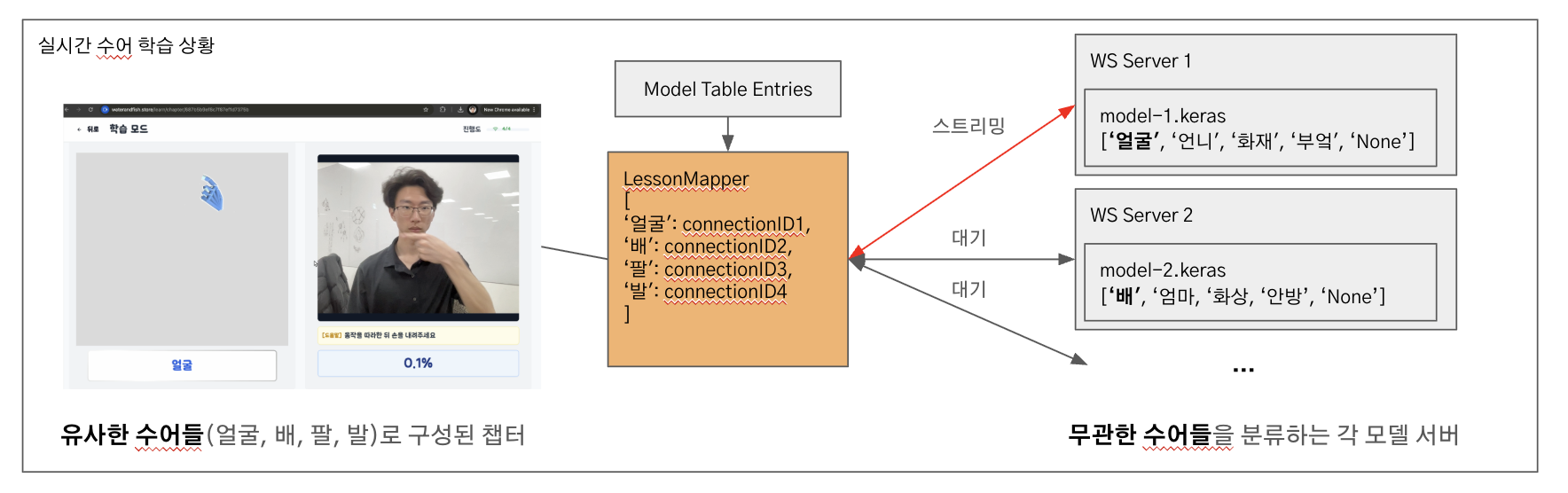
수어지교는 기존의 영상과 같은 단방향 매체밖에 존재하지 않는 수어 학습 솔루
션을 개선하고자 개발한 '실시간 상호작용'이 가능한 수어 학습용 웹 서비스입니다.
개요
모델 배포는 문제다
모델을 학습시키면서 알게 된 사실은, 서로 다른 동작들을 묶어서 모델을 학습시켜야 효과적인 분류가 가능했다는 점입니다. 동작이 비슷하면 모델이 패턴을 명확히 구분하는 성능이 떨어졌기 때문입니다.
하지만 수어 도메인의 특성상, 의미가 다를수록 동작에 분명한 차이가 존재했습니다. 그래서 '얼굴', '언니', '화재', '부엌'처럼 의미가 무관한 라벨을 학습시켜야 서로 다른 동작을 묶을 수 있었습니다.
이로 인해서 모델 하나는 의미적으로 무관한 라벨을 구별하게 되었는데요, 이를 결국 어떻게 배포할지가 문제가 되었습니다. 어디까지나 수어를 단순 분류하는 서비스가 아니라 사용자가 학습하는 서비스이기 때문에 의미적으로 유사한 수어를 한 챕터에서 학습해야 학습 효과가 좋을 것이라고 생각했기 때문입니다. 아래와 같이 문제를 정의할 수 있죠.
