[논문 리뷰 및 구현] AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
paper
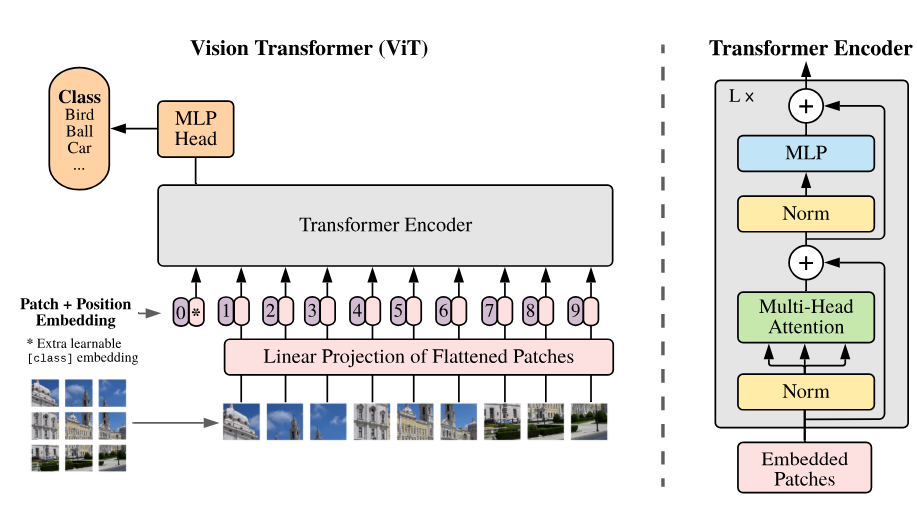
Abstract
- transformer 구조는 nlp 분야에서 사실상의 표준으로 사용되지만 vision 분야에서는 제한되어있다.
- vision에서는 attention을 cnn에 결합하거나 전체 구조는 유지하고 특정 구성요소를 대체하는 방향으로 사용이 되고있음
- 이 논문에서는 CNN에 대한 의존성을 끊고 순수 transformer가 image patch sequence를 통해서 image classification tesk를 잘 수행할 수 있다는 것을 보여줌.
- 많은 양의 데이터를 pretrain하고 적은 양의 benchmark dataset을 transfer learning을 하면 적은 비용으로 SOTA의 성능을 낼 수 있다는 것을 보임
1. INTRODUCTION
self-attention을 사용한 transformer 구조는 nlp 분야에서 당연한 선택이 되었다. 이 과정에서 transformer는 매우 방대한 데이터를 pretrain하고 특정 업무에 맞는 적은 데이터를 fine-tune하는 구조로 사용이 되었다.
transformer의 scalability와 computational efficiency 덕분에 100B 정도로 어마어마하게 큰 모델을 학습하는게 가능해졌고 매우 큰 모델 사이즈와 데이터셋에도 성능이 정체되지 않았다.
그러나 컴퓨터 비전에서는 attention을 사용하기 제한이 되었는데 이전에 시도된 방법들은 convolution을 특정 부분 변환하거나 완전히 바꾸는 방식이 존재했는데 완전히 바꾸는 방식은 특정 알고리즘에 의존을 하기 때문에 현대 하드웨어 구조상 구조를 크게 키울 수 없다.
결국 아직도 vision분야에서는 ResNet기반의 모델이 SOTA의 지위를 가진다.
이 논문에서는 vision 분야에서 transformer을 적은 수정으로 적용한 방법과 모델 구조를 제시한다.
- 이미지를 특정 patch로 나눈 다음 linear embedding을 붙인다.
- 이미지 patch는 nlp의 token과 처럼 처리가 된다.
- 모델을 image classification tesk에 지도학습으로 학습한다.
여기서 중요한 점은 모델을 중간 크기 데이터셋으로 학습을 하였을 때에는 ResNet보다 안좋은 점수를 보였지만
엄청나게 큰 데이터셋으로 pretrain을 진행하고 특정 테스크에 fine-tune을 진행하면 매우 좋은 성능을 보였다는 것이다.
이는 nlp 분야에서 모델을 학습하는 방법과 동일하다.
