이 시리즈는 교재 CSAPP을 통해 컴퓨터 아키텍처를 프로그래머 입장에서 정의합니다.
A Tour of Computer Systems
프로그램의 정의
텍스트 파일이 뭔가요?
텍스트 파일은 배타적인 아스키 코드로 구성된 파일입니다. 이 아스키 코드는 비트로 표현되죠.
아스키 코드를 표현하기 위해서는 몇 개의 비트가 필요한가요?
아스키는 기본적으로 0~127까지의 숫자로 할당돼 있습니다. 따라서 2^7개면 충분히 표현할 수 있죠. 하지만 컴퓨터 아키텍처 상으로 1바이트는 8비트로 구성되기 때문에 텍스트 파일의 각 아스키 코드는 8비트를 할애해서 구성됩니다.
그래서 값으로 바꿔 생각해보면, 텍스트 파일의 크기는 텍스트 개수 * 8로 구할 수 있겠죠?
아래와 같은 코드가 있을 때, 이 코드 텍스트들은 아스키 코드로 저장됩니다. 따라서 char 타입 하나가 1바이트로 표현할 수 있는 이유는 7개의 비트로 충분히 아스키 코드를 표현할 수 있기 때문이라고 생각할 수도 있겠군요.
#include <stdio.h> // 18
// 1
int main() // 10
{ // 1
printf("hello, world\n"); //29
return 0 //12
} //1
위 코드에서 글자의 개수를 모두 세 보면 용량이 얼마인지도 알 수 있습니다. 개행 문자와 공백을 포함해서 79개이군요. 그렇다면 이 텍스트 파일의 용량은 79바이트입니다.
프로그램은 프로그램에 의해 다른 형태로 번역된다.
프로그램을 왜 번역하나요?
풀어서 설명해서 그렇지, 이게 결국 컴파일입니다. 당연히 아스키 코드는 컴퓨터가 이해할 수 있는 데이터가 아니고, 최종적인 instruction은 이진수로 구성되기 때문에 컴파일이 필요하죠.
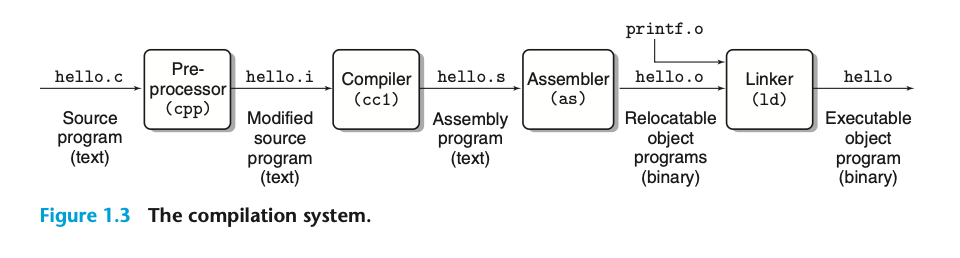
c언어의 경우 pre-processor, compiler, assembler, linker가 컴파일 과정에 개입합니다. 각 단계를 간략히 짚어볼까요?
preprocessor: #include, #define 같은 전처리 지시문(directive)을 처리하여 실제 컴파일할 코드를 준비
compiler: 아스키 텍스트 데이터를 어셈블리 언어로 번역
assembler: 어셈블리 언어 데이터를 이진수 명령으로 구성된 executable object file로 번역
linker: 이미 기계어 번역이 끝난 파일에서 헤더값을 참조해서 외부 라이브러리나 모듈에서 참조된 심볼들의 구체적인 주소값을 추가
Processors Read and Interpret Instructions Stored in Memory
당연하게도, 프로세서는 메모리에 저장된 멍령을 읽고 해석합니다. 이 과정은 디스크에서 메모리 위치로 파일을 복사(read), 유저 프로세스 생성 과정을 포함하죠.
