들어가기 전에
해시 테이블의 평균 검색, 삽입, 삭제시의 시간복잡도는 O(1)이다.
이게 가능하려면, 어떤 메모리 주소에 어떤 데이터가 저장되어 있는지 한번에 알 수 있어야 한다.
이번 포스팅에서는 아래 순서대로 hash table을 파헤쳐 보려고 한다.
- 무작위로 뽑은 10개의 수를 어떻게 하면 O(1)의 시간복잡도로 추가하고 삭제할 수 있는지에 대한 답을 찾아가는 방식으로 해시를 이해
- 해시를 이해하기 위해 필요한 용어와 개념
- 해시 테이블에 문자열을 저장하는 방법
코드 예제에서는 C언어로 작성하였다.
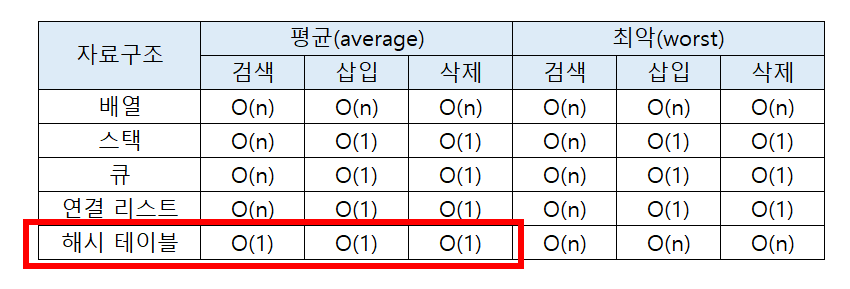
무작위로 뽑은 수 10개를 저장해 보자
239, 94, 1, 131, 99, 853, 42, 56, 922, 3
O(1)으로 알 수 있는 방법은 무엇일까?
방법1: 입력값의 최댓값을 배열의 크기로?
가장 단순 무식하면서 주먹구구식 방법이다.
- 입력값의 최댓값만큼 긴 배열을 만든다.
- 배열[입력값]에 값이 있으면 1, 없으며 0을 저장한다.
즉, 이 경우에는 입력값이 배열의 색인
numbers[3] = 1; /* 입력값: 3 */
numbers[99] = 1; /* 입력값: 99 */

방법1의 문제
- 입력값이 엄청 크다면?
- 예: 무작위로 뽑은 수 중 최댓값이 291,948 (, 4gb)
- 배열의 크기를 무한히 늘릴 수도 없으며
- 메모리 사용량 측면에서도 비효울의 극치이다.
우리가 알고 있는 사실들
- 입력값이 총 10개이다.
- 아주 큰 값이 입력값으로 들어올 수 있다.
만들고 싶은 것
- 다음과 같은 입력과 출력을 가지는 함수
- 입력: 10개의 중복 없는 수
- 출력: 범위가 [0,9]인 배열의 색인
- 즉, 자료(입력) -> 색인(출력)으로 바꾸는 함수
- O(1)으로 검색할 수 있도록, 반복문이 없어야 함
- 가장 간단한 방법은 입력값을 입력값 길이 만큼 %연산 하는 것이다.
- 입력값 % 10
방법2: 입력값 % 10으로 색인 만들기
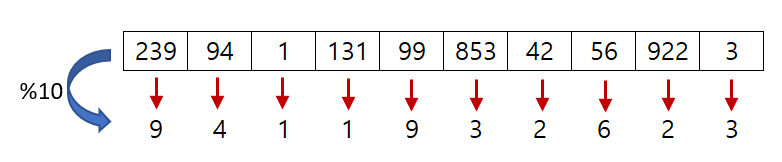
방법2의 문제
- 동일한 색인 위치에 들어가는 값들이 생긴다
- 배열의 크기를 두 배 정도로 늘리면?
