논문링크
간단한 논문 소개이다.
이 논문은 수학 문제 풀이에서 MCTS를 활용한 학습을 통해 7B llm으로 O1을 이긴 방법을 제시한다.

방법
바빠서 자세히 읽어보진 못했기에 간단하게 정리하겠다.
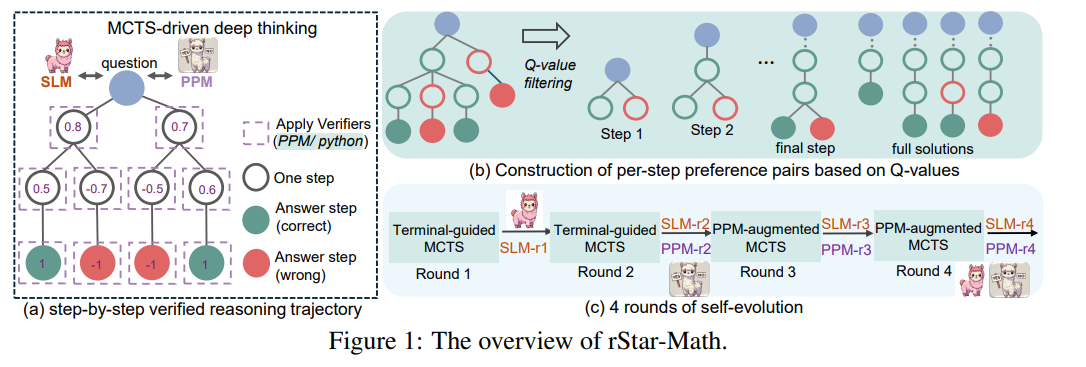
작은 LLM 즉 SLM은 빠르게 데이터 생성이 가능하기 알파고에서 rollout policy와 비슷한 기능을 할 수 있다.
이를 활용해서 MCTS를 진행할 수 있는데
SLM은 문제가 있다. 성능이 떨어진다...
심지어 답이 맞아도 풀이가 틀리는 경우도 존재한다.
그래서 이 논문은 위 그림처럼 code augmented COT를 제시하는데
 위처럼 파이썬 코드를 같이 생성하고 python 코드가 잘 실행이 되어 정답이 맞는지 확인이 되는 것들로만 진행을 하는 것이다.
위처럼 파이썬 코드를 같이 생성하고 python 코드가 잘 실행이 되어 정답이 맞는지 확인이 되는 것들로만 진행을 하는 것이다.
이 부분이 재밌었는데 LLM은 할루시네이션으로 억지로 답을 맞추는 즉, 1=2와 같이 말도 안되는 답을 생성할 때가 종종 있다. 이를 python code를 돌려서 스스로 답이 맞는지 확인해보는 과정을 진행하는 것인데 되게 재밌게 느껴졌다.
동시에 process preference model로 각 과정을 평가해서 Q value 즉, 점수를 매긴다.
이때 점수가 떨어지는 것들은 가지치기를 통해서 제거하면서 계속 진행을 하면 결국에는 점점 정확한 답을 생성해내게 될 것 이다.
자세히 읽어보진 않았지만 LLM에서 MCTS를 진행했다는 부분이 흥미롭고 위처럼 파이썬 코드로 정답을 검수했다는 것도 되게 흥미롭다.

AGI