중간 크기의 dataset에서 transformer가 안좋은 성능을 보인 이유는 CNN에 비해서 inductive bias 즉 학습하는 과정에서 없던 경우를 추측하는 성능이 떨어지기 때문이다.
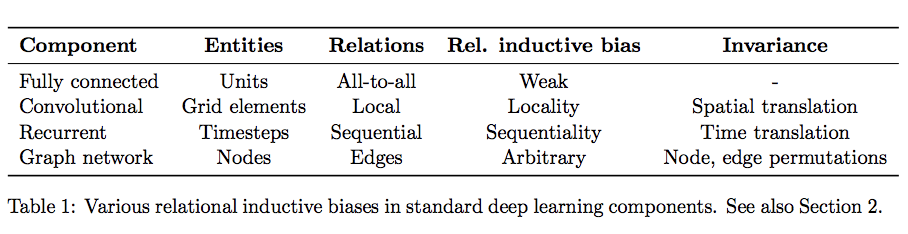
deep learning 에서 inductive bias를 나타낸 표인데 여기에서 Relation inductive bias는 입력과 출력의 관계에 따라서 나타낸 것이다. Fully connected layer는 모든 layer가 연결되어 있기 때문에 Rel. inductive bias가 약하고 Convolution은 공간적으로 inductive bias가 존재한다.
inductive bias란
모델의 정확도를 늘리기 위해 데이터에 대한 knowledge를 활용한 추가적인 가정이다.
추가적인 가정을 먼저 세우고 이에 따라서 모델을 만든다.
위 그림을 보면 Fully connected layer는 모든 input이 영향을 가지지만 Convolution layer는 공간적으로 특정 부분만 영향을 준다. 이는 우리가 이미지를 인식할 때 주변의 픽셀이 관련성이 높다는 사실을 반영한 inductive bias이다.
Recurrent layer는 비슷하게 시간의 흐름이 영향을 준다.
Convolution을 중점으로 설명하자면 모델의 공간적인 내용이 영향을 주기 때문에 대칭적인 이미지나 이미지의 같은 사물을 인식하는 성능이 증가하게 된다.
그러나 transformer는 모든 input에 대해서 영향력을 따지기 때문에 fully connected layer와 같이 inductive bias가 약하다.
3. Method
3.1 VISION TRANSFORMER (VIT)
원래 기존 transformer는 1D token들의 sequence를 input으로 받는다.
(seq, tok)
2D를 처리하기 위해
의 구조로 구성된 이미지를 의 구조로 변환한다. 여기에서 는 해상도이고 는 채널이다.
는 각각 이미지를 patch로 나눴을 때 patch의 크기이고 의 크기로 Patch가 나뉜다.
transformer는 (seq, tok)의 차원으로 vector를 받기 때문에
각각의 patch를 flatten 해서 D차원으로 할당한다. 즉 으로 구성된 flatten patch에 로 구성된 linear layer를 곱해서 D차원으로 바꿔준다.
그리고 추가로 BERT와 비슷하게 학습가능한 class token을 붙이고
학습 가능한 positional embedding을 더해준다.
class token은
bert 입력의 제일 처음에 들어가며 해당 문장의 대표 임베딩 결과로 나머지 문장 token sequence들의 결합된 의미를 가지게 되는데 classification task의 경우 이 cls 토큰에 간단한 classifier를 붙여서 사용한다.
class 토큰은 마지막에 이미지의 표현을 담당한다.
여기에서 은 0번째 토큰의 마지막 layer의 출력을 뜯한다. Layer Normalization을 적용해서 이미지의 표현을 담당한다.
pre-train과 fine-tune 과정에서 classification head가 에 부착이 되고 pre-train에서는 1개의 hidden layer를 가진 MLP로 수행이 되고 fune-tune 과정에서는 1개의 layer로 linear layer로 구현이 된다.
positional embedding은 이미지의 위치를 표현하는데 사용이 되고 1D learnable positional emedding을 더함으로써 구현이 된다.
,
수식으로 표현하면 위와 같다.
이후 transformer encoder은 multihead self-attention과 MLP block으로 구성이 되어있고 각각 block의 전에는 LN(layer normalization)이 들어가있고 block 뒤에는 residual connection이 들어가있다.