단일 모델로 유사한 의미의 3~4가지 수어를 효율적으로 학습시키 어려움
추상화: 신경쓰지 않을 결심
고민을 거듭한 끝에, 모델이 무엇을 분류할 수 있는지 클라이언트가 신경쓰지 않아도 되도록 '모델'과 '챕터' 사이의 관계를 추상화 시킬 수 있는 아키텍처를 구축하고자 했습니다. 아래 그림을 통해 예시를 살펴보도록 하겠습니다.
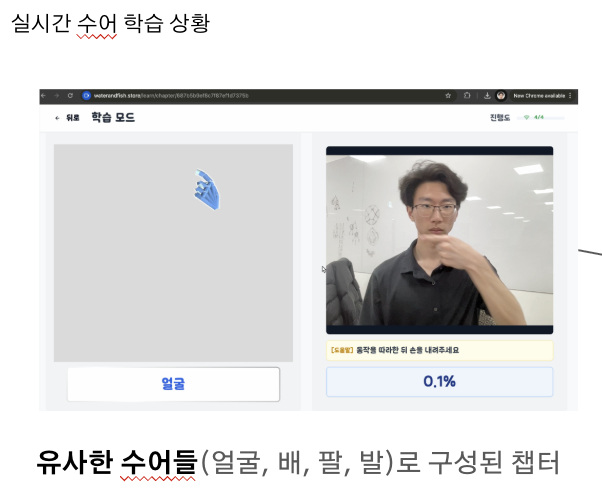
그림에서 사용자는 '얼굴', '배', '팔', '발'이라는 유사한 의미들로 구성된 '신체부위' 챕터를 공부하고 있습니다. '얼굴'을 학습한 다음에는 '배'를 분류하는 모델로 입력 데이터를 자연스럽게 넘겨줄 수 있어야 하죠.
하지만 모델 하나로는 이 챕터 하나를 구성할 수 없습니다. 각 라벨을 분류할 수 있는 모델이 어떤 것인지 지시하는 별도의 자료구조 없이는 말이죠. 이를 위해 아래와 같이 두 가지 자료구조를 구현하였습니다. 바로 Model Table Entry와 Lesson Mapper입니다. 두 가지 자료구조의 역할 설명은 아래에서 더 자세히 살펴보도록 하겠습니다. 아무튼 이런 구현 덕분에 '유관한 수어로 구성된 챕터'와 '무관한 수어로 구성된 각 모델 서버'간의 관계를 맺어줄 수 있었습니다.
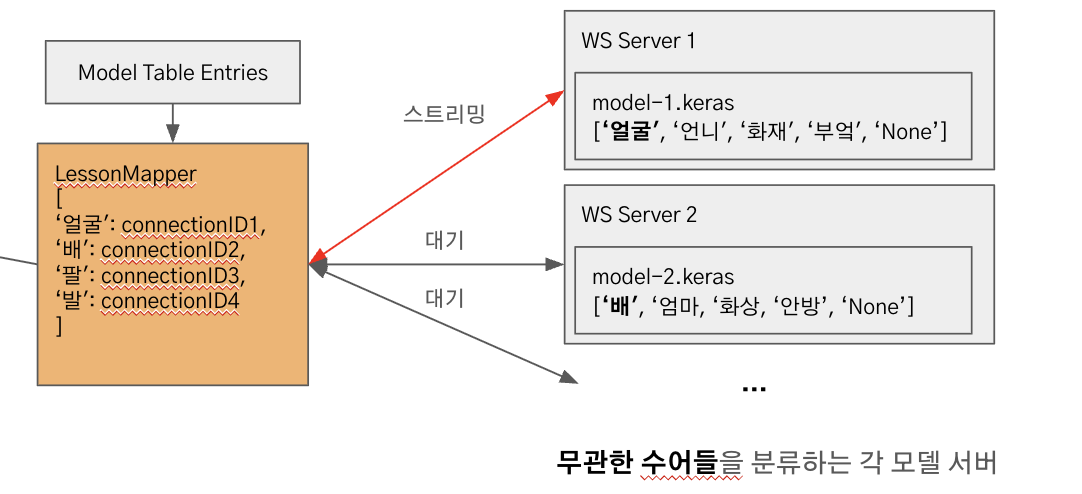
그림에서처럼 '얼굴'을 학습중인 사용자는 두 자료구조 덕분에 동작 데이터를 '얼굴'을 분류할 수 있는 서버로 보내게 됩니다. 그 서버는 다른 동작들도 분류할 수 있지만 그 부분은 몰라도 상관 없죠.
