수어지교는 기존의 영상과 같은 단방향 매체밖에 존재하지 않는 수어 학습 솔루
션을 개선하고자 개발한 '실시간 상호작용'이 가능한 수어 학습용 웹 서비스입니다.
개요
첫 번째 글에서는 딥러닝 모델을 피드백 서비스에 적용한 방식을 살펴봤습니다. 이번 글에서는 딥러닝 모델을 사용해 실시간성이 보장되는 피드백 기능을 구현한 과정을 살펴보도록 하겠습니다.
두 가지 문제: 실시간성과 정확성
실시간 상호작용을 구현하기 위해서는 실시간성과 정확성이 보장돼야 했습니다. 사용자가 어떤 서비스를 '실시간'이라고 느끼기 위해서는 어떤 입력에 대해 서비스 로직이 100ms 내로 처리가 돼야 하며, 웹 서비스 환경을 고려했을 때 정확성을 보장할 수 있는 '강인한' 서버 아키텍처가 필요했습니다.
수어지교에서 지연 발생 구간들
이전 글에서 수어 분류 모델의 입력 형상이 (675, 60)이었다고 했는데요, 이때 입력 된 시퀸스의 길이가 60이므로 이 정도 길이의 데이터에 대해 모델이 충분히 빠른 분류를 수행해 주는게 기본이겠죠. 하지만 이 속도는 모델을 학습 시킨 후에는 유의미하게 변경하기는 어려웠습니다. (다양한 모델 경량화 기법이 있는 것으로 알고 있지만, 당장 작동하는 웹 서비스를 구현하기에 앞서 잘 모르는 기술을 테스트할 시간도 부족했습니다.)
따라서 실시간성을 보장하기 위해서는 지연이 어디서 발생하는지 파악하는 것이 첫번째 할 일이었습니다.
처음 기획했던 피드백 시스템은 다음과 같은 과정을 따릅니다.
- 사용자 영상 입력
- 영상을 분류 서버로 전송
- 영상에서 미디어파이프 랜드마크 시퀸스 추출
- 슬라이딩 윈도우 방식으로 60프레임을 저장하는 버퍼를 갱신
- 갱신된 버퍼에 대해 분류 수행
- 분류 결과를 클라이언트로 전송(피드백 제공)
이런 방식으로 초기 프로토타입을 개발하여 테스트 한 결과, max total inference time이 298ms로 느리게 나왔습니다. 실시간이라고 느끼기에 사용자의 동작에 대해 298ms + alpha 시간 뒤에 피드백이 돌아오기 때문에 사용자가 답답함을 느낄 만한 시간입니다.
실시간성과 정확성을 함께 챙기기
두 번째 문제는 정확성 문제입니다. 이는 f1 score로 측정되는 모델의 예측 정확도와 별도로, 서비스 측면에서 모델의 정확도를 의미합니다. 모델의 정확도와 서비스의 정확도가 어떻게 다른지 아래의 예시로 살펴보도록 하겠습니다.
아래는 슬라이딩 윈도우로 갱신 된 입력 시퀸스에 대해 1초간의 모델 분류 결과입니다. (실제로 모델은 30FPS 기준 60프레임을 모아서 5개 프레임이 갱신될 때마다 분류를 하므로 정확한 분류 텀은 약 0.16초에 가깝습니다. 이는 단순 분류 시간의 측정인 total inference time과는 별도 개념임에 주의해주세요.)
| 시간(초) | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1.0 |
|---|---|---|---|---|---|---|---|---|---|---|
| 분류 1 | None | 언니 | 언니 | 언니 | 언니 | 언니 | 언니 | None | None | None |
| 분류 2 | None | None | 언니 | None | None | None | None | None | None | None |
이 시간별 분류 결과에서, 분류 1의 경우는 사용자가 '언니' 동작을 수행했다고 볼 수 있습니다. 0.2초부터 0.7초까지 총 0.6초간 모델이 입력 시퀸스를 '언니'로 분류했으니까요. 하지만 분류 2의 경우는 아무 동작 없이 가만히 있다가 노이즈로 인해 일시적인 '언니' 분류가 있었다고 봐야 합리적입니다.
