CSAPP의 네트워크 프로그래밍과 MCU의 Proxy Lab 실습에 대한 정리입니다.
Client-Server Programming Model에 대해
모든 네트워크 어플리케이션은 클라이언트-서버 모델에 기초를 두고 있습니다. 그러면 이때, 클라이언트와 서버는 기계가 아님을 명심하고 넘어가야 합니다. 이들은 프로세스입니다. 프로세스의 역할에 따라, 하나의 소프트웨어 아키텍처에서도 프로세스는 클라이언트일 수도, 서버일 수도 있습니다.
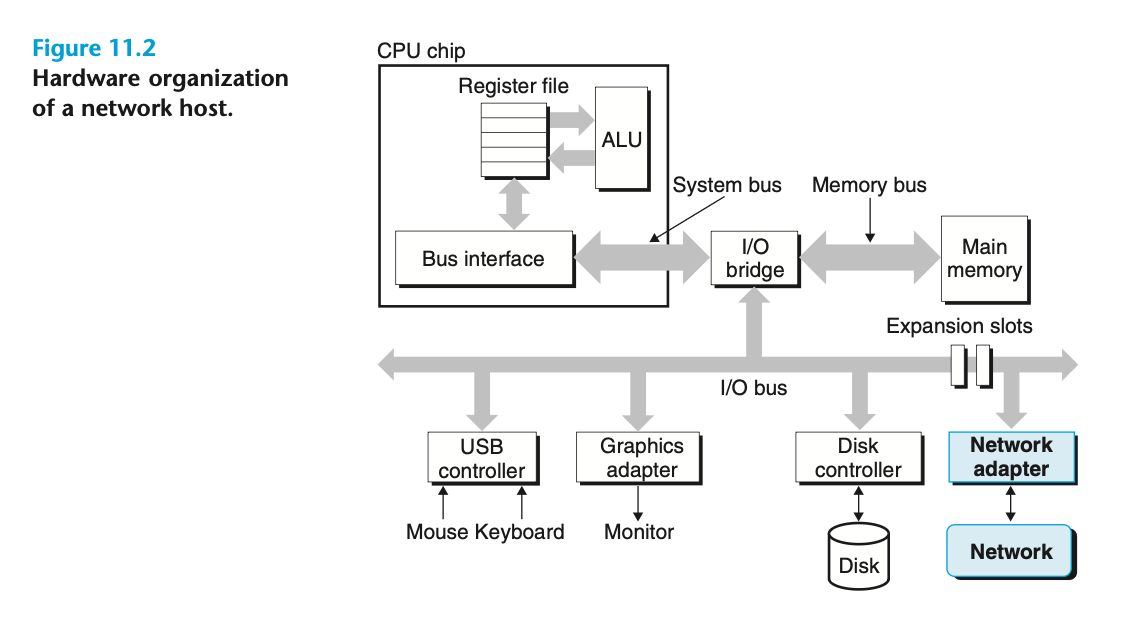
Ethernet이 뭔가요? (그 외 기타 개념들)
가장 유명한 LAN(Local Area Network)의 기술입니다. 그 외에도 기본적인 개념을 아래와 같이 살펴볼 수 있습니다.
- MAC 주소: 각 이더넷 어뎁터가 비휘발성 메모리에 가지고 있는 유니크한 48비트 주소
- 프레임: 호스트가 보내는 bits의 덩어리
- 라우터: 각 LAN을 연결하여 인터넷을 구성하는 특수 컴퓨터
- 프로토콜 소프트웨어: 각 호스트가 다른 호스트로 데이터를 전송할 수 있게 하는 솔루션. 서로 다른 네트워크 간의 차이를 완화
- 패킷: 헤더와 페이로드로 구성된 청크.
결국 TCP, IP, UDP 모두 호스트가 다른 호스트로 데이터를 전송할 때 쓰는 '프로토콜 소프트웨어'군요
internet과 Internet의 차이
Internet은 Global IP internet을 의미하는, internet의 구현 방식 중 하나입니다. 그렇다면 internet은 뭘까요? 프로그래머의 관점에서, 인터넷은 호스트의 집합입니다. 단, 아래의 조건을 따르죠.
