[ComputerVision] Object Detection 이란? with 1-stage, 2-stage , AP
이미지 내에서 사물 인식하는 방법에는 다양한 유형이 존재한다.
- classification
- classification + Localization : 하나의 물체 위치를 찾는 문제
- Object Detection : 다수의 사물의 위치와 클래스를 바운딩박스로 분류하는 문제
- Instance Segmentation : 각각의 사물 객체를 픽셀단위로 구분
1. Object Detection 방식
[1] 2-stage
- 물체의 위치를 찾는 문제 -> 분류 문제를 "순차적"으로 진행
- faster R-CNN
image > Region proposals [물체가 존재할 것 같은 위치] > feature Extractor > 'classification' & 'regression' [사물이 존재할 것이라고 예측하는 bounding box]
- R-CNN
이미지에 대하여 CPU 상에서 Selective Search 를 진행함
-> 물체가 존재할법한 위치 2000개를 찾음
-> 2000개의 위치를 개별적으로 CNN -> 모든 resion feats를 저장한 feature vector 를 추출
-> Regressors(정확한 위치의 바운딩박스를 조절하여 예측), SVMs(classification)-장점 : CNN을 이용해서 각 Region 의 클래스를 분류할 수 있다.
-단점 : 전체 프레임워크가 End-to-End 방식이 아니기 때문에 Global Optimal Solution을 찾기 어렵다
- Fast R-CNN [RoI pooling / softmax]
- 기존의 R-CNN 마찬가지로 Selective Search를 통해 Region proposal을 찾음
- 다만 , feature map 을 뽑기 위해서 CNN을 한번만 이용한다는 점이 차이가 있다.
- 이후 RoI(Region of Interest) pooling 을 통해 각각의 region 에 대해서 feature 를 추출한다.
- *CNN의 구조에서 각각의 input에 대해 위치를 어느정도 보존하기 때문에 RoI layer 과정이 가능하다
- CNN -> FC -> softmax layer 를 거쳐 각각의 class 에 대한 probablity를 구할 수 있다.
-장점: Feature extraction , RoI pooling layer , Region Classfication , Bounding Box Regression step(단계) 모두 End-to-End 학습이 가능
-단점 : CPU 에서 Selective Search -속도 느림
- Faster R-CNN [selective search ->> RPN]
- 기존의 R-CNN,Fast R-CNN에서는 CPU 에서 Region Proposal 이 일어난다(속도↓)
- GPU 에서 Region Proposal를 수행하는 = 'Region Proposal Network(RPN)'제시
- RPN : Feature map 을 보고 어느곳에 물체가 존재할 것인지 예측하는 네트워크
(한번의 forwarding 으로 예측가능 해서 시간적인 장점이 존재)
-> Selective Search 의 시간적인 단점을 보완하는 네트워크 - fast R-CNN 의 detection Architecture 를 이용하여 Regression& softmax(classication)
- 전체 프레임워크를 end-to-end 방식으로 학습
[fast R-CNN + RPN]를 합친 것-장점 : RPN을 제안하여 전체 프레임워크 End-to-End 가능
-단점 : 여전히 component 가 많아서 전체 Architecture 가 복잡하며, Region Classification 단계에서 각 region 에 따른 feature vector 는 개별적으로 FC layer 로 Forward 해야함
[2] 1-stage Detector
- 물체의 위치를 찾는 문제와 분류 문제를 한번에 진행
- YOLO : 빠르지만 정확도는 2-stage 가 더 좋음
image > feature Extractor > 'classification' & 'regression'
2. Region Proposal
- Sliding Window
이미지에서 다양한 형태의 window 를 sliding 하여 물체가 존재하는지 확인하는 것(너무 많은 영역에 대하여 확인해야 한다는 단점-> 느려짐)
- Selective search (CPU)
-인접한 영역(region) 끼리 유사성을 측정해 큰 영역으로 차례대로 통합해 나가는 방식 (R-CNN, Fast R-CNN)
-물체가 존재할 것 같은 위치를 찾을 수 있음
3. Object Detection 정확도 측정 방법
- Recall / Precision
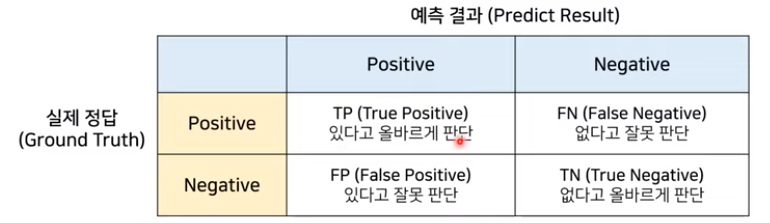
- Precision (모델이 탐지한 물체의 개수중 올바르게 탐지한 경우 )
TP / TP+FP - Recall (실제 정답 물체 중 우리 모델이 얼마나 맞췄는지 경우)
TP / TP + FN
모든 영역에서 전부 사물이 존재한다고 판단 => 재현율을 높아지지만 정확도는 하락
매우 확실할 때만 사물이 존재한다고 판단 => 정확도는 높아지지만, 재현율은 하락
- Average Precision (AP)
- 일반적으로Precision 과 Recall 은 반비례관계
->> AP 로 성능을 평가하는 경우가 많음 (precision 과 recall을 모두 고려) - 단조 감소 그래프를 통해서 넓이를 계산
*TP / FP 결정의 기준 ?
Object Detection model의 결과의 바운딩 박스가 실제 바운딩 박스와 얼마나 겹치는지에 대한 비율
IoU(Intersection over Union)
= Area of Overlap(바운딩 박스의 교집합)/ Area of Union(바운딩 박스의 합집합)
4. NMS (Non Maximum Suppression)
NMS : IoU가 특정 임계점 threshold 이상인 중복 box를 제거
- object detection 에서 하나의 객체에 하나의 바운딩 박스가 적용되어야 하는데 여러개의 바운딩 박스가 겹쳐 있을 경우 NMS를 적용하여 하나로 합치는 방법이 필요하다.
