CNN이란?
Convolutional Neural Network의 약자로, 합성곱(convolution)을 수행하는 인공 신경망을 의미합니다.
합성곱의 수행 과정과 신경망의 기본 원리를 각각 알고 있으면 두 개념을 합친 CNN을 이해하는 건 어렵지 않은데요, 무엇보다 합성곱 필터 = 신경망 가중치라는 개념을 이해하는 것이 중요합니다.
아래 글을 통해 자세히 알아보도록 합시다.
7.1.1 CNN
-
CNN: 계층을 조립하여 만드는 것은 기존 신경망과 같지만, 합성곱 계층과 풀링 계층이 등장한다.
-
완전연결, Affine 계층: 인접하는 계층의 모든 뉴런과 결합. affine계층 뒤에 활성화 함수 ReLU 계층이 이어짐.
-
CNN에서는 합성곱 계층과 풀링 계층 추가, 출력 직전 은닉층과 출력층에서는 똑같이 Affine+ReLU, Affine+Softmax 계층을 쓸 수 있음,
-
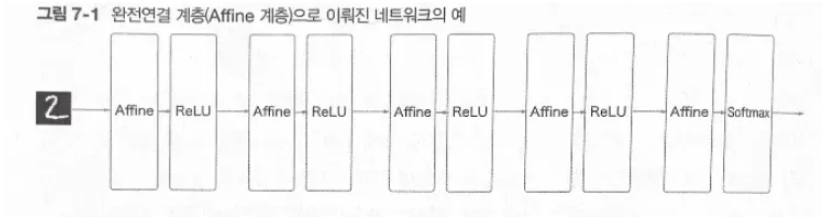
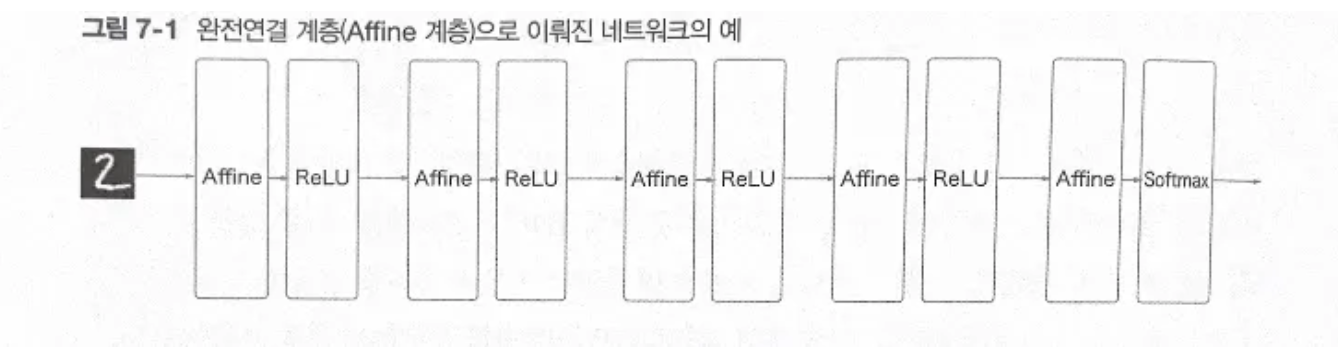
완전연결 계층(Affine 계층)으로 이뤄진 네트워크
-
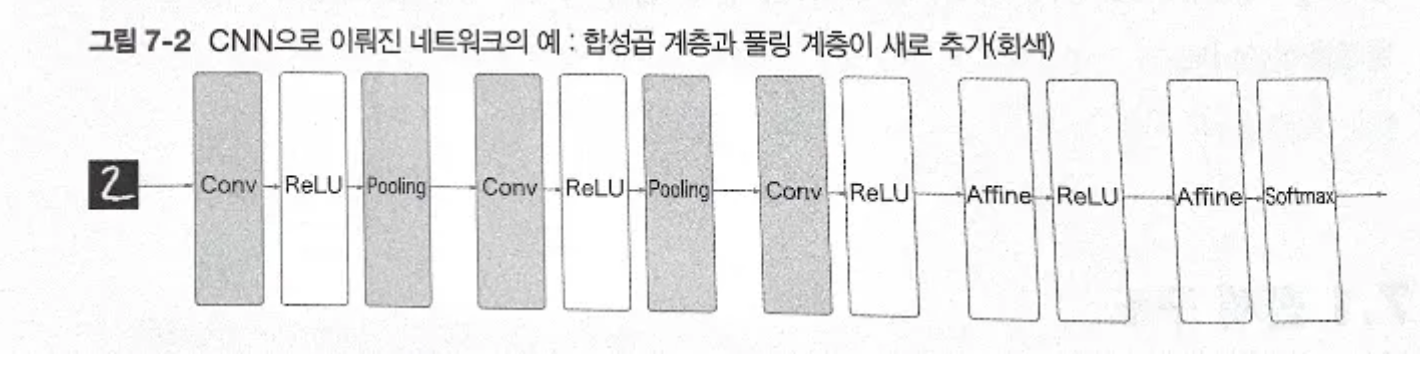
CNN으로 이뤄진 네트워크 예
-
참고
- affine: allowing for or preserving parallel relationships. (옥스포드 영어 사전)
- 즉, 계층간 신경망이 하나하나 다 연결된 것을 의미함.
7.2.1 완전연결 계층의 문제점
- 완전연결 계층에서는 인접하는 계층의 뉴런이 모두 연결되고 출력의 수는 임의로 정할 수 있음.
- 하지만 완전연결 계층에서는 데이터의 형상이 무시됨.
- 예를 들어 이미지는 3차원 형상이며 이 형상에는 소중한 공간적 정보가 담겨 있음. 생각해볼 수 있는 패턴들
- 공간적으로 가까운 픽셀은 값이 비슷하거나
- RGB의 각 채널은 서로 밀접하게 관련되어 있거나
- 거리가 먼 픽셀끼리는 별 연관이 없거나
- 완전연결 계층은 형상을 무시하고 모든 입력 데이터를 동등(같은 차원의) 뉴런으로 취급
- 반면 합성곱 계층은 형상을 유지.
- 특징 맵: 합성곱 계층의 입출력 데이터
- 입력 특징 맵: 합성곱 계층의 입력 데이터
- 출력 특징 맵: 합성곱 계층의 출력 데이터
- 따라서, 입출력 데이터 = 특징맵
7.2.2 합성곱 연산
-
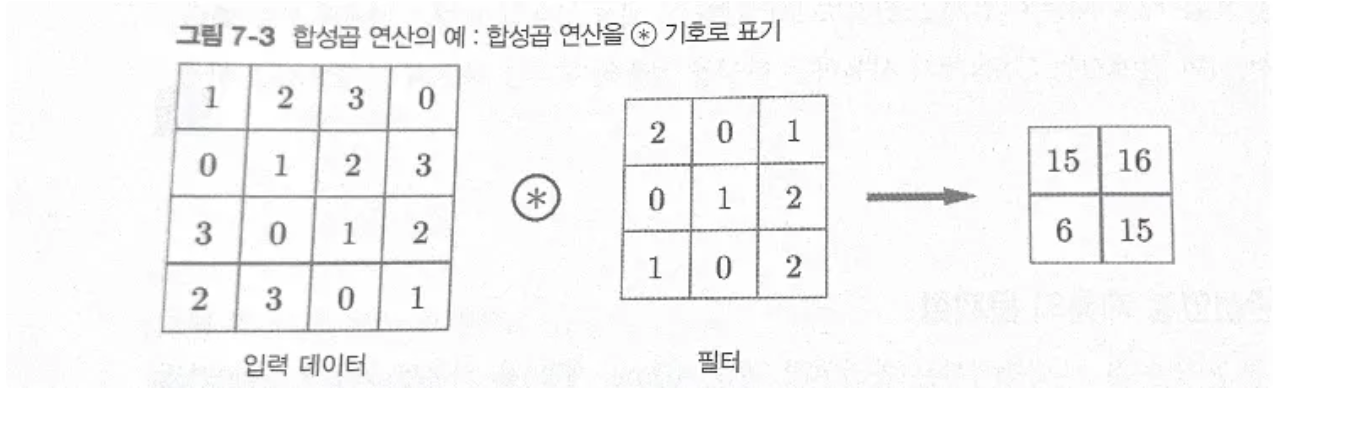
합성곱 연산: 이미지 처리에서 말하는 필터 연산.
-
커널: 필터의 다른 말
-
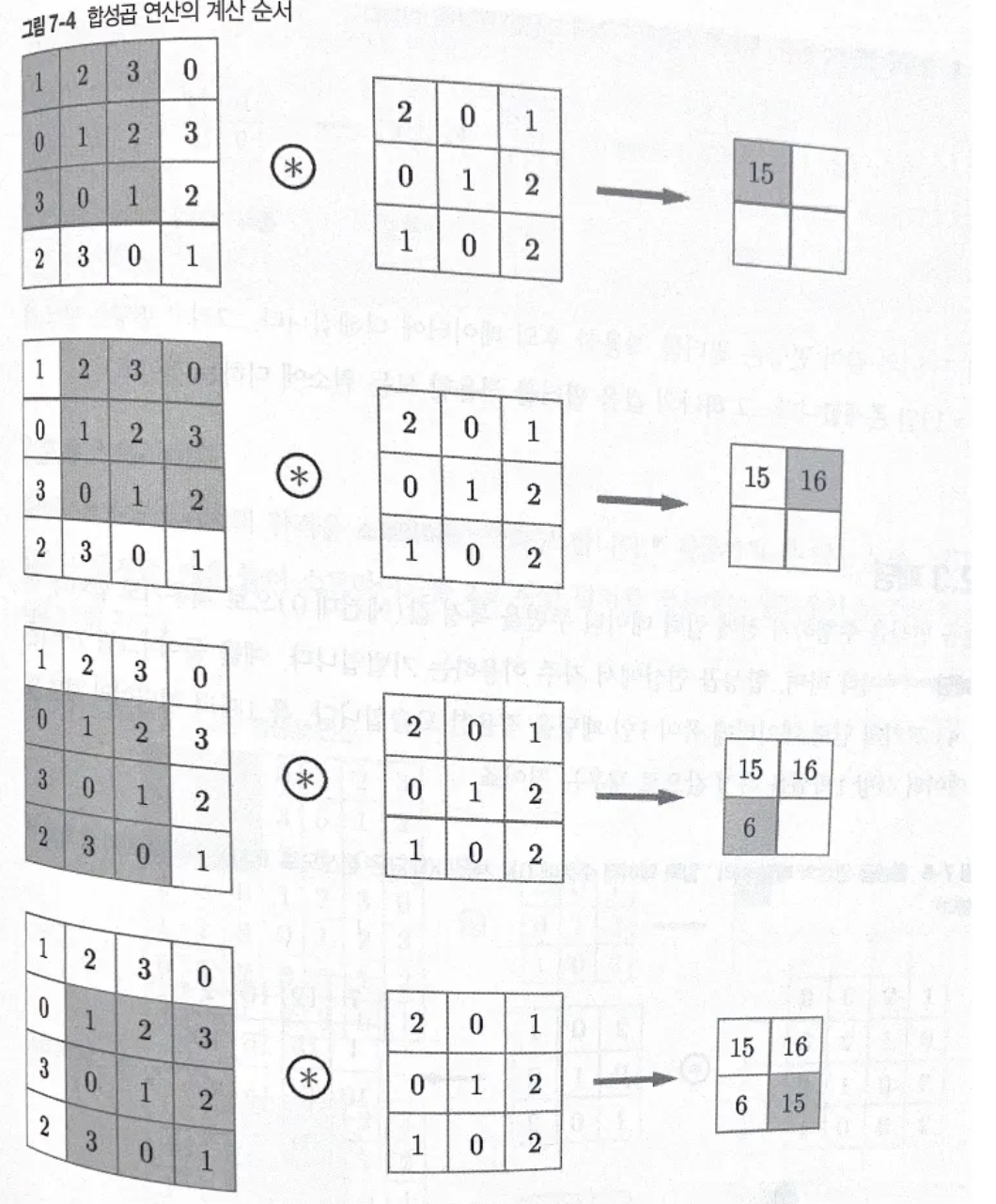
필터의 윈도우를 일정 간격으로 이동해가며 입력 데이터에 적용. (윈도우는 아래 그림의 회색 영역)
-
CNN에서는 필터의 매개변수가 그동안의 ‘가중치’에 해당.
