🧶 복잡도 (Complexity)
흔히 알고리즘에서 쓰이는 복잡도(Complexity)란 그 알고리즘이 얼마나 효율적인지를 나타내는 지표의 의미이다. 특정 알고리즘이 어떠한 입력에 대하여 연산을 수행할 때 얼마만큼의 시간이 걸리는지와 얼마만큼의 메모리를 사용하는지, 이 2가지 관점에 대한 효율성을 측정하기 위한 개념이다. 즉 알고리즘의 성능을 판단하는 척도라고 보면 된다.
얼마만큼의 시간이 걸리는지를 나타내는게 '시간복잡도(Time Complexity)', 얼마만큼의 메모리를 사용하는지를 나타내는게 '공간복잡도(Space Complexity)' 이다.
⌛ 시간복잡도 (Time Complexity)
시간복잡도는 알고리즘이 얼마나 시간적으로 효율적인지, 즉 얼마나 짧은 시간 안에 연산을 수행할 수 있는지를 나타내는 지표로 의미적으로는 시간적인 개념이지만 실제로 코드에서 측정되는 대상은 '실행되는 연산의 횟수'이다.
동일한 알고리즘이어도 실행되는 컴퓨터가 좋으면 시간이 더 적게 걸리고 똥컴이면 더 오래 걸릴테니, 동일한 하드웨어 환경에서 동일한 코드를 실행하였을 때 실행되는 연산의 수를 기준으로 한다.
(근데 어차피 동일한 환경이라면 실행되는 연산의 횟수에 따라서만 걸리는 시간이 결정되니까 그냥 시간의 의미로 생각해도 되긴 함)
아무튼 실행되는 연산의 횟수를 따지는 복잡도인데, 단순히 특정한 입력에 대하여 실행되는 연산의 횟수만 보는게 아니라 입력의 크기가 증가함에 따라 실행되는 연산의 횟수(= 실행되는데 걸리는 시간)가 얼마나 증가하는지를 나타내는 것이다.
동일한 환경에서 동일한 코드를 실행하였을 때 입력 n의 크기가 증가함에 따라 실행되는데 걸리는 시간이 증가하는 그래프가 어떤 모양인지를 나타내는 것, 즉 입력과 (문제를 해결하는데 걸리는)시간의 함수 관계를 나타내는 개념이다.
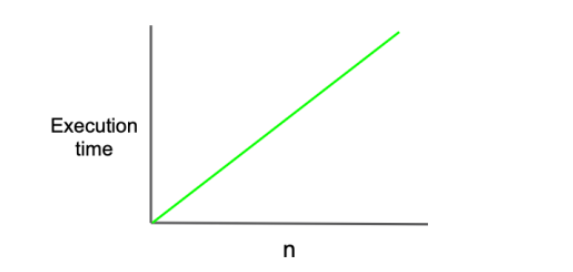
그리고 시간복잡도 측면에서 효율적인 알고리즘이라는 것은 이런 함수의 그래프의 기울기가 작다는 것이다. 이는 곧 입력의 크기가 증가함에 따른 시간의 증가 비율을 최소화했다는 의미로 볼 수 있다.
n의 크기의 증가에 따른 시간의 증가 그래프가 어떤 함수의 모양인지를 본다는 것은 n이 무한대로 갈 때 어떤 함수의 모양에 근접해지는지를 본다는 의미이고, 이를 '점근적 분석(Asymptotic Analysis)' 이라고도 한다.
그리고 입력과 실행 시간의 함수를 점근적 분석을 통해 어떠한 일반적인 함수로 표현하는 표기법을 '점근적 표기법' 이라고 한다. 그리고 이 표기법이 곧 시간복잡도의 표기법이 된다. 이 시간복잡도의 표기법은 아래와 같은 3가지 표기법이 존재한다.
💡 시간복잡도는 보는 관점에 따라 3가지의 표기법이 있다.
