0. Abstract
최근에 음악을 알고리즘, 딥러닝 모델을 사용하여 생성하는것에 직면했다. 본 논문에서는 AI와 인간의 음악을 작곡하는데에 있어 관계를 찾는것을 목표로 하고 있다.
1. Introduction
음악은 기본적으로 피치와 리듬의 반복으로 이루어져있다. 그리고 음악을 생성하는데 있어 전에는 읽어보지 못했던 새로운 여러 문장을 읽는것과 같은 수준의 창의성이 필요하다.
음악을 작곡하는 영역은 MIR에서 중요한 주제이다. 음악을 작곡하는데에는 많은 subtask가 존재한다.
- 멜로디 생성
- 멀티트랙, 다중악기 생성
- style transfer
- harmonization
본 논문에서는 이러한 요소들은 AI와 딥러닝을 베이스로한 다양한 기술의 관점을 담고있다고 한다.
1.1 From Algorithmic Composition to Deep Learning
인공지능을 통해 음악을 작곡하는데 있어 발전 과정을 서술하고 있다. 1980년대를 기점으로 등장하기 시작했는데, EMI와 같은 방법이 등장했다. 그리고 2000년대 후반에 David Cope가 Markov chains으로 문법 기반의 자동 음악 작곡을 구성했고 이러한 유형의 작곡은 고정된 순서로 따라야 하는 통제된 절차로 구성되어 있다. 그러나 이러한 방법은 Harmonize Melodies를 다양한 스타일로 생성할 수 있으나, 일반화 부족과 직접 rule-based를 통해 작업해야하므로 딥러닝 모델과 비교해서 좋지않은 성능을 보여준다.
1980년대부터 2000년대까지 신경망을 기반으로한 음악 생성 모델이 연구되기 시작했다. NLP와 computer vision에서 좋은 성능을 보인 NN architectures가 사용되었고 pre-trained된 모델도 사용될 가능성을 보여줬다. 오늘날 음악 생성은 transformer 기반의 모델이 등장했으며 이는 음악을 하나의 언어라고 간주할 수 있다.
1.2 Neural Network Architectures for Music Composition with Deep Learning
VAE(Variational Auto-Encoders)
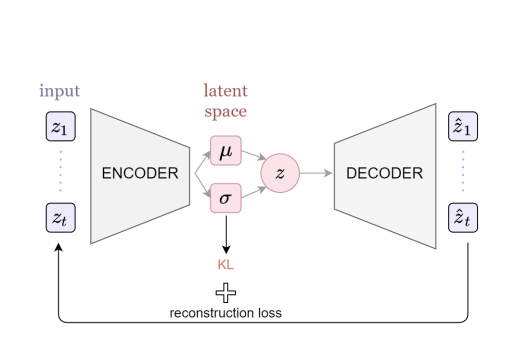
VAE는 generative model의 하나로써, input과 output을 같게 만드는것을 통해 의미있는 latent space를 만드는 auto-encoder와 비슷하게 encoder와 decoder를 활용하여 latente space로부터 원하는 output을 decoding함으로써 data generation을 하는 model이다.
GANs(Generative Adversarial Networks)
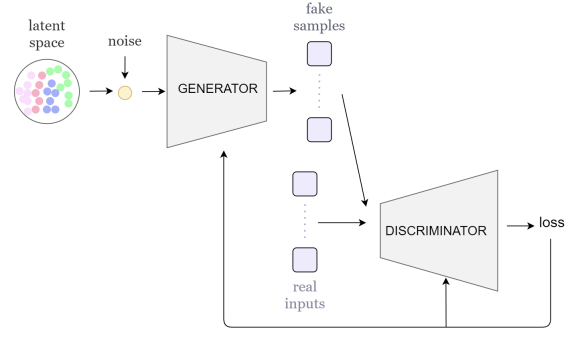
데이터 분포에서 sampling한것과 같은 새로운 데이터를 만드는 generator network와 이를 진짜인지 아닌지 구분하는 discriminator network를 adversarial learning을 통해 학습을 진행하는 model이다.