-
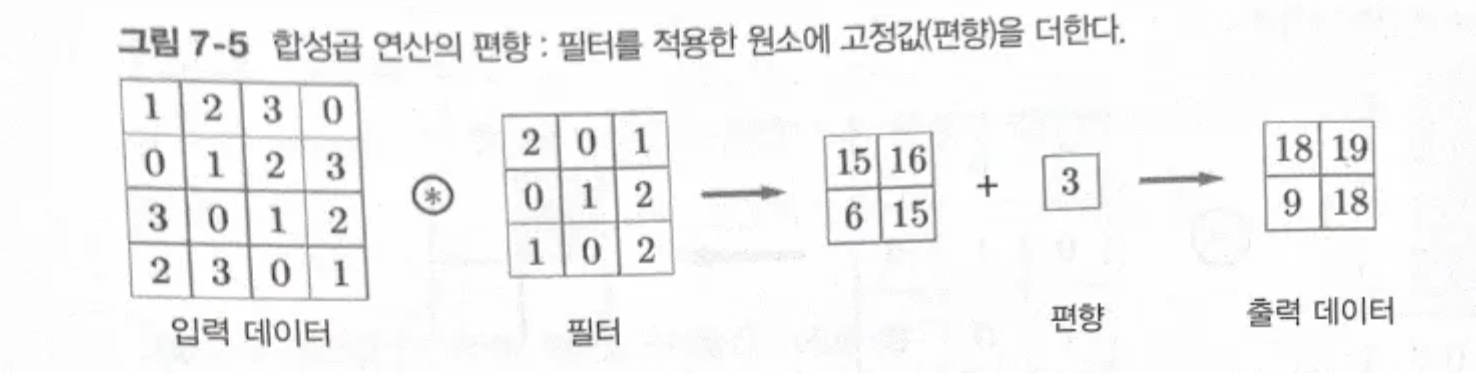
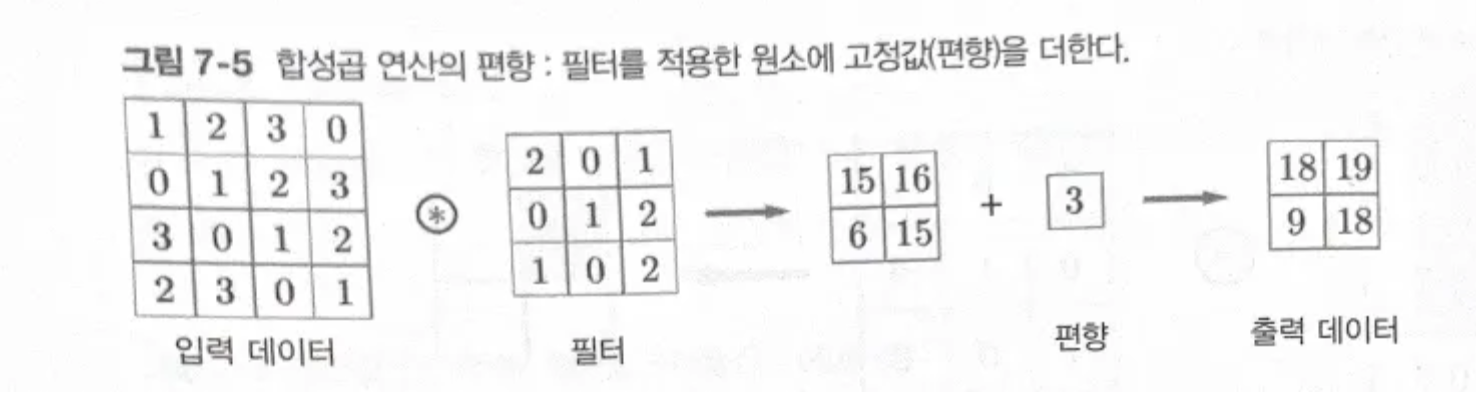
CNN에서의 편향: 편향은 1by1으로 하나만 존재하며, 이를 필터 적용한 데이터 모든 원소에 더함.
-
합성곱 연산의 예
- 합성곱 연산의 계산 순서
- 편향을 적용한 합성곱 연산
7.2.3 패딩
-
패딩: 합성곱 연산 수행 전 입력 데이터 주변을 0으로 채움.
-
패딩 크기를 원하는 정수로 설정할 수 있음.
-
패딩의 목적: 출력 크기 조정할 목적으로 사용. 합성곱 연산을 되풀이하면 출력이 입력보다 줄어들게 되어 심층신경망에서 문제가 될 수 있음. 패딩을 통해 이를 방지.
-
합성곱 연산의 패딩 처리
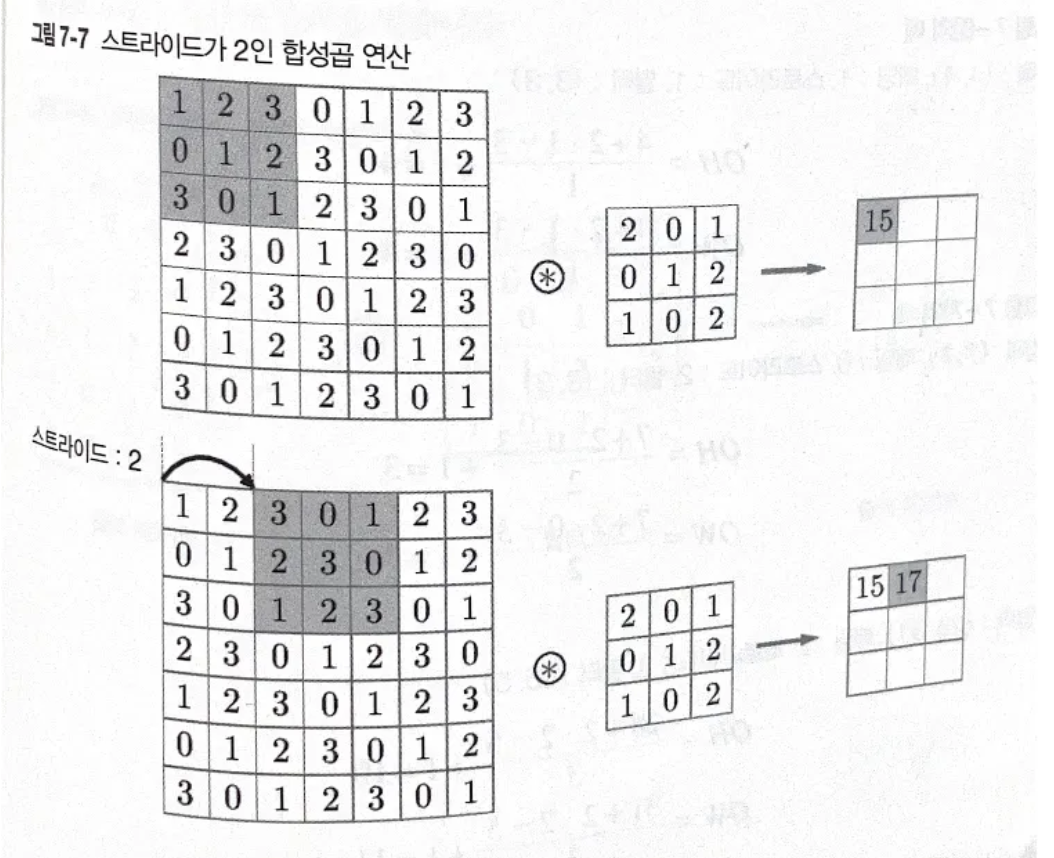
7.2.4 스트라이드
-
스트라이드: 필터를 적용하는 간격(윈도우 이동 간격)
-
스트라이드를 키우면 출력 크기는 작아짐.(패딩을 크기 하면 출력 크기도 커지므로, 둘은 반대 작용을 함.)
-
지금까지 본 입력 크기, 필터 크기, 패딩, 스트라이드를 통해 출력 크기를 계산할 수 있음. 아래 수식을 참고
-
주의 사항: 출력 크기가 정수가 아니면 오류를 내는 등의 대응 필요. 하지만, 딥러닝 프레임워크에서는 그냥 가까운 정수로 반올림 시켜버리기도 함.
-
텐서플로우에서는? TensorFlow(특히 Keras Conv2D, tf.nn.conv2d 등)에서는 공식에 의해 나온 출력 크기가 정수가 아닐 경우 자동으로 내림(floor, 즉 버림) 하여 정수로 만든다고 한다.
-
스트라이드 적용 예시
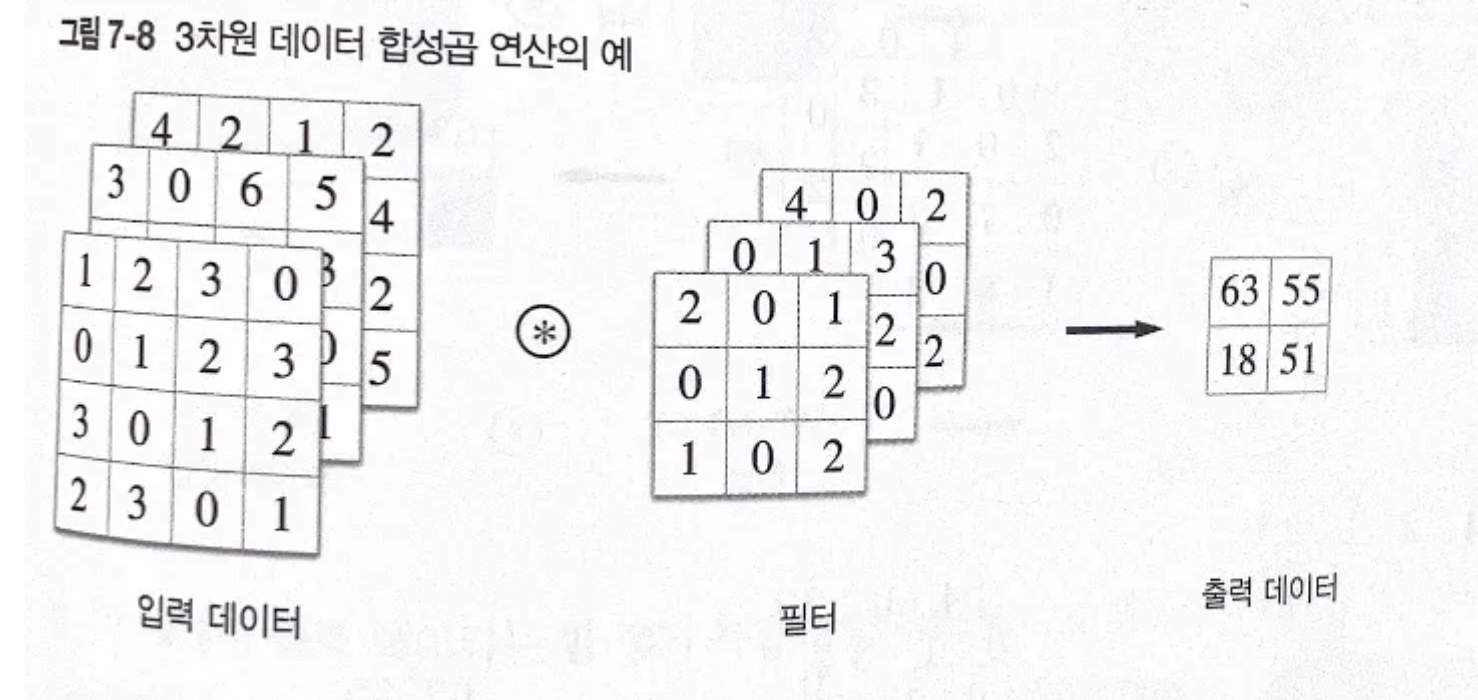
7.2.5 3차원 데이터의 합성곱 연산
-
위에서 본 합성곱은 모두 2차원. 하지만 이미지만 해도 3차원 데이터(세로, 가로, 채널(RGB))임.
-
3차원 데이터의 특징 맵: 채널 방향으로 특징 맵 개수가 늘어남. → 특징 맵 개수만큼 필터가 필요
-
합성곱 연산을 채널마다 수행 후 그 결과를 하나로 더함.
-
당연히, 특징 맵의 채널 수와 필터의 채널 수가 같아야 함.
