Introduction
Seq2seq model은 RNN기반 (LSTM, GRU) encoder와 decoder로 구성된 model이다. Seq2seq model은 보통 translation, generation, Q&A, 등에서 활용되는 모델이다. 예를 들어, translation에서는 입력의 길이와 출력의 길이가 다르기 때문에 기존 neuarl 기반의 model로는 학습하기 힘들다. Seq2seq model은 이러한 한계점을 극복한 end-to-end model이다.
Sequence-to-sequence Model
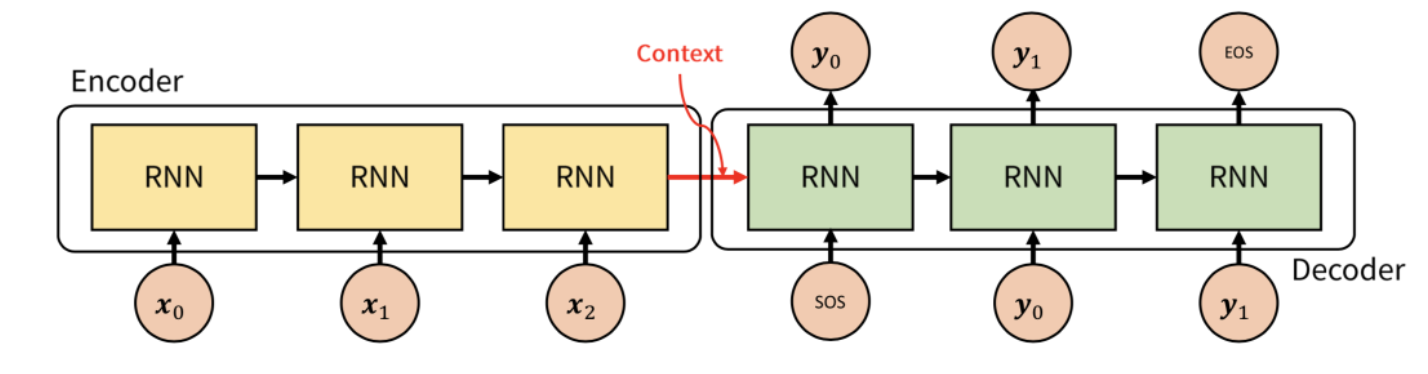
먼저 Encoder는 input sequence가 들어오면 context vector를 생성하고 decoder는 context vector를 생성한다. 이때, context vector는 input에 대한 정보를 압축하고 있는 vector이다. 예를 들어, "안녕하세요"라는 문장이 input으로 들어왔을 때, encoder에서 context vector를 만들고 이 context vector를 바탕으로 decoder는 output을 생성한다.
Model의 구조를 좀 더 자세히 들여다보면, encoder와 decoder는 두개의 RNN architecture로 구성되어 있다. Encoder 부분에서 input sequence가 토큰화 되어서 들어오게되고 단어의 각 토큰은 RNN cell에서 각 timestep의 input이 된다. Encoder에는 모든 input이 들어오게되고 마지막 cell timestep에서의 hidden state를 decoder로 넘겨주는데 이때 이 hidden state를 context vector라고 한다.
Decoder는 초기 입력으로 < sos > 토큰이 들어가게된다. < sos > 토큰을 입력되면 다음에 등장할 단어의 확률이 높은 단어를 출력한다. 그리고 끝을 알리는 < eos > 토큰이 입력될 때까지 반복한다.
Seq2Seq 모델의 train하는 방법과 test하는 방법은 조금 다른데, 예를들어 train 과정에서 encoder에 < sos > I love you가 입력으로 들어오게되면, decoder에는 I love you < eos >가 나오도록 훈련한다. 이를 teacher forcing이라고 한다. 반면 test 과정에서는 decoder에는 context vector와 < sos >만을 input으로 받고 출력 할 단어를 예측한다. 그러나 마지막 output의 hidden state으로 모든 정보를 담아낼 수 있을까?
그리하여 도입된 mechanism이 바로 attention이다. Encoder의 최종 output에만 의존하는것이 아닌 각 encoder의 정보를 모두 활용하는 방법이다.