구현
Model Table Entry
문제
모델 테이블 엔트리(MTE)는 가상 메모리의 페이지 테이블 엔트리(PTE)를 참고한 자료구조입니다. PTE가 가상 주소와 물리 주소를 매핑해 주듯이, MTE는 수어와 모델의 관계를 매핑해줍니다. 이렇게 관계를 매핑해주는 자료구조가 없다면 모델은 챕터와 1차원적인 관계를 가지게 되고, 아마 '얼굴', '언니', '화재', '부엌'을 한 챕터에서 공부해야 했을 겁니다. 하지만 MTE 덕분에 모델이 어떤 라벨을 분류할 수 있는지 누구도 신경쓰지 않아도 되죠.
구현
수어지교는 각 수어를 정의하는 데이터를 'Lesson'이라는 이름으로 DB에 저장합니다. 아래와 같이 말이죠.
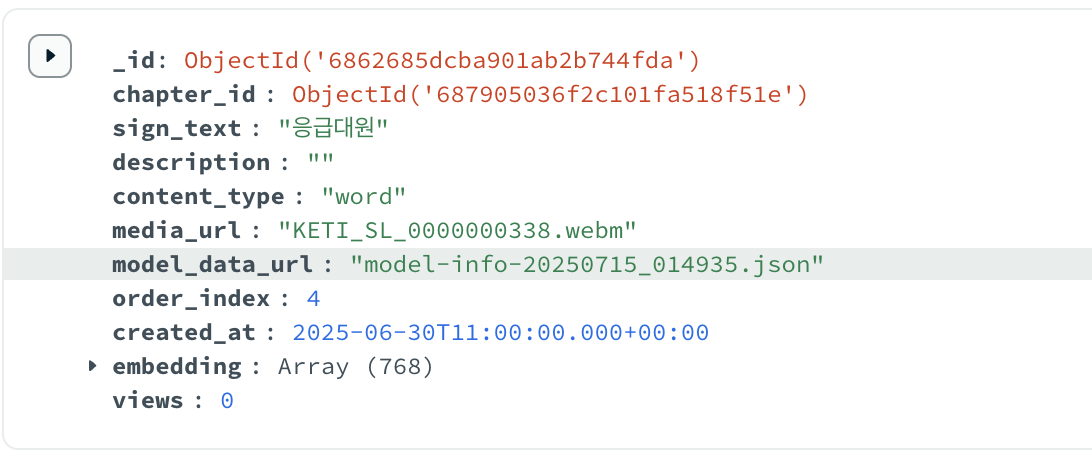
그림에서 보이는 model_data_url이 바로 MTE입니다. 모델의 메타 데이터를 가리키는 주소를 담고 있죠.
이 메타 데이터는 배포 파이프라인에서 매우 중요한 역할을 차지합니다. 하나의 챕터를 선택했을 때 일어나는 일들을 차례대로 보도록 하겠습니다.
클라이언트가 챕터를 선택하면 chapter_id와 함께 아래와 같은 api를 호출하게 됩니다. 이 api 함수는 deploy_model 함수를 chapter_obj_id, db와 함께 호출하죠. deploy_model은 챕터에 필요한 모든 모델을 각 웹소켓 서버에 배포한 후, 웹소켓 주소인 ws_urls와 클라이언트의 작업 분배에 필요한 lesson_mapper와 함께 응답을 보냅니다.