사실 이런 노이즈는 서비스의 구조에 따라 아무 문제가 되지 않을 수도 있지만, 수어지교는 수어 피드백 기능을 위해 '임계값'을 활용합니다. '언니' 동작을 배우던 중 분류 결과의 confidence가 80퍼센트 이상이면 '언니'를 제대로 수행했다고 '정답' 처리를 합니다. 이런 구조에서 백엔드 서버가 이런 분류 2 결과를 그대로 내보낼 경우 임계값을 단발적으로 넘기고 예상치 못한 '정답' 처리가 될 수 있습니다.
정리
이렇게 수어지교 서비스가 꼭 해결해야 했던 문제를 살펴봤습니다. 이제부터 해결 방법을 보겠습니다.
실시간성
문제
기존 프로토타입에서 max total inference time이 298ms 였음을 살펴봤습니다. 지연 발생 지점들을 정리했었는데, 그것들에서 데이터 전송 과정은 생략하고 분류 서버와 클라이언트의 역할을 나누어서 보도록 하겠습니다.
| 클라이언트 | 분류 서버 |
|---|---|
| 1. 사용자 영상 입력 | |
| 3. 영상에서 미디어파이프 랜드마크 시퀸스 추출 | |
| 4. 슬라이딩 윈도우 방식으로 60프레임을 저장하는 버퍼를 갱신 | |
| 5. 갱신된 버퍼에 대해 분류 수행 |
분류 서버가 전처리와 분류를 전부 수행하고 있습니다. 또한, 640x480 해상도의 RGB 영상을 스트리밍하고 있으니 각 이미지 한 장의 용량이 922kib에 달하는 데이터를 지속적으로 전송하는 트래픽도 무시할 수 없습니다.
클라이언트의 부담을 조금 늘리면 서버의 부하를 줄일 수 있겠죠. 다행히도 미디어파이프 랜드마크 프레임워크는 CDN 배포를 지원하고, 최적화도 잘 돼 있고, 성능도 괜찮습니다.
해결: 미디어파이프 랜드마크 CDN
아래는 클라이언트에서 미디어파이프 랜드마크 시퀸스를 추출하는 코드입니다.
// 비디오 스트림 연결 및 MediaPipe 처리 시작
useEffect(() => {
if (currentStream && videoRef.current && isInitialized) {
videoRef.current.srcObject = currentStream;
videoRef.current.onloadedmetadata = () => {
if (videoRef.current) {
videoRef.current.play().catch(console.error);
// MediaPipe 처리를 위한 프레임 루프 시작
const processFrameLoop = () => {
if (holisticRef.current && videoRef.current && videoRef.current.readyState >= 2) {
holisticRef.current.send({ image: videoRef.current });
}
requestAnimationFrame(processFrameLoop);
};
processFrameLoop();
console.log('🎯 MediaPipe 프레임 처리 루프 시작됨');
}
};
}
}, [currentStream, isInitialized]);이 과정을 거치면 640x480 사이즈의 이미지에서 사람의 동작만을 의미하는 벡터값을 추출할 수 있습니다. 벡터 값의 사이즈는 아래와 같이 계산할 수 있습니다.
pose: 33 3 8 = 792 byte
left_hand: 21 3 8 = 504 byte
right_hand: 21 3 8 = 504 byte
총 1800 byte, 약 1.8kib에 불과하죠. 실제로는 (HTTP 1.0 웹소켓 특성상) 벡터 값이 텍스트 데이터로 넘어가기 때문에 표현되는 값에 따라 길이가 차이가 있을 수 있지만, 계산 편의상 그 부분을 무시하고 생각하면 전체 실시간 트래픽 용량을 약 92% 줄일 수 있습니다.
서버에서 전처리하는 과정이 없으니 백엔드 서버는 아래 함수를 통해 수신한 벡터 값을 feature engineering 후 분류를 바로 수행하면 됩니다. 웹소켓 메시지의 landmarks_data를 그대로 process_landmarks로 넘겨주면 아래와 같은 과정을 수행하여 마지막에 predict를 수행하는 모습을 볼 수 있습니다.
def process_landmarks(self, landmarks_data, client_id):
"""랜드마크 벡터 처리 및 분류 (성능 최적화 + 프로파일링)"""
...