수식으로 표현하면 다음과 같다.
Inductive bias
CNN은 이미지에 특화된 iductive bias가 vision transformer보다 훨씬 많다. 예를 들어 locality(인접 픽셀 인식), two-dim neighborhood structure(2차원 구조), translation equivariance(물체 옮겨도 동일하게 인식) 이 있다.
그러나 vit에는 오직 MLP layer에서만 locality와 translation equivaliance가 존재한다. 2차원 구조는 초반에 patch를 자르는 때나 fine-tune 과정에서 이미지의 해상도를 수정하기 위해 positional embedding을 수정하는데 사용되는 등 거의 사용되지 않는다.
여기에서 이미지의 해상도를 수정할 때
4x4의 이미지를 8x8로 수정한다고 치면 기존 4x4의 사이 embedding을 평균화 시켜서 아래와 같이 해상도를 늘릴 수 있다.
이미지 출처
결국 2차원 구조는 학습 과정에서 모델이 기초부터 학습을 해야 한다.
Hybrid Architecture
raw 이미지 feature에서 patch를 가져오는 대신에 CNN의 feature map을 가져오는 것이 가능하다.(나도 생각했던 부분이다.)
이 hybrid 구조에서는
,
위 수식의 E는 x에 적용이 되는 것이 아니라 CNN으로 뽑아낸 feature map에 적용이 된다.
특수한 경우로 patch의 크기가 1x1이 될 수 있는데 이 때에는 input sequence는 그냥 feature map을 flattening을 하고 transformer dim로 projection을 진행한다.
3.2 FINE-TUNING AND HIGHER RESOLUTION
ViT를 large dataset에서 pretrain한 다음 downstream task에 fine-tune을 진행하였다.
이 때 pretrain된 prediction head 즉 위에서 언급한 1개의 hidden layer를 가진 MLP를 제거하고 0으로 초기화한 의 feedforward layer를 추가한다. 는 downstream task의 class 숫자이다.
pretrain보다 높은 해상도로 fine-tune을 하는 것이 이득일 수도 있다.
high resolution 이미지를 같은 patch size로 나눈다면 더 많은 patch가 나오기 때문에 더 긴 sequence가 나온다.
그러나 vision transformer는 input sequence의 길이에 제한이 없지만 학습된 positional embedding이 의미가 사라질 수 있다.
그러기 위해서 positional embedding을 원본의 위치에 따라서 보정한다.
이는 위에서 언급한 평균화에 대한 내용으로 생각된다.
4. Experiments
모델을 다양한 크기의 데이터셋으로 pretrain을 진행하고 테스트하였다.
pretrain의 computational cost 관점에서 ViT는 적은 비용으로 SOTA를 달성하였다.
4.1 setup
Datasets
pretrain을 위해
- ImageNet-1K -> 1K의 class, 1.3M개의 이미지
- ImageNet-21K -> 21K개의 class, 14M개의 이미지
- JFT -> 18K class, 303M high-resolution 이미지
이후 각각 cifar10/100등 task에 맞게 fine-tune을 진행
Model Variants
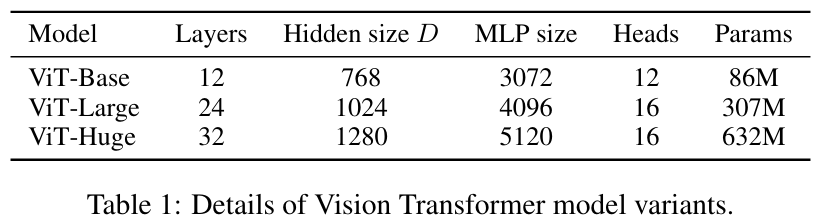 ViT configuration은 Base, Large model은 BERT를 가져와서 사용했고 Huge 모델은 직접 구축하였다.
ViT configuration은 Base, Large model은 BERT를 가져와서 사용했고 Huge 모델은 직접 구축하였다.
이후에 나올 notation에서 ViT-L/16같은 경우 ViT-Large model에서 Patch size=을 의미한다.