- 호스트 집합의 모든 호스트는 32비트의 IP 주소로 매핑돼 있다.
- IP 주소는 인터넷 도메인 이름이라는 identifier로 매핑돼 있다.(모든 경우는 아니다)
- 한 호스트의 프로세스는 다른 호스트의 프로세스와 소통할 수 있다.
그렇다면, 브라우저 프로세스에서 url 칸에 google.com을 입력하면 어떻게 될까요? 이 요청은 우선 운영체제의 DNS 캐시를 조회합니다. 여기서 캐시 미스가 발생하면 ISP 사업자가 관리하는 내부 재귀 DNS 서버에 조회를 하게 되고, 여기서도 찾지 못하면 ICANN이라는 비영리 단체가 관리하는 루트 네임 서버로 요청이 날아가죠. (이 비영리 기관의 루트 네임 서버가 없어지면 사람들은 인터넷을 못 쓰겠군요!)
이렇듯, Internet은 하나의 기술이 아니라, 꽤 많은 이해 관계가 직접적으로 걸려있는 글로벌 사업에 가깝습니다.
UDP는 대체 TCP와 뭐가 달라요?
Applciation Programmer의 관점에서, UDP는
host to host가 아닌 process to process로 데이터 전송이 가능하다는 차이점이 있습니다. 이 점이 TCP와의 가장 큰 차이점이죠.
도메인 네임에 대해서 더 자세히
도메인 네임은 기본적으로 트리 구조로 구성되고, 트리 상 위치가 인코딩돼 있습니다. 맨 하위 노드에는 IP가 매핑돼 있군요.
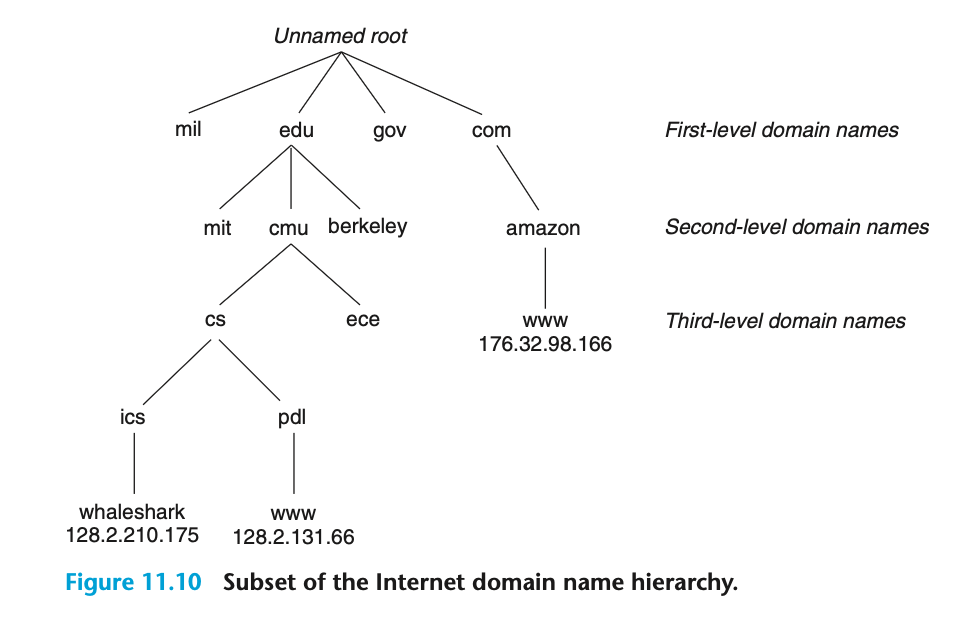
그렇다면 이 트리는 기본적으로 어떤 서버에 저장돼 있을까요? 아까 살펴봤던 전 세계(IPS 사업자, ICANN 등) 관리 컴퓨터의 서버에 저장돼 있습니다. 운영체제의 DNS 캐시에는 트리가 아니라 해시 자료구조 등으로 구현돼 있죠.