- 아까보다는 덜 하지만 여전히 겹치는 색인이 존재
방법3: 소수사용 (방법2의 보완)
- 흔히 다음과 같이 하는게 좋다고 말함
- 배열의 크기는 입력값의 최소 2배
- 크기에는 소수 (prime number)를 사용
- 소수로 나눠야 동일한 색인이 안 나올 가능성이 가장 높음
- (이 부분은 추후 다른 포스팅에서 정리할 예정)
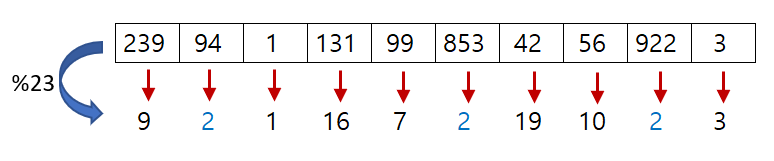
- (이 부분은 추후 다른 포스팅에서 정리할 예정)
- 그래도 중복이 없을 수 없다..!
중복 색인 문제를 해결하는 방법
- 나머지연산으로 구한 색인 위치 이후에 빈 공간을 찾아 저장
- 즉, 색인을 1씩 증가해가며 빈 색인 위치를 찾아 거기에 저장
- 따라서, 더이상 색인이 아닌 실제 값을 저장해야 함
- 그렇게 하려면, 배열에서 비어있는 위치를 알 수 있어야 함
- 방법1: 같은 크기의 불 (bool) 배열을 만들어서 사용 여부를 나타냄
- 방법2: 어떤 특정한 값을 저장해서 비어있다는 사실을 나타냄
- 보통 유효하지 않은 값(절대 들어올 수 없는 값: 예: INT_MIN)을 사용
- 보통 유효하지 않은 값(절대 들어올 수 없는 값: 예: INT_MIN)을 사용
배열을 사용한 해시 테이블 예
해시 테이블 초기화
#include <limits.h>
#define TRUE (1)
#define FALSE (0)
#define BUCKET_SIZE (23)
int s_numbers[BUCKET_SIZE];
/* INT_MIN으로 해시 테이블을 초기화 */
void init_hashtable(void)
{
size_t i;
for (i = 0; i < BUCKET_SIZE; ++i) {
s_numbers[i] = INT_MIN;
}
}검색
int has_value(int value)
{
int i;
int start_index;
start_index = value % BUCKET_SIZE;
/* 음수가 들어왔을 때 버켓 사이즈 보다 작게 만드려고 아래 코드를 추가 */
if (start_index < 0) {
start_index += BUCKET_SIZE;
}
i = start_index;
do {
if (s_numbers[i] == value) {
return TRUE;
} else if (s_numbers[i] == INT_MIN) {
return FALSE;
}
i = (i + 1) % BUCKET_SIZE;
} while (i != start_index); /* 한 바퀴 다 돌면 값이 없다는 뜻이므로 반복문을 빠져 나옴 */
return FALSE;
}} else if (s_numbers[i] == INT_MIN) {- 위 코드에서 이게 가능하게 하려면 아래와 같은 가정이 필요함
- 예를 들어, 나머지 연산으로 중복된 값이 3개가 있을 때 앞의 두 개 값이 지워지지 않는다는 가정
- 예) 11, 12, 13을 나머지 연산한 값이 모두 3이고, 11, 12, 13을 순서대로 저장하면 배열의 인덱스 3, 4, 5에 순서대로 11, 12, 13이 저장이 될 것이다. 그 이후에 4번 인덱스에 담긴 12를 지우면 4번 인덱스에 INT_MIN이 저장되게 되고 이 상태에서 13을 검색하면 값이 없다고 나오게 된다.