- Big-O (빅-오) : 최악의 경우를 고려 (상한 점근)
- Big-Ω (빅-오메가) : 최선의 경우를 고려 (하한 점근)
- Big-θ (빅-세타) : 평균적인 경우를 고려 (상한과 하한의 평균)
세가지 표기법도 모두 수학적으로 함수의 그래프에서 점근적 상한선, 점근적 하한선, 평균을 나타내는 것으로 보는 설명이 있지만 우리는 정확한 수학적인 의미가 궁금한건 아니니까 이런 수학적 개념보다는 그냥 의미적인 내용을 살펴보자.
궁금하다면 참고 : https://bblackscene21.tistory.com/7
예를 들어 길이가 n인 배열에서 특정 값을 가진 요소를 찾는 상황이라고 가정해보자.
(값이 동일한 요소는 없는 배열이라고 가정)
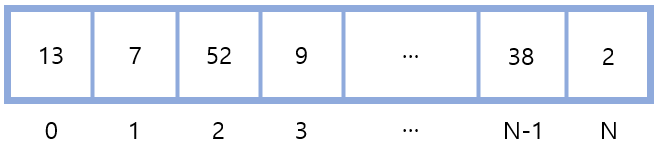
그리고 반복문을 써서 0번 인덱스부터 순서대로 배열을 순회하여 찾는 값과 동일한 값을 가진 요소를 찾는 상황이라고 가정하자.
동일한 알고리즘을 사용해도 찾는 요소가 배열의 앞쪽에 있으면 요소 몇개만 순회하면 되니 시간이 적게 걸리고, 찾는 요소가 배열의 끝부분에 있으면 거의 N개의 요소를 순회해야 하므로 시간이 오래 걸린다.
이러한 상황일 때 Big-O 표기법은 최악의 경우로, 찾는 요소가 N번 인덱스에 있는 상황에서의 코드의 연산 횟수를 따지는 표기법이다. 요소를 순회하는 연산을 N번 해야하는 최악의 경우를 상정하는 것이고 이는 즉 "이 코드의 연산 횟수는 아무리 많아도 N 이하다" 라는 상한 점근의 의미가 된다.
Big-Ω 표기법은 최선의 경우를 상정하여 나타내는 표기법으로, 위의 경우에서는 찾는 요소가 0번 인덱스에 있는 상황에서의 코드의 연산 횟수가 되겠다. 따라서 요소를 순회하는 연산을 1번 하는 최상의 경우를 의미하고 이는 "이 코드의 연산 횟수는 아무리 적어도 1 이상이다" 라는 하한 점근의 의미가 된다.
Big-θ 표기법은 그냥 최악의 경우와 최상의 경우의 평균치를 나타내는 표기법으로, 위의 경우에서는 찾는 요소가 중간쯤(N/2번 인덱스)에 있는 상황에서의 코드의 연산 횟수가 된다.
보통 코드의 시간복잡도를 나타낼 때에는 최악의 경우를 상정한 Big-O 표기법을 사용한다. 코드의 실행이 금방 끝나는 운좋은 경우의 값을 내세우며 효율성을 이야기하는 것 보다는 최악의 상황일 때의 값으로 따져 아무리 오래걸려도 이정도의 시간을 넘지는 않는다는 것을 보여주는게 코드의 일반적인 효율성을 보여주기에 타당하다고 볼 수 있다.
그래서 어떠한 알고리즘의 시간적인 효율을 판단할 때에는 시간복잡도를 보통 Big-O 표기법으로 나타내어 최악의 경우에 걸리는 시간을 기준으로 알고리즘의 성능을 표시한다.
시간복잡도 측정
Big-O 표기법을 기준으로 시간복잡도를 계산하는 방법을 알아보자.
let sum = 0;
for (let i = 1; i <= N; i++) {
sum += i;
}N이 input 값이라고 했을 때, 이 코드는 1부터 입력받은 값 N 까지의 총 합을 구하는 코드이다. 이 코드에서 수행되는 연산의 총 횟수를 구해보면
let sum = 0 과 for문의 let i = 1 은 코드의 최초 시행 시 한번씩만 실행된다. 따라서 이 둘의 실행 횟수는 2.
for문의 i++ 와 sum += i 는 for문이 실행될 때 마다 실행되는 연산이므로 for문이 N번 실행되는 상황에서는 각각 N번씩 실행된다. 따라서 이 둘의 실행 횟수는 2N.