Transformer
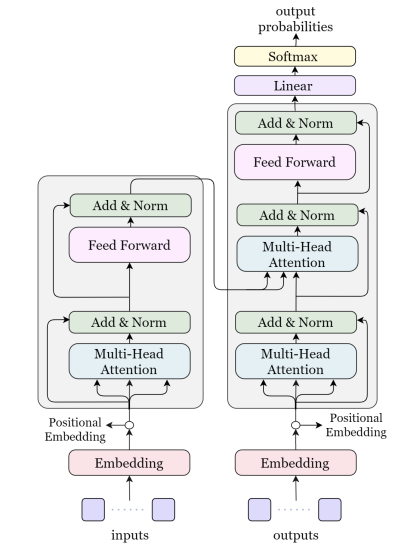
Encoder와 decoder를 attenation mechanism을 통해 연결한 model.
2.The Music Composition Process
본 논문에서는 글을 적는 task와 음악을 생성하는 task를 비슷하다고 얘기하고 있다. 그리고 음악은 장르마다 각각 다른 작곡방식을 가지고 있다.
-
Classical music : 하나 혹은 두개 bar로 불리우는 motif로 시작하고 melody와 music pharse로 발전시켰다.
-
Pop/Jazz : 일반적으로 코드 진행을 통해 작곡을 하거나 즉흥적인 멜로디로 발전
그리고 작곡은 멜로디와 반주, 두가지로 나누어서 구성되어있다.
멜로디는 다른 주파수를 가진 다양한 악기를 통해 구성되어 있고 반주는 깊고 구조화된 느낌을 살려준다. 그리고 음악은 두가지 차원으로 볼 수 있는데, 이는 시간과 하모니이다.
Time
- notes의 duration과 rhythm으로 구성
- 가로축
- low-level -> notes는 bar라는 단위로 구성되거나 측정할 수 있음
- high-level -> 어덜개보다 많은 bar = phrase로 구성된 sections
Harmony
- notes의 value와 pitch로 구성
- 세로축
- low-level -> note 단위
- high-level -> chord (time-dimension과 dependency함.) -> 화음 ex) C-Major, Dm(minor)
4. Music Elements