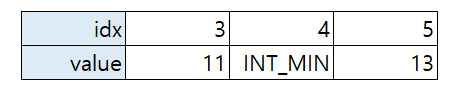
- 위 코드에서 이게 가능하게 하려면 아래와 같은 가정이 필요함
추가
int add(int value)
{
int i;
int start_index;
start_index = value % BUCKET_SIZE;
/* 음수가 들어왔을 때 버켓 사이즈 보다 작게 만드려고 아래 코드를 추가 */
if (start_index < 0) {
start_index += BUCKET_SIZE;
}
i = start_index;
do {
if (s_numbers[i] == value || s_numbers[i] == INT_MIN) {
s_numbers[i] = value;
return TRUE;
}
i = (i + 1) % BUCKET_SIZE;
} while (i != start_index);
return FALSE;
}main.c 에서 사용
int main (void)
{
init_hashtable();
add(703);
add(793);
add(724);
add(441);
add(219);
add(1);
add(81);
add(546);
add(777);
add(747);
return 0;
}이게 바로 해시 테이블
- 위에서 본 코드가 아주 간단한 해시 테이블
- 색인 중복이 없으면 검색, 추가 모두 O(1)
- 색인 중복이 있는 경우, 최악의 경우 O(N)
연결리스트를 사용하는 방법
- 배열 안의 각 요소에 연결 리스트를 저장
- 여전히 색인이 겹치는 경우가 있지만
- 위 방법 (중복이 생기는 경우 다음 색인으로 넘어가는 방법)보다는 적음
- 하지만 최악의 경우 여전히 O(N)
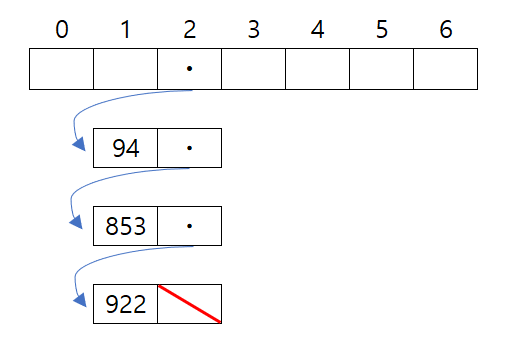
- 하지만 이 방법도 노드가 들어올 때마다 동적할당을 해야 하기 때문에 느릴 수 있다.
- 조금 더 최적화를 생각하는 사람들은 이러한 단점을 보완하기 위해 배열 안의 각 요소에 배열을 사용
- 최대 길이를 정해두고, 그 크기를 초과할 경우 assert를 걸어둬 디버그시에 배열의 크기를 늘림
- 배열을 잡는 개념은 정적 배열을 잡거나, 동적 배열을 실행중에 한 번만 잡으면 되기때문에 노드 하나가 들어올 때마다 메모리 할당을 하는 것 보다는 빠르다
해시 값 / 해시 함수 / 해시 충돌
해시 값
해시값은 어떤 데이터를 해시 함수에 넣어서 나온 결과값이다. 이렇게 해서 받은 값은 주민등록번호나 학번과 같이 그 데이터를 대표하는 값이여야 하고 고유한 값이여야 한다.
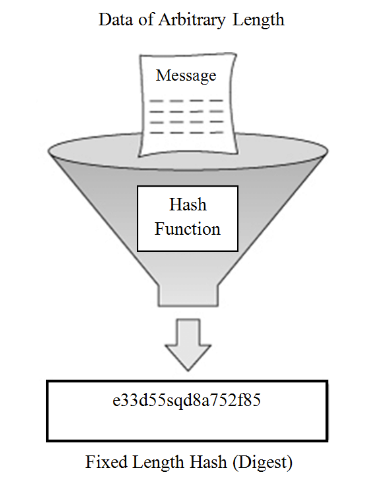
해시 함수
해시 함수는 임의의 크기 (길이의 제한x)를 가진 데이터를 고정된 길이의 해시값에 대응하게 해 주는 함수이다.
해시 함수의 특성
해시 함수도 함수이기 때문에, 아래 함수의 특성을 가진다.
- 입력값이 같으면 출력값은 언제나 같다.
- 입력값이 달라도 출력값이 같을 수 있다.
- 위 2번의 특성 때문에 충돌이 발생한다.
해시 충돌 (hash collision)
- 입력값이 다른데 출력값이 같은 경우
- 따라서 출력값으로 부터 입력값을 찾을 수 있다는 보장이 없다.
- 이런 일이 없으면 없을 수록 좋은 해시 함수이다. (속도를 고려하지 않았을 때를 가정)
해시 테이블에 문자열 저장
앞서 해시 함수란 임의의 크기를 가진 데이터를 고정길이의 출력값으로 바꾸는 함수라고 했다. 임의의 크기를 가진 데이터는 어떤 것이 있을까? 정수형은 길이가 정해져 있다. 일반적으로 int형 의 경우 4byte, double 형의 경우 8byte의 고정된 크기를 가지고 있다. 문자열의 경우는? 문자열은 고정된 크기가 없고 5글자일수도 5만자일 수도 있다. 때문에 해시 테이블에 문자열을 저장해 보도록 하자.