# 1. 랜드마크 데이터 유효성 검사
if not self.validate_landmarks_data(landmarks_data):
logger.warning(f"[{client_id}] 잘못된 랜드마크 데이터")
return None
# 2. 랜드마크 데이터 수집
landmarks_list = []
landmarks_list.append({
"pose": landmarks_data["pose"],
"left_hand": landmarks_data["left_hand"],
"right_hand": landmarks_data["right_hand"]
})
# 시퀀스에 추가
self.client_sequences[client_id].extend(landmarks_list)
# 3. 예측 실행 빈도 제한 (성능 향상)
should_predict = (
len(self.client_sequences[client_id]) >= self.MAX_SEQ_LENGTH and
vector_count % self.prediction_interval == 0
)
result = None
if should_predict:
# 4. 랜드마크 전처리 (예측할 때만)
preprocessing_start = time.time()
sequence = self.improved_preprocess_landmarks(list(self.client_sequences[client_id]))
preprocessing_time = time.time() - preprocessing_start
# 5. 모델 예측
prediction_start = time.time()
pred_probs = self.model.predict(sequence.reshape(1, *sequence.shape), verbose=0)
...
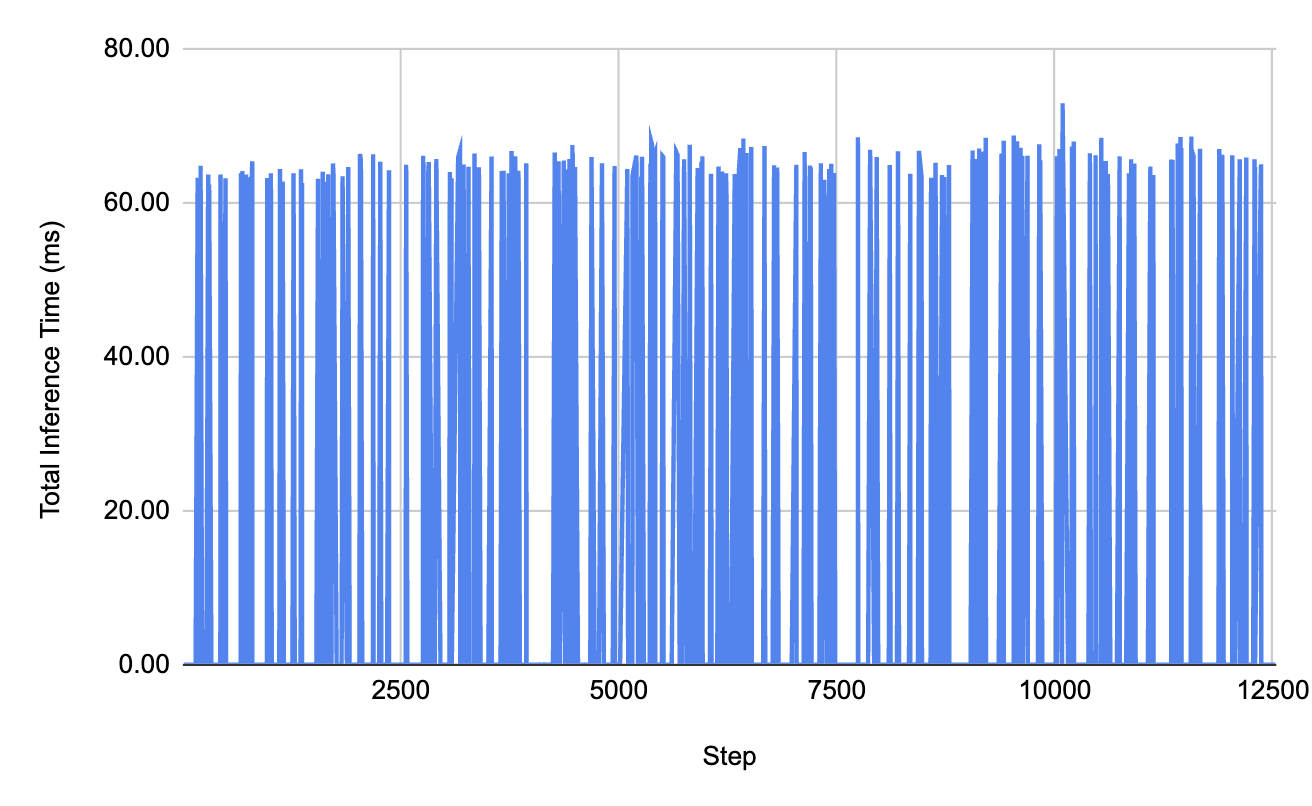
이러한 과정 생략 덕분에 서버측의 total inference time을 기존 293ms에서 아래와 같이 최대 72ms로 줄일 수 있었습니다. 이는 클라이언트 측의 특징점 추출에 걸리는 시간을 고려하지 않았기 때문에 실제로는 조금 더 시간이 걸릴 수 있습니다만, 메시지 하나를 처리하는데 서버 측 시간을 76.5% 줄였다는데는 큰 의미가 있습니다.