포트는 뭔가요?
우선 연결이 뭔지 정의해봅시다. 연결은 프로세스를 연결하는 점 대 점(point to point) 연결입니다.
소켓은 이 연결의 엔드 포인트입니다. 프로세스와 프로세스는 각각의 소켓을 통해서 연결되죠. 그리고 이 소켓이 파일과 같은 층위의 개념이라는 사실은 아주 중요합니다. 운영체제는 소켓을 파일처럼 관리합니다. 그래서 연결을 통해 '읽기'와 '쓰기'가 가능하죠. 그렇다면, 프로세스 입장에서는 '소켓'을 쉽게 식별할 수 있을 겁니다. 파일 디스크립터를 이용해 파일을 식별하듯이요. 하지만 네트워크 입장에서는 각 프로세스의 소켓 번호를 일일이 알 수 없습니다. 이때 네트워크가 소켓을 찾아가기 위해 쓰는 값이 포트 번호입니다.
운영체제 입장에서도 마찬가지입니다. 운영체제가 각 프로세스의 파일 디스크립터를 모르듯이, 소켓도 모릅니다. 따라서 포트 번호 체계를 통해 호스트에서 사용중인 소켓들을 관리할 수 있죠. 소켓이 프로세스를 위한 추상화라면, 포트는 운영체제와 네트워크를 위한 추상화입니다.
그렇다면 이 소켓들을 네이버 접속할 때도 쓰는 건가요?
네 맞아요. 브라우저가 네이버에 접속하면 네트워크 통신을 통해 운영체제로부터 소켓을 생성하고, 내부적으로 이 소켓에 파일 디스크립터를 할당시켜 관리합니다. 소켓은 브라우저와 네이버 웹 서버 간의 통신 엔드포인트로 사용되고, 네이버의 IP 주소와 함께, 웹 서비스 기본 포트인 80(HTTP) 또는 443(HTTPS)를 통해 웹 서버의 '프로세스'를 지정합니다. 브라우저는 이 소켓을 통해서 HTTP/HTTPS 요청을 보내고, 서버로부터 응답을 받아 웹 페이지를 렌더링합니다.
그럼 웹 소켓과 이런 TCP 소켓은 차이가 뭔가요?
TCP 소켓이 더 저수준입니다. TCP 소켓은 운영체제 TCP 스택 위에서 동작하며, 저수준 바이트 스트림을 통해 데이터를 주고받는 기본적인 네트워크 통신 수단입니다. 반면 웹소켓은 HTTP 프로토콜 위에서 연결되어 초기 핸드셰이크 이후 전이중 양방향 통신이 가능한 '프로토콜'입니다. TCP 소켓 위에 추상화된 프로토콜이고, 브라우저에서 저지연 통신이 가능하도록 설계됐습니다.
에코 서버를 구현해 봤다면, 아래를 명심해야 합니다.
에코 서버: TCP 소켓 단위의 가장 단순한 형태의 네트워크 서버. 여기서 HTTP 프로토콜 타입으로 작성된 메시지를 서버가 해석할 수 있으면 이를 HTTP 서버라고 부르면 된다.
웹소켓: HTTP 위에서 더 추상화된 양방향 통신 프로토콜
수미상관
네, 결국 대체 프로토콜이 뭐냐, 소켓이 뭐냐, 포트가 뭐냐 이런 문제들은 서버-클라이언트 모델에서 서버와 클라이언트가 '프로세스'라는 점을 이해하고 나면 많은 부분 해소됩니다.
네트워크는 연결입니다. 연결은 프로세스와 프로세스간의 양방향 통신을 가능하게 합니다. 이 연결을 통해 데이터를 요청하면 클라이언트라고 부릅니다. 요청받은 데이터를 보내면 서버라고 부릅니다. (실제로는 connectionFd, listenFd, clientFd 처럼 소켓을 사용하는 방식이 서로 다릅니다.)