-
3차원 데이터 합성곱 연산 예시
-
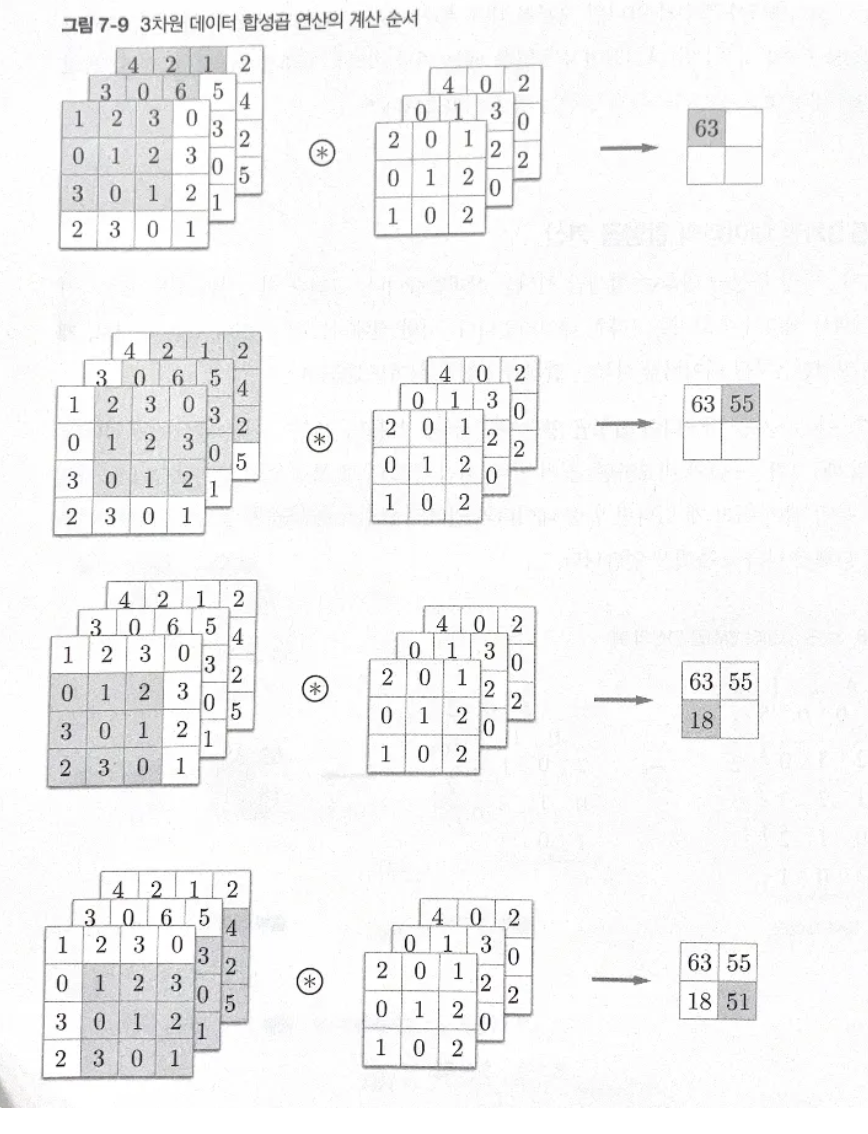
3차원 데이터 합성곱 연산의 계산 순서
7.2.6 블록으로 생각하기
-
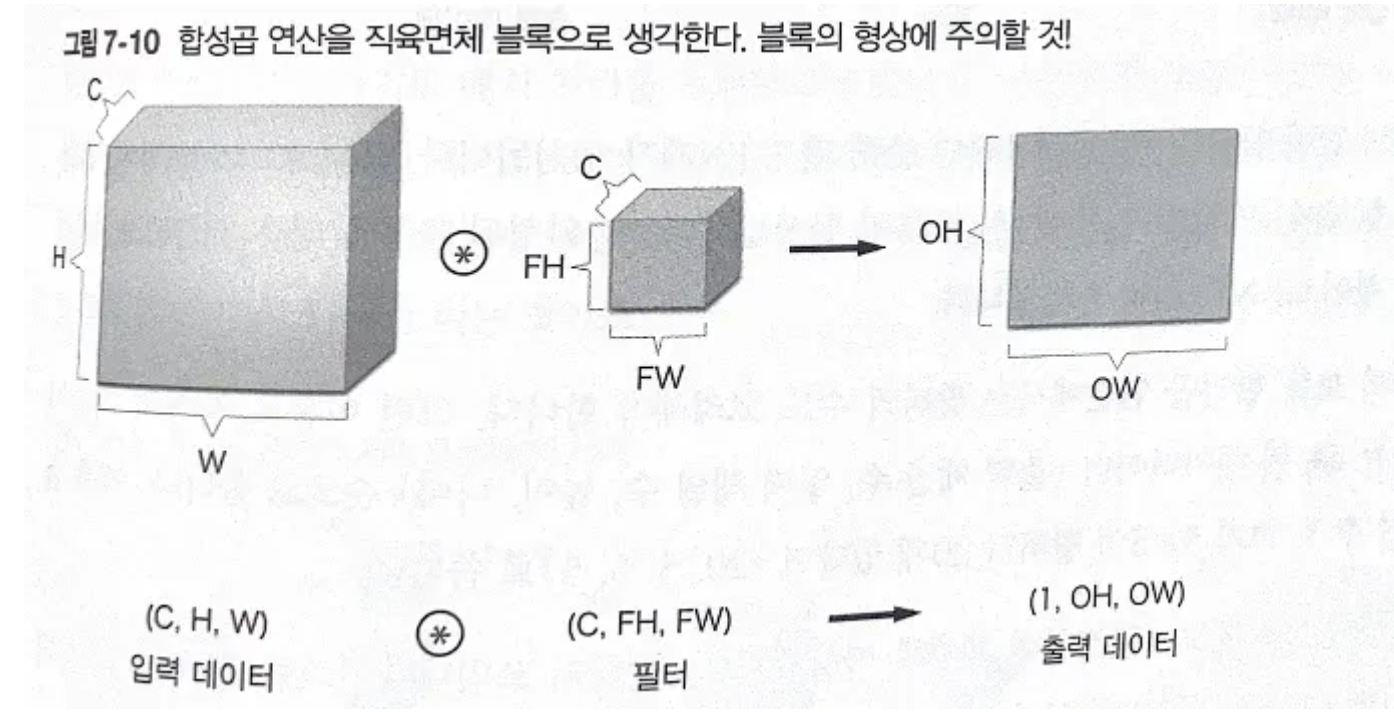
3차원 합성곱 연산 쉽게 생각하는 법: 데이터와 필터를 직육면체 블록이라고 생각하기.
-
출력 맵이 한 장의 특징맵임에 주목. 만약 다수의 특징 맵을 출력으로 보내고 싶다면? 필터를 다수 사용하기.
-
여러 장의 출력 특징 맵을 다음 계층으로 넘기는 것이 CNN의 처리 흐름.
-
필터의 가중치 데이터: (출력 채널 수, 입력 채널 수, 높이, 너비)
-
예를 들어 채널 수 3, 크기 5by5, 필터가 20개인 경우 (20, 3, 5, 5)로 표기
-
편향은 채널 하나에 값 하나씩으로 구성. 아래 그림에서 편향의 형상은 (FN, 1, 1)임. 편향 블록과 출력 특징 맵 블록을 더하면 편향의 각 값이 필터의 출력인 (FN, OH, OW) 블록의 대응 채널의 원소 모두에 더해짐.
-
직육면체 블록으로 보는 합성곱 연산
-
여러 필터를 사용한 합성곱 연산의 예
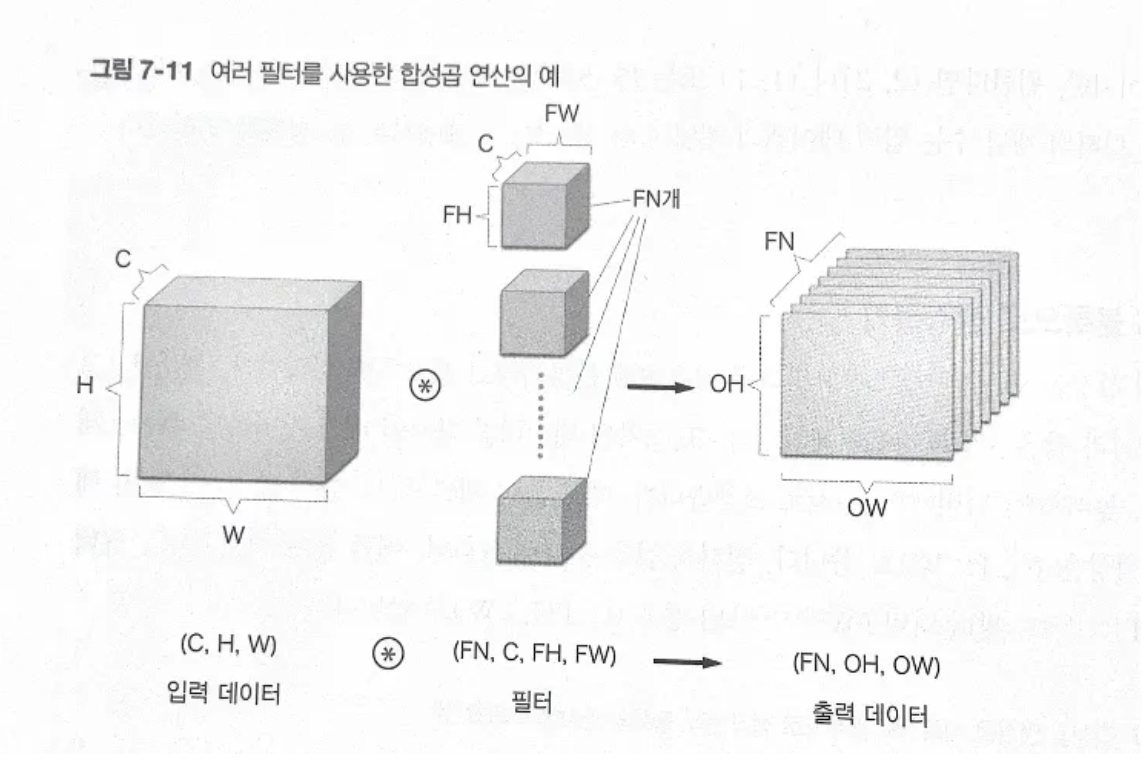
-
합성곱 연산의 처리 흐름(편향 추가)
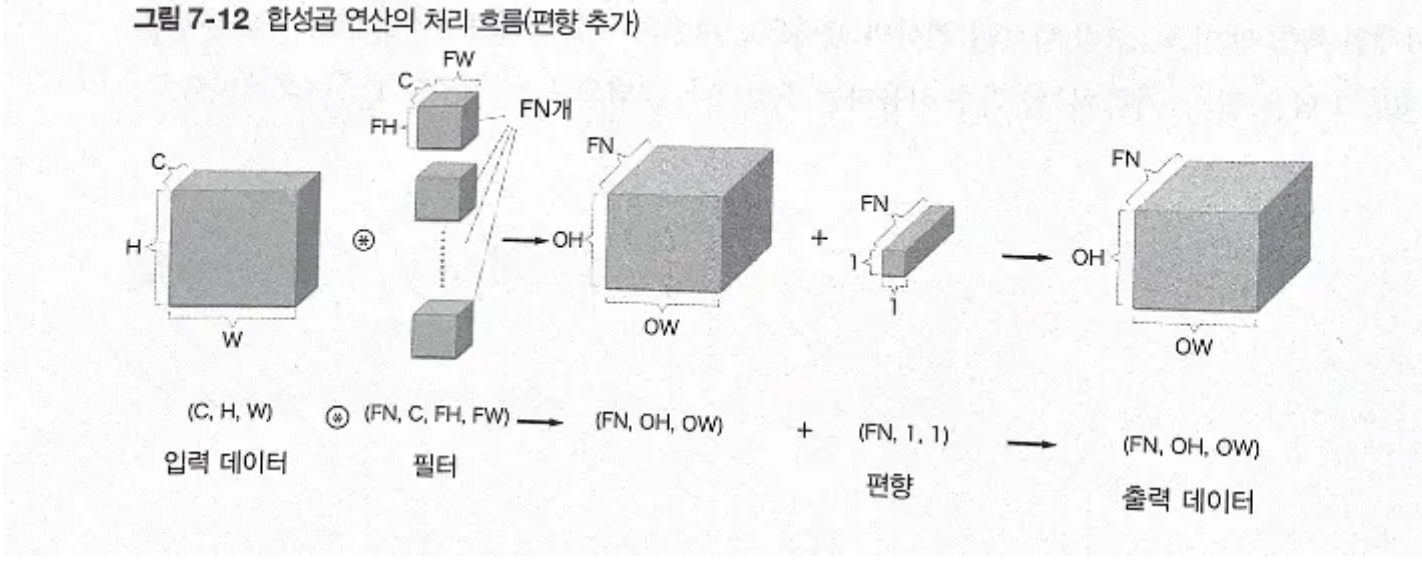
- 3차원 합성곱 연산에서 편향은 크게 다른 점이 없고, 어쨌든 이미지가 블럭이 됐다고 생각하면 각 계산 요소도 쉽게 이해가 가능하다.