정확성
문제
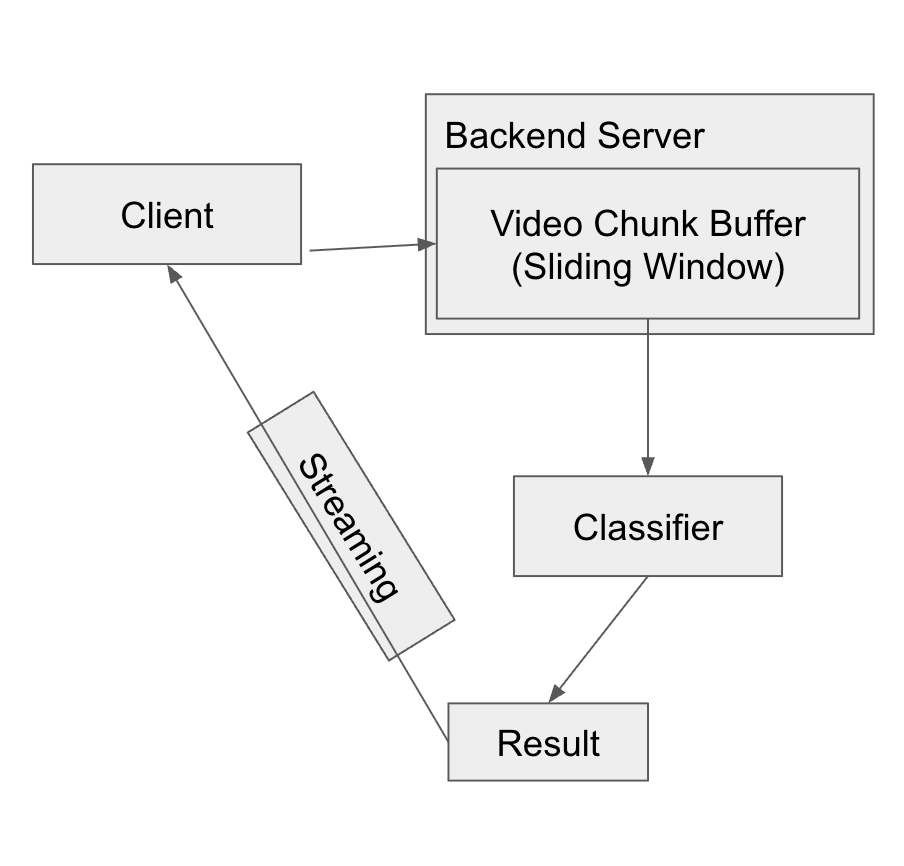
앞서 노이즈가 클라이언트의 피드백에 영향을 미치는 문제가 무엇인지 살펴봤습니다. 기존의 분류 서버는 아래와 같이 분류 모델(classifier)에서 분류 수행 후 그 결과를 바로 클라이언트로 전송했습니다. 임계값을 기준으로 '정답'을 판정하는 시스템에서 이런 방식은 노이즈 문제에 취약했죠.
시행착오
처음으로 고려했던 방식은 REST API를 혼합하는 방식이었습니다. 로컬에서 테스트 할 때처럼 모델이 0.5초 이상 같은 결과로 분류를 하면 별도의 응답을 클라이언트로 보내서 정답을 처리하는 방식이죠.