TCP 연결을 통해 데이터 패킷을 주고받습니다. 이때 데이터에 HTTP 형식으로 메서드와 body가 포함돼 있으면 클라이언트는 HTTP 프로토콜로 서버에 요청을 보낸 겁니다. 이를 서버가 받아서 해석할 수 있으면 그 서버도 HTTP 서버인 것입니다. 소켓은 파일 디스크립터를 통해 각 프로세스가 관리하기 때문에 운영체제와 네트워크가 각 연결을 식별하기 위해서는 소켓의 더 넓은 영역에서의 추상화가 필요합니다. 그게 포트입니다.
소켓 인터페이스가 뭔가요?
소켓 인터페이스는 네트워크 응용 프로그램을 만들 때 필요한 공용 함수들의 집합이라고 보면 됩니다. 커넥션을 열고, 커넥션으로부터 데이터를 읽고, 반대로 쓰는 등의 액션을 위해 준비된 인터페이스입니다.
소켓 인터페이스를 알아보기 전에, 소켓=파일이라는 사실을 다시 한 번 짚고 넘어가죠.
소켓 인터페이스의 가장 큰 문제 인식은, 어떻게 소켓을 지정할 것인가였습니다. 지금은 보이드 포인터가 있지만, 그 당시에는 없었죠. 그래서 뭘 썼나요? 별도의 구조체를 썼습니다.
// generic socket address structure (for connect, bind, and accept)
struct sockaddr {
uint16_t sa_family; // protocol family
char sa_data[14]; // address data
};구조체 안에 14 byte의 문자열이 있는 모습을 볼 수 있죠. 소켓 주소가 여기에 지정돼 있습니다. 이 구조체를 소켓을 지칭하는 '포인터'로 쓴 것이죠.
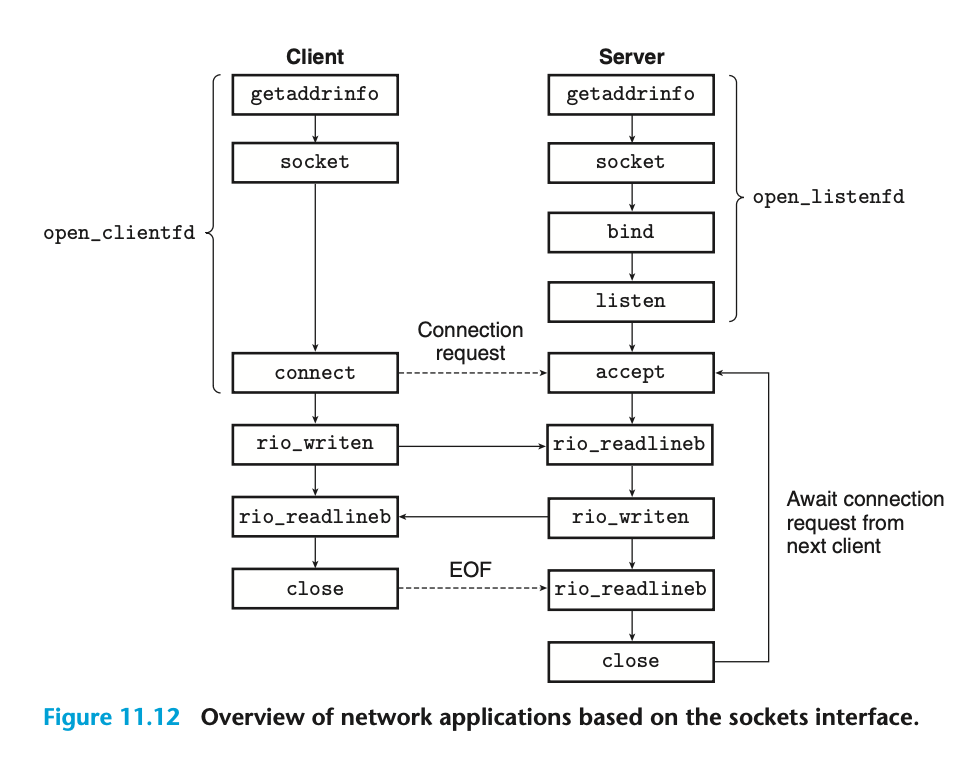
그렇다면 위 그림에 나오는 대부분 함수들을 이해할 수 있습니다. get_addr_info 함수는 미루고, socket 함수를 먼저 보도록 하죠.
