
Introduction

MMV: MultiModal Versatile Networks

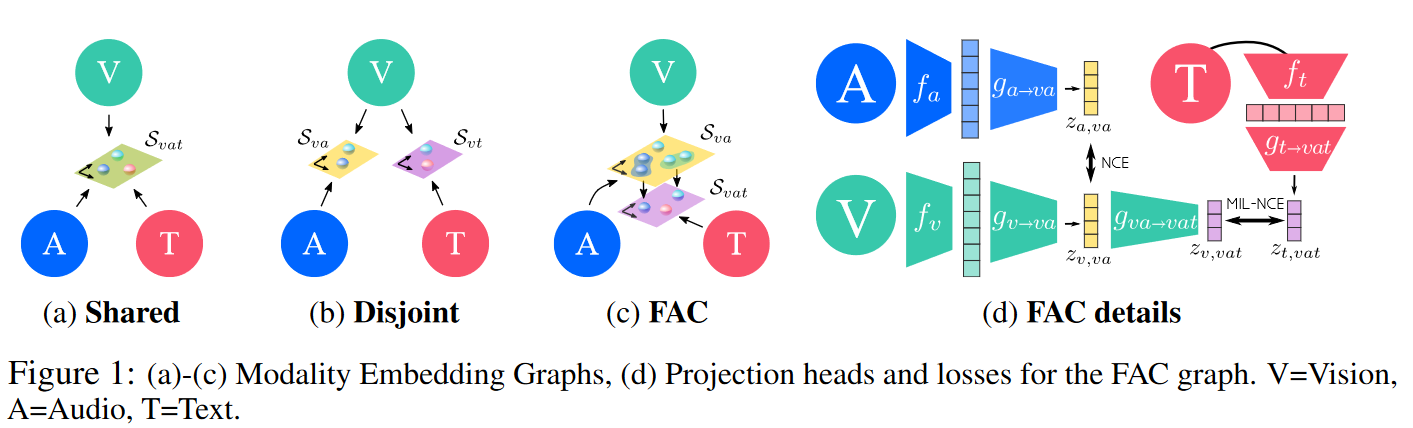
Shared / Disjoint
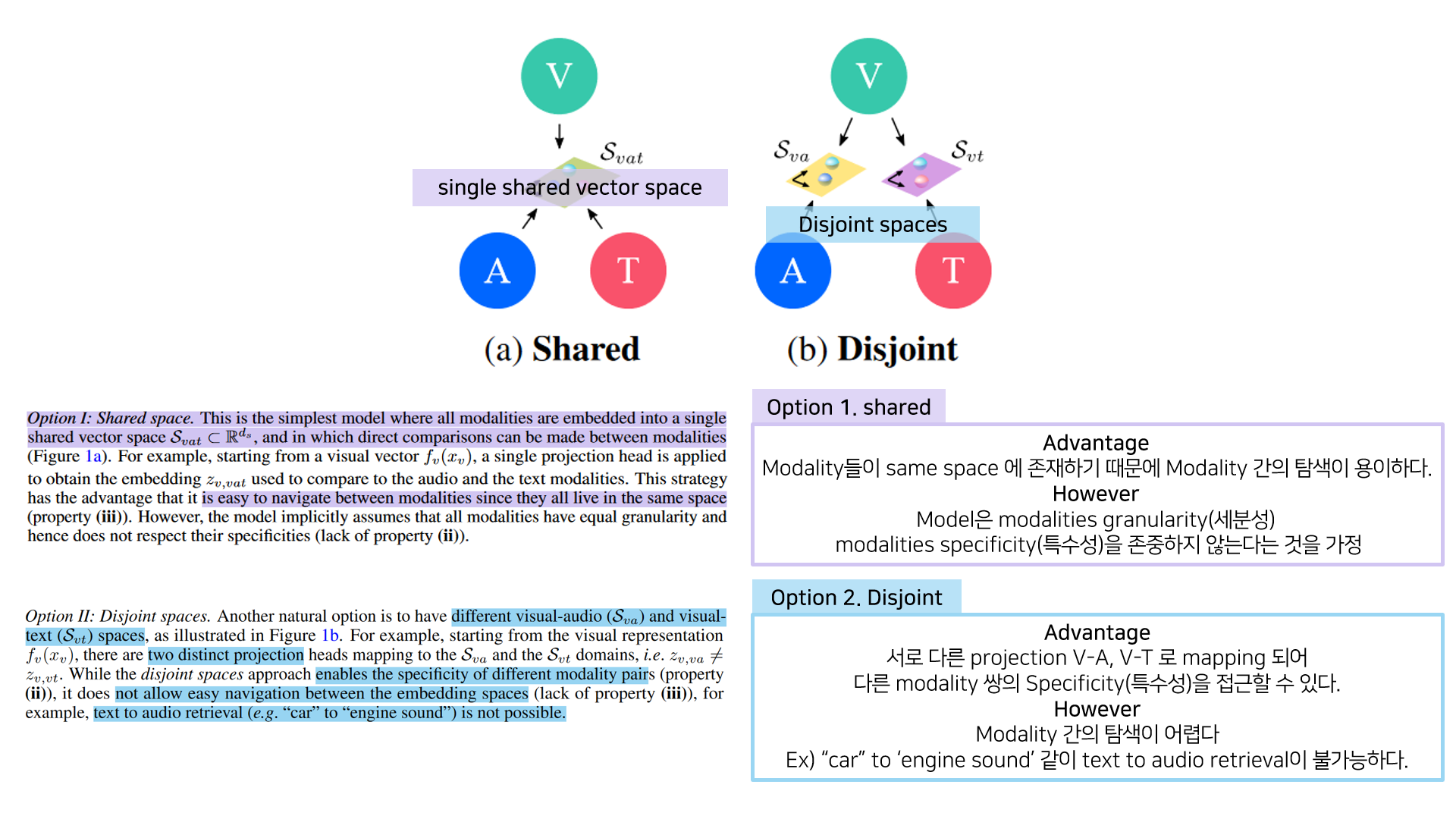
FAC (Fine and Coarse spaces)