하지만 웹 소켓 연결에 별도로 REST API까지 섞어서 서비스 로직을 개발하려니 복잡하기도 하고, 과연 실시간 환경에서 강인하게 동작해줄지 우려스러웠습니다. 정확성을 챙기기 위해 실시간성과 안정성을 희생해야 하는 상황이었기에 좋은 선택이 아니라고 판단했습니다.
실시간 이동 평균도 실시간이다
이때 떠올린 아이디어는 분류 결과의 평균을 보내는 것이었습니다. 웹소켓 응답 메시지는 prediction, confidence, possiblities로 구성됩니다. 모든 라벨에 대한 예측 결과인 probabilites 중 최고 값의 라벨이 prediction, 확률이 confidence에 저장됩니다.
결과 예시
"prediction": "학교",
"confidence": 0.9,
"probabilities": ["학생":0.0, "강아지":0.1, "학교":0.9, "None":0.0]이런 상황에서, probabilites의 일정 길이 평균을 구한 후 prediction, confidence를 다시 지정해주면 해결해야 하는 문제인 노이즈를 smoothing 시킬 수 있겠다는 생각이 들었습니다. 일련의 probabilites로부터 prediction과 confidence를 다시 구할 경우 돌발적인 probabilites의 확률들은 다른 정상 값들에 의해 상쇄될 것이기 때문입니다.
def calculate_averaged_result(self, client_id):
"""버퍼의 분류 결과들의 평균을 계산"""
buffer = self.client_result_buffers[client_id]
if not buffer:
return None
# 모든 라벨에 대한 확률 합계 초기화
total_probabilities = {}
for label in self.ACTIONS:
total_probabilities[label] = 0.0
# 버퍼의 모든 결과에서 확률 합계 계산
for result in buffer:
for label, prob in result['probabilities'].items():
total_probabilities[label] += prob
# 평균 확률 계산
buffer_size = len(buffer)
avg_probabilities = {}
for label in self.ACTIONS:
avg_probabilities[label] = total_probabilities[label] / buffer_size
# 평균 확률이 가장 높은 라벨 찾기
best_label = max(avg_probabilities, key=avg_probabilities.get)