@router.get("/deploy/{chapter_id}")
async def deploy_chapter_model(
chapter_id: str,
request: Request,
db: AsyncIOMotorDatabase = Depends(get_db),
):
try:
# 모델 서버 배포
ws_urls, lesson_mapper = await deploy_model(chapter_obj_id, db)
if not ws_urls:
return JSONResponse(
status_code=status.HTTP_200_OK,
content={
"success": True,
"data": {"ws_urls": []},
"message": "해당 챕터에 배포할 모델이 없습니다"
}
)
return JSONResponse(
status_code=status.HTTP_200_OK,
content={
"success": True,
"data": {"ws_urls": ws_urls, "lesson_mapper": lesson_mapper},
"message": f"모델 서버 배포 완료: {len(ws_urls)}개"
}
)deploy_model은 어떻게 필요한 모든 모델을 서버에 배포할까요?
우선 챕터 정보를 조회하고 챕터 안의 모든 lesson(수어)들을 조회합니다. lesson 엔티티들은 모두 model_data_url을 가지고 있죠. 이것을 모두 조회합니다.
async def deploy_model(chapter_id, db=None):
"""챕터에 해당하는 모델 서버를 배포"""
# 챕터 정보 조회
chapter = await db.Chapters.find_one({"_id": chapter_id})
if not chapter:
raise Exception(f"Chapter with id {chapter_id} not found")
# 해당 챕터의 레슨들 조회
lessons = await db.Lessons.find({"_id": {"$in": chapter["lesson_ids"]}}, {"embedding": 0}).to_list(length=None)
# 모델 데이터 URL이 있는 레슨 확인
model_data_urls = [lesson.get("model_data_url") for lesson in lessons if lesson.get("model_data_url")]
cleanup_dead_servers()그 후, 조회한 모델 메타 데이터를 루프로 순회하며 서버를 생성하는 작업을 합니다. 이때, 동시성 처리도 함께 살펴보도록 하겠습니다.
ws_urls = []
for model_data_url in model_data_urls:
model_id = model_data_url포트는 공유자원이라서 동시성 처리가 필요해요
모델 배포 로직에서 왜 동시성 처리가 필요할까요? 빠른 반응성을 위해 수어지교는 단일 모델 서버 아키텍처를 구현했습니다. 웹 소켓 서버 하나가 모델 하나를 구동하죠. 만약 여러 클라이언트가 동일한 모델을 필요로 할 경우 새로 서버를 여는 대신 기존 실행 서버를 연결시켜주고, 아무도 모델을 사용하지 않을 때만 모델을 종료합니다.
이때, 웹 소켓 서버는 하나 이상이 구동될 수 있으므로 공유자원인 포트 번호에 대해 동시성 처리가 꼭 필요합니다. 만약 처리를 해주지 않으면 중복된 포트를 요청하게 되어 포트 충돌이 생길 수 있겠죠.
기존 프로토타입에서는 아래와 같이 간단한 링 버퍼 방식으로 포트를 관리했는데, 중복 포트 문제가 잦게 발생했습니다.
PORT_BASE = 9000
new_port = (PORT_BASE + len(self.running_servers)) % 100수어지교 서비스는 '포트 풀'을 관리하는 방식으로 이 문제를 해결했습니다. 내부적으로는 최소 힙 자료구조를 사용하여 늘 가용한 가장 작은 번호를 할당하도록 하였죠.
port = allocate_port(model_id)
# 포트 할당 함수 (작은 번호부터 할당)
def allocate_port(model_id):
with ports_lock:
if model_id in model_ports:
return model_ports[model_id]
if not available_ports:
raise Exception("No available ports in pool")
port = heapq.heappop(available_ports)
model_ports[model_id] = port
return port그리고 위 코드에도 나와 있지만, 포트 풀 접근 시 늘 락을 획득하도록 하여 동시 처리 문제를 다루었습니다. 살펴볼 모델 배포 코드에도 계속 락이 등장하는 이유입니다. 다시 deploy_model로 돌아가서 단계별 처리 과정을 보도록 하겠습니다.
1단계부터 동시성 처리 절차입니다. 요청 받은 모델을 구동하던 서버가 종료중인지 확인하는 절차입니다. 웹 소켓 서버 종료는 시간이 꽤 걸리기 때문에 self.running_server 안에 원하는 모델이 있다고 해서 그 주소를 돌려줬다가는 사용자가 종료중인 모델에 연결을 시도할 수도 있기 때문에 이러한 검증이 필요합니다.