Attention
Attention Mechanism은 decoder가 단순히 encoder의 context vector를 받아 sequence를 출력하는 것이 아니라, decoder가 출력되는 t 시점마다 encoder에서의 전체 input sequence 한번 더 보는것이다. 이 때 decoder는 encoder의 모든 input sequence를 중요한 단어에 대하여 더 큰 attention을 준다. 즉, encoder에서 중요한 단어에 집중하여 이를 decoder에 바로 전달하는 mechanism이다.
Attention Mechanism을 이해하기 위해서는 먼저 Key - Value에 대한 이해가 필요하다. Dictionary의 개념과 똑같은데 예를 들어, {boy : 남자}에서 'boy'라는 key의 value는 '남자'가 된다. 아래는 attention의 기본 구조를 함수로 나타낸것이다.
Q = Query, 특정 t시점의 decoder에서의 hidden state
K = Keys, 모든 시점의 encoder의 hidden state
V = Values, 모든 시점의 encoder의 hidden state
주어진 Query에 대해서 모든 key와의 유사도를 계산한다. 구해낸 유사도를 key와 mapping되어 있는 value 값에 반영하고 그 유사도가 반영된 value를 모두 더하여 attention value를 얻는다.
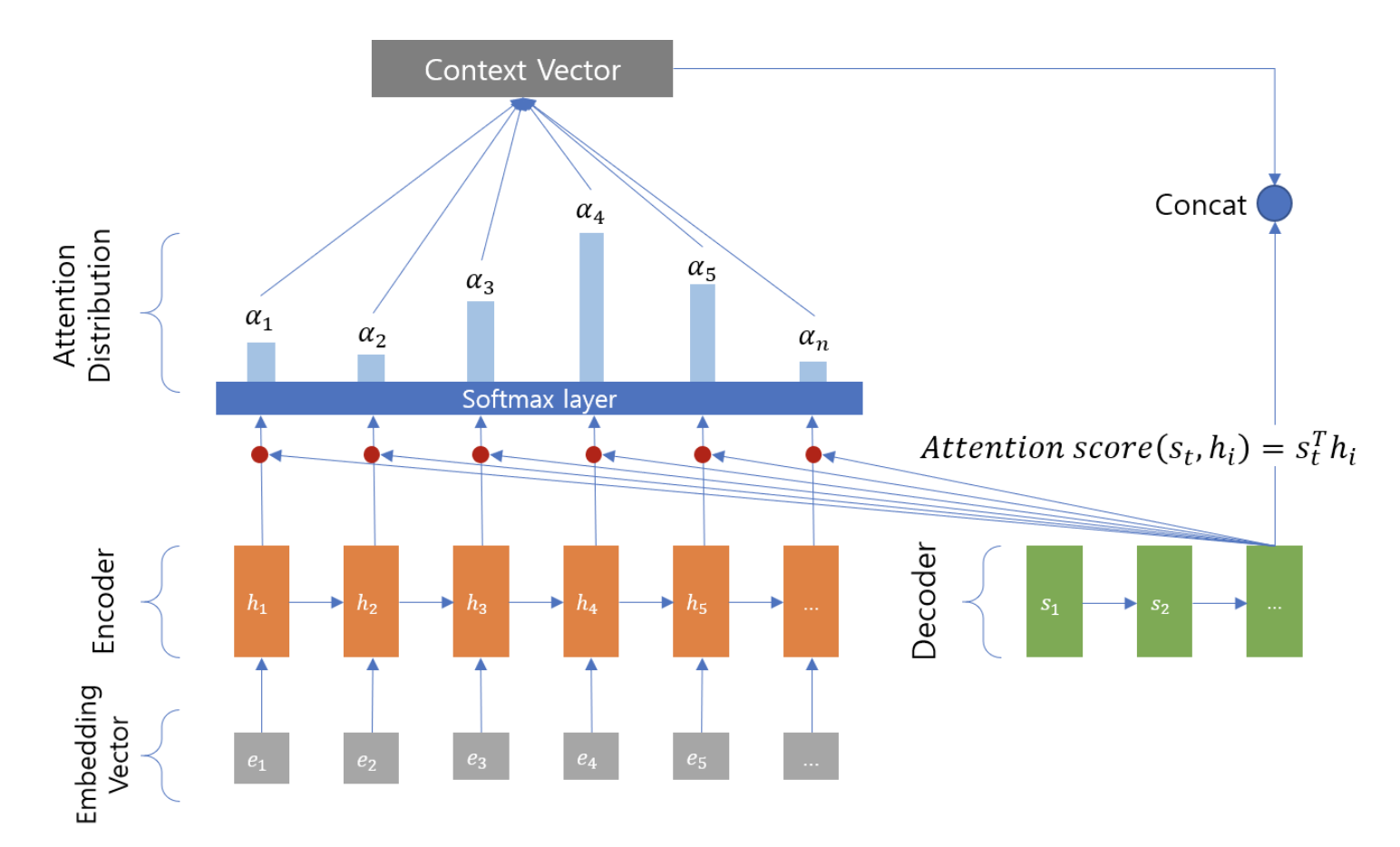
Attention score
Attention mechanism에 가장 첫번째 단계로 attention score를 구한다. 위 그림에서 는 encoder에서 각 시점의 hidden state이다. 그리고 는 decoder에서 현재 시점의 hidden state이다. 이 때 이 과정에서 decoder의 는 Query가 되고 참고하고자 하는 encoder의 hidden state인 는 key가 된다.