7.2.7 (CNN에서의) 배치 처리
-
CNN에서의 배치 처리: 각 계층을 흐르는 데이터의 차원을 하나 늘려 4차원 데이터로 저장.(맨 앞에 배치 처리를 위한 ‘데이터 수’차원 추가
-
신경망에 4차원 데이터가 하나 흐를 때마다 데이터 N(위에서 말한 데이터 수 차원)개에 대한 합성곱 연산이 이뤄짐.
-
합성곱 연산의 처리 흐름
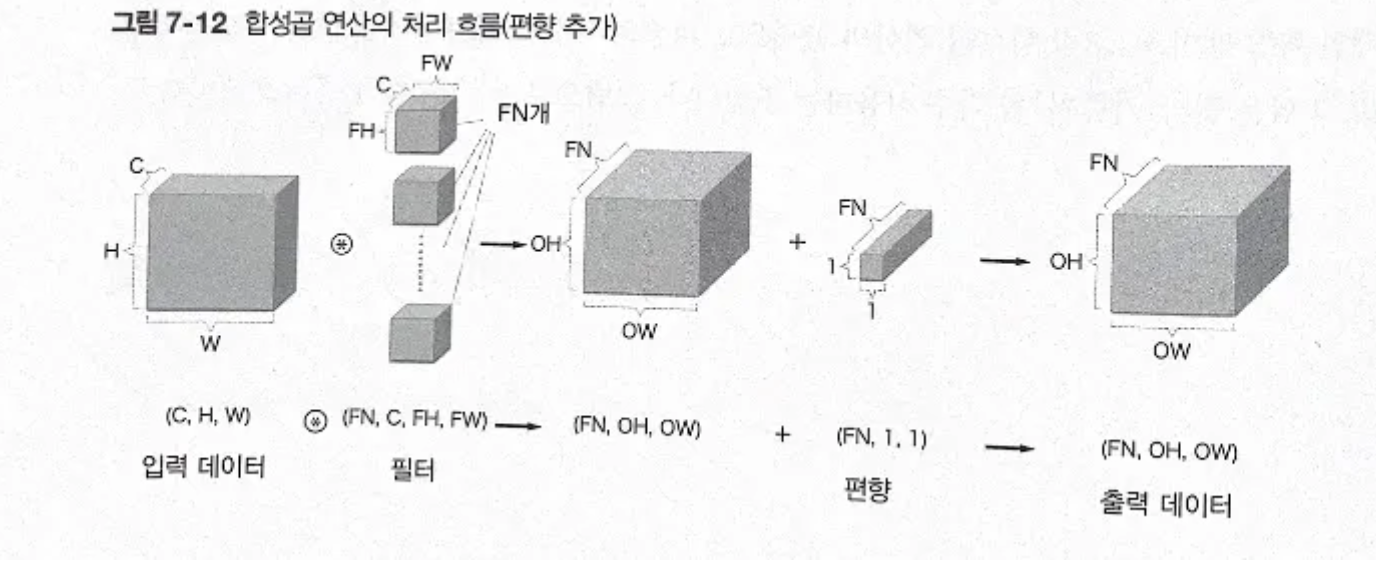
7.3 풀링 계층
-
풀링: 세로, 가로 방향의 공간을 줄이는 연산. 특정 사이즈의 영역을 원소 하나로 집약
-
최대 풀링(max pooling): 특정 영역, 예를 들어 2x2 영역이라 하면 그 영역의 최대 값만을 하나 꺼냄.
-
풀링 윈도우: 풀링 수행할 이동하는 특정 영역.
-
보통 풀링 윈도우와 스트라이드 값을 동일하게 설정
-
2x2 최대 풀링을 스트라이드 2로 처리하는 순서
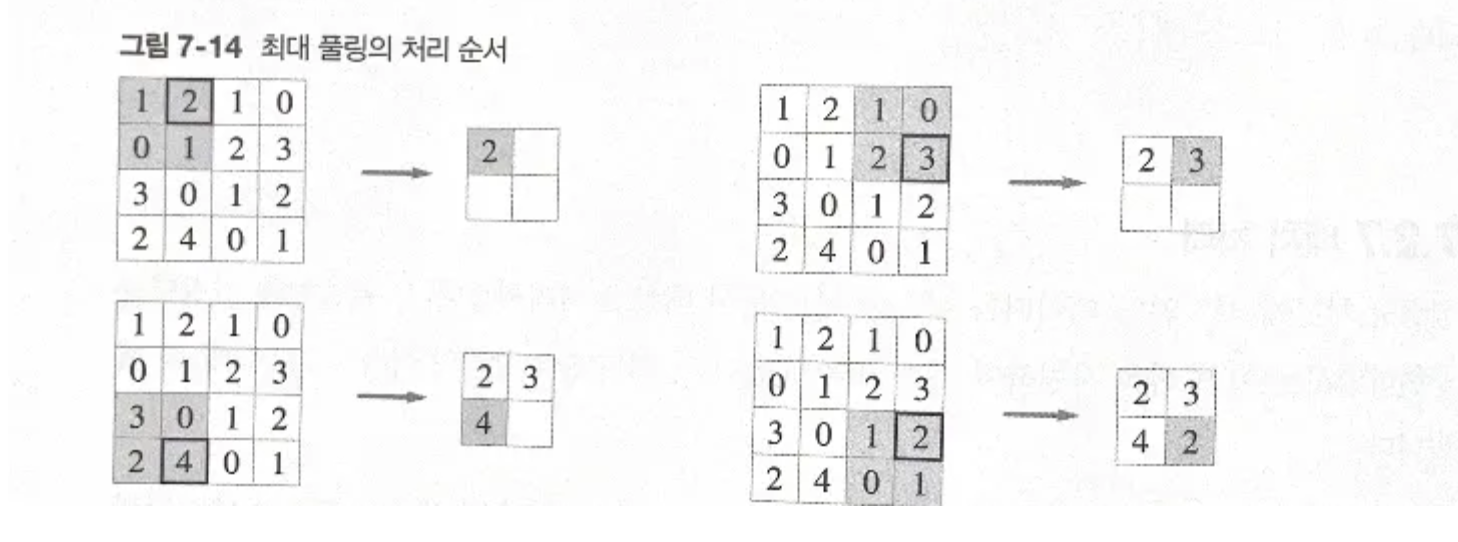
- 합성곱과 연산 목적은 비슷해 보이지만 더 단순한 느낌.
7.3.1 풀링 계층의 특징
-
풀링 계층은 합성곱 계층과 달리 학습해야 할 매개변수가 없음.
-
채널 수가 변하지 않는다.(합성곱이 필터 채널 수 만큼 출력 특징 맵 채널을 만드는 것과 대조)
-
입력의 변화에 영향을 적게 받음(robustness): 최대 풀링을 한다 치면, 풀링 영역 내에서 최대값 요소가 위치를 약간 바꾸거나, 그 외 요소의 값이 약간 바뀌는 것이 출력 특징 맵에 반영되지 않는다.ㄴ
-
풀링은 채널 수를 바꾸지 않는다
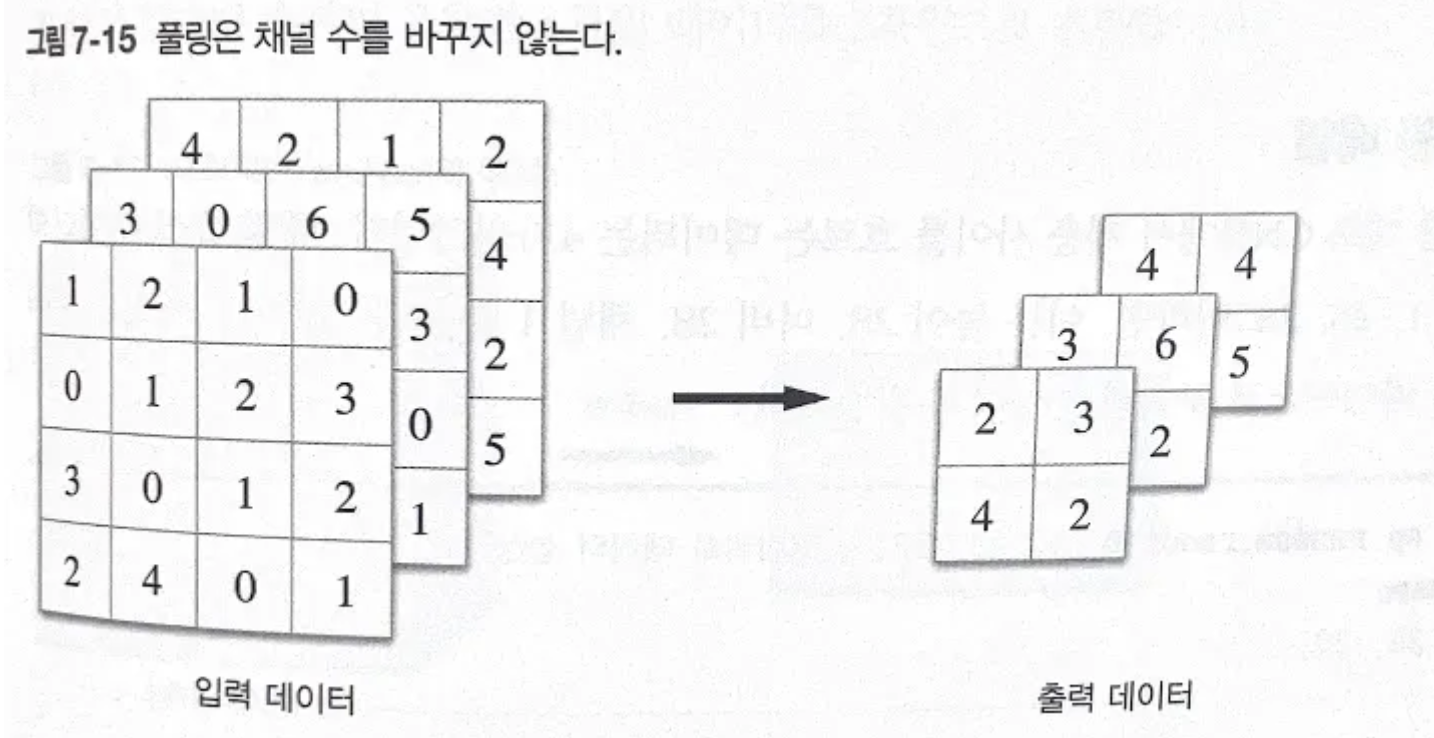
-
풀링 계층의 강건함
- 확실히, 최대 풀링 같은 경우도 합성곱과 비슷한 역할을 하는것 같지만서도 필터가 없이 그냥 정해진 규칙대로(Rule Base) 특징 맵에 연산을 수행하는 느낌이다. 학습 레이어 사이에 있는 규칙의 영역처럼 보인다.
7.4.1 4차원 배열 / 7.4.2 im2col로 데이터 전개하기
- 다시 복습해보는 합성곱 연산의 데이터 차원 구성: (데이터 수, 채널, 높이, 너비)
- numpy로 이 배열들의 곱을 수행할 때 for문 중첩으로 구현하면 성능 매우 떨어짐.(애초에 for문 쓰지 말라고 쓰는 numpy이기 때문)
- im2col이라는 편의 함수가 그래서 필요함.
