1. Introduction
단어의 learning continuous representations은 오랜 역사를 가지고 있었다. 여러 연구가 있었고 Collobert and Weston은 feed-forward neural network를 통해 word embedding을 학습시키는 것을 제안했다. 더 최근에, Mikolov는 단순한 더 큰 corpus에서도 학습하기 위해서 log-bilinear model을 제안했다.
기존 model은 parameter를 공유하지 않고 구별되는 vector로 단어를 표현했다. 그러나 이런 모델은 내부구조를 무시하여 형태학적으로 복잡한 Turkish or Finnish와 같은 언어에서는 제대로 표현하지 못한다. 그렇기 때문에 문자 수준에서의 정보를 사용해서 형태학적으로 풍부한 언어에 대한 vector를 표현하는것을 고안했다.
본 논문에서는 representation을 학습하기 위해 문자의 n-gram을 학습하고 n-gram vector들을 더했다. Skip-gram으로 학습한 vector에 n-gram vector의 합을 더해주어 model을 확장했다.
3.Model
3.1 General Model
General Model로는 Word2Vec의 skip-gram model을 사용했으며 W개의 단어가 있을 때, 단어의 vector값을 통해 주변단어의 등장확률을 예측하는 방향으로 학습을 진행했다.
: 총 단어의 개수
: 중심단어
: 주변단어
총 단어의 개수가 있고 중심단어가 정해졌을 때, 주변단어가 어떤것이 올 확률이 제일 높은지를 예측한다. 그리고 고유 벡터를 구하여 softmax 함수를 거쳐 확률값을 계산한다.
분자는 중심단어가 주어졌을 때 주벼단어가 올 확률이고 분모는 중심단어가 주어졌을 때 모든 단어들이 등장할 확률의 합이다. 그리고 negative sampling을 통해 학습을 진행.
첫번째 항은 중심단어가 존재할 때, 주변단어가 맞으면 두 vector의 유사도를 높게 만들고, 두번째 항은 실제 주변단어가 아닐경우 두 vector의 유사도를 낮게 만든다.
3.2 Subword model
단어의 내부적인 구조를 더 잘 반영하기 위해 FastText는 n-gram character의 bag으로 표현한다.
예를들어 'where'라는 단어를 3-gram의 bag으로 표현하면 다음과 같다. (단어의 구분을 위해 앞뒤로 <,>가 추가된다.)
where -> < where > -> < wh, whe, her, ere, re>
그리고 special sequence로 단어 자체인 'where'가 추가된다.
where -> < where > -> < wh, whe, her, ere, re>, < where >
그러므로 주변단어와의 score function을 모든 bag of words와의 내적의 합으로 구하게 된다.
: 모든 n-gram의 dictionary size
: 단어 w에서 나올 수 있는 모든 n-gram의 집합
: n-gram의 모든 vector 표현
: postive/negative examples의 내적값
모든 n-gram에 대해 dictionary를 만드는 것은 계샨량이 너무 많기 때문에 본 논문에서는 n-gram의 subset을 1에서 K까지의 정수로 mapping하는 hashing function을 사용했다. Hash 값이 충돌할 수 있지만 vocab의 size를 제어하는데에 효율적이다.
4. Experimental Setup
- C++로 구현
- C-Bow와 Skipgram을 baseline으로 사용
- linear decay of the step size
- dimension은 300
- window size는 1~5 Random으로 사용
- subsampling의 threshold값은
- 5회 이상 등장하는 단어 사용
- Wikipedia dataset 사용
5. Results
5.1 Human similarity judgement
Human judgement와 cosine similarity의 spearman's rank 상관계수를 비교한다.