# 1단계: 종료 중인지 먼저 확인 (우선순위 존중)
shutdown_in_progress = False
shutdown_lock.acquire(priority=1) # 생성 작업은 낮은 우선순위
try:
models_lock.acquire(priority=1)
try:
if model_id in shutting_down_models:
print(f"Model server {model_id} is shutting down, will start new one")
shutdown_in_progress = True
finally:
models_lock.release()
finally:
shutdown_lock.release()만약 종료 중이 아니고 정상 실행중인(접속자가 1명 이상인) 서버라면 직접 백엔드 서버가 웹소켓 서버의 상태를 확인합니다. 만약 정상이라면 ws_urls에 기존 웹소켓 서버의 url을 추가하고 루프를 벗어납니다.
# 2단계: 종료 중이 아니라면 일반적인 상태 확인
if not shutdown_in_progress:
models_lock.acquire(priority=1)
try:
# 직접 프로세스 상태 확인
process = model_server_manager.server_processes.get(model_id)
pid = process.pid if process else None
server_alive = False
if model_id in model_server_manager.running_servers:
try:
server_alive = is_server_alive_by_pid(pid)
except Exception:
server_alive = False
if server_alive:
print(f"Model server already running for {model_id}")
ws_urls.append(model_server_manager.running_servers[model_id])
continue
else:
print(f"Model server for {model_id} is not alive. Restarting...")
model_server_manager.running_servers.pop(model_id, None)
model_server_manager.server_processes.pop(model_id, None)
finally:
models_lock.release()이제부터는 새로 모델을 실행하는 분기의 흐름입니다. 위 루틴을 수행하던 중 변동이 또 있을 수 있으니 다시 한 번 종료 상태를 확인합니다.
# 3단계: 서버 시작 전에 다시 한번 종료 상태 확인
shutdown_lock.acquire(priority=1)
try:
models_lock.acquire(priority=1)
try:
if model_id in shutting_down_models:
print(f"Model server {model_id} shutdown detected during startup, skipping...")
continue
finally:
models_lock.release()
finally:
shutdown_lock.release()그 후 포트 풀에서포트를 획득 후 모델 메타 데이터와 포트를 토대로 서버를 실행합니다.
# 4단계: 포트 할당 및 모델 서버 시작 (락 외부에서 실행)
port = allocate_port(model_id)
try:
ws_url = await model_server_manager.start_model_server(model_id, model_data_url, port=port)
except Exception as e:
print(f"Failed to start model server for {model_id}: {str(e)}")
release_port(model_id)
raise Exception(f"Failed to start model server for {model_id}: {str(e)}")이렇게 생성된 ws_urls로 클라이언트는 연결을 하게 되고, 수어 동작을 해당 웹 소켓들로 스트리밍합니다.
Lesson Mapper
문제
위의 구현을 통해 클라이언트가 요청한 챕터에 필요한 모든 모델 서버의 url을 정리할 수 있었습니다. 하지만 한 가지 문제가 있습니다. 클라이언트가 한 번에 챕터를 구성하는 최대 4개의 모델에 연결을 하게 하므로 따로 조치를 하지 않으면 데이터를 모든 서버로 보내게 됩니다. job을 분배하기 위한 방법이 구현되지 않은 상태죠.
원래 이런 작업에는 모델 서버를 따로 생성하지 않고, calary worker를 두어서 백엔드 서버가 메시지 큐로 들어오는 작업을 배분하는 것이 간편한 것을 알고 있지만, 사용자의 동작이 메시지 큐를 거쳐 calary worker로 라우팅 되는 시간과 라우팅 지정을 위한 오버헤드를 고려했을 때 웹 소켓 서버로 바로 입력을 스트리밍 하는 구조가 실시간 처리에 효과적이라고 판단했습니다.
이를 위해서는 메시지 큐 방식과는 다른 작업 분배 방식이 필요했고, 다중 웹 소켓 서버에 걸맞게 '스위치'를 구현하게 되었습니다.