best_confidence = avg_probabilities[best_label]
# 평균 결과 생성
averaged_result = {
"prediction": best_label,
"confidence": best_confidence,
"probabilities": avg_probabilities,
"buffer_size": buffer_size # 디버깅용 정보
}
return averaged_result이 코드를 통해 아래와 같은 구조의 실시간 피드백 웹 구조를 구현할 수 있었습니다.
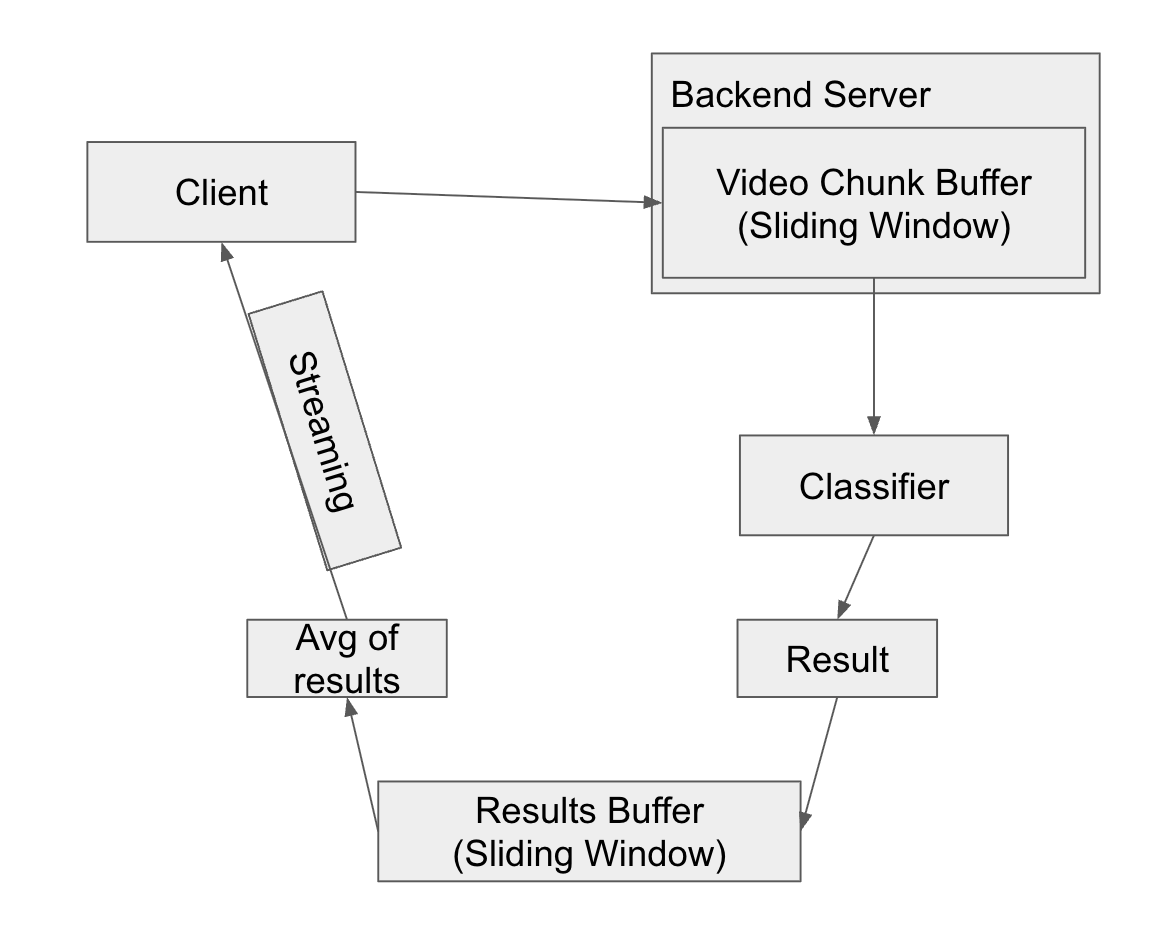
결과를 바로 보내던 자리에 결과들의 버퍼가 생긴 것을 보실 수 있습니다. 이 버퍼 요소가 슬라이딩 윈도우 방식으로 결과를 업데이트하고, 업데이트가 일어날 때마다 버퍼 요소의 평균을 구해 결과의 평균을 실시간으로 전달합니다. 이를 통해 별도의 REST API 통신을 구현하지 않고도 노이즈 문제를 해결할 수 있었으며, 어쨌든 결과가 전송되는 텀은 동일하기 때문에 실시간성도 보장할 수 있었습니다.
정확성 2
문제
수어 서비스를 개발하면서 모델에게 데이터 분류를 맡기기 전 모종의 규칙으로 필터링을 하는 것이 필요함을 체감할 수 있었는데요, 이는 아래와 같은 이유 때문입니다.
우선, 모델은 늘 무언가로 분류하려고 합니다. 처음에는 아무것도 하지 않는 동작, 즉 None 라벨이 필요하다는 생각을 못하고 특정 수어 동작 4개에 대한 분류가 가능한 모델을 학습시켰습니다. 이를 실제로 웹캠으로 테스트할 때, 제가 가만히 있는 동작마저도 다른 어떤 동작으로 분류되려고 하는 모습을 보고 '가만히 있는 동작' 그 자체도 분류의 대상임을 깨달았습니다. 그 후 모든 모델에 None을 기본으로 포함시켜 학습시켰습니다. 하지만 여전히 이는 위험성을 내포하고 있습니다.
만일 사용자가 의미 없이 손을 흔들어도 모델은 그에 대해 분류를 수행합니다. 확률은 낮을 수 있어도 말이죠. 따라서 실제 서비스에서 의미 없는 손 동작을 얼마나 잘 분류하느냐 역시 매우 중요한 과제였습니다.
여기에 대해서는 두 가지 방법이 있습니다.
이상적인 방법: 계층적 분류 구조
'유의미한 동작'과 '무의미한 동작'을 이진 분류할 수 있는 신뢰성 있는 모델을 학습시켜서, 이 모델이 사용자의 수어를 1차적으로 분류하는 방식입니다. 여기서 '유의미한 동작'으로 판명 나면 이를 다시 기존의 모델에 통과시켜 어떤 의미인지 판단하는 구조입니다.