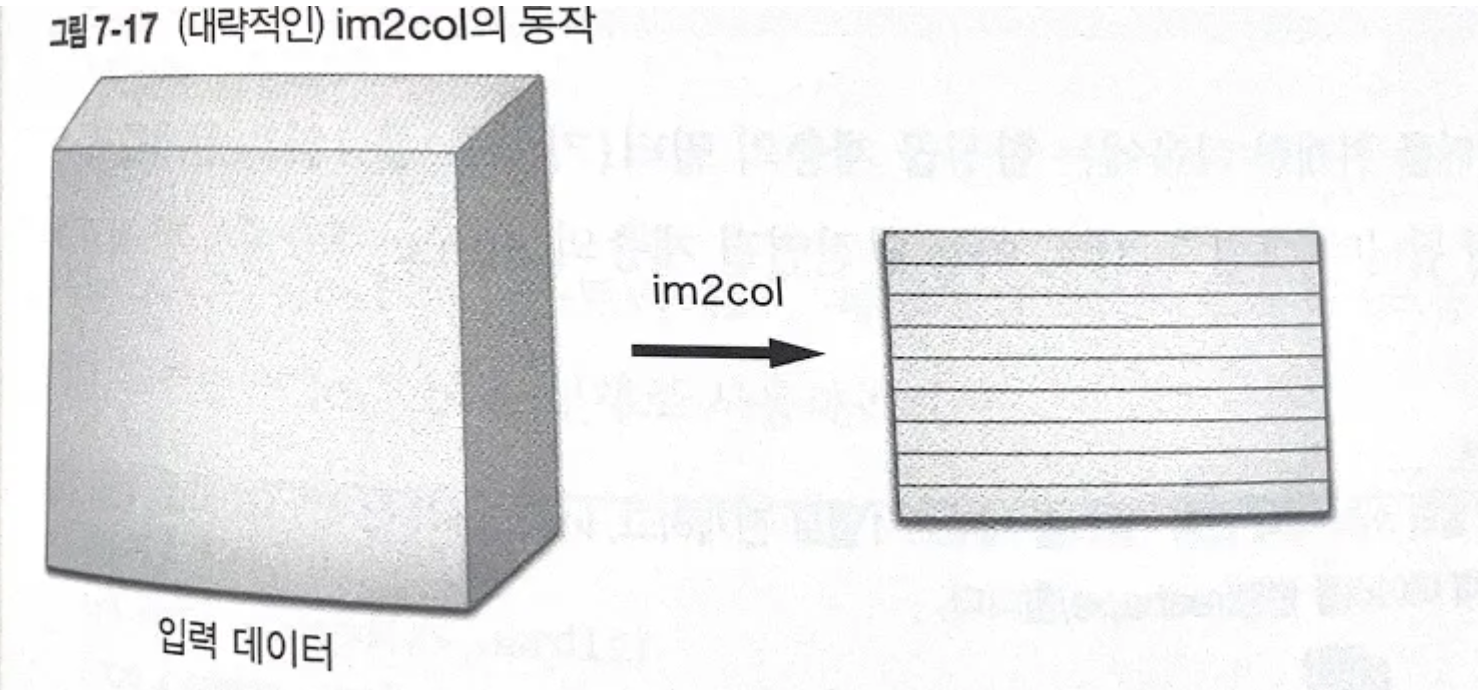
- im2col: 입력 데이터를 필터링(CNN에서의 가중치 연산)하기 좋게 전개하는 함수. 3차원 입력데이터에 적용 시 2차원 행렬로 바뀜.
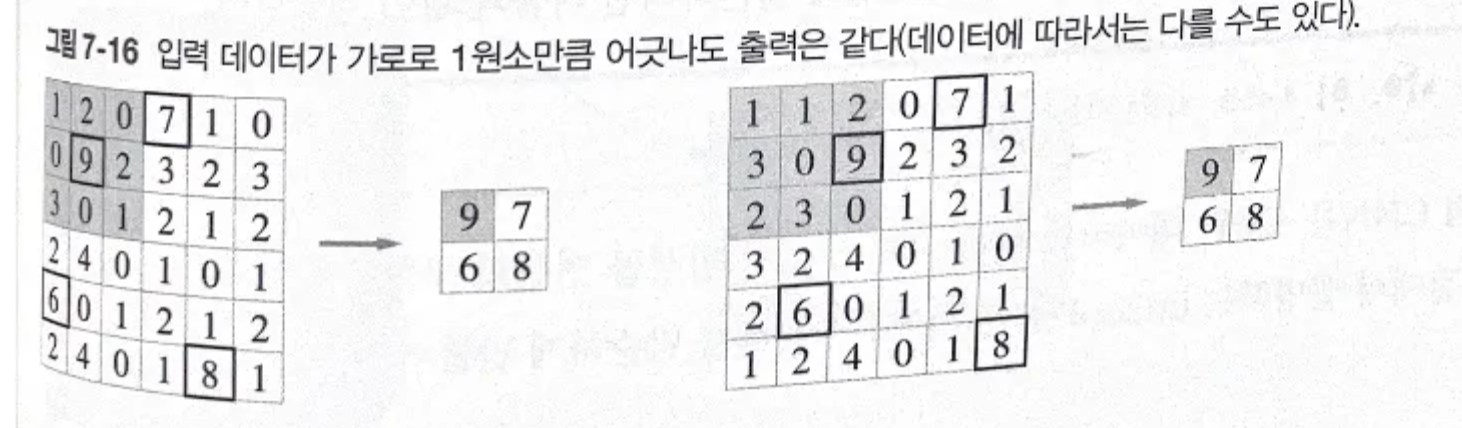
- 스트라이드를 크게 잡아서 필터 적용 영역이 겹치지 않으면 좋지만, 실제 상황에서는 겹치는 경우가 대부분.
필터 적용 영역이 겹치게 되면 im2col로 전개한 후의 원소 수가 원래 블록의 원소 수보다 많아집니다. 그래서 im2col을 사용해 구현하면 메모리를 더 많이 소비하는 단점이 있습니다. 하지만 컴퓨터는 큰 행렬을 묶어서 계산하는데 탁월합니다. 예를 들어 행렬 계산 라이브러리(선형 대수 라이브러리) 등은 행렬 계산에 고도로 최적화되어 큰 행렬의 곱셈을 빠르게 계산할 수 있습니다. 그래서 문제를 행렬 계산으로 만들면 선형 대수 라이브러리를 활용해 효율을 높일 수 있습니다.
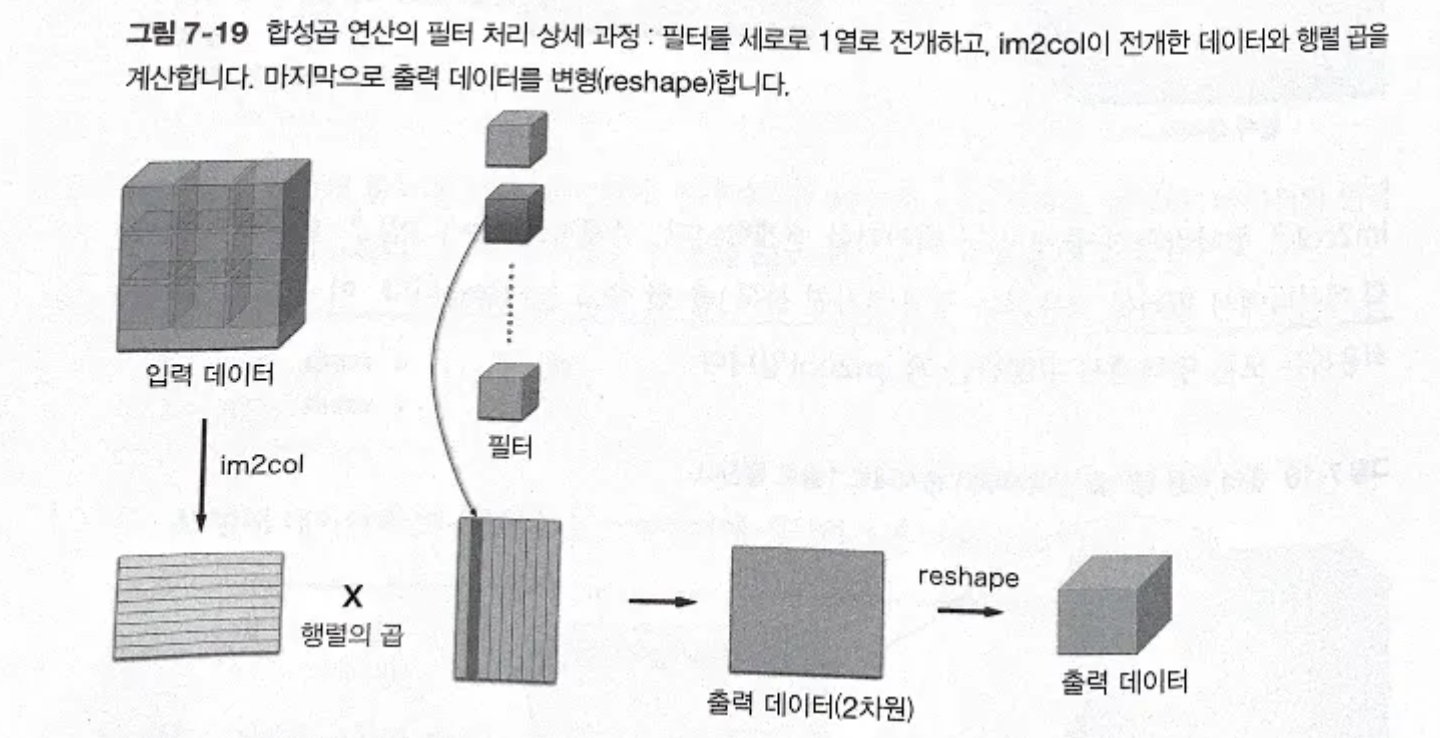
- 대략적인 im2col 동작
- 필터 적용 영역을 앞에서부터 순서대로 1줄로 펼친다
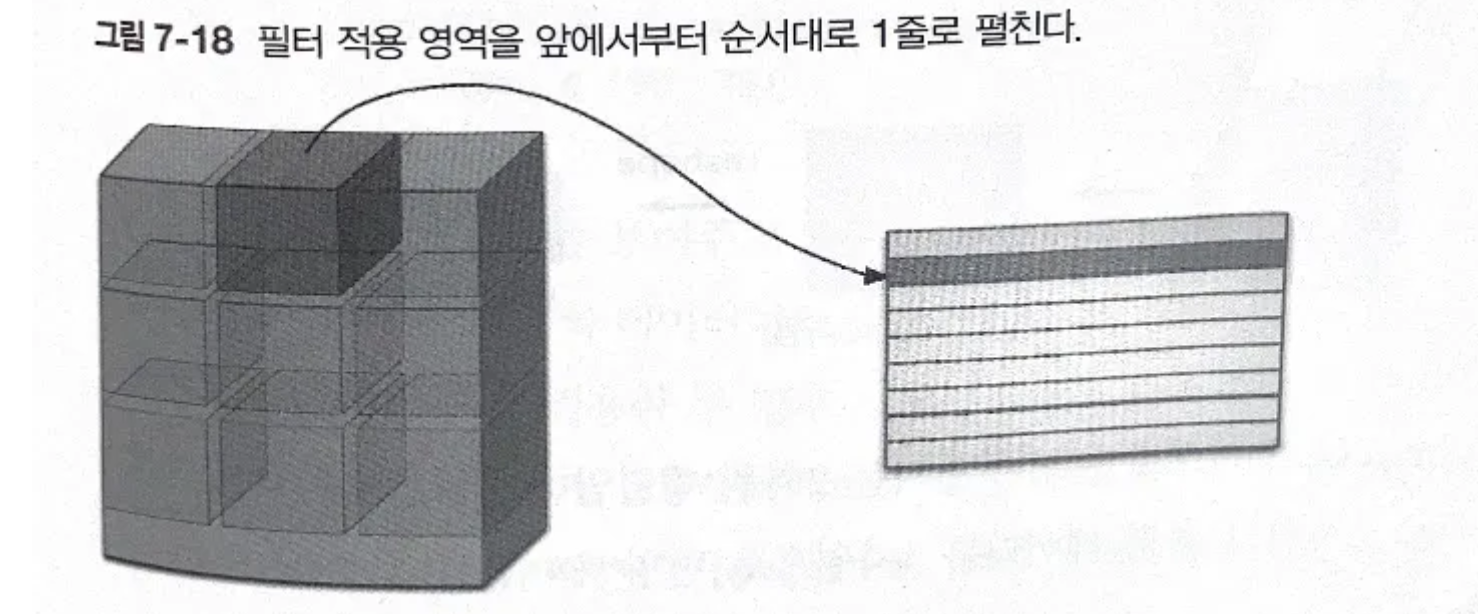
- 합성곱 연산의 필터 처리 상세 과정
7.4.3 합성곱 계층 구현하기
-
합성곱 계층은 필터(가중치), 편향, 스트라이드, 패딩을 인수로 받아 초기화.