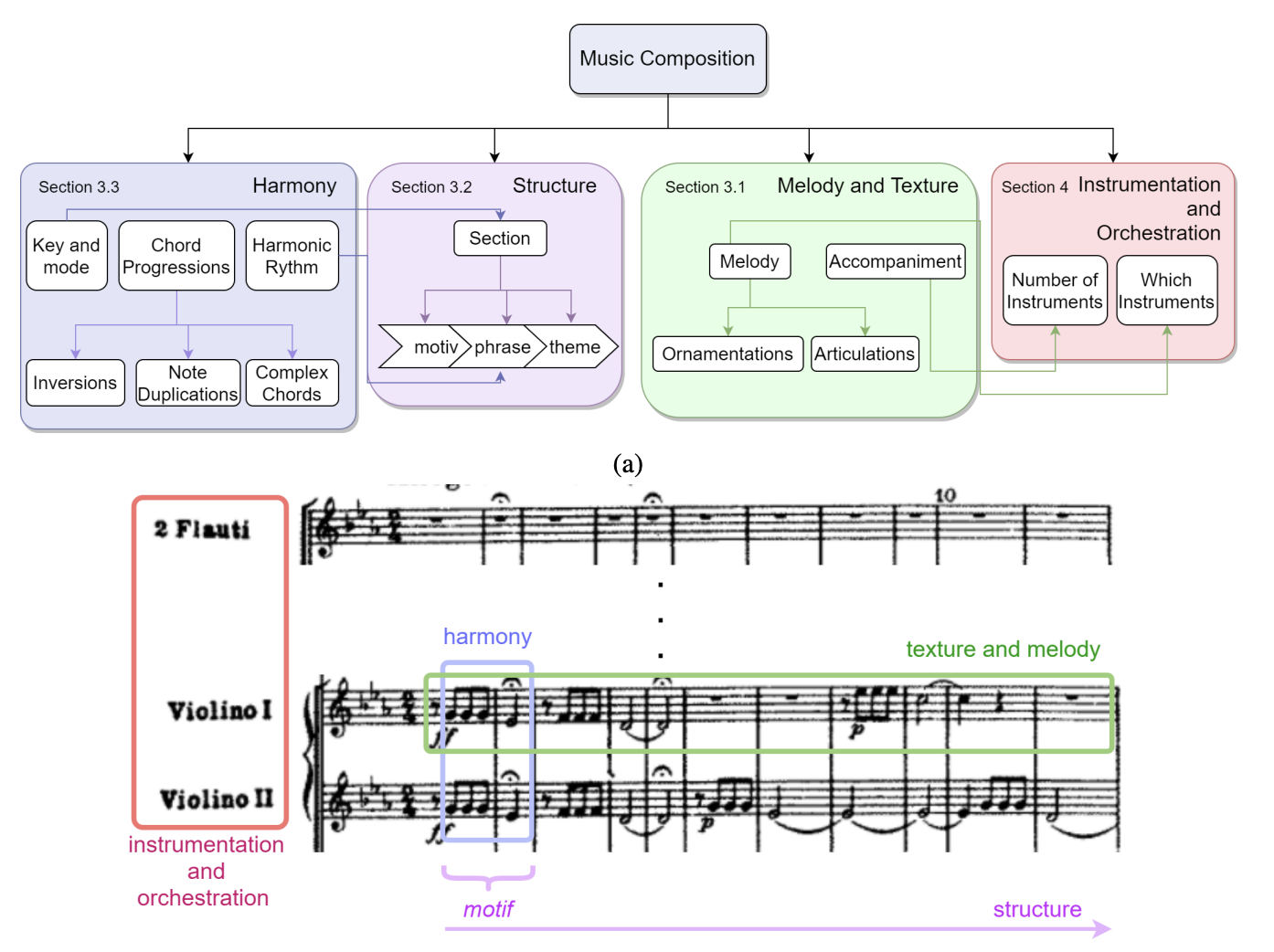
Harmony(화성)
- chord의 연속으로 이루어진 notes의 중첩
- low-level : chord-level
- high-level : key -> ex) 노래가 만약 C key라고 한다면 노래의 음들은 대부분 C-Major chord안에서만 등장
Music Form or Structure
- 가장 작은 단위는 motif(음악 주제를 구성하는 단위) -> phrase(motif가 모인것, 숨을 쉬는 마디라고 함) -> sections(combination of phrase) -> composition(concatenation of sections)
Melody and Textures
- Textures : Music piece가 하나의 작품으로 결합된것
- Melody : 단선율, 다선율의 notes
Instrumentation and Orchestration
- Instrumentation : track단위로, 악기 조합에 초점
- Orchestration : 멜로디 배분에 초점
5. Melody Generation
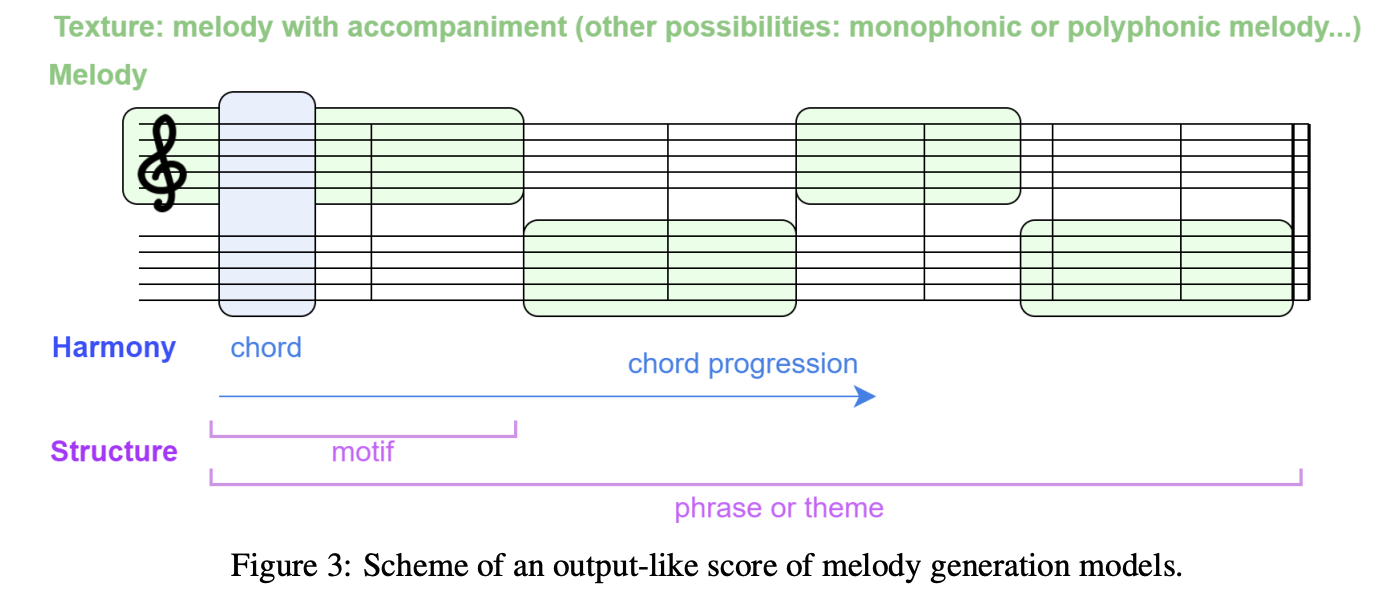
멜로디는 notes의 sequence로 특정 리듬이 미적으로 정렬되있는것을 의미한다. 멜로디는 단선율, 다선율이 될 수 있으며, 같은 시간대에 연주되는 notes의 수가 다른것을 의미한다. 멜로디 생성은 현재 인공지능으로 음악을 작곡하는데 있어 중요한 부분이고 여러 모델이 연구되고 있다.