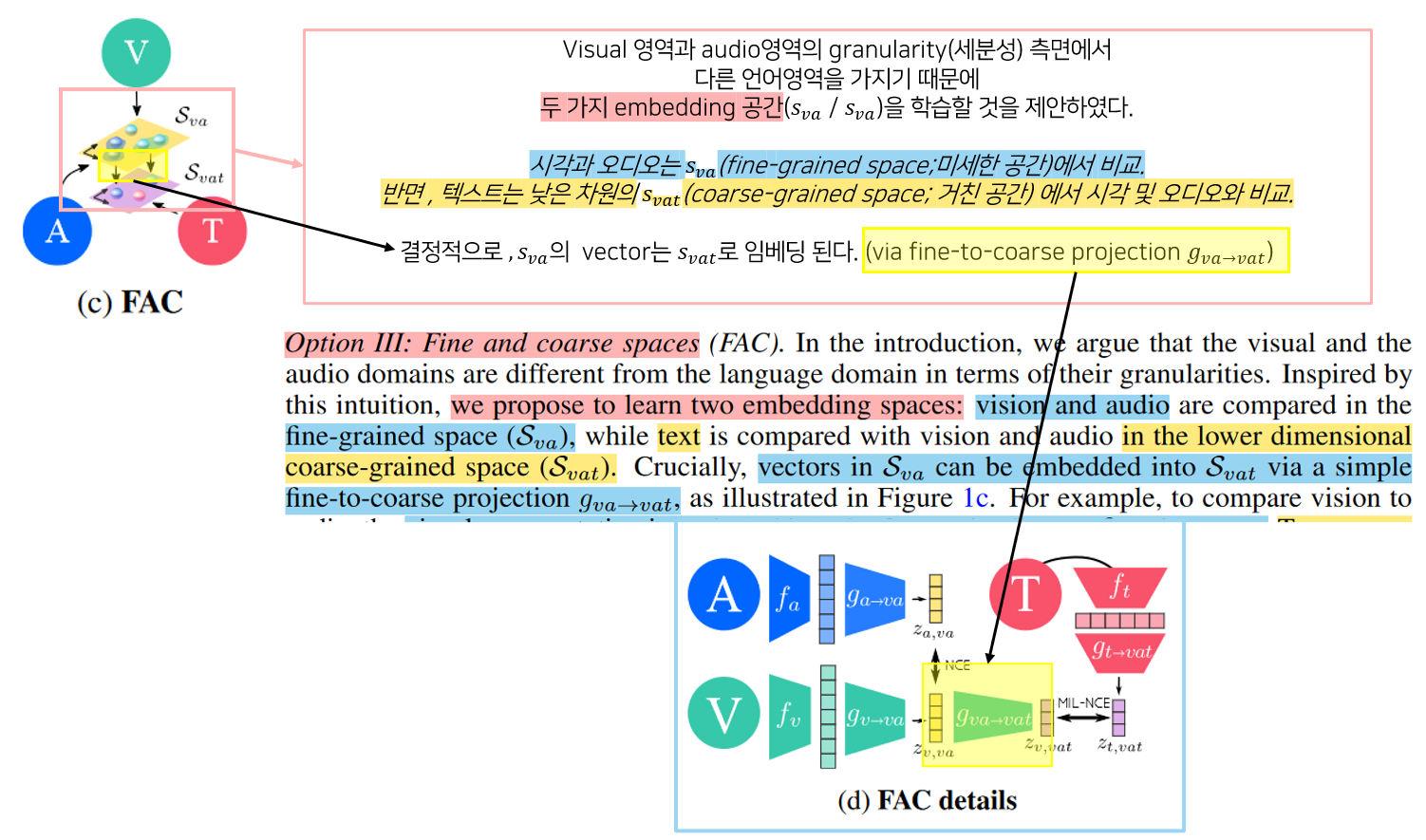
Fine to coarce projection(gva->vat)을 통해서 fine-grained space(vision-audio embedding space) vector 를 더 낮은 차원인 coarse-grained space(text embedding space)로 임베딩한다.