참고로 transformer의 sequence length는 patch size의 제곱에 반비례하기 때문에() patch size가 작은 모델일수록 더욱 비싸다.
baseline CNN은 ResNet에서 Group Normalization, standardized convolution을 사용한 모델을 사용하였다.
그리고 hybrid로 CNN을 featuremap에 사용한 ViT모델의 경우 ResNet (BiT)라고 표기를 하였다.
4.2 COMPARISON TO STATE OF THE ART
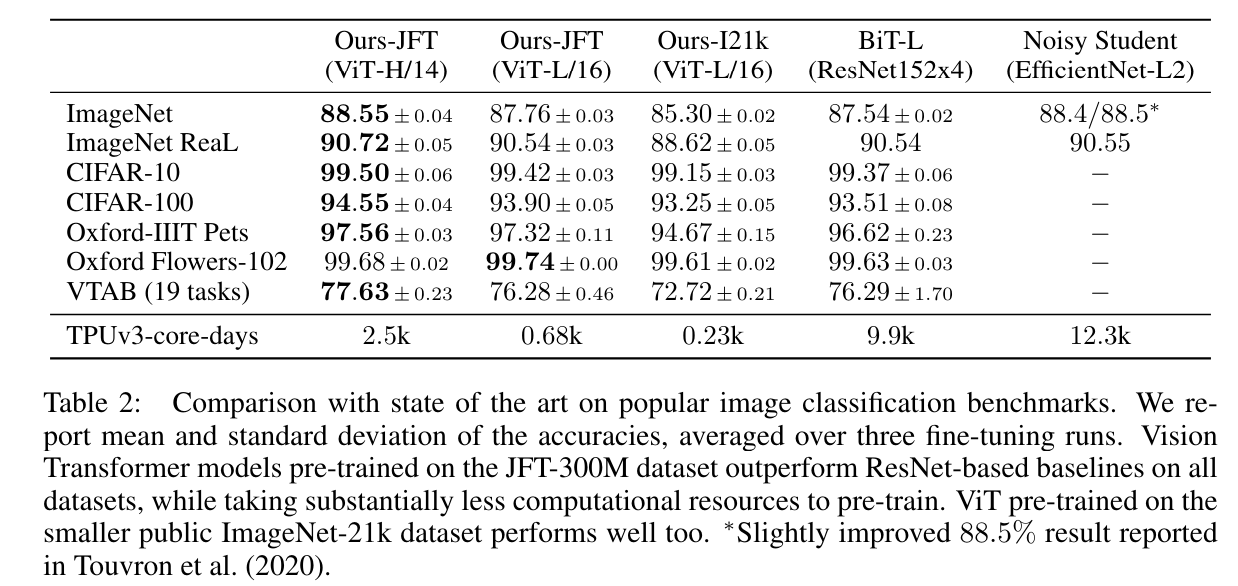 SOTA 모델인 BiT-L, Noisy Student 등의 모델과 비교를 하였는데
SOTA 모델인 BiT-L, Noisy Student 등의 모델과 비교를 하였는데
JFT로 pretrain한 ViT-L/16의 모델부터 이미 BiT-L, Noisy Student 등 더 적은 비용으로 ResNet base SOTA 모델을 이기는 모습을 보여준다.
TPUv3-core-days는 1일 안에 학습하기 위해 필요한 TPUv3 코어의 개수를 의미한다.
예를 들어 0.23k의 경우 8 core TPU로 30일 가깝게 학습하면 학습이 끝난다.
4.3 PRE-TRAINING DATA REQUIREMENTS
pretrain을 ImageNet-1K, ImageNet-21K, JFT 각각 크기에 따라서 비교하였을 때 어떻게 된지 실험한 부분이다.
fine-tune 시에는 regularization은 모두 동일하게 weight decay, drop out, label smoothing 3개가 사용되었다.