5.1 Deep Learning Models for Melody Generation: From Motifs to Melodic Phrases
- 초기 단계는 motif와 chord progression으로 시작되어 점차 phrase와 melody로 이어짐.
- 초반에는 딥러닝을 통해 짧은 시간대의 notes sequence를 생성했으며(RNN을 통해) 점차 긴 시간대의 음악을 작곡하게 됨.
- 좋은 성능을 갖기위해 생성모델을 도입하기 시작했음.
- 현재 가장 좋은 성능을 보이는 모델 중 MusicVAE가 있음(1.5백만개의 데이터를 통해 학습)
- 또한 transformer 기반으로 한 Music Transformer와 MuseNet이 등장하여 더 긴 Melody를 생성함.
- 그러나 더 긴 sequence의 멜로디를 생성하면 랜덤하게 생성됨
- TransformerVAE, Piano Tree와 같이 모델을 섞거나 머신러닝을 합친 모델이 등장하여 더 긴 멜로디를 생성함.
- 최근 가장 성능이 좋은 모델은 Denoising Diffusion Probabilistic Models(DDPMs)을 기반으로 한 모델. 64 마디의 곡 생성 가능함.
5.2 Structure Awarness
멜로디는 그룹을 지어 섹션이 되고 이는 작곡에서 있어 근본적인 역할을 한다. 이러한 섹션은 장르에 따라 다양한 역할을 갖는다.
- Pop or Trap genres : chorus, verse
- Classic : Exposition, development, recapitulation
또한 section은 ABAB형태를 가지기도 한다.
딥러닝 모델을 기반으로 Self-Similarity constrain을 통해 구조화된 음악을 생성하려고 했다. C-RBM(Convolutional Restricted Boltzmann Machine)을 통해 음악을 생성하고 Self-Similarity 제약조건을 통해 템플릿을 만들어 학습과 생성을 진행했다. 이러한 작업은 작곡가가 작곡을 하는 과정에 있어서 절차를 따르는것과 생성된 음악이 템플릿에 맞춰져있는것과 비슷하다. 새로운 딥러닝 모델은 현재 end-to-end에 맞춰져있고 템플릿 없이 생성하려고 시도하고 있다.
5.3 Harmony and Melody Conditioning
기본적인 딥러닝 모델로 생성된 멜로디의 harmony를 잘 분석할 수 없는데, 그 이유는 서로 다른 section으로 구성되어 있지 않고 section과 section 사이에 존재하는 cadences or bridges를 구성하고 있지 않기 때문이다. 그러나transformer model을 사용하면 다선율의 melody를 작곡할 수 있다. 이 모델을 사용할때, 우리는 특정 멜로디가 피아노로 작곡되었는지, 다른 악기로 작곡되었는지 명시해야한다.
그리고 멜로디의 harmonization은 멜로디를 고려하여 수반된다. 이러한 화음은 악기와 track에 상관없는 코드 화음일 수 있고 multi-track 화음은 특정 악기와 연관되어있다. 멜로디에 화음을 붙이는 작업은 처음에 HMM model에서 RNN으로 넘어가고 있다. 또한, multi-track 화음은 GAN을 기반으로 한 model이 좋은 성능을 보여주고 있다. ChordAL과 같이 코드 반주에서 멜로디를 만들어 내는 end-to-end model에 대한 연구가 진행되고 있다.