이 문제는 단순해 보이지만, 가상 메모리와 COW같은 기술들이 파생되는 메커니즘이기도 합니다.
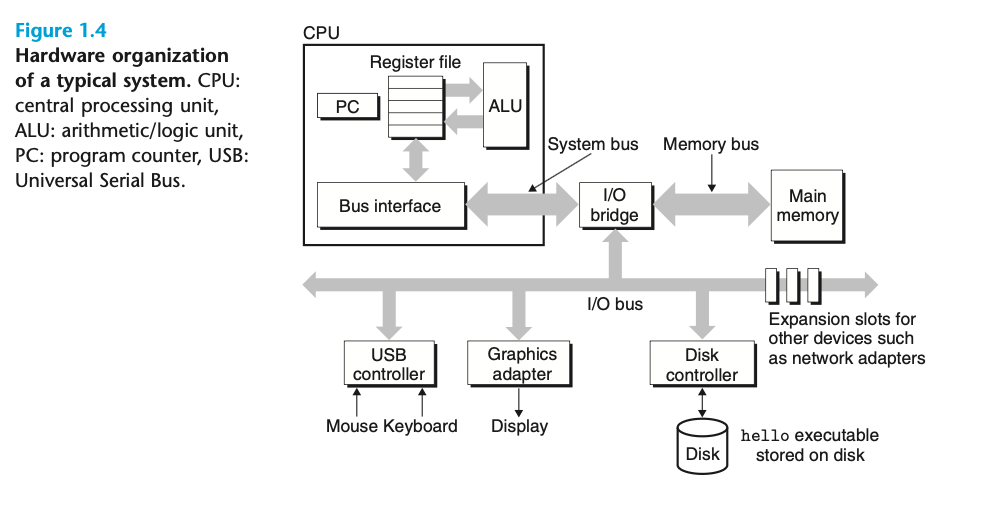
하드웨어적 문제
Bus가 뭔가요?
컴퓨터 아키텍처에서 가장 중요한 파라메터 중 하나는 word-size입니다. 이 값은 한 번에 컴퓨터가 처리할 수 있는 데이터 크기이기도 하고, 가상공간 주소 크기를 정의합니다.
버스는 딱 이 word-size만큼의 데이터를 전송할 수 있는 회로입니다.
ISA
Instruction Set Architecture에 대한 본문의 내용을 좀 상세히 읽어보는게 좋을 거 같습니다.
Instruction set architecture defines very simple instruction executing model.
ISA는 아주 간단한 명령 실행 모델을 정의한다.
A processor appears to operate according to this model.
프로세스는 이 명령 실행 모델에 따라 실행한다.
(In this model, instructions execute in strict sequence, and executing a single instruction involves performing a series of step)
이 모델에서 명령은 엄격한 순서대로 실행되며, 하나의 명령을 실행하는 것도 일련의 과정 수행을 포함한다.
The processor …
프로세서는 ...
- reads the instruction from memory pointed at by the program counter(PC)
PC가 가리키고 있는 메모리의 명령을 읽는다.
- interprets the bits in the instruction
명령의 비트를 해석한다.
- performs some simple operation dictated by the instruction
명령이 지시하는 심플한 연산을 수행한다.
- and then updates the PC to point to the next instruction(which may or may not be contiguous in memory to the instruction that was just executed)
PC를 업데이트해서 다음 명령을 가리키게 한다. 이 명령은 PC가 가리켰던 이전 명령과 연속적일 수도 있고 아닐 수도 있다.
그래서 결국 ISA가 뭔가요?
ISA는 모델입니다. 프로세서가 명령을 실행할 때는 아주 단순한 명령을 이 명령 실행 모델에 따라 연산을 수행하는 거죠. 같은 64비트 명령이라도 ISA에 따라서 다르게 해석될 수 있고, 우리는 이를 보통 아키텍처라고 부릅니다.
