Abstract
이 논문은 k-means와 같은 clustering에 기반한 self-supervised learning 방법론인 Deep cluster을 제시한다.
이 방법을 통해 SOTA를 달성
1. Introduction
현재 모델의 성능이 정체된 이유가 "고작" 수백만 밖에 안되는 데이터셋의 크기임을 지적하고 라벨링하여 만든 데이터도 비싸고 bias가 낄 수 있음을 이야기하며 unsupervised한 방법론의 필요성을 제시한다.
이전의 CNN을 이용한 K-means 학습 알고리즘은 representation이 0으로 가거나 cluster가 1개로 모이는 trivial solution으로 도달하였다.
이 논문은 large-data로 end-to-end 학습이 가능한 방법론을 제시한다.
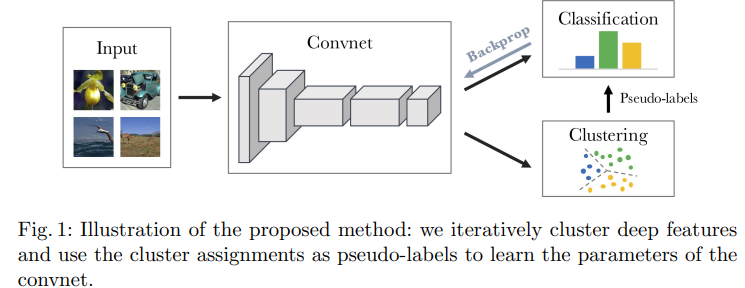 내용은 이미지의 representation을 clustering을 진행하고 이를 토대로 classification을 진행한다.
내용은 이미지의 representation을 clustering을 진행하고 이를 토대로 classification을 진행한다.
이 논문은 k-means를 주로 다루지만 다른 clustering 방법론도 가능하다.
3. Method
3.2 Unsupervised learning by clustering
만약 encoder의 weight 가 gaussian distribution으로 random init이 된다면 representation의 성능이 어떻게 나올까?
랜덤한 representation이 나오기 때문에 ImageNet 1k기준 0.1% 즉 1/1000이 나올 것 같지만 그렇지 않다.
random AlexNet 위의 MLP classifier의 성능은 12%가량 나온다!
convnet의 좋은 성능은 그 자체의 구조에서도 나오는 것이다.
이 논문의 아이디어는 여기에서 출발한다.
그 초기의 signal을 활용해서 학습을 하는 것이다.
- convnet의 output을 cluster을 하고 이를 K-means를 활용해서 pseudo-label을 만든다.
- 이후 그 pseudo-label을 활용해서 모델을 학습한다.
- 이를 반복한다.
K-means 알고리즘을 수식으로 표현하면 다음과 같은데
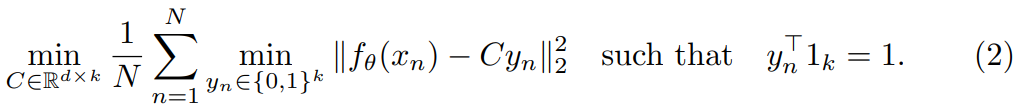 논문에서는 d가 무슨 의미인지 알려주지 않는데 아마 representation의 dim같다. 이후 K개의 중심을 찾는데
논문에서는 d가 무슨 의미인지 알려주지 않는데 아마 representation의 dim같다. 이후 K개의 중심을 찾는데
1. 과 가장 가까운 center를 찾고
2. 거리를 최소화하는 곳으로 중심 를 옮긴다.
이렇게 문제를 해결하게 되면 optimal assignment 이 center 에서 나오게 된다.
3.3 Avoiding trivial solutions
이때 trivial solution이 나오는 것이 가능하다.
Empty clusters
모든 sample이 1개의 cluster에 있는 것이 가능.
empty cluster이 발생하는 것을 막는 것이 없기에 발생한다.
보통 feature quantization에서 사용하는 방법은 자동으로 empty cluster를 재할당하는 식으로 막는다.
구체적으로는 만약 cluster가 비게 된다면 여러개가 할당되어있는 cluster 중 하나를 고르고 그 중심을 조금 바꾼 부분으로 재할당을 시도한다.
Trivial parametrization
대부분의 이미지가 몇개의 cluster에 독점적으로 들어있다면 는 그것들을 중심으로 구분할 것이다.
만약 1개의 cluster가 독점을 한다면 convnet은 동일한 output만 만들어낼 것이다.
이러한 문제를 해결하기 위해서 data를 pseudo label에 대해 uniform하게 sampling이 되어야 한다.
loss function에 cluster의 크기에 대한 역수 가중치를 두어서 해결한다.
4 Experiments
4.1 Preliminary study
A와 B의 두가지 다른 assignment에서 공유되는 정보를 비교하기 위해서 Normalized Mutual Information(NMI)를 사용
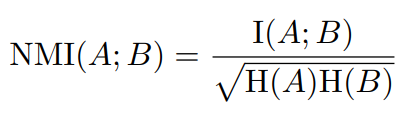 I는 mutual information이고 H는 entropy이다.
I는 mutual information이고 H는 entropy이다.