5.4 Genre Transformation with Style Transfer
음악의 스타일과 장르는 소리를 디자인하는 음악의 이론에 범주하고 있다. 보통 스타일 변환은 음악의 음의 pitch를 올리거나 새로운 악기를 추가하는 등의 변환이 존재한다.
컴퓨터를 기반으로한 음악 생성에서 스타일을 변환하는 가장 공통적인 방법은 스타일의 embedding을 얻어 사용하거나 feature vector를 통해 새로운 음악을 생성하는 것이다. 처음으로 스타일 변환을 사용한 음악 생성은 MIDI-VAE이다. MIDI-VAE는 latent space에 style(pitch, dynamics, instrument feature의 조합)을 encode하여 새로운 다선율 음악을 생성하는 모델이다. Style-transfer는 전이 학습에서도 성과를 이루었다. 예를 들어, Lakh MIDI dataset을 사전학습하여 urban 스타일의 음악을 생성하는 전이 학습이 가능하다.
6 Instrumentation and Orchestration
앞서 말했듯이, instrumentation and orchestration(기악과 편곡)은 음악을 구성하는데 있어 필수적인 요소이다. 기악은 비슷한 악기들의 앙상블을 조합하는 방식이며 편곡은 비슷하거나 다르게 작성된 section을 조합하거나 선택하는 방식이다.
6.1 From Polyphonic to Multi-Instrument Music Generation
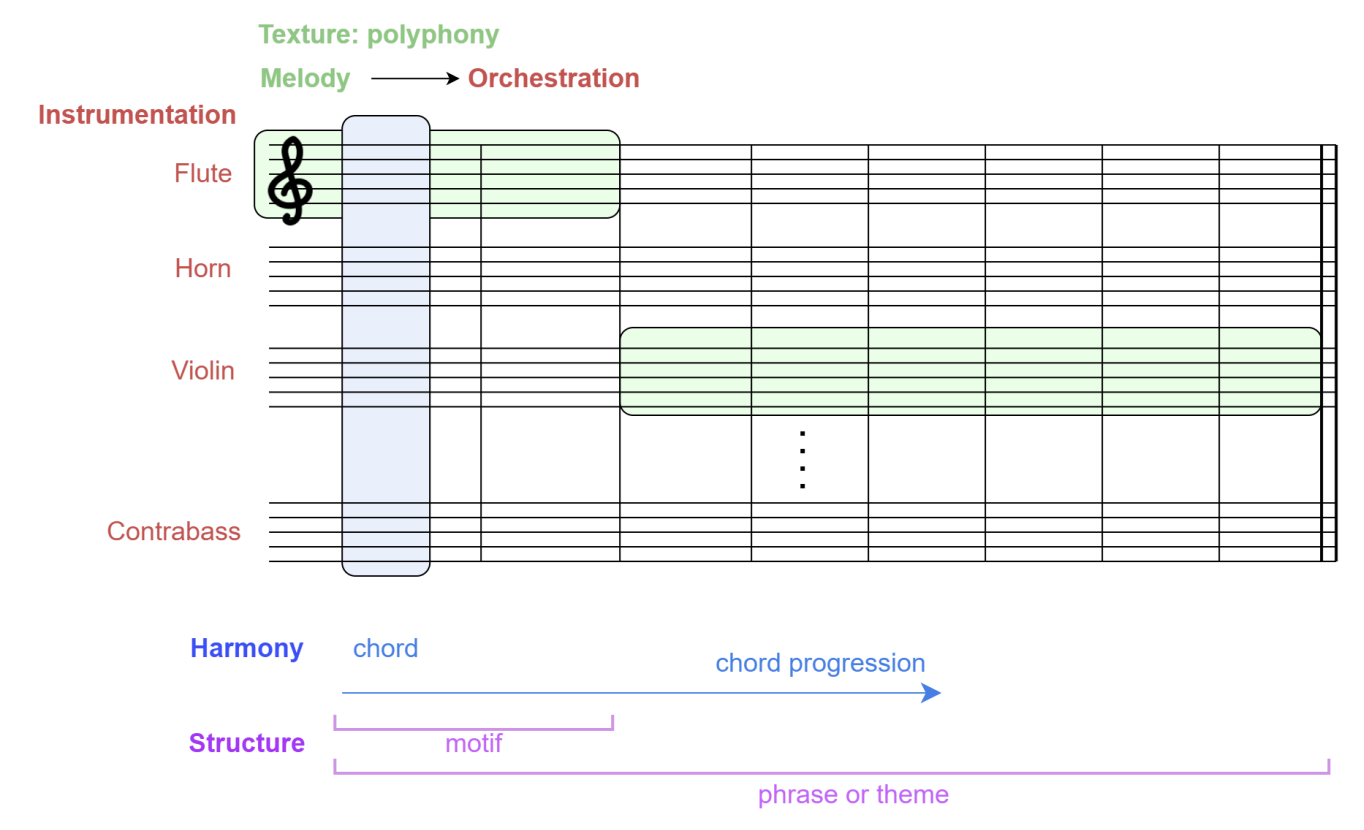
컴퓨터를 기반으로한 작곡에서 우리는 multi-instrument multi-track music에서 기악과 편곡의 컨셉을 그룹지을 수 있다. 그러나 딥러닝을 기반으로한 모델에서는 multi-instrument의 컨셉을 알 수 없다. Multi-instrument를 활용한 딥러닝 모델은 하나의 악기 이상으로 다선율의 음악을 생성할 수 있지만, 생성된 음악이 동일한 harmonic progression을 따를 수 있을까?