하지만 이 간단한 이진 분류 모델을 구현하기가 너무 어려웠습니다. 모델이 유의미한 동작 패턴과 무의미한 동작 패턴을 구별할 수 있도록 학습시키기 위해서는 각각의 집합에 라벨링 된 데이터가 필요한데, 유의미한 동작은 기존 데이터로 학습시킬 수 있다 쳐도, 무의미한 동작 데이터는 찾지 못했습니다. 구현하고 싶다면 우선 데이터 수집과 라벨링부터 수행해야 했기 때문에 프로젝트 기간 중에는 수행이 어려웠습니다.
그래서 현실적인 방법으로 틀었습니다. 계층적인 구조는 유지하되, 필터링 주체를 모델에서 규칙으로 바꾸는 방안이었습니다.
현실적인 해결: 규칙 기반 필터링
아래 코드는 클라이언트에서 사용자의 동작의 가속도 값을 검사 후 임계값이 넘는지 검증하는 함수입니다.
const inspect_sequence = (sequence: any) => {
// console.log('🔍 시퀀스 검사 시작:', sequence.data.sequence?.length || 0, '프레임');
// 시퀀스 데이터 추출
const landmarksSequence = sequence.data.sequence as LandmarksData[];
if (!landmarksSequence || landmarksSequence.length < 3) {
return; // 최소 3개 프레임이 필요
}
// 가속도 계산을 위한 임계값 설정
const ACCELERATION_THRESHOLD = 300.0; // 가속도 임계값 (더 낮게 조정)
const FRAME_RATE = 30; // 예상 프레임 레이트
const FRAME_INTERVAL = 1 / FRAME_RATE; // 프레임 간격 (초)
// 노이즈 필터링을 위한 설정
const MIN_MOVEMENT_THRESHOLD = 0.01; // 최소 이동 거리 임계값 (낮게 조정)
const CONSECUTIVE_DETECTIONS_REQUIRED = 1; // 연속 감지 횟수 요구사항 (1로 줄임)
const TOTAL_MOVEMENT_THRESHOLD = 0.03; // 전체 이동 거리 임계값 (낮게 조정)
// 각 랜드마크 포인트의 가속도 계산 (손만 감지)
const checkAcceleration = () => {
let fastMovementCount = 0; // 빠른 동작 감지 횟수
for (let i = 1; i < landmarksSequence.length - 1; i++) {
const prev = landmarksSequence[i - 1];
const current = landmarksSequence[i];
const next = landmarksSequence[i + 1];
// 손 랜드마크 가속도 계산 (왼손)
if (prev.left_hand && current.left_hand && next.left_hand) {
for (let j = 0; j < Math.min(prev.left_hand.length, current.left_hand.length, next.left_hand.length); j++) {
const prevPos = prev.left_hand[j];
const currentPos = current.left_hand[j];
const nextPos = next.left_hand[j];
if (prevPos && currentPos && nextPos && prevPos.length >= 3 && currentPos.length >= 3 && nextPos.length >= 3) {
// 개별 프레임 간 이동 거리 계산
const movement1 = Math.sqrt(
Math.pow(currentPos[0] - prevPos[0], 2) +
Math.pow(currentPos[1] - prevPos[1], 2) +
Math.pow(currentPos[2] - prevPos[2], 2)
);
const movement2 = Math.sqrt(
Math.pow(nextPos[0] - currentPos[0], 2) +
Math.pow(nextPos[1] - currentPos[1], 2) +
Math.pow(nextPos[2] - currentPos[2], 2)
);
// 전체 이동 거리 계산 (시작점에서 끝점까지의 직선 거리)
const totalMovement = Math.sqrt(
Math.pow(nextPos[0] - prevPos[0], 2) +
Math.pow(nextPos[1] - prevPos[1], 2) +
Math.pow(nextPos[2] - prevPos[2], 2)
);
// 최소 이동 거리와 전체 이동 거리 모두 확인
if (movement1 < MIN_MOVEMENT_THRESHOLD && movement2 < MIN_MOVEMENT_THRESHOLD) {
continue; // 개별 프레임 간 이동이 너무 작음
}
if (totalMovement < TOTAL_MOVEMENT_THRESHOLD) {