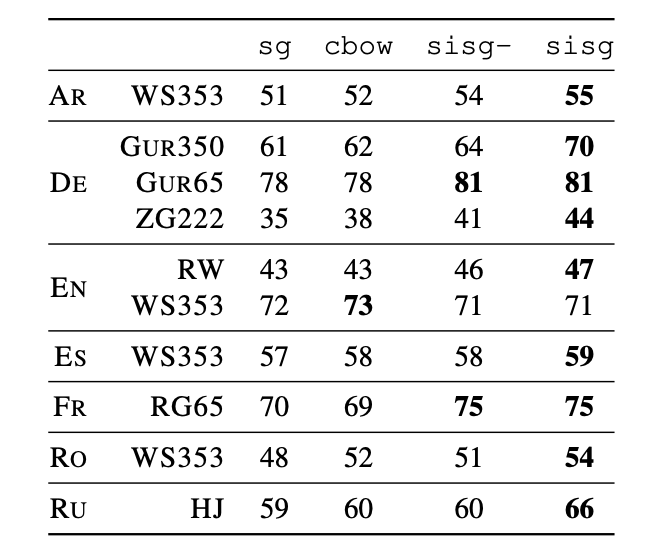
sisg- : Out of vocabulary에 대해 null vector로 표현
sisg(subword information skipgram) : Out of vocabulary도 n-gram vector의 합으로 표현
- sisg가 OOV에 대해 sisg-보다 좋은 성능을 보임
- 형태가 복잡한 언어에서 좋은 성능을 보임
- English WS353은 common word가 많아 n-gram의 효과가 안좋음
5.2 Word analogy tasks
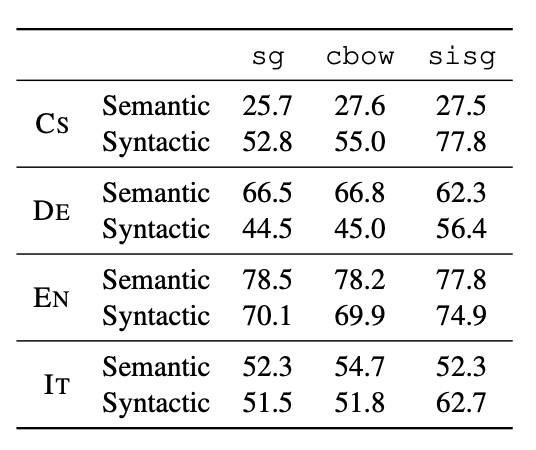
- syntatic(구문 분석)에서는 좋은 성능을 보였지만 semantic(의미 분석)에서는 개선 효과가 없음
- 본 논문에서는 n-grams의 size가 적절히 선택되면 개선할 수있음
5.3 Comparison with morphological representations
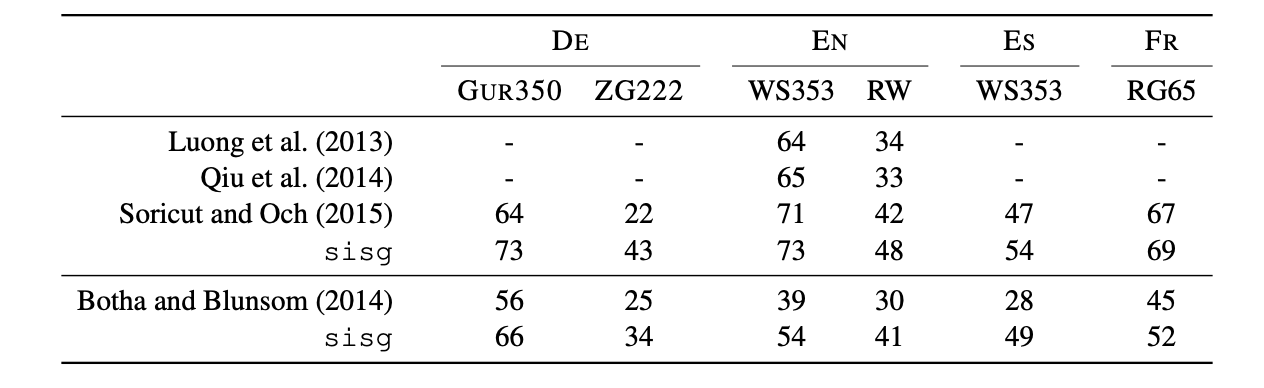