위의 그림을 통해서 다선율의 음악 생성은 특정한 하모니로 음악을 작곡할 수 있다. 그러나 앙상블 안에서 얼마나 많고 어떠한 악기를 사용했는지 결정하는것과 멜로디와 화음을 어떻게 나눌것인지는 아직 해결되지 않았다.
6.2 Multi-Instrument Generation from Scratch
Multi-track 음악을 생성하는 모델은 최근에 제안되고 있다. 이전 몇몇 모델은 드럼을 통해 멜로디와 코드를 생성했었다.
음악 생성에서 가장 많이 사용되는 모델은 GANs와 VAEs이다. 가장 처음, 잘 알려진 model은 MuseGAN으로 2017년에 등장했다. 그 다음 더 많은 model들이 multi-instrument 생성 task를 수행했고, 2020년에 autoencoder를 사용한 MusAE가 등장했다. 최근에는 transformer를 기반으로한 모델도 등장했다. (Music Transformer)
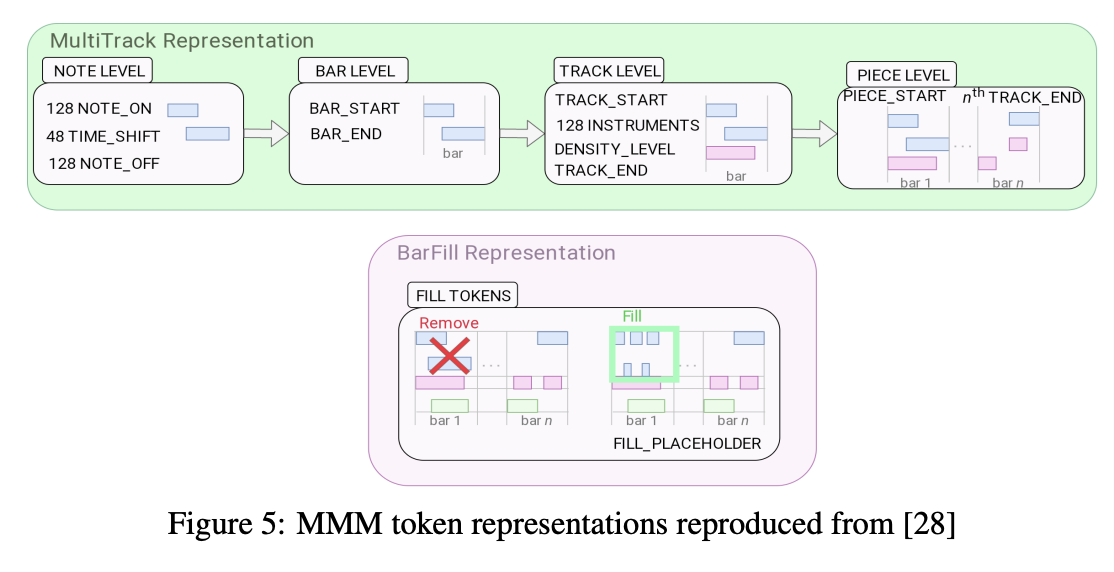
그리고 2020년 Conditional Multi-Track Music Generation model(MMM)이 등장했는데, 이 모델은 LakhNES dataset을 기반으로 하고 있고 여러개의 track을 하나의 sequence로 합침으로써 이전 모델의 token representation을 향상시켰다. 이 모델은 노트를 지우고 복원하는 방법을 통해 학습을 진행한다. 또한, 위 그림을 통해 여러개의 단일 트랙을 하나의 sequence로 합친것을 볼 수 있다.그러나 기악과 편곡에는 적합한 모델이 아니다. 이 모델은 미리 악기를 지정해주기 때문에 다른 트랙의 특징을 파악하기 어렵다.