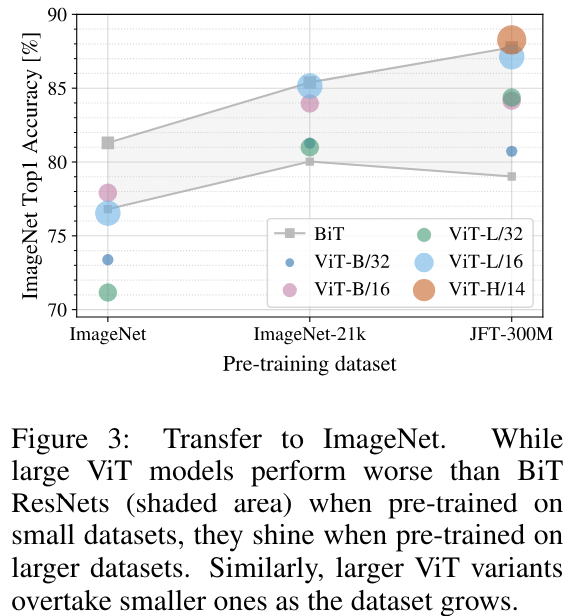 결과는 위와 같다.
결과는 위와 같다.
ViT-H 제일 큰 모델은 처음에는 이미지에 나오지도 못할 정도로 성능이 안좋다가 300M 데이터에서 급격하게 상승하였다.
다른 ViT 기반 모델들 역시 regularization이 존재함에도 초반에는 BiT보다 눈에 띄게 안좋은 성능을 내었다.
그러나 데이터의 수가 늘어나면서 성능의 증가를 보였다.
요약하자면 ResNet 기반 모델은 적은 데이터에서 좋은 성과를 보이는 반면 transforemer 기반의 모델은 많은 데이터에서 좋은 성과를 보였다.
4.4 Scaling Study
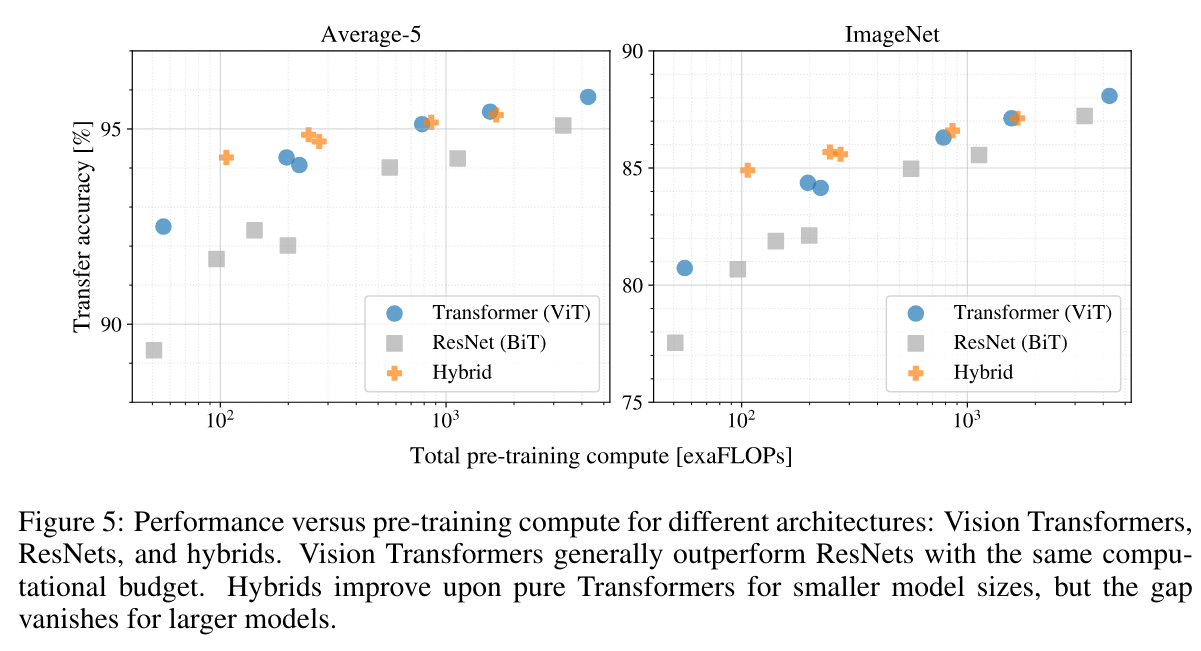 이 부분에서는 모델의 계산량에 따라서 정확도를 정리한 표이다.