Hello, World를 실행하는 과정
이렇게 프로그램 하나의 실행 과정을 봤습니다. 마지막으로 Hello World의 실행 과정을 그림과 함께 이해해보겠습니다.
주체를 이해하는게 중요하다
프로그램 실행 과정의 각 주체를 이해하는게 중요합니다. ‘프로세서’는 ‘기계 언어 인스트럭션’을 실행합니다. ‘기계 언어 인스트럭션’은 우선 디스크에 있는 데이터를 메모리로 복사하고, 메모리에 있는 ‘hello, world\n’ 텍스트
를 레지스터 파일로 복사합니다. 그리고 다시 기계어 인스트럭션은 이 복사된 파일을 스크린으로 복사합니다.
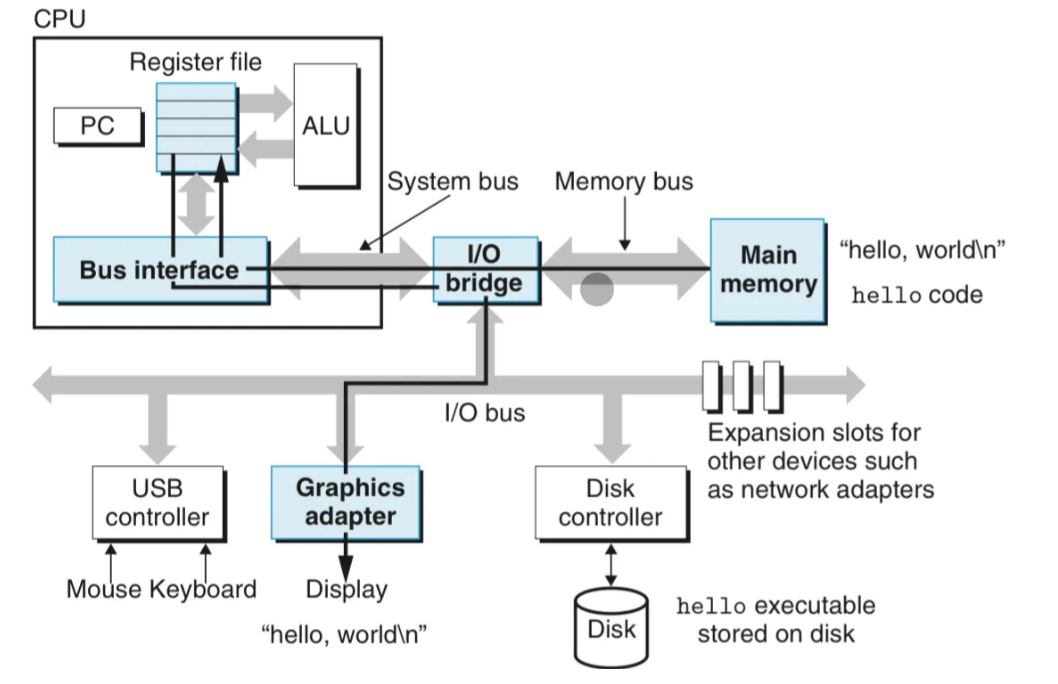
캐시 등장해주세요
위의 경우, 메커니즘을 이해하기 위해서 Hello, World의 출력 과정을 '복사'의 연속으로 살펴봤습니다. 하지만 이 복사 과정은 꽤나 오버헤드가 큽니다. 프로세서의 기계어 명령 실행은 빠릅니다. 프로그램의 디스크-메모리 복사는 느립니다. 메모리에 있는 텍스트를 레지스터로 복사하는 과정도 느립니다. 레지스터의 텍스트를 스크린으로 처리하는 명령 자체는 빠르지만 이 과정의 복사는 또 느립니다.
중요한 건 빠른 연산과 느린 연산이 하나의 프로그램 실행 과정에 중첩되어 있어 병목이 발생한다는 점입니다. 다 같이 느리면 어쩔 수 없지만 부분적인 느림은 해결하기만 하면 속도 향상에 도움이 되겠죠. 그래서 캐시가 등장합니다.