구상
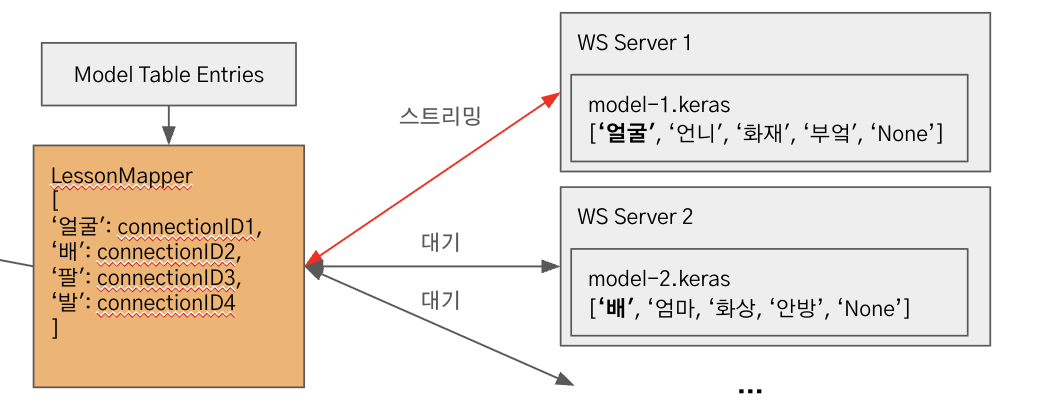
그림에서 LessonMapper가 그 역할을 수행합니다. LessonMapper는 그림과 같이 각 수어와 그것을 분류할 수 있는 웹소켓 연결 id를 지정합니다. 아까 살펴봤던 백엔드 서버의 deploy_model 코드에서 마지막 단계에 아래 과정으로 생성됩니다.
lesson_mapper = defaultdict(str)
for lesson in lessons:
lesson_mapper[str(lesson["_id"])] = model_server_manager.running_servers[lesson["model_data_url"]]
return ws_urls, lesson_mapperlesson id를 key 값으로 쓰고 웹 소켓 서버의 url을 value 값으로 하는 default dictionary 자료구조입니다. 이를 통해 클라이언트는 필요한 웹 소켓 서버가 무엇인지 그때그때 파악해서 정확한 웹 소켓 서버로 데이터를 전송할 수 있습니다.
클라이언트는 아래와 같이 매번 필요한 수어(Lesson)의 ID(currentSignId)를 갱신하고 그에 따라 웹 소켓 주소(wsURL)에 해당하는 이미 연결 된 connection ID를 가져와 currentConnectionID로 설정합니다. 그에 따라 클라이언트는 항상 currentConnectionID로 메시지를 스트리밍하면 되죠.
if (currentSignId) {
const wsUrl = lessonMapper[currentSignId];
setCurrentWsUrl(wsUrl);
if (wsUrl) {
const connection = getConnectionByUrl(wsUrl);
if (connection) {
setCurrentConnectionId(connection.id);
...
sendMessage(JSON.stringify(landmarksSequence), currentConnectionId);
그렇다면 스트리밍 되지 않는 나머지 웹 소켓 서버들은 어떻게 될까요? 아무 일도 하지 않습니다. 연결만 유지한 상태에서 아무 데이터도 수신하지 않기 때문에 코어를 사용할 일도 없죠. 따라서 스위치 구현만으로 충분히 작업 분배가 됐다고 볼 수 있습니다.
이상으로 모델을 웹 소켓 서버에 배포하여 클라이언트에게 연결을 제공하는 과정을 살펴봤습니다. 메시지 큐에 비해 직관적인 연결 구조 덕분에 아래와 같이 빠른 실시간 추론을 구현할 수 있었죠(최대 72ms).
