해시맵 (HashMap)
해시 테이블
일반적으로 어떤 키에 대응하는 어떤 값을 저장하는 것을 해시 테이블(엄밀히는 해시 맵)의 형태라고 한다. 대표적인 예로 C#의 Dictionary, Java의 HashMap 등이 있다.
- 키 (key) :
데이터의 위치를 의미하는 데이터- 정수뿐만 아니라 문자열이나 구조체등의 자료형도 가능
- 값 (value) :
실제로 저장하는데이터 - 키(열쇠)를 가지고 자물쇠를 열면 거기에 데이터가 있다는 의미
키와 값을 사용해서 저장하는 예
- 저장 하려는 값:
{John: 89, Maria: 100}- 해시 값 예 (각 문자의 아스키 코드의 합)
- J + o + h + n = 399
- M + a + r + i + a = 490
- 색인
399 % 5 = 4
490 % 5 = 0
- 순서대로 하나씩 넣기
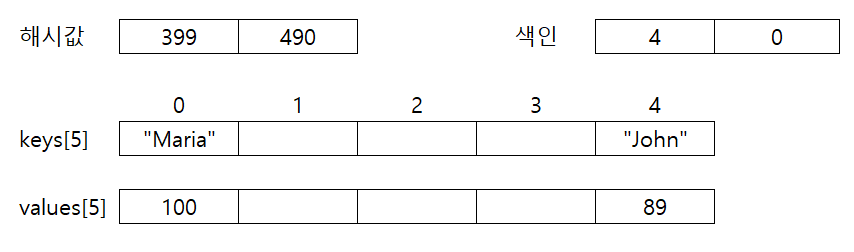
- 해시 값 예 (각 문자의 아스키 코드의 합)
key를 이용해 값을 얻어오기
- 저장했을 때와 마찬가지 방법으로 해시값을 구하고, 색인값을 구함
- 해당 색인으로 갔는데 Key값이 다르다면 색인을 하나씩 증가시키면서 탐색
- 즉, 저장할 때와 같은 색인을 이용해서 값을 읽음
해시 테이블에도 충돌이 발생
- 두 가지
- 해시 충돌 : 입력 값(키)가 다른데 같은 해시값이 나옴
- 색인 충돌 : 해시값이 다른데 색인이 같음
- 색인 충돌의 경우, 인덱스를 하나씩 올려가며 빈 곳에 저장하는 방법으로 해결
해시 충돌
- 함수의 특성상, 입력값이 달라도 출력값이 같을 수 있음
- 즉, 서로 다른 문자열을 해시 함수에 넣어도 같은 해시값이 나올 수 있음
- 하지만 해시 충돌 같은 경우도 색인 충돌과 같은 방법으로 해결할 수 있음
- 중복되면 인덱스 하나 올리고, 또 올리고, ...
- 따라서, 해결하지 않아도 되지만.. 방지할 수 있다면?
해시 충돌 방지의 이점
만약 해시 충돌을 방지할 수 있다면 어떤 이점이 있을까?
결론적으로 말하면 메모리 낭비를 줄일 수 있고, 실행속도도 빨라진다.
위 [키와 값을 사용해서 저장하는 예] 에서 보면 데이터를 추가할 때, key배열에 문자열을 저장하고 있다. 해시 충돌이 빈번하게 일어난다면 이처럼 문자열을 저장하지 않고서는 해시맵을 사용할 수 없을 것이다. 문자열의 길이는 정해져 있지 않고, 그렇다면 저장 할 때마다 동적 할당을 해야 하는데, 메모리 낭비에 실행시간이 느려질 수 밖에 없다.
하지만, 해시 충돌이 전혀 일어나지 않는다면? key 배열에 해시 값인 int형만 저장해도 된다. 이렇게 되면 동적할당을 할 필요가 없어진다.
좋은 해시 함수를 쓰면 가능한 이야기이다.
좋은 해시 함수란?
좋은 해시 함수란 어떤 경우에도 고정된 크기의 값으로 변환이 가능해야 하고(필수), 해시 충돌이 거의 없어야 한다.
충돌이 전혀 안나는 해시함수는 없지만 아주 덜 나는 함수는 있다. 예를 들어 32비트 해시에서 이상의 데이터를 넣으면 충돌이 발생할 수 밖에 없다.
해시 함수 테스트
stackExchange라는 사이트에서 어떤 사람이 해시 함수 테스트 결과를 공유해 주었다. 관심이 있으면 참고해 보면 좋을 듯 하다.
해당 테스트에 사용한 키는 소문자 영단어 216,553개, 정수 1 ~ 216,533, 랜덤으로 뽑은 216,533개의 GUID이다.
가벼우면서 괜찮은 해시 함수: 65599
/* 65599를 곱해나가는 해시 함수 */
size_t hash_65599(const char* string, size_t len)
{
size_t i;
size_t hash;
hash = 0;
for (i = 0; i < len; ++i) {
hash = 65599 * hash + string[i];
}
return hash ^ (hash >> 16);
}
충돌을 고려한 해시맵 예
int add(const char* key, int value, size_t (*hash_func)(const char*, size_t))
{
size_t i;
size_t start_index;
size_t hash_id;
hash_id = hash_func(key, strlen(key));
start_index = hash_id % BUCKET_SIZE;
i = start_index;
do {
if (s_keys[i] == NULL) {
/* 새 키-값을 설정 */
return TRUE;
}
if (strcmp(s_keys[i], key) == 0) {
return TRUE;
}
i = (i + 1) % BUCKET_SIZE;
} while (i != start_index);
return FALSE;
}충돌이 없을 때 해시맵 예
int add_fast(size_t hash_key, const char* value)
{
size_t i;
size_t start_index;
start_index = hash_key % BUCKET_SIZE;
i = start_index;
do {
if (s_keys[i] == INT_MIN) {
/* 새 해시-값 삽입 */
return TRUE;
}
if (s_keys[i] == hash_key) {
return TRUE;
}
i = (i + 1) % BUCKET_SIZE;
} while (i != start_index);
return FALSE;
}언제 어떤 자료형을 써야할까?
- 기본적으로 배열
- 가장 간단
- 하드웨어 최적화와 캐시 메모리 덕분에 O 표기법에 상관없이 성능이 가장 빠른 경우가 많음 (대용량의 데이터가 아닌 경우)
- 데이터 삽입과 삭제가 빈번히 일어난다면?
- 연결 리스트가 좋음
- 다음과 같은 경우에는 해시 기반 자료 구조들
- 데이터 양이 많은데, 자주 검색해야 함
- 배열에 넣기 힘든 데이터 (예: 연속적, 규칙적인 색인이 나올 수 없는 경우)
References