논리적으로 프로세서는 레지스터 파일만 있어도 연산을 수행할 수 있습니다. 하지만 레지스터와 메모리의 성능차이는 극심하고, 디스크는 더 느리죠. 그리고 레지스터의 성능 향상으로 인해 이 차이는 더 벌어져버렸습니다. 그래서 캐시가 등장했습니다. 캐시의 정의는, '근미래에 아마도 필요할 정보를 일시적으로 저장하는 저장소'입니다. '아마도'가 골때리죠. 프로그램 특성 상 어떤 데이터가 아마도 근미래에 필요할지 알 수 없기 때문에 FIFO, LRU, RR 등 다양한 전략이 사용됩니다.
프로세서 내의 캐시는 L1, L2 캐시가 있다 정도만 알면 될 거 같습니다. 둘 모두 SRAM으로 만들어집니다. 더 중요한 것은 메모리 계층 상의 캐시 개념을 이해하는 겁니다.
메모리 계층은 모든 계층을 캐시로 만든다
간단한 개념이기 때문에 자세히 다루지는 않겠습니다. 지금까지 본 온갖 저장소를 빠른 순서대로 나열하면 그게 메모리 캐시입니다. 그리고 각 계층은 자신보다 상위의 저장소를 위한 캐시로 봉사합니다.
이 챕터의 나머지 내용들
나머지 내용들은 꽤 중요하지만 처음 보면 잘 이해가 안 되는 그런 개념들입니다.
운영체제는 I/O 장치를 파일처럼 다룬다
이건 네트워크 프로그래밍에서도 아주 중요한 개념입니다. 파일이라는 포맷 안에서 운영체제는 컴퓨터 하드웨어의 데이터를 외부로 복사하거나 읽어들입니다. 소켓도 파일이고, 마우스와 프린터, 디스크도 파일이죠.
프로세스
프로세스는 실행 프로그램의 추상화입니다. 각각의 프로세스는 자기만의 페이지테이블을 통해 독립적인 가상주소 공간을 가진다고 생각할 수 있죠. 아래 나오는 스레드와의 가장 큰 차이점은, 프로세스는 실행 프로그램으로서 독립적인 가상 주소 공간을 가지지만 스레드는 그렇지 않고, 여러개의 루틴이 하나의 주소 공간을 공유한다는 점일 겁니다.
스레드
쓰레드는 기본적으로 하나의 루틴(control flow)입니다. 함수 스택이 연속적으로 이어진다고 생각하기 쉽지만, 스레드가 있으면 하나의 프로세스 런타임 스택 안에서 동시에 동작하는 여러 루틴을 구현할 수 있죠. 각각의 스레드 초기화 함수는 main() 역할을 합니다.
커널
The kernel is the portion of the operating system code that is “always resident in memory”
커널은 메모리에 상주하는 운영체제 프로그램의 부분입니다. 그렇다면, 커널은 왜 메모리에 상주해야 할까요? 커널이 하는 일을 생각해봅시다. 커널은 프로세스를 관리합니다. 가령 프로세스가 메모리 접근 요청을 하면, MMU는 이를 받아서 물리 주소로 변환하는 과정을 수행하고, 이 작업을 위한 페이지 테이블을 관리하기 위해 소프트웨어적으로 구현된 Supplemental Page Table을 운영체제가 관리합니다. 만약 페이지 폴트가 나서 운영체제가 SPT를 참조할 때마다, 이 작업을 수행하는 프로그램을 메모리로 올린다면 아주 번거롭겠죠, 아니 애초에 이건 재귀적으로 불가능한 작업일 겁니다. 페이지 폴트 처리를 하기 위해서 페이지 폴트를 처리해주는 커널 코드를 올린다니, 말이 안 되죠.