- 해야할 일
- 문자열을 배열 색인으로 변환
- 문자열은 문자열이라 % 연산이 불가능함
- 그래서 두 단계로 나눠서 진행
- 문자열을 정수형으로 반환 (해시 함수 이용)
- 반환된 정수를 %연산해서 배열 색인으로 변환
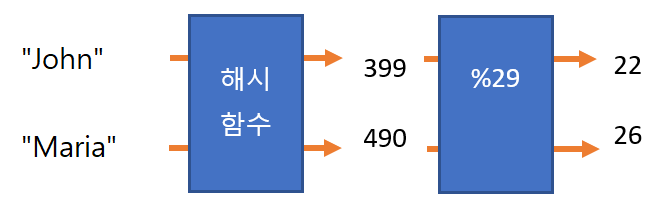
1) 문자열->정수형
-
문자열의 각 요소는 char형 = 아스키코드 = 정수형
-
각 요소의 아스키 코드값을 더해 주어 정수형으로 변환
-
해시 함수 예
- 해시 충돌이 빈번하게 일어나서 잘 사용하지는 않는 해시 함수
int hash_function(const char*) { int value = 0; const char* c = str; while (*c != '\0') { value += *c++; } return value; }
2) 저장
문자열을 정수형으로 변환했으니 실제로 버킷에 저장해보자.
-
"John"의 해시값은 399, "Maria"의 해시값은 490
-
해시 값을 바탕으로 나머지 연산을 이용하여 색인을 구할 수 있음
-
색인을 구하면 테이블에 저장
- 만약 해당 색인에 값이 저장되어 있다면 색인을 1씩 증가시켜 빈 곳을 찾아 저장
- add 함수 예
/* add 함수에 문자열 하나와 hash함수 포인터를 전달 */ int add(const char* value, int (*hash_func)(const char*)); add("Teemo", hash_function); add("Hana", hash_function); -
하지만 위 해시함수는 O(문자열 길이)만큼 돌아야 하기 때문에 O(1)으로 돌지 않는다.
-
만약, 해당 문자열을 여러번 쓰는 경우 (삽입할 때 한번쓰고, 검색할 때 한번 쓰고 등등), O(1)으로 만드려면 해시 함수를 한 번만 호출하고 그 결과를 기억해 둬야 함
- int hash_id = hash_function(문자열)
-
그리고 필요할 때 hash_id를 이용해 해시 테이블 함수 호출
- add(hash_id, data);
-
이렇게 하면 hash_id % 23 연산 한 번으로 해당 문자열의 색인을 구할 수 있으니, hash_id로 부터 저장할 위치의 색인을 O(1)으로 구할 수 있다!
지금까지 본 건 HashSet
지금까지 본 건 엄밀히 따지면 HashSet이다.
집합 내 어떤 데이터를 중복 없이 저장한 게 전부이다. 저장하려고 해시 함수를 사용했을 뿐.
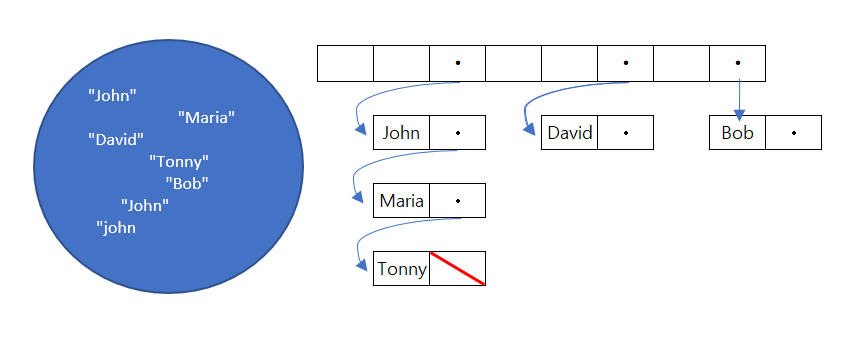
다음 포스팅에서 HashMap에 대해서 알아보려고 한다.
References