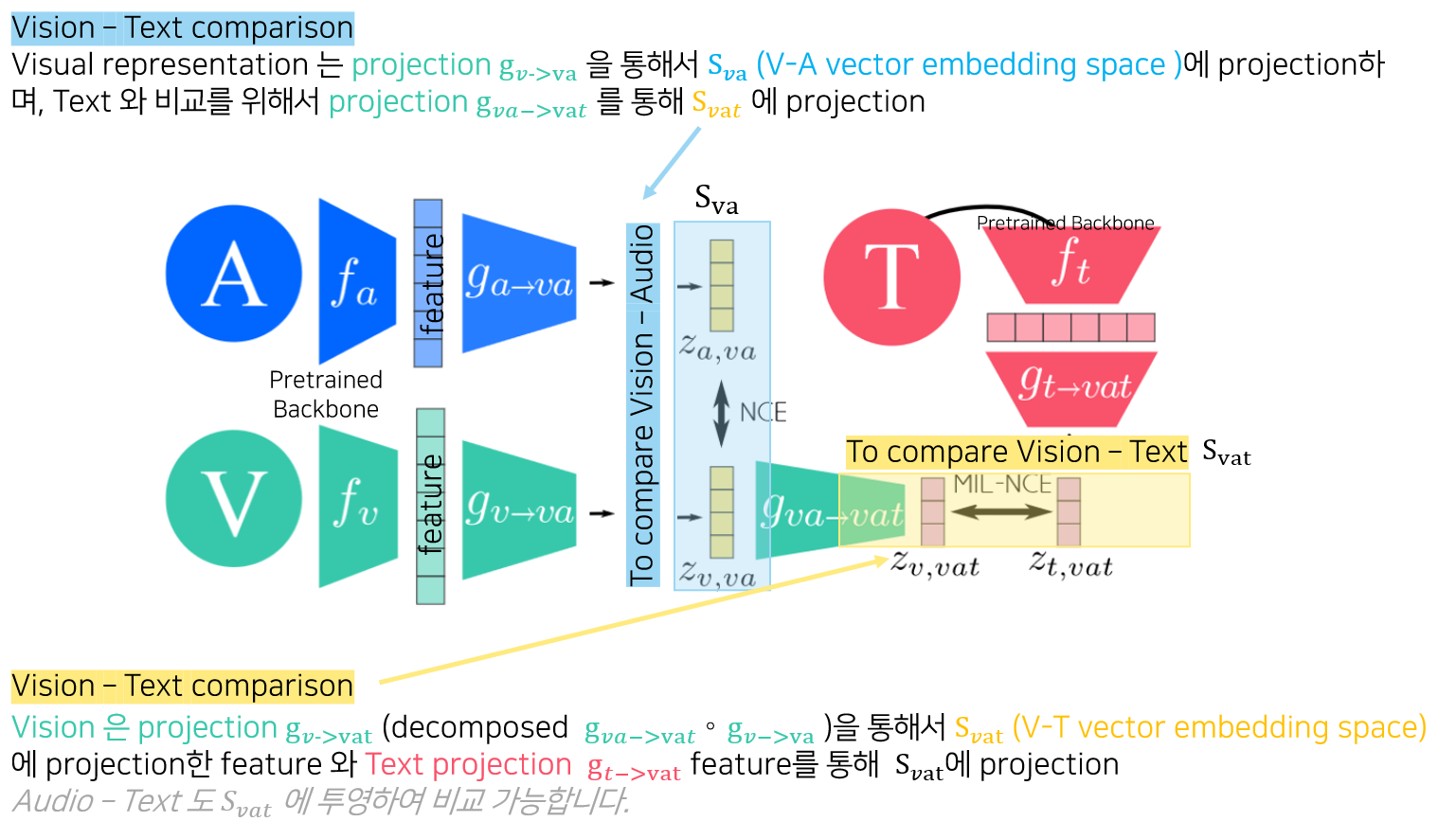
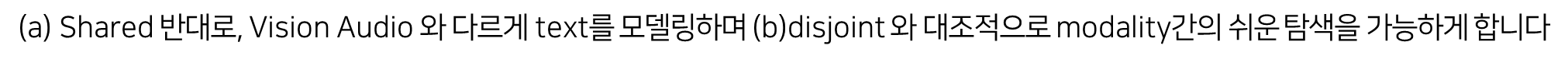
Multimodal Contrasitive loss
contrasitive learning? <- click!


무니의 성장스토리 😣