-
필터는 (FN, C, FH, FW)의 4차원 형상
- FN: 필터 개수
- C: 채널
- FH, FW: 필터 높이, 너비
-
im2col 함수 덕분에 완전 연결층과 거의 같이 구현 가능.
-
합성곱 역시 col2im을 쓴다는 점을 제외하면 완전 연결층과 동일.
-
im2col 함수의 인터페이스
- im2col(input_data, filter_h, filter_w, stride=1, pad=0)
- input_data - (데이터 수, 채널 수, 높이, 너비)의 4차원 배열로 이뤄진 입력 데이터
- filter_h - 필터의 높이
- filter_w - 필터의 너비
- stride - 스트라이드
- pad - 패딩
-
im2col 사용 예시
import sys, os sys.path.append(os.pardir) from common.util import im2col # 배치 크기가 1, 채널은 3개, 7x7 데이터 x1 = np.random.rand(1, 3, 7, 7) # 데이터 수, 채널 수, 높이, 너비 col1 = im2col(x1, 5, 5, stride=1, pad=0) print(col1.shape) # (9, 75) # 배치 크기가 10, 나머지는 첫째와 같음. x2 = np.random.rand(10, 3, 7, 7) # 데이터 10개 col2 = im2col(x2, 5, 5, stride=1, pad=0) print(col2.shape) # (90, 75) # 두 경우 모두 im2col함수 적용 후 2번째 차원 원소 75 = 필터의 원소 수와 같음(3 * 5 * 5) -
합성곱 계층 구현
class Convolution: def __init__(self, W, b, stride=1, pad=0): self.W = W self.b = b self.stride = stride self.pad = pad def forward(self, x): FN, C, FH, FW = self.W.shape N, C, H, W = x.shape out_h = int(1 + (H + 2*self.pad - FH) / self.stride) out_w = int(1 + (W + 2*self.pad - FW) / self.stride) # 입력 데이터를 im2col로 전개하고 필터도 reshape을 사용해 2차원 배열로 전개 col = im2col(x, FH, FW, self.stride, self.pad) # reshape의 두 번째 인수가 -1: 다차원 배열의 원소 수가 변환 후에도 똑같이 유지되도록 적절히 묶어주는 편의기능 # 즉, 앞의 코드에서 (10, 3, 5, 5)형상을 한 다차원 배열 W의 원소 수는 750이고, 이 배열에 # reshape(10, -1)을 호출하면 750개 원소를 10묶음으로, 형상이 (10, 75)인 배열로 만들어줌. col_w = self.W.reshape(FN, -1).T # 필터 전개. # 전개한 두 행렬의 곱을 구함 out = np.dot(col, col_W) + self.b # 출력 데이터를 적절한 형상으로 바꿔줌. (N, C, H, W 순으로 형상 순서를 바꿔 주기 위함) out = out.reshape(N, out_h, out_w, -1).transpose(0, 3, 1, 2) return out def backward(self, dout): FN, C, FH, FW = self.W.shape dout = dout.transpose(0,2,3,1).reshape(-1, FN) self.db = np.sum(dout, axis=0) self.dW = np.dot(self.col.T, dout) self.dW = self.dW.transpose(1, 0).reshape(FN, C, FH, FW) dcol = np.dot(dout, self.col_W.T) dx = col2im(dcol, self.x.shape, FH, FW, self.stride, self.pad) return dx -
CNN에서는 필터가 곧 가중치라는 사실을 절대 잊으면 안 됨!
7.4.4 풀링 계층 구현하기
-
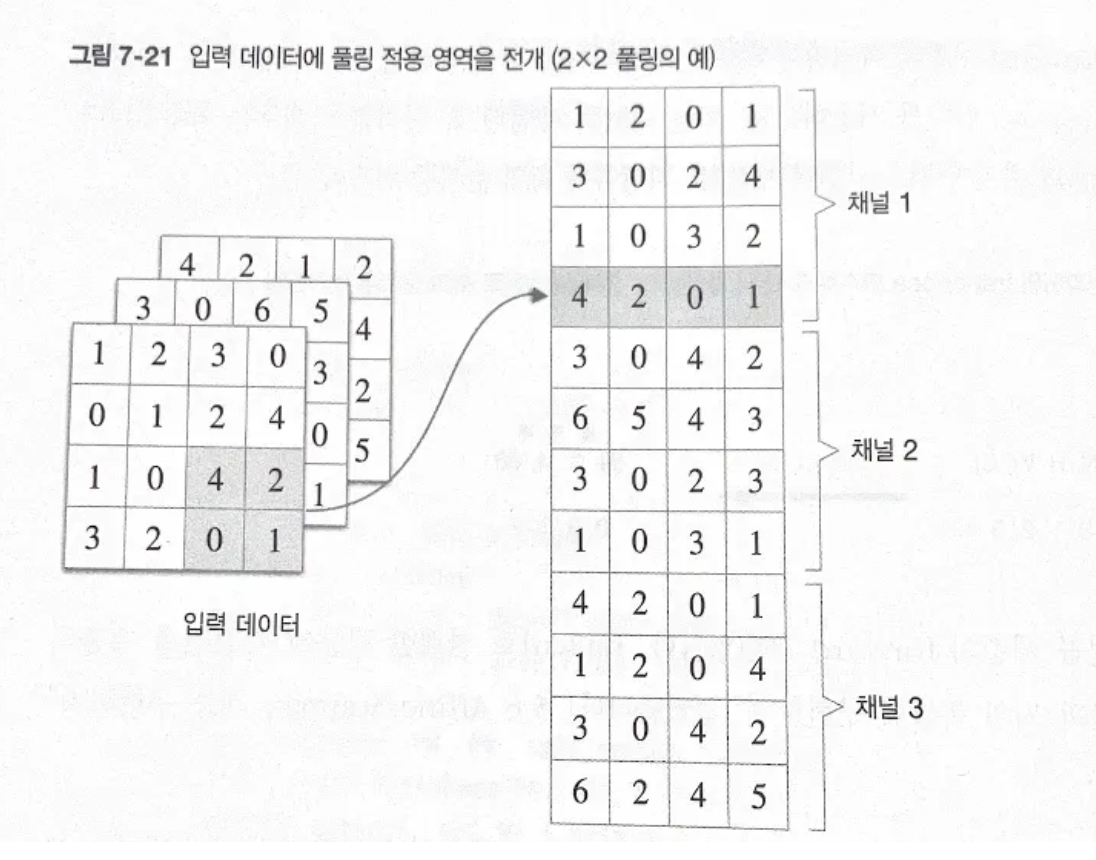
입력 데이터에 풀링 적용 영역을 전개(2x2 풀링의 예)
-
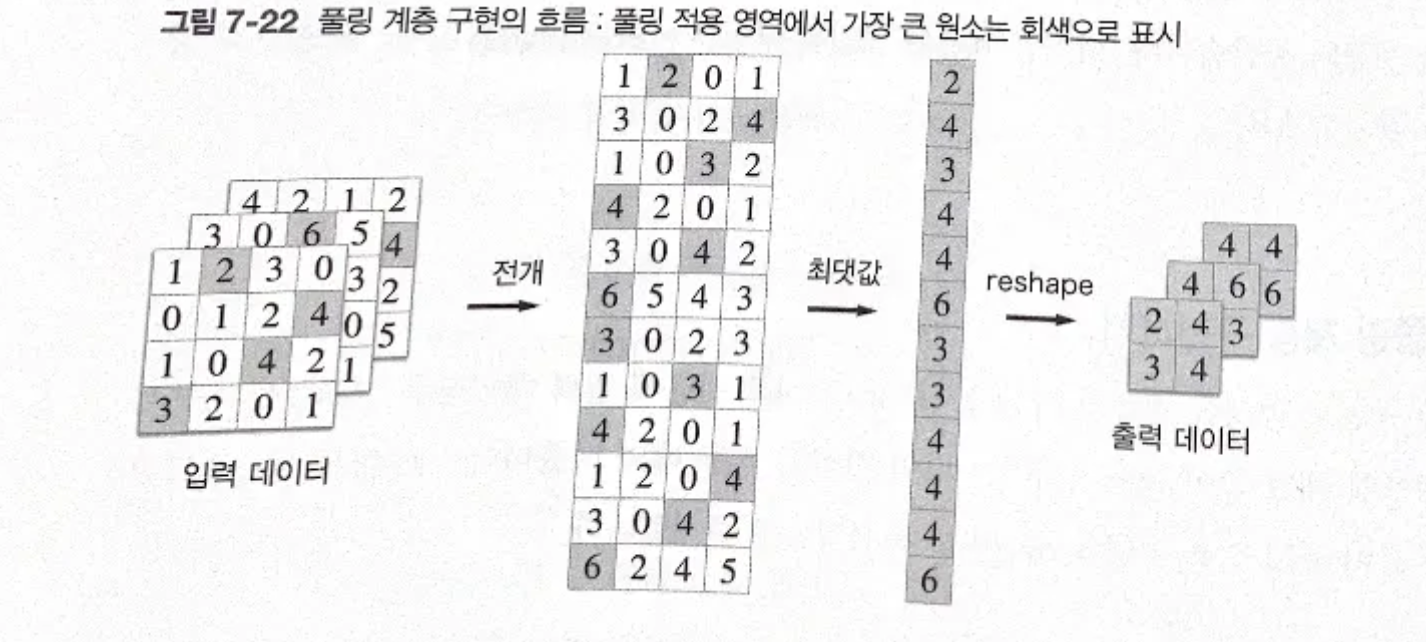
일단 이렇게 전개 후 전개한 행렬에서 행별 최댓값 구하고 적절한 형상으로 성형.
-
파이썬 구현
class Pooling: def __init__(self, pool_h, pool_w, stride=1, pad=0): self.pool_h = pool_h self.pool_w = pool_w self.stride = stride self.pad = pad def forward(self, x): N, C, H, W = x.shape out_h = int(1 + (H - self.pool_h) / self.stride) out_w = int(1 + (W - self.pool_w) / self.stride) # 전개 (1) col = im2col(x, self.pool_h, self.pool_w, self.stride, self.pad) col = col.reshape(-1, self.pool_h*self.pool_w) # 최댓값 (2) out = np.max(col, axis=1) # 성형 (3) out = out.reshape(N, out_h, out_w, C).transpose(0, 3, 1, 2) return out -
풀링 계층의 세 단계
- 입력 데이터를 전개
- 행별 최댓값을 구함
- 적절한 모양으로 성형
-
풀링 계층은 역전파 안 하는 것 아니었나? 분명 학습해야 할 매개변수가 없다고 알고 있는데
- 풀링 계층에는 가중치(weight), 편향(bias) 같은 학습 파라미터가 존재하지 않음. 계산은 최대값(MaxPooling) 또는 평균(AvgPooling) 등으로만 고정적으로 이뤄짐.
- 하지만 전체 신경망 학습(오차 역전파) 때 풀링 계층을 통과한 그래디언트(오차)는 앞 계층으로 전달되어야 하므로, 역전파 연산은 반드시 이뤄진다(기울기가 전달되지 않으면 앞 컨볼루션 계층 등의 파라미터가 학습되지 않으므로).
-
최대 풀링(MaxPooling)의 역전파
-
예를 들어, 2x2 최대 풀링이면, 각 2x2 영역에서 뽑힌 최대값 위치에만 오차가 할당되고 나머지 값엔 0이 할당됩니다.