그리고 를 transpose한 것과 encoder의 모든 hidden state를 dot-product하는데 이를 통해 모든 유사도를 구할 수 있다고 이해했다. (그리고 이때 attention score는 모두 scalar 형태를 띄게된다.)
모든 encoder의 hidden state와 dot product를 하게되므로 다음과 같이 나타낼 수 있다.
Attention Distribution
구한 Attention score list에 softmax 함수를 취하여 합이 1이 되는 확률 분포를 만들어준다. 이때 각각의 값들을 attention weight라고 한다.
Attention Value
위에서 구한 값들을 통해 attention value 를 구하게 된다. 앞서 구한 encoder의 hidden state인 와 decoder의 현시점 attention distribution인 의 가중합을 통해 구할 수 있다.
Concatenate
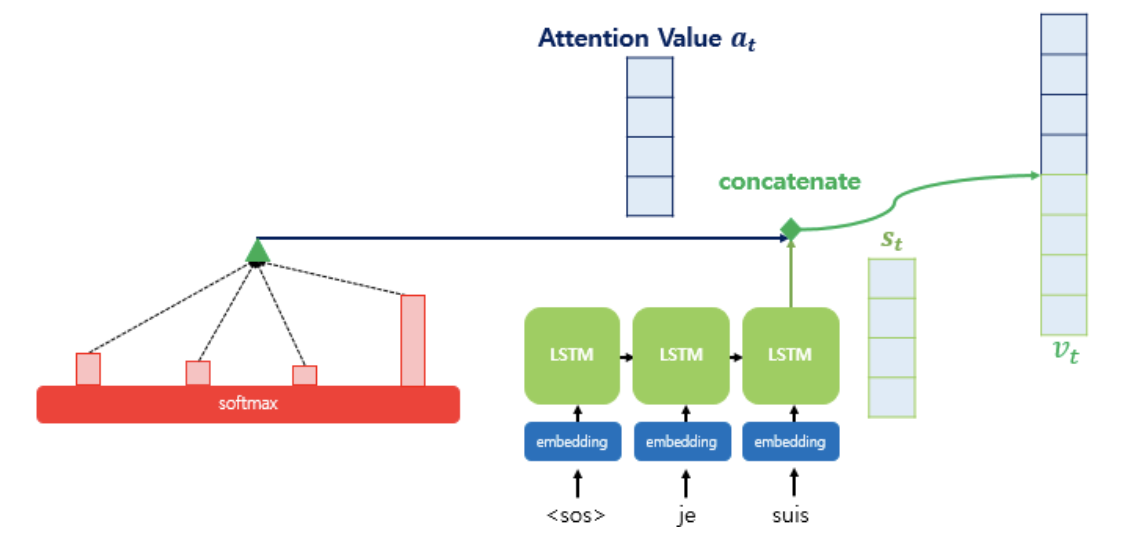
앞서 구한 attention value인 와 decoder의 hidden state인 를 결합한다. 그렇게 구한 는 encoder의 정보를 decoder로 넘겨주는 역할을 한다.
하지만 는 output layer에 직접 입력 되는것이 아니라 가중치 행렬을 곱하고 편향을 더해주어 output layer로 보낸다.
마지막으로 에 softmax 함수를 취해서 decoder에서 다음 단어를 예측한다