continue; // 전체 이동 거리가 너무 작음 (미세한 움직임 무시)
}
const velocity1 = {
x: (currentPos[0] - prevPos[0]) / FRAME_INTERVAL,
y: (currentPos[1] - prevPos[1]) / FRAME_INTERVAL,
z: (currentPos[2] - prevPos[2]) / FRAME_INTERVAL
};
const velocity2 = {
x: (nextPos[0] - currentPos[0]) / FRAME_INTERVAL,
y: (nextPos[1] - currentPos[1]) / FRAME_INTERVAL,
z: (nextPos[2] - currentPos[2]) / FRAME_INTERVAL
};
const acceleration = {
x: (velocity2.x - velocity1.x) / FRAME_INTERVAL,
y: (velocity2.y - velocity1.y) / FRAME_INTERVAL,
z: (velocity2.z - velocity1.z) / FRAME_INTERVAL
};
const accelerationMagnitude = Math.sqrt(
acceleration.x * acceleration.x +
acceleration.y * acceleration.y +
acceleration.z * acceleration.z
);
if (accelerationMagnitude > ACCELERATION_THRESHOLD) {
fastMovementCount++;
console.warn(`🚨 빠른 동작 감지! 왼손 포인트 ${j}의 가속도: ${accelerationMagnitude.toFixed(3)} (${fastMovementCount}/${CONSECUTIVE_DETECTIONS_REQUIRED})`);
if (fastMovementCount >= CONSECUTIVE_DETECTIONS_REQUIRED) {
// alert(`너무 빠른 동작이 감지되었습니다!\n왼손 포인트 ${j}의 가속도: ${accelerationMagnitude.toFixed(3)}\n천천히 동작해주세요.`);
setIsBufferingPaused(true);
return true;
}
} else {
fastMovementCount = 0;
}
}
}
}
// 손 랜드마크 가속도 계산 (오른손)
// 생략
return false;
};
이 코드를 적용하기 위해 우선 0.5초 가량의 버퍼를 저장합니다. 버퍼의 미디어파이프 랜드마크 시퀸스에 대해 위 코드를 통해 가속도를 계산하고, 그 가속도가 임계값을 넘기면 의미 없는 휘젓는 종류의 손동작으로 판단하고 전송을 중단, 버퍼를 비워버리는 방식으로 코드가 구현됐습니다.
const is_fast = inspect_sequence(landmarksSequence);
if (!is_fast) {
if (isBufferingPaused && bufferingPauseTime > 0) {
console.log('bufferingPauseTime:', bufferingPauseTime);
setBufferingPauseTime(prev => {
const newTime = prev - 1000;
console.log('newTime:', newTime);
if (newTime <= 0) {
setIsBufferingPaused(false);
console.log('bufferingPauseTime 0 됨');
return 0;
}
else {
return newTime;
}
});
}
console.log("sendMessage 호출");
if (!isBufferingPaused) {
sendMessage(JSON.stringify(landmarksSequence), currentConnectionId);
}
} else {
console.log('❌ 동작 속도 빠름. 시퀸스 전송 건너뜀');
setDisplayConfidence('천천히 동작해주세요');
setIsBufferingPaused(true);
setBufferingPauseTime(3000);
setLandmarksBuffer([]);
}
setTransmissionCount((prev) => prev + prevBuffer.length);
// 버퍼 비우기
return [];
}
return prevBuffer;
});
}, BUFFER_DURATION);이 때문에 클라이언트 측에서 입력이 서버로 전송되는 속도가 대폭 줄어들었지만, 의미 없는 동작, 특히 휘젓는 종류의 가속도가 높은 동작을 규칙 기반으로 확실히 걸러줄 수 있게 되면서, 서버의 모델이 무리한 분류를 할 가능성을 차단할 수 있었습니다.
이상으로 '제대로 작동하는' 딥러닝 모델 활용 서비스를 구현하기 위해 서버 실시간 처리를 구현/개선한 방안을 살펴보았습니다. 다음 글에서는 모델이 어떻게 배포되며 작업을 분배하는지 살펴보도록 하겠습니다.
긴 글 읽어주셔서 감사합니다.