-
즉, "기울기 분배 방식"만 다를 뿐, 풀링 계층 자체적으로 학습하는 것은 없음
-
아래는 풀링 계층의 역전파.
def backward(self, dout): dout = dout.transpose(0, 2, 3, 1) pool_size = self.pool_h * self.pool_w dmax = np.zeros((dout.size, pool_size)) dmax[np.arange(self.arg_max.size), self.arg_max.flatten()] = dout.flatten() dmax = dmax.reshape(dout.shape + (pool_size,)) dcol = dmax.reshape(dmax.shape[0] * dmax.shape[1] * dmax.shape[2], -1) dx = col2im(dcol, self.x.shape, self.pool_h, self.pool_w, self.stride, self.pad) return dx
-
7.5.1 CNN 구현하기
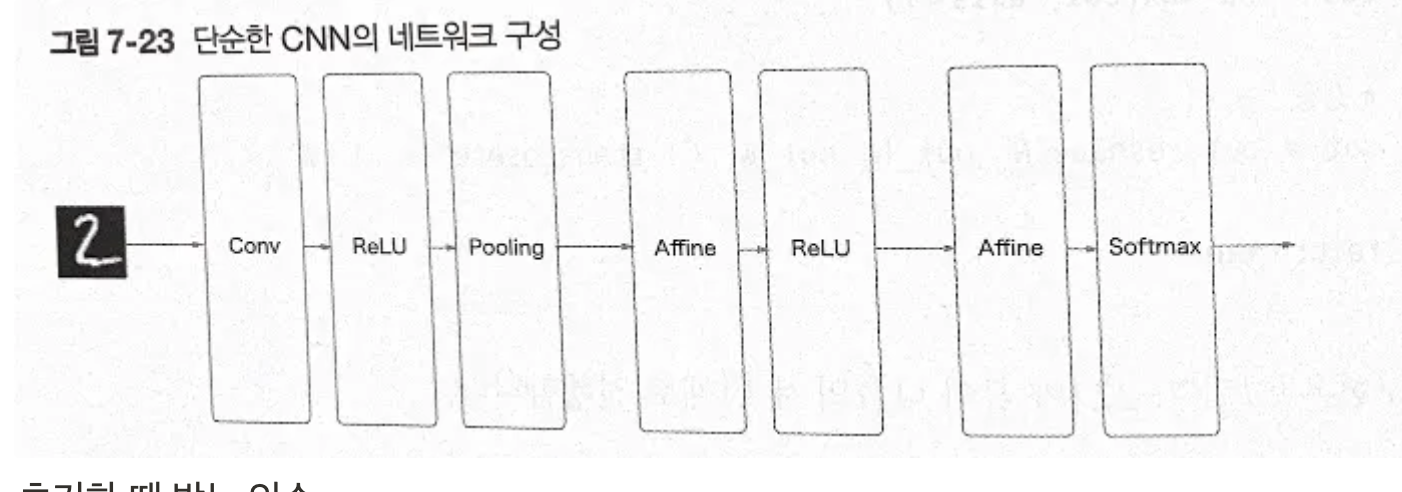
- 단순한 CNN 네트워크 구성(합성곱 계층 하나밖에 없음)
- 초기화 때 받는 인수
- input_dim - 입력 데이터(채널 수, 높이, 너비)의 차원
- conv_param - 합성곱 계층의 하이퍼파라미터(딕셔너리), 딕셔너리의 키는 다음과 같다.
- filter_num - 필터 수
- filter_size - 필터 크기
- stride - 스트라이드
- pad - 패딩
- hidden_size - 은닉 층(완전연결)의 뉴런 수
- output_size - 출력 층(완전 연결)의 뉴런 수
- weight_init_std - 초기화 때의 가중치 표준편차
- 초기화코드
-
초기화 인수로 주어진 합성곱 계층의 하이퍼파라미터를 딕셔너리에서 꺼냄.
class SimpleConvNet: def __init__(self, input_dim=(1, 28, 28), conv_param={'filter_num':30, 'filter_size':5, 'pad': 0, 'stride':1}, hidden_size=100, output_size=10, weight_init_std=0.01): filter_num = conv_param['filter_num'] filter_size = conv_param['filter_size'] filter_pad = conv_param['pad'] filter_stride = conv_param['stride'] input_size = input_dim[1] conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride + 1 pool_output_size = int(filter_num * (conv_output_size/2) * (conv_output_size/2)) -
학습에 필요한 매개변수는 1번째 층의 합성곱 계층과 나머지 두 완전연결 계층의 가중치와 편향.
self.params = {} self.params['W1'] = weight_init_std * np.random.randn(filter_num, input_dim[0], filter_size, filter_size) self.params['b1'] = np.zeros(filter_num) self.parmas['W2'] = weight_init_std * np.random.randn(pool_output_size, hidden_size) self.params['b2'] = np.zeros(hidden_size) self.params['W3'] = weight_init_std * np.random.randn(hidden_size, output_size) self.params['b3'] = np.zeros(output_size) -
마지막으로 CNN을 구성하는 계층들을 생성
self.layers = OrderDict() self.layers = ['Conv1'] = Convolution(self.params['W1'], self.params['b1'], conv_param['stride'], conv_param['pad']) self.layers['Relu1'] = Relu() self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2) self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2']) self.layers['Relu2'] = Relu() self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3']) self.last_layer = SoftmaxWithLoss() -
추론을 수행하는 predict 메서드와 손실함수의 값을 구하는 loss 메서드를 다음과 같이 구현 가능.
# x: 인수, t: 정답 레이블 def predict(self, x): for layer in self.layers.values(): x = layer.forward(x) return x def loss(self, x, t): y = self.predict(x) return self.lat_layer.forward(y, t) -
오차 역전파법으로 기울기 구하는 구현
def gradient(self, x, t): # forward propagation self.loss(x, t) # back propagation dout = 1 dout = self.last_layer.backward(dout) layers = list(self.layers.values()) layers.reverse() for layer in layers: dout = layer.backward(dout) # save results grads = {} grads['W1'] = self.layers['Conv1'].dW grads['b1'] = self.layers['Conv1'].db grads['W2'] = self.layers['Affine1'].dW grads['b2'] = self.layers['Affine1'].db grads['W3'] = self.layers['Affine2'].dW grads['b3'] = self.layers['Affine2'].db return grads
-
-
위 코드를 토대로 직접 훈련을 시켜보도록 하자.
-
훈련 결과는 아래와 같다.
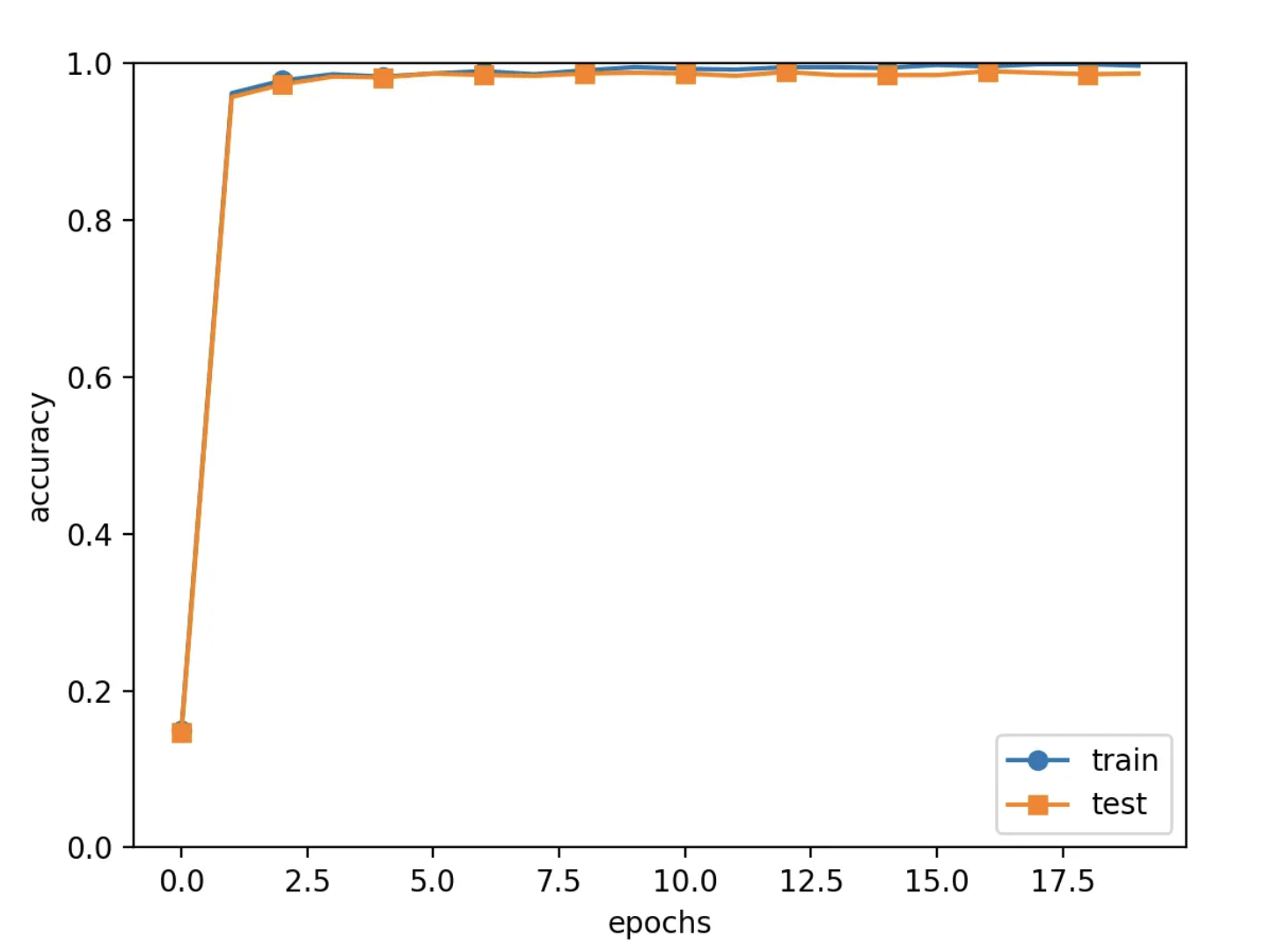
=============== Final Test Accuracy =============== test acc:0.9886 Saved Network Parameters!
7.6.1 1번째 층의 가중치 시각화하기
-
합성곱 계층은 입력으로 받은 이미지 데이터에서 무엇을 볼까?
-
위에서 시행한 CNN 훈련은 합성곱 계층의 가중치 형상이 (30, 1, 5, 5)이었음.
-
필터의 크기가 5x5이고 채널이 1개이므로, 1채널의 흑백 이미지로 시각화 가능.
-
필터: 1개, 5x5 사이즈 필터 시각화
- 학습 전 필터(가중치): 규칙성 없음.

- 학습 후 로드한 pkl파일의 가중치: 규칙성이 있음(흰색에서 검은색으로 점차 변화, 덩어리(blob)이 생김.

- 규칙성 있는 필터가 보는 것: 에지와 블롭 등의 패턴.
- 내가 직접 실시한 훈련으로 추출된 가중치와 비교
- 학습 전 필터(가중치): 규칙성 없음.
-
CNN의 필터(가중치)는 시각적으로 볼 수 있다. 가중치를 시각화한다는 개념이 매우 흥미롭다.
7.6.2 층 깊이에 따른 추출 정보 변화
- 위에서 본 것은 1번째 합성곱 계층의 필터였음.
- 그렇다면 겹겹이 쌓인 CNN의 각 계층에서는 어떤 정보가 추출될까?
- 이에 대한 연구가 따로 있다: 딥러닝 시각화에 관한 연구.
- “계층이 깊어질 수록 추출되는 정보는 더 추상화됨.”
딥러닝의 흥미로운 점은 합성곱 계층을 여러 겹 쌓으면, 층이 깊어지면서 더 복잡하고 추상화된 정보가 추출된다는 것. 처음 층은 단순한 에지에 반응하고, 이어서 텍스처에 반응하고, 더 복잡한 사물의 일부에 반응하도록 변화함. 층이 깊어질 수록 뉴런이 반응하는 대상이 단순한 모양에서 ‘고급’정보로 변화. → 사물의 의미를 이해하도록 변화.