이 부분에서는 모델의 계산량에 따라서 정확도를 정리한 표이다.
1. 표를 봤을 때 같은 계산량에 대해서 ResNet보다 transformer가 더 좋은 성능을 보인다는 것을 알 수 있다.
2. cost가 낮을 때에는 hybrid가 transformer모델보다 더 좋아보이지만 cost가 높아지면서 차이가 감소한다.
3. transformer 모델이 현재 주어진 범위에서의 테스트에서 정체되지 않는 모습을 보여줬다.
4.5 INSPECTING VISION TRANSFORMER
결국 이미지를 처리하는 모델이기 때문에 ViT가 어떻게 이미지를 인식하는지 내부를 확인해보았다.
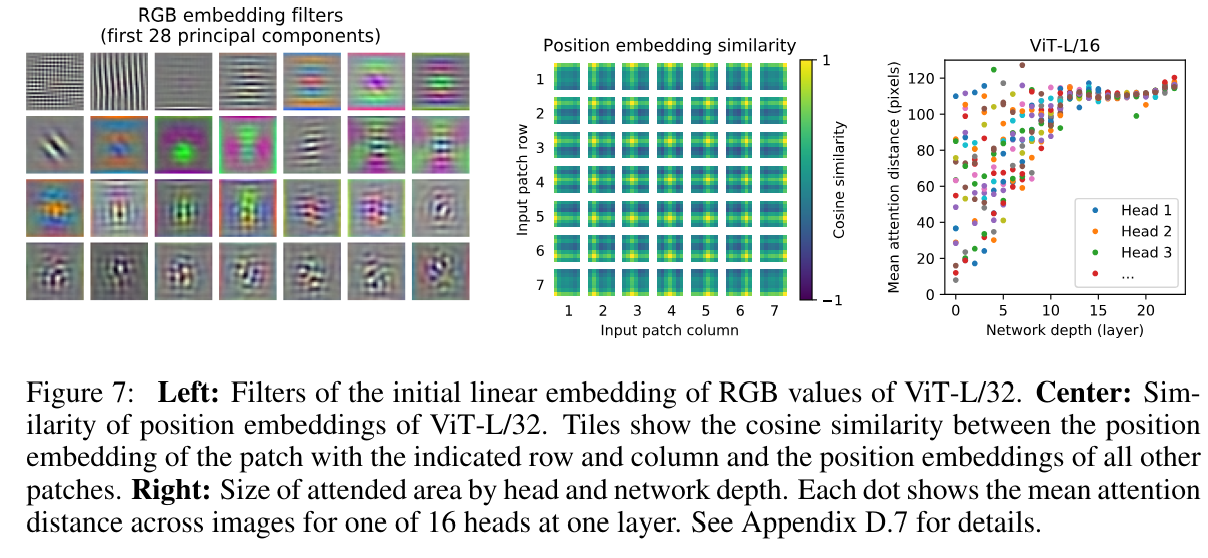 왼쪽은 ViT-L/32 모델의 input에 flatten 된 patch를 projection하는 linear embedding의 component를 보여주는 모습인데 각 저차원의 patch에서 그럴듯한 기초를 만들어준다.
왼쪽은 ViT-L/32 모델의 input에 flatten 된 patch를 projection하는 linear embedding의 component를 보여주는 모습인데 각 저차원의 patch에서 그럴듯한 기초를 만들어준다.
가운데 사진은 learned positional embedding의 모습인데 자신의 patch와 다른 patch들 모두와 cos_similarity를 구한 모습이다.
모델이 비슷한 위치의 patch에 대해서 비슷한 embedding을 부여함으로써 관련성이 높게 판단하는 모습을 보여준다.
심지어 동일한 행/열은 동일한 position embedding을 가진다.
이는 모델이 2차원 구조를 학습했다는 것을 보여준다.
결국 수동으로 만든 position embedding의 결과와 자동으로 학습한 것의 결과가 비슷한 것을 설명할 수 있다.