(편의상 보통 for문에서는 for문의 let i = 1 이나 i++ 같은 내용까지는 따지지 않고 for문 안의 로직이 몇번 실행되는지만 따지는듯 하다. 이렇게 따지면 sum += i 라는 연산이 N번 실행되는 거니까 실행 횟수는 N)
그래서 위 코드에서 실행되는 연산의 총 횟수는 2N+2 이다. 이렇게 실행되는 연산의 총 횟수를 구했을 때 최고차 항을 제외한 나머지 항을 없앤 뒤 최고차 항의 계수를 없애면 Big-O 표기법의 시간복잡도 값이 된다.
이는 시간복잡도는 N의 크기가 엄청나게 큰 상태일 때 '가장 영향을 많이 끼치는 항 하나'로 표시하기 때문이다.
2N+2 에서 N이 증가함에 따라 2N은 기울기가 2인 선형 그래프로 한없이 값이 커지지만 2는 그냥 상수이므로 N이 1이든 10이든 10억이든 항상 값은 2이다. 따라서 N이 무한대로 갔을 경우 2는 2N에 비해 비교할 수 없을 정도로 작은 값이기 때문에 무시가 가능하다고 보는 것이다.
따라서 상수인 2는 제외하고 최고차항인 2N이 남고, 남은 최고차항의 계수 또한 무시가 가능한 값으로 취급한다. 2N과 N은 분명 N이 커질수록 차이가 커지긴 하지만 우리가 코드에서 시간복잡도를 따져서 보는 포인트는 N이 증가함에 따라 시간이 어떤 비율로 증가하는지 이기 때문이다. 값이 선형으로 증가하는지, 비선형으로 증가하는지, 상수처럼 변함이 없는지 등 함수 그래프의 모양이 중요하기 때문에 N의 차수가 중요하지 계수는 중요한 파라미터가 아니다.
그래서 위의 예시 또한 2N이나 N이나 N이 증가함에 따라 값이 '선형적'으로 증가한다는 점은 동일하기 때문에 계수를 생략하여 N이라는 값을 도출해 내는 것이다. 따라서 위 코드는 Big-O 표기법으로 나타내어 O(N) 이라는 시간 복잡도를 가지는 알고리즘이다.
이와 같은 규칙에 의거하여 또다른 알고리즘의 시간복잡도를 구해보자.
// 3번 할당
let a = 0;
let b = 0;
let c = 0;
// n*3n번 할당
for (let i = 0; i < N; i++) {
for (let j = 0; j < N; j++) {
a = i*j;
b = i*j;
c = i*j;
}
}
// 2n번 할당
for (let k = 0; k < N; k++) {
a = b * k + 45;
b = c * k;
}
// 1번 할당
let d = 10;일단 4개의 변수 할당문은 N의 값에 상관없이 1번씩 선언되므로 총 4.
2중 for문은 내부의 for문이 한 사이클당 3번의 연산을 하므로 N번의 사이클이면 3N번의 연산을 한다. 그리고 이 3N번의 연산 자체가 외부 for문에 의해 N번 실행되므로 총 실행 횟수는 3N^2.
1중 for문은 한 사이클당 2번의 연산을 하므로 N번의 사이클이면 총 실행횟수는 2N.
따라서 이 코드는 총 3N^2 + 2N + 4 의 실행 횟수를 가지는 로직이다. 이를 앞서 설명한 규칙으로 최고차항이 아닌 항들을 제거하고 최고차항의 계수를 제거하여 O(N^2) 이라는 시간복잡도을 계산할 수 있다.
이런식으로 실행 횟수를 계산하여 만든 함수가 어떤 형태의 함수에 점근적으로 근접하는지를 따져서 나타내는게 시간복잡도의 Big-O 표기법이고, 알고리즘의 시간복잡도를 나타낼 때 표준으로 사용하는 지표이다.
시간 복잡도의 종류
이렇게 연산 횟수를 직접 계산한 후 규칙에 따라 간단하게 일반화시켜 시간복잡도로 나타내면 시간복잡도는 일반적으로 다음과 같은 종류들로 분류된다.