#include <sys/types.h>
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
Returns: nonnegative descriptor if OK, -1 on error소켓 함수의 구체적인 구현은 공개돼있지 않습니다.
어라, socket 함수는 왜 이렇게 단순하죠?
소켓함수는 연결을 여는 함수가 아닙니다. 소켓을 여는 함수죠. 마치 파일을 열고 파일 디스크립터를 돌려주는 filesys_open 함수처럼, 소켓도 운영체제 내부적으로 소켓을 열고 소켓의 파일 디스크립터를 리턴합니다. 그때 운영체제가 고려하는 건 도메인, 타입, 그리고 프로토콜이죠. 이것들에 대해서는 구체적으로 살펴보지 않겠습니다.(저도 잘 모릅니다)
아무튼 socket 실행 결과 서버든 클라이언트든 빈 소켓 하나를 가지게 되는 셈입니다. 그럼 다음으로 할 일은 간단합니다. 이 소켓을 연결의 엔드포인트로 쓰게끔 연결을 열고, 데이터를 그 파일 디스크립터에 쓰거나 읽으면 됩니다.
프로세스가 자신의 소켓을 열었다면 다음으로 해야 할 일은 상대방의 소켓에 이 소켓을 연결하는 일이겠죠? 이를 위해서 socketaddr을 알아야 할 겁니다. 이 소켓 주소를 탐색하는 함수가 getaddrinfo입니다.
getaddrinfo
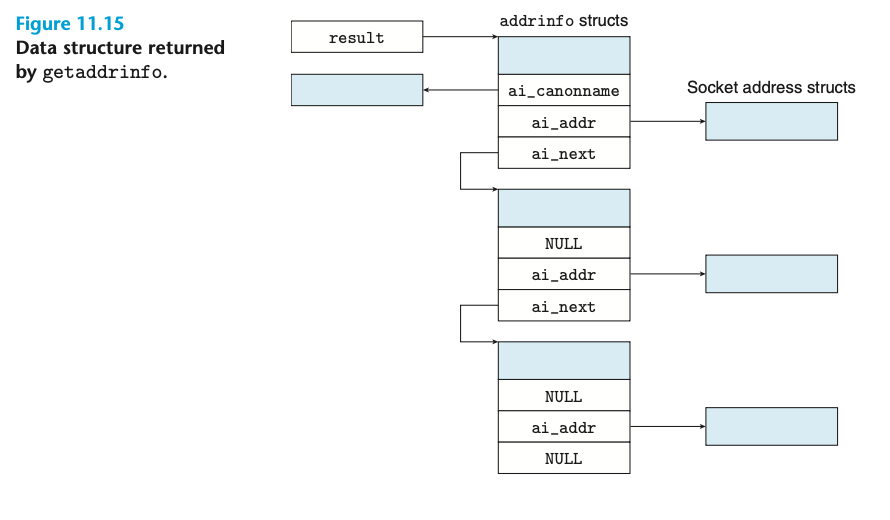
이 함수는 getaddrinfo가 돌려주는 구조체의 명세를 담고 있습니다. 여러모로 복잡하지만, 결국은 아까 보았던 '소켓의 포인터'역할을 하는 socketaddr 구조체를 하나 찾기 위해 이런 연결 리스트의 구조체를 조회하는 것으로 보면 됩니다.
int getaddrinfo(const char *host, const char *service, const struct addrinfo *hints, struct addrinfo **result);
Returns: 0 if OK, nonzero error code on error여기서 host가 지정되는 모습을 볼 수 있군요! 그렇다면 포트는 어디서 지정될까요? service가 바로 포트입니다.