오른쪽 사진은 average attention distance를 나타낸 그림이다.
average attention distance는 attention layer가 참조하는 부분의 거리의 평균을 의미한다. 낮을 수록 가까운 곳을 참조하고 클수록 먼 곳을 참조한다.
예를 들어
고양이는 쥐를 쫓아 집 밖으로 달려갔다. 라는 문장에서
각각 토큰을
[1]고양이는 [2]쥐를 [3]쫓아 [4]집 [5]밖으로 [6]달려갔다.
로 표현을 한다면
"달려갔다"(6)가 "고양이는"(1)에 attention을 가장 많이 기울인다면 거리는 5이다.
만약 동시에 "쫓아"(3)에도 attention을 기울인다면 거리는 3이 되고 평균은 (5+3)/2=4가 된다.
이 정보를 토대로 알 수 있는 사실은
시작 부분의 layer부터 거리 낮은 곳과 높은 곳을 참조함으로써 국소적인 정보와 전반적인 정보를 참조하는 것을 알 수 있다.
또한 layer가 깊어질수록 멀리 있는 정보를 참조하는데
전체적으로 모델 아래 그림과 같이 classification에 필요한 정보에 집중을 한다.

4.6 SELF-SUPERVISION
여기에서는 모델의 학습 과정에서 BERT의 masking을 따라해서 사용한 masked patch prediction을 사용해서 모델을 self-supervision을 진행하였다고 나와있다. 각각 patch를 masking 하고 self 예측 학습을 진행하는 것이다.
self-supervised pretrain을 진행한 모델은 scratch에서 학습한 모델보다 2%의 향상을 보였지만 supervised pretraining을 진행한 것보다 4% 뒤쳐진 결과를 내었다.
결국 transformer 모델에서 중요한 부분은 scalability와 많은 selfsupervised pretrain dataset의 영향이라고 본다.
5. Conclusion
이 논문에서는 trasnformer 구조를 image recognition 분야에 직접적으로 사용하였다.
이전의 다른 self attention을 image 분야에 사용한 논문과는 다르게 patch를 초기 설정할 때 사용하는 것을 제외하면 image-specific inductive bias를 추가하지 않았다.
그리고 이미지의 patch를 sequence로 보고 transformer의 encoder를 사용해서 처리하였다.
이러한 방식은 큰 모델에서 대량의 pretrain dataset과 합쳐져서 매우 효과적으로 작동을 하였다.
그러나 아직 ViT에 대한 많은 도전이 남아있다.
datectio이나 다른 분야의 task에도 시도해볼 수 있을 것이고 self-supervised pretrain의 방법론을 분석해볼 수 있을 것이다.
구현
multi head attention과 scaled dot-product는 이전 게시글에서 구현을 하였기에 생략을 하였다. attention 구현
이번에는 multi head attention과 sacled dot-product를 활용해서 encoder와 ViT 모델을 32x32 cifar10 이미지를 목표로 구축하였다.
class Encoder_block(nn.Module):
def __init__(self, d_model=512, num_head=8, dropout=0.1):
super().__init__()
self.attention = multi_head_Attention(d_model, num_head)
self.norm1 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.FFN = nn.Sequential(
nn.Linear(d_model, d_model*4),
nn.ReLU(),
nn.Linear(d_model*4, d_model)