O(1)
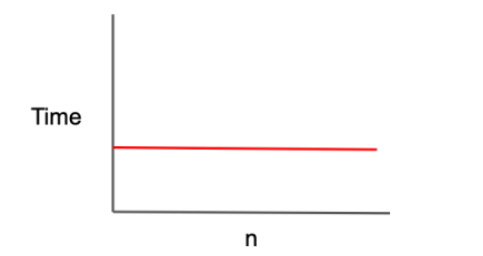
입력값이 증가하더라도 걸리는 시간이 증가하지 않는 상수 연산의 복잡도이다. '일정한 복잡도(constant complexity)' 라고도 부르며 입력값의 크기에 상관없이 가장 빠른, 가장 이상적인 시간 복잡도이다.
O(logN)
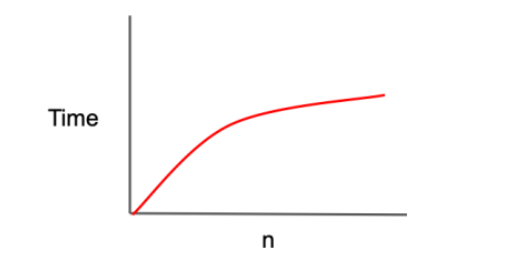
그래프가 로그함수의 모양으로 나타나며 '로그 복잡도(logaritmic complextiy)' 라고도 부른다. 입력값이 증가하면 걸리는 시간이 증가하다가 어느 정도 이상부터는 거의 증가하지 않기 때문에 N -> ∞ 인 스케일에서는 O(1) 그래프의 모습과 별로 차이가 없는 O(1) 다음으로 빠른 복잡도이다.
O(N)
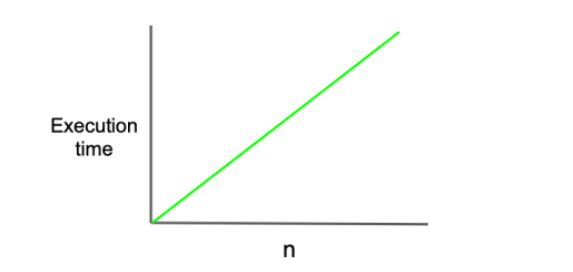
입력값이 증가함에 따라 걸리는 시간도 같은 비율로 증가하는 복잡도이다. 선형적으로 증가하기 때문에 '선형 복잡도(linear complexity)' 라고 부른다.
O(N^2)
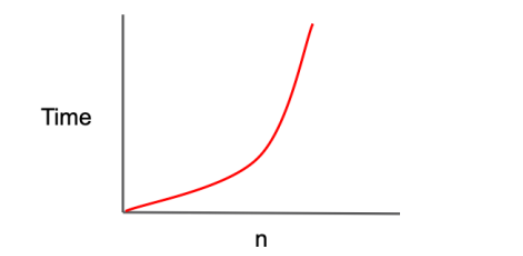
그래프가 2차 함수의 모양으로 나타나며 '2차 복잡도(quadratic complexity)' 라고 부른다. 주로 중첩 반복문인 경우 나타나는 유형의 복잡도이다.
O(2^N)
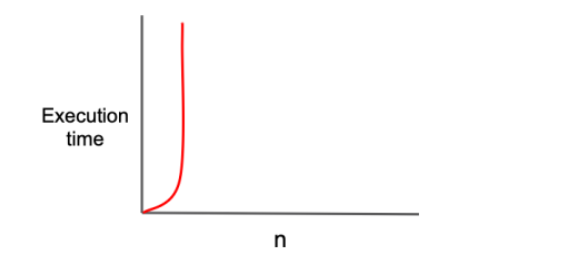
그래프가 지수 함수의 모양으로 나타나며 '기하급수적 복잡도(exponential complexity)' 라고 부른다. 2차 함수 보다도 더 기하급수적으로 올라가는 복잡도로 Big-O 표기법중 거의 가장 느린 시간 복잡도이다.