- FastText의 성능이 제일 좋음 -> 다른 model은 합성어의 개별 단어는 training corpus에 등장하지만 합성어 자체가 등장하지 않을 경우 제대로 modeling을 할 수 없기 때문에
5.4 Effect of the size of the training data
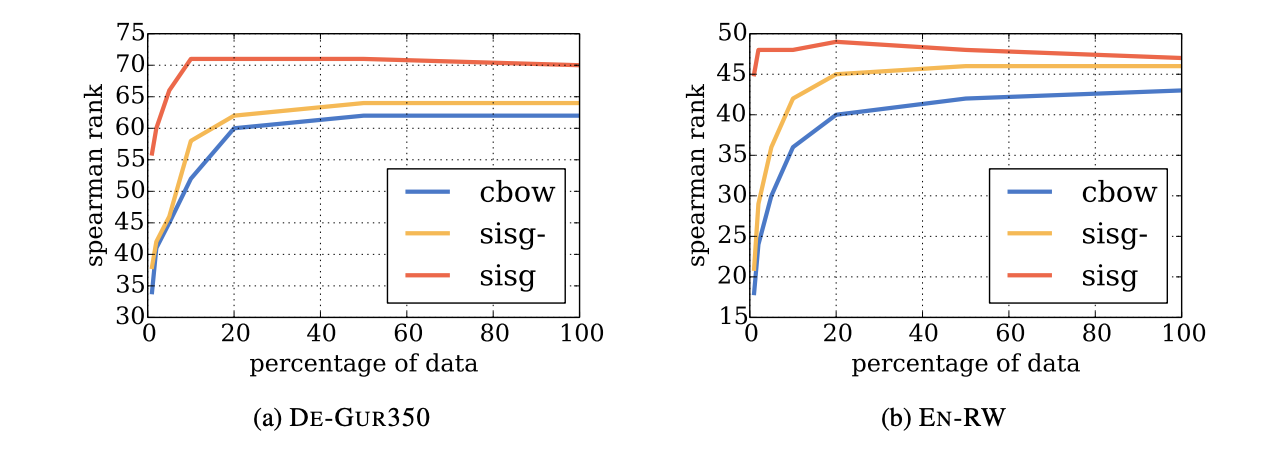
- 모든 크기에서 sisg가 성능이 제일 좋음
- dataset의 크기가 성능 증가의 항상 비례하지 않음 -> scalability
- sisg는 적은 dataset으로 좋은 성능이 나옴
5.5 Effect of the size of n-grams
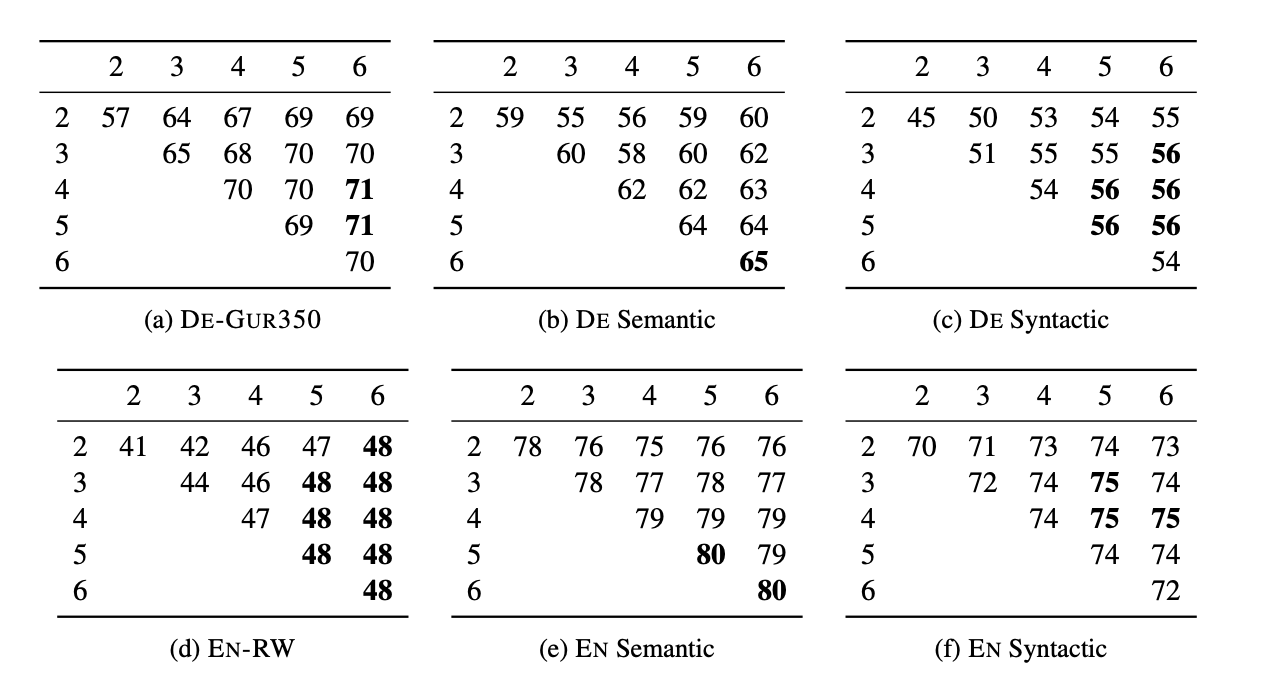
- n이 3 이상, 5와 6이하에서 가장 좋은 성능이 나옴
- n-gram 생성시 단어 앞뒤로 '<', '>'가 붙여지기 때문에 bi-gram은 의미가 없음
- test data의 scarcity를 고려하면 적절한 n 값이 필요