)
self.norm2 = nn.LayerNorm(d_model)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x):
x = x + self.dropout1(self.attention(self.norm1(x)))
x = x + self.dropout2(self.FFN(self.norm2(x)))
return x
class ViT(nn.Module):
def __init__(self, class_num=10, d_model=384, num_head=6, img_size=32, patch_size=4, num_block=6):
super().__init__()
self.patch_size = patch_size
self.num_patch = (img_size//patch_size)**2 # 64개
self.d_model = d_model
self.num_head = num_head # 각 head마다 d_k=d_v=64
self.layers = nn.ModuleList([Encoder_block(d_model, num_head)
for _ in range(num_block)])
self.out = nn.Linear(d_model, class_num)
# input shape: (batch, 3, 32, 32)
self.cls_token = nn.Parameter(torch.randn(1, 1, d_model))
self.patch_embedding = nn.Linear(3*patch_size**2, d_model)
self.pos_embedding = nn.Parameter(
torch.randn(1, self.num_patch+1, d_model))
def forward(self, x):
# input shape: (batch, 3, 32, 32)
# 이미지를 patch로 나누기
# (batch, 3, 32, 32) -> (batch, 3, 8, 8, 4, 4)
x = x.unfold(2, self.patch_size, self.patch_size).unfold(
3, self.patch_size, self.patch_size)
# (batch, 3, 8, 8, 4, 4) -> (batch, 8, 8, 3, 4, 4) -> (batch, 64, 3*4*4)
x = x.permute(0, 2, 3, 1, 4, 5).reshape(
x.size(0), -1, self.patch_size**2*3)
# (batch, 64, 3*4*4) -> (batch, 65, 3*4*4) cls_token 추가
cls_token = self.cls_token.expand(x.size(0), 1, self.d_model)
x = torch.cat((cls_token, self.patch_embedding(x)), dim=1)
x = x + self.pos_embedding
# (batch, 65, 384)
for layer in self.layers:
x = layer(x)
x = x[:, 0]
return self.out(x)
cifar10 데이터로
- sgd
- lr 0.01
- weight decay 0.0001
- momentum 0.9
- batch size 512
- epoch 300
- multi step [150, 225]마다 * 0.1
의 옵션으로 학습을 시켜보았는데 다음과 같은 모양이 나왔다.
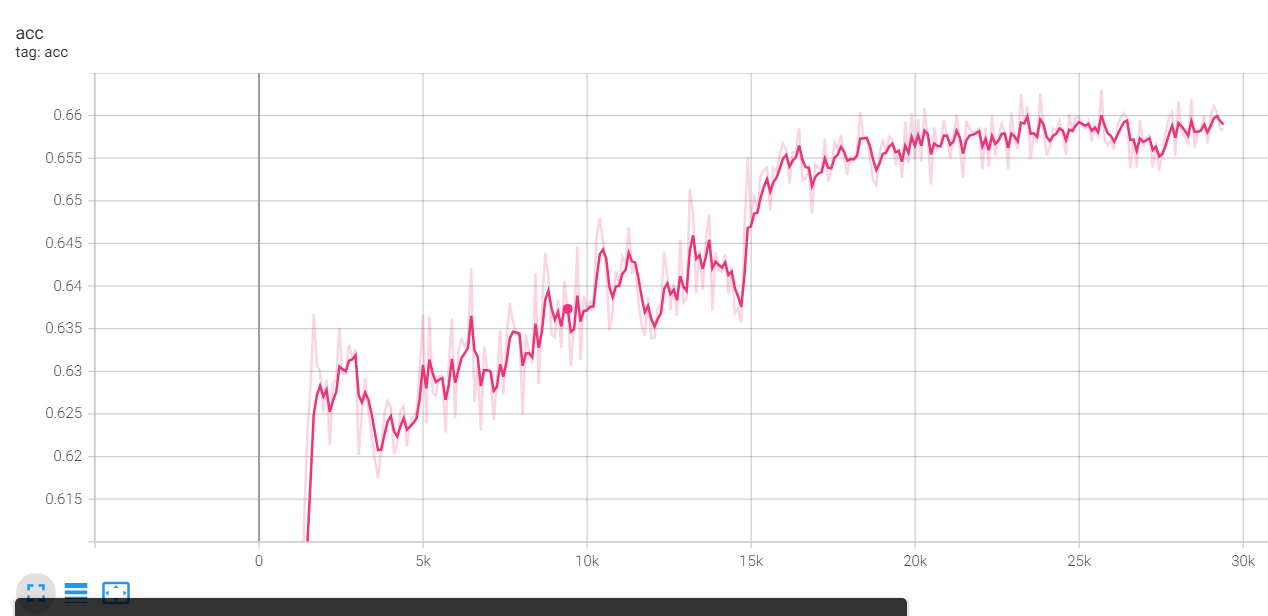
정확도가 대략 0.66이 나왔는데
adamw로 cos annealing T_max=100, weight decay=0.1 으로 학습 하였을 때는 정확도가 최대 0.75까지 나왔다.