7. Evaluation and Metrics
음악 생성을 평가하는 방법은 딥러닝의 output에 따라 달라진다. 평가 방법에는 객관적인 방법과 주관적인 방법이 존재한다. 그러나 창의성을 측정해야하기 때문에 주관적인 방법이 중요하고 객관적인 방법은 model의 결과의 질을 정량화하는데 도움이 된다.
7.1 Objective Evaluation
딥러닝 기반의 모델의 성능을 측정하기 위해 가장 많이 사용하는 지표는 perplexity, BLEU, precision, recall or F-score이다.
Loss는 input과 output의 차이를 알기위해 사용된다. 반면에 perplexity는 model의 일반화 성능을 보여주는 지표이다.(loss가 음악 생성에 더 연관되어 있음.) Music Transformer는 loss와 perplexity를 사용하지만 TonicNet과 MusicVAE는 model이 생성한 음악의 질을 평가하기 위해 loss만을 사용하고 있다.
또한 음악적인 요소를 통해 평가하는 지표들도 있다.
- Pitch-related : scale consistency, tone spam, ratio of empty bars or number of pitch classes used를 평가하는 지표
- Rhythm-related : duration or pattern of the notes을 평가하는 지표
- harmony-related metrics : the chords entropy, distance or coverage를 평가하는 지표
7.2 Subjective Evaluation
정성적인 평가는 보통 음악의 창의성을 평가한다. 가장 많이 사용되는 방법은 모델이 생성한 음악을 듣고 작곡가를 유추하는 방법이다. 이를 위해서는 평가를 하는 사람들의 구성하는 방법을 고려해야하고 뒤로갈수록 피로한것도 고려해야한다.
8. Discussion
- Are the current DL models capable of generating music with a certain level of creativity?
-> MusicVAE의 경우 짧은 motif를 생성하는데는 좋은 결과를 보여주고 있으나, 긴 phrase나 motif를 생성할 경우 어떠한 리듬을 따르거나 notes의 direction pattern을 따르지 못하는 결과를 보여준다. 결론적으로 좋은 질의 motif를 생성하지 못한다고 볼 수 있다.
- What is the best NN architecture to perform music composition with DL?
-> 더 긴 input sequence를 넣기 위하여 transformer 기반의 모델을 사용하기 시작했다. 그리고 음악의 style과 같이 high-level의 음악을 생성하기위해 GAN과 VAE가 사용되었다. (딱히 Best는 없는듯.)
- Could end-to-end moethods generate entire structured music pieces?
-> 아직 완벽한 end-to-end model은 존재하지 않는다.
- Are the composed pieces with DL just an imitataion of the inputs or can NNs generate new music in styles that are not present in the training data?
-> 지금까지 도입된 딥러닝 기반의 음악 생성 모델들은 표절이나 모방이 아닌것으로 보인다.
- Should NNs compose music by following the same logic and process as humans do?
-> 과거의 event를 통해 미래를 예측하는 auto-regressive하다는점은 인간의 작곡 과정과 비슷하다.
- How much data do DL models for music generation need?
-> MusicVAE는 3.7million melodies, 4.6million drum pattern and 116 thousand trios를 사용 / Music Transformer는 1,100 piano pieces. 많은 데이터가 필요한것으로 보임. 그러나 최근 transfer-learning을 통해 이를 해결한것으로 보인다.
- Are current evaluation methods good enough to compare and measure the creativity of the composed music?
모델의 창의성과 NN의 성능 두가지 모두 평가할 수 있는 지표가 필요하다.

Embark on a musical adventure in Edmonton with Dark Mountain Music's tailored music lessons! As more than just a music school, we're a vibrant community of musicians, educators, and learners. Committed to excellence, our range of lessons caters to various preferences and lifestyles. Join us and experience the transformative power of music lessons edmonton!