-
CNN의 합성곱 계층에서 추출되는 정보
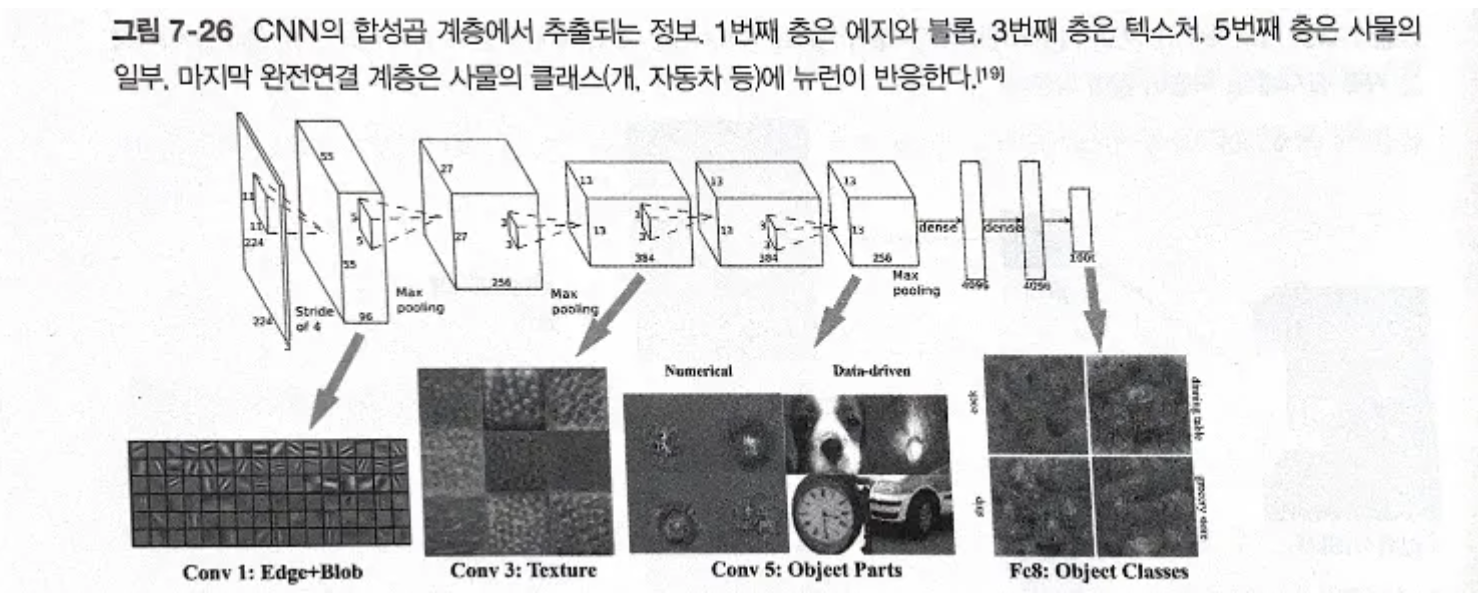
-
이건 진짜 신비롭다. 층이 깊어질수록 필터(가중치)가 더 시각적으로 고급화 된다니.
-
이것의 더 자세한 설명은 아래 글을 참조.
-
왜 층이 깊어질수록 추출 정보가 더 추상적이 될까?
- 딥러닝(CNN)에서 “깊은 층으로 갈수록 더 고급(추상) 특징이 형성된다”는 현상은 단순한 관찰을 넘어, 학습 구조와 최적화, 정보 흐름의 원리로 설명할 수 있다. 핵심 이유를 구조적으로 정리한다.
- 1) 수용영역(Receptive field)의 확장
- 합성곱과 풀링(또는 스트라이드)을 거듭하면 각 뉴런이 “원본 입력의 더 넓은 영역”을 바라본다. 초깊은 층의 뉴런은 이미지의 광범위한 패턴(멀리 떨어진 부분의 조합)까지 포착하므로, 자연스럽게 국소적 에지→텍스처→부품→객체와 같은 계층적 특징으로 진화한다.
- 즉, 얕은 층은 작은 패치에서만 통계적으로 안정적인 에지/코너에 반응하고, 깊은 층은 넓은 컨텍스트에서만 안정적인 “의미 있는 조합(예: 눈+코의 배치, 물체 실루엣)”에 반응한다.
- 2) 계층적 조합성(Compositionality)
- CNN은 “단순 특징을 결합해 더 복잡한 특징을 만든다”는 구성 원리를 내재한다. 1층의 에지들이 2–3층에서 텍스처와 간단한 모양으로 결합되고, 그 위층에서 부품(눈, 휠, 손잡이)으로, 더 위층에서 전형적 배치 패턴을 통한 물체/장면 개념으로 합성된다.
- 이 조합적 구조는 합성곱(지역성·가중치 공유)과 비선형성(ReLU 등)이 반복되며 자연스럽게 생기는 표현력 확장의 결과다.
- 3) 비선형 누적과 분리성(Separability)
- 각 층의 비선형성(ReLU, GELU 등)은 선형 필터들의 단순 합으로는 표현하기 어려운 “결정 경계와 불변성”을 만들어낸다.
- 층이 깊어질수록 입력 공간이 반복적으로 비선형 변환되어, 클래스 간 분리가 쉬운 표현 공간으로 매핑된다. 이 과정에서 모델은 낮은 수준 잡음에 둔감하고 과업 관련 요인(객체 정체성)에 민감한 고차 특징을 학습한다.
- 4) 통계적 불변성 학습(Translation/Deformation invariance)
- 합성곱(가중치 공유)과 풀링/스트라이드는 평행이동·소규모 변형에 대한 불변성을 촉진한다.
- 얕은 층은 위치·방향에 민감한 에지를 포착하지만, 층을 거듭하며 위치·규모·조명 등의 변이에 덜 민감한 안정적 패턴(“의미”)을 대표하도록 가중치가 압박된다. 결과적으로 “무엇인지”에 가깝고 “어디/어떻게 보였는지”에 먼 특징으로 이동한다.
- 5) 목적함수(감독 신호)가 위계를 유도
- 분류/탐지 손실은 최종적으로 “의미 단위(클래스)”를 맞히도록 가중치를 조정한다. 역전파는 상위 과업 신호를 하위층까지 전송해, 얕은 층은 범용적·안정적 저수준 특징을, 깊은 층은 과업에 직접 유용한 고수준 특징을 갖도록 역할 분화를 만든다.
- 즉, 손실이 “의미 중심”의 특징을 선호하게 만들고, 이는 깊은 층일수록 더 강하게 반영된다.
- 6) 정보 병목과 최소충분표현(Information Bottleneck 관점)
- 훈련 중 노이즈 억제와 일반화 압력에 의해 네트워크는 입력의 세부적 변동(잡음)을 버리고, 출력(레이블) 예측에 필요한 통계만 남기는 경향이 있다.
- 깊은 층은 잉여 정보를 버리고 의미와 직결된 통계(클래스 불변 요인)를 유지하는 “압축된 표현”으로 수렴하기 쉽다.
- 7) 파라미터 공유와 규격성의 축적
- 합성곱의 지역 필터와 공유 구조는 대칭성(평행이동 동일시)을 강하게 주입한다. 계층을 거듭해 이런 유도편향(inductive bias)이 누적되면서 “반복되는 모티프의 결합”이 효율적인 표현으로 선택된다. 이로 인해 시각적으로도 더 조직화되고 정형화된 필터/특징맵이 등장한다.
- 8) 학습 동역학: 초기층의 보편성, 후속층의 특수화
- 많은 과업/데이터에서 초기층은 거의 공통의 에지·코너 필터로 수렴(전이학습에서 초깃층이 재사용 가능한 이유), 반면 후속층은 데이터셋/과업 특이적 패턴에 맞춰 특수화된다. 이 특수화가 “의미적 추상화”로 관찰된다.
- 9) 시각화 연구에서의 관찰적 근거
- 필터 시각화, 활성화 최대화, 디컨볼루션/가이드드 백프로퍼게이션, 클래스 어트리뷰션(Saliency, Grad-CAM) 등에서 공통적으로 얕은 층은 에지/그라디언트, 중간층은 텍스처/반복 패턴, 깊은 층은 부품·객체 형태에 반응하는 경향이 반복 관찰된다.
- 이는 단지 “예쁜 그림”이 아니라, 상기의 수용영역·비선형·불변성·감독 신호의 상호작용이 만든 귀결을 실험적으로 뒷받침한다.
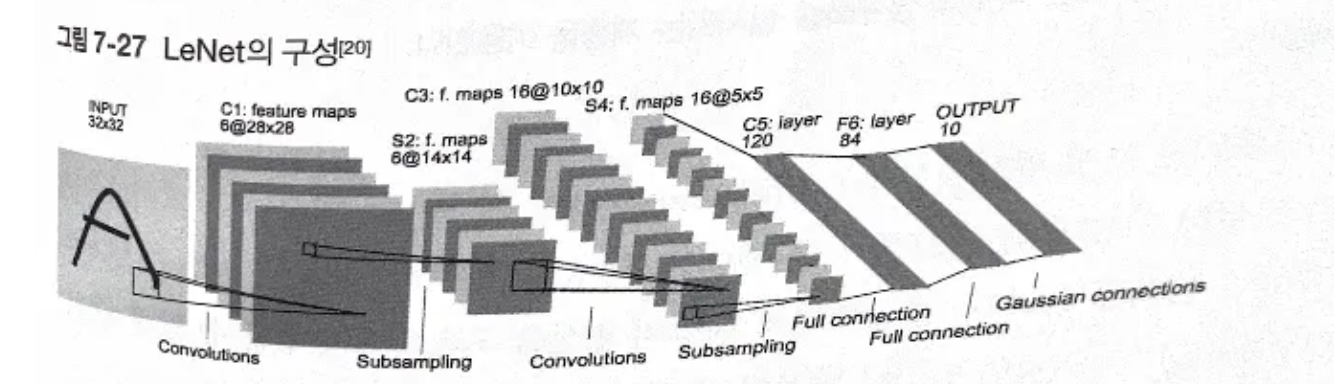
7.7.1 LeNet
-
합성곱 계층과 풀링 계층(단순히 원소를 줄이기만 하는 서브샘플링 계층)을 반복한 후 완전연결 계층을 거쳐 결과 출력.
-
1997년에 제안됨.
-
LeNet의 구성
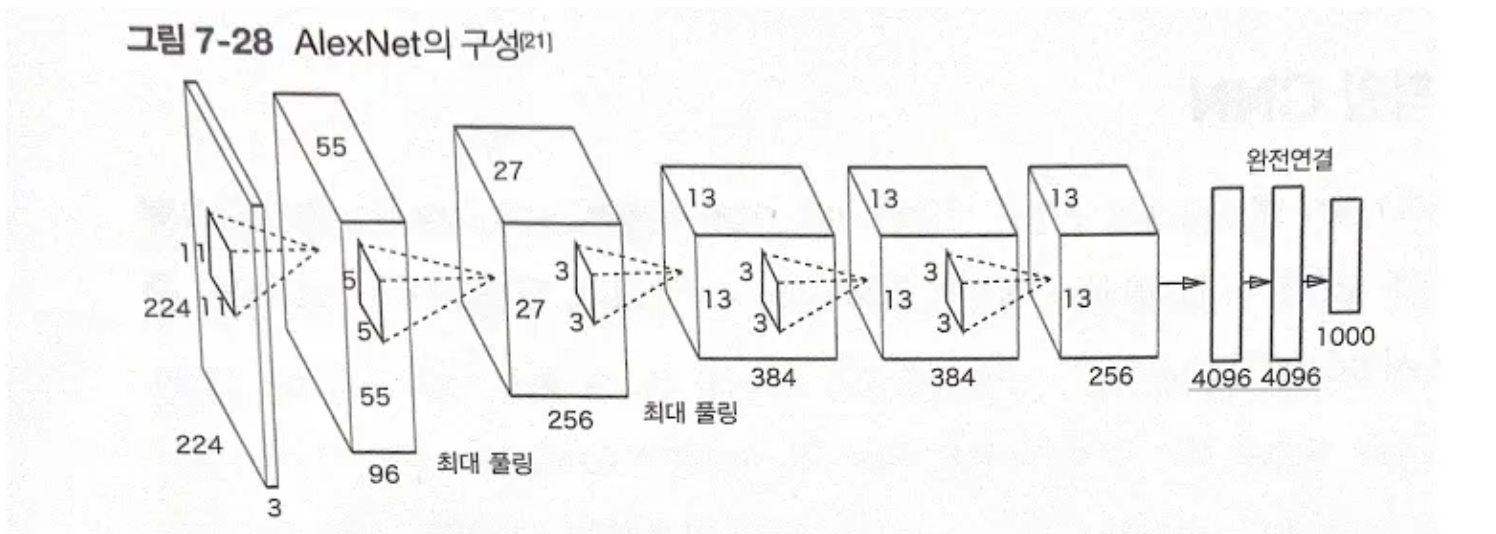
7.7.2 AlexNet
-
2012년 발표
-
LeNet과의 차이
- 활성화 함수로 ReLU를 사용
- LRN(Local Response Normalization)이라는 국소적 정규화를 실시하는 계층 이용
- 드롭아웃을 사용
-
LeNet, AlexNet, 현대 CNN 모두 큰 차이는 없지만 이를 둘러싼 컴퓨터 기술과 데이터가 진보를 이룸.
-
AlexNet의 구성