5.6 Language Modeling
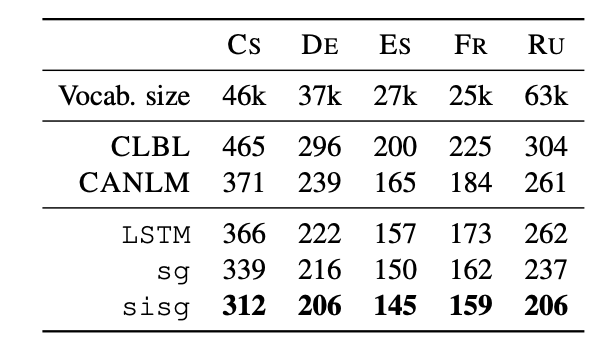
sg : LSTM + Skipgram
sisg : LSTM + n-gram + SKipgram
- sisg가 성능이 제일 좋음
- 형태학적으로 풍부한 언어일수록 성능이 좋음
6. Qualitative analysis
6.1 Nearest neighbors
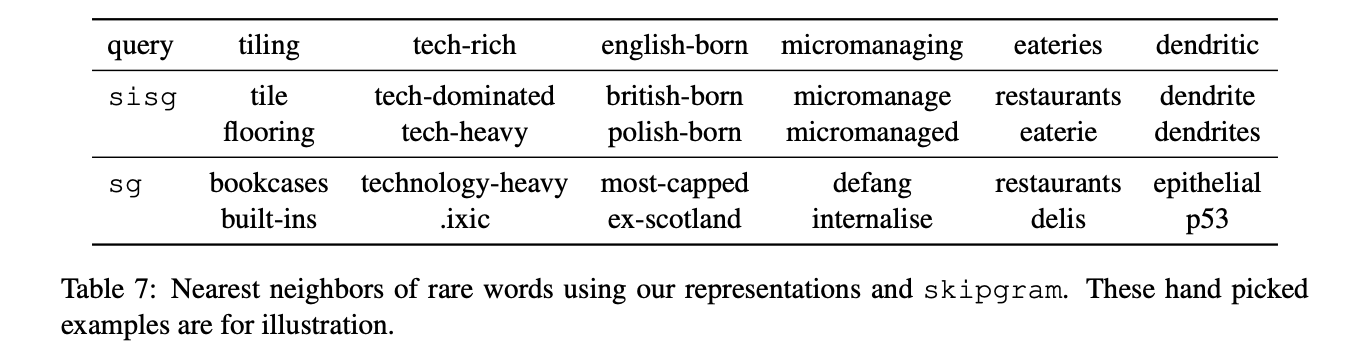
cosine simlarity를 이용해 가장 유사한 단어 2개를 뽑았을 때 sisg가 더 잘 찾아낸다.
6.2 Nearest neighbors

n-gram이 알맞은 형태소를 잘찾은것을 확인할 수 있다.
7. Conclusion
기존 Skipgram은 언어의 구조적인 특징을 반영하지 못한다는 단점을 가지고 있다. 이를 개선하기 위해 FastText는 형태적인 정보를 얻기 위해 n-gram 단위로 subwords를 나누어 분석했다. 기존 Word2Vec보다 빠르게 훈련할 수 있고 성능도 더 좋았다.