이런 유형들의 복잡도를 한 그래프에 나타내면 다음과 같다.
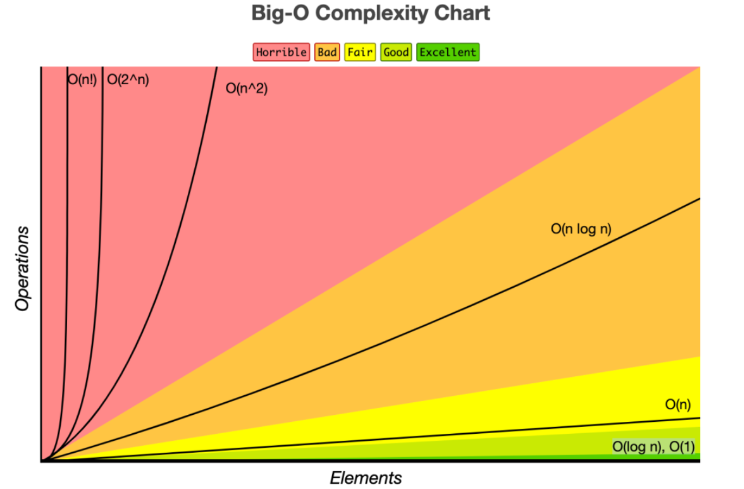
이렇게 시간 복잡도는 효율적인 코드로 개선하는 데 쓰이는 척도가 되는 지표이다. 시간 복잡도의 차수를 높이는 주된 요인이 보통 반복문의 중첩인데 같은 로직이어도 반복문을 최대한 중첩시키지 않는 방향으로 설계하여 O(N^2) 보다는 O(N)을, O(N) 보다는 O(1)을 지향하는게 효율적인 알고리즘을 짜는 가장 중요한 마스터키가 될 것이다.
🗃️ 공간복잡도 (Space Complexity)
공간 복잡도는 프로그램을 실행시켰을 때 필요로 하는 자원 공간의 양을 말한다. 알고리즘이 얼마나 많은 메모리 공간을 차지하는지에 초점을 맞춰 효율성을 분석하는 지표라고 보면 된다.
간단한 예를 들어 C언어에서
int a[1000];이라는 배열을 선언했다고 치면 배열의 요소는 int형이므로 4byte 이고, 이러한 요소가 1000개 있는 것이므로 차지하는 메모리 공간의 총량은 4000 byte 가 되는데, 이러한 공간을 의미한다.
보통 공간 복잡도는 시간 복잡도와 반비례하는 경향이 있다. 시간적으로 효율적인 로직을 짜기 위해서는 이런저런 변수를 사용하는 등 메모리 공간을 더 투자하는 경향이 많기 때문에 시간 효율성과 공간 효율성을 동시에 챙기기란 현실적으로 굉장히 어렵다.
하지만 요즘은 하드웨어의 발달로 인해 메모리 공간이 굉장히 넉넉해졌기 때문에 공간 복잡도의 중요도가 많이 낮아졌다고 한다. 그래서 시간 복잡도를 고려하지 않았을 때의 프로그램 실행 시 비효율성이 훨씬 크기때문에 지금은 시간 복잡도를 더 우선하여 효율성을 고려한다.
따라서 알고리즘의 효율성을 따질 때에는 시간 복잡도가 기준이 된다고 보면 된다!
참고 자료
https://www.youtube.com/watch?v=tTFoClBZutw
https://hanamon.kr/%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98-time-complexity-%EC%8B%9C%EA%B0%84-%EB%B3%B5%EC%9E%A1%EB%8F%84/
https://bblackscene21.tistory.com/7
https://insight-bgh.tistory.com/505#google_vignette
https://velog.io/@cha-suyeon/Algorithm-%EC%8B%9C%EA%B0%84-%EB%B3%B5%EC%9E%A1%EB%8F%84-%EA%B3%B5%EA%B0%84-%EB%B3%B5%EC%9E%A1%EB%8F%84#2-%EA%B3%B5%EA%B0%84-%EB%B3%B5%EC%9E%A1%EB%8F%84