connect
이제 소켓과 목적지 주소가 생겼으니 클라이언트와 서버를 나누어서 생각해보겠습니다. 클라이언트 입장에서는 이제 준비가 끝났습니다. 연결 대상인 소켓도 있고, 목적지 소켓 주소도 알고 있습니다. 이 두가지 인수로 연결을 수행하는 함수가 connect 함수입니다. connect의 인자값을 살펴봅시다. clientfd는 현재 클라이언트 프로세스가 socket함수로 열었던 소켓의 파일 디스크립터겠군요. addr 포인터 변수는 당연히 소켓 주소 구조체의 주소일겁니다. socketlen_t는 뭘까요? 소켓 구조체는 크기가 다 다릅니다. 프로토콜 패밀리에 따라서 sockaddr의 크기가 달라질 수 있기 때문에, 연결 대상인 서버에서 '얼마나' 소켓 주소 구조체를 읽어들여야 하는지 알려주기 위해 이를 지정합니다. 이는 IPv4와 IPv6의 차이에서 기인합니다.
#include <sys/socket.h>
int connect(int clientfd, const struct sockaddr *addr, socklen_t addrlen);
Returns: 0 if ok, -1 on error그렇다면 여기서 의문점이 하나 생깁니다. getaddrinfo는 소켓 주소 구조체가 아니라 addrinfo 구조체로 구성된 연결리스트의 더블포인터를 반환해줍니다. 그런데 connect는 소켓 주소 구조체를 바로 인자값으로 받죠. 그렇다면 이 연결 리스트를 순회하며 각 소켓 주소 구조체에 대해 connect를 수행하는 함수가 있다는 사실을 유추할 수 있습니다. 이 함수가 open_clientfd입니다.
아래를 보면, getaddrinfo를 수행 후 결과로 받은 listp를 순회하면서 각각의 경우에 socket과 connect를 시도하는 모습을 볼 수 있습니다.
int open_clientfd(char *hostname, char *port) {
int clientfd;
struct addrinfo hints, *listp, *p;
/* Get a list of potential server addresses */
memset(&hints, 0, sizeof(struct addrinfo));
hints.ai_socktype = SOCK_STREAM; /* Open a connection */
hints.ai_flags = AI_NUMERICSERV; /* ... using a numeric port arg. */
hints.ai_flags |= AI_ADDRCONFIG; /* Recommended for connections */
Getaddrinfo(hostname, port, &hints, &listp);
/* Walk the list for one that we can successfully connect to */
for (p = listp; p; p = p->ai_next) {
/* Create a socket descriptor */
if ((clientfd = socket(p->ai_family, p->ai_socktype, p->ai_protocol)) < 0)
continue; /* Socket failed, try the next */
/* Connect to the server */
if (connect(clientfd, p->ai_addr, p->ai_addrlen) != -1)
break; /* Success */
Close(clientfd); /* Connect failed, try another */
}
/* Clean up */
Freeaddrinfo(listp);
if (!p) /* All connects failed */
return -1;
else /* The last connect succeeded */
return clientfd;
}그럼 서버는 뭐가 다른가요?
서버는 두 종류의 소켓을 관리한다는 점이 다릅니다. 클라이언트는 clientfd에 소켓을 할당해 이를 서버와의 연결 엔드포인트로 쓰는 반면, 서버는 listenfd에 소켓을 열고 이를 accept라는 함수로 넘깁니다. accept는 listenfd로 들어오는 연결을 대기하다가 연결이 들어오면, 새로운 파일 디스크립터를 열고 이를 connection fd(connfd)에게 리턴해줍니다. 서버의 메인 루틴은 이 connfd를 공유자원으로 관리하면서 다른 워커 쓰레드에게 넘겨주는 식으로 '공급자-소비자' 문제로 바꿔 해결할 수도 있습니다.
listenfd = Open_listenfd(argv[1]);
while (1) {
clientlen = sizeof(clientaddr);
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen);
Getnameinfo((SA *) &clientaddr, clientlen, hostname, MAXLINE, port, MAXLINE, 0);
printf("Accepted connection from (%s, %s)\n", hostname, port);
doit(connfd);
Close(connfd);
}