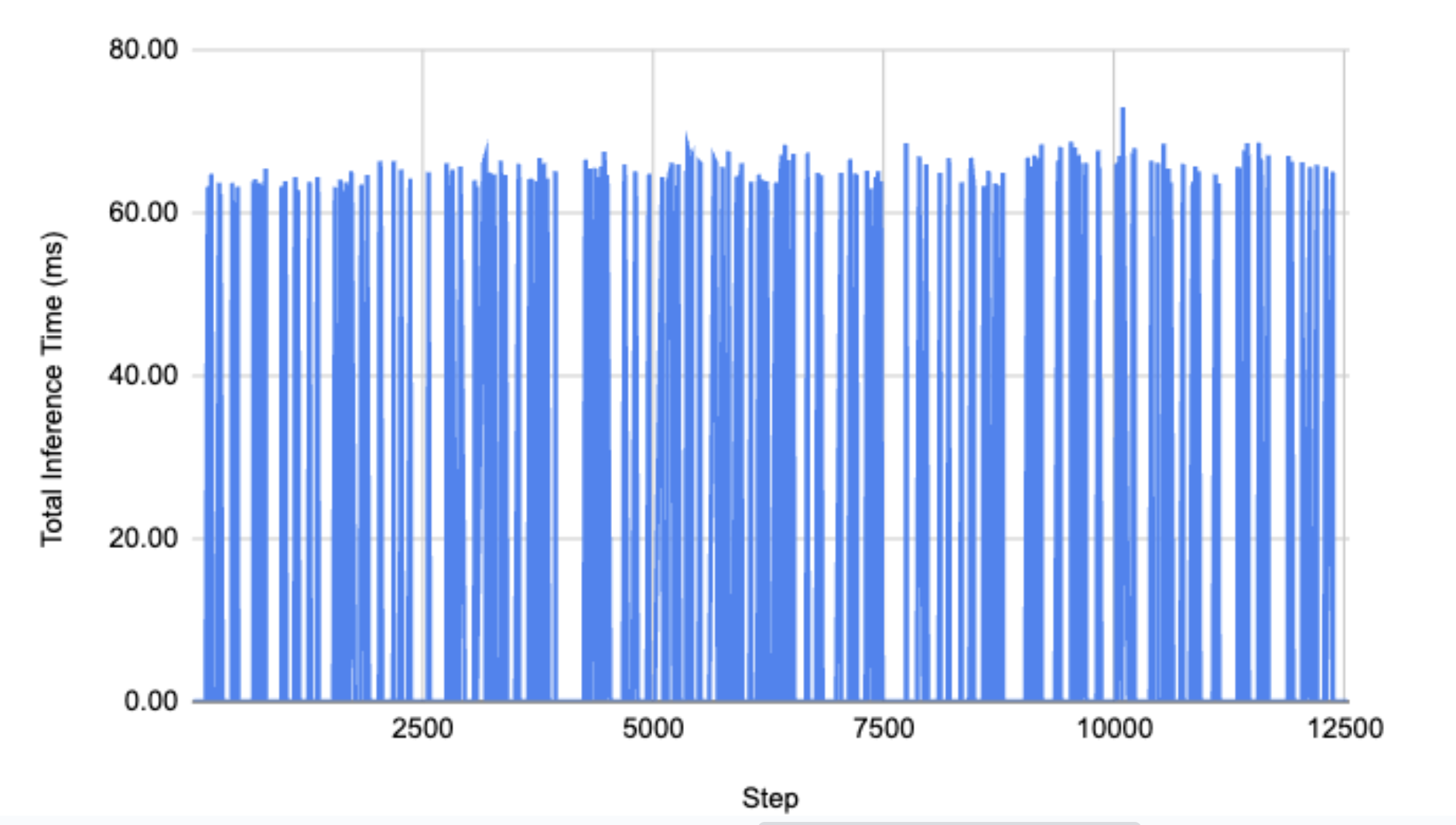
이번 프로젝트를 통해 딥러닝 모델 학습, 모델 배포, 클라이언트 처리까지 전반적인 딥러닝 활용 서비스의 구현 경험을 할 수 있었습니다. 다음 프로젝트를 기대하며, 시리즈를 마무리하겠습니다.
감사합니다.