만약 A와 B가 독립이면 0이고 서로가 완전히 종속적이라 서로를 예측할 수 있으면 1이다.
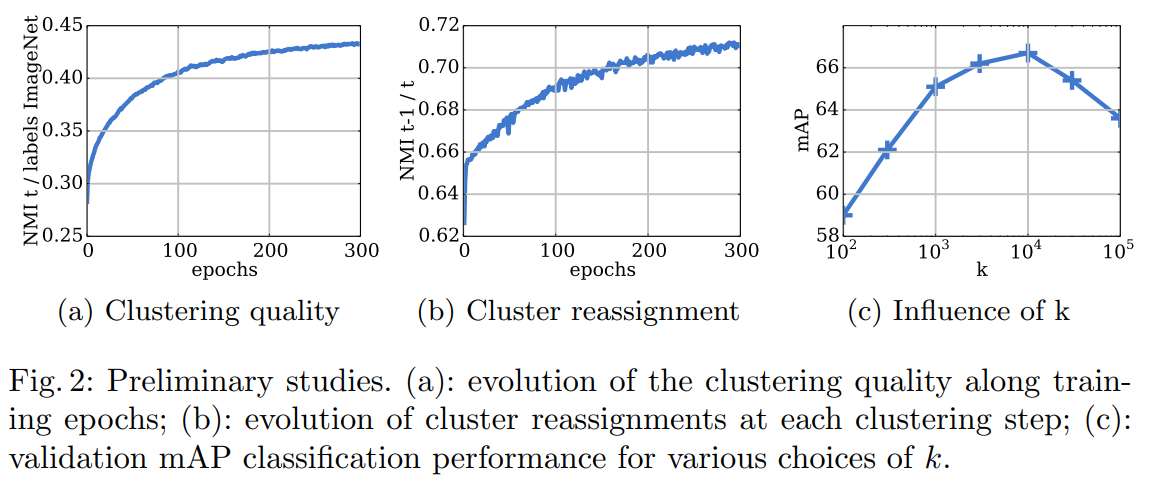 점차 학습이 진행되며 공유하는 정보가 많아짐.
점차 학습이 진행되며 공유하는 정보가 많아짐.
(a)는 cluster assignment와 ImageNet label이다. label에 공유하는 정보가 점차 증가.
(b)는 각 epoch N과 N-1 사이의 정보이다. 갈수록 증가한다.
각 epoch에 cluster를 다시 할당하지만 점차 cluster가 안정화 되고 있다는 것이다.
(c)는 k의 개수에 따른 정확도이다.
기존 이미지넷의 label이 1000이라서 1000이 제일 좋을 것 같았지만 10000이 제일 좋았다.
4.3 Linear classification on activations
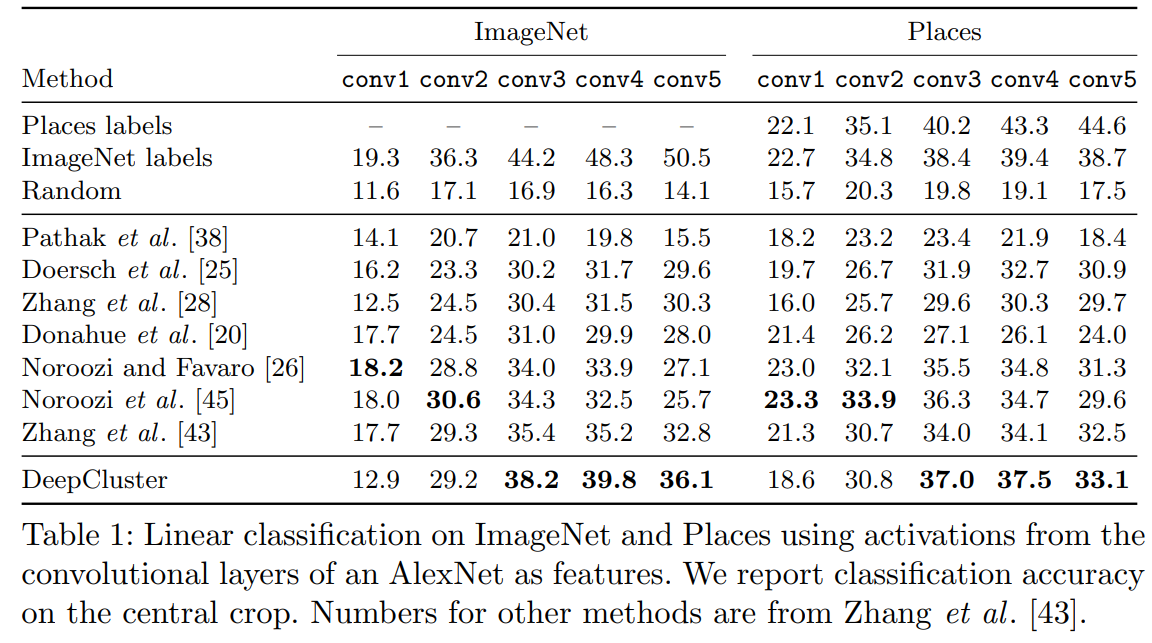
SOTA의 성능을 얻었다.
