A3C 논문이다.
A2C는 (Advantage Actor-Critic)이고
A3C는 (Asynchronous Advantage Actor-Critic)이다.
Abstract
이 논문은 agent를 비동기로 즉 병렬로 훈련하는 방법을 제시하였다.
또한 기존 강화학습 알고리즘을 병렬로 학습하면 더 안정화되는 것을 보여준다.
특이한건 gpu대신 cpu 코어를 병렬로 사용해서 훈련을 진행하였다.
1. Introduction
deep learning과 rl의 조합은 좋은 성능을 보였지만 아직 불안정하다.
안정화 시키기 위한 방법은 여러가지가 제시 되었지만 대부분 공통의 아이디어를 공유한다. online RL-agent가 보는 데이터의 분포가 일정하지 못하고 업데이트 되는 데이터가 correlation을 가진다.
이를 DQN에서는 experience replay memory를 통해서 데이터 배치화와 random sampling을 통해서 해결하였다.
그러나 이러한 학습 방법은 off-policy에서만 가능했다.
또한 experience replay memory는 몇가지 단점이 존재하는데
1. 추가적인 메모리를 사용한다.
2. off-policy algorithm이 필요하다.
이 논문에서는 비동기 병렬 학습 방법을 제시한다.
비동기로 학습이 진행되기 때문에 correlation이 없을 것이고
많은 데이터로 더 안정화시킬 수 있다.
4. Asynchronous RL Framework
multi-thread를 적용한 one-step Sarsa, one-step Q-learning, n-step Q-learning, advantage actor-critic을 소개한다.
이때 여러개의 actor을 동시에 돌리는 것은 환경의 다양한 부분을 동시에 탐사하는 것과 동일하다는 것을 확인했다.
또한 이때 다른 actor 정책을 사용해서 이 환경 탐색의 다양성을 최대화 할 수 있다.
각 thread마다 다른 정책을 돌림으로써 online-param update가 1개의 agent가 online update하는 것보다 less correlated하다.
그렇기 때문에 replay-memory가 필요없다.
이 외에도 추가적인 장점이 존재하는데
1. parallel actor-learner의 숫자가 늘수록 학습 시간이 linear하게 줄어든다.
2. replay-memory에 의존하지 않기 때문에 on-policy 알고리즘에도 사용할 수 있다.(Sarsa, actor-critic 등)
Asynchronous one-step Q-learning
 one-step Q-learning의 코드는 위와 같다.
one-step Q-learning의 코드는 위와 같다.
minibatch를 사용하는 것처럼 gradient를 적용하기 전까지 쌓다가 이후에 한번에 적용한다. 이는 여러개의 learner가 update를 overwrite하는 것을 방지하고 computational cost에도 이점을 준다.
마지막으로 각 thread마다 다른 exploration policy를 적용하는 것이 robustness를 주는 것을 확인.
이때 이 논문은 -greedy를 적용해서 다른 탐색을 가질 수 있게 만들었음.
Asynchronous one-step Sarsa
위의 one-step Q-learning과 동일 그러나 target value가 다르다.
에서 가 max가 아니라 가 에서 고르는 action으로 적용이 된다.
Asynchronous n-step Q-learning
 위와 바뀐점은 여러번 step을 이동해서 history에 저장해두고 나중에 돌아보면서 update를 진행하는 것이다.
위와 바뀐점은 여러번 step을 이동해서 history에 저장해두고 나중에 돌아보면서 update를 진행하는 것이다.
Asynchronous advantage actor-critic
A3C이다.
위의 n-step Q-learning과 비슷하게 forward로 n-step을 계산하고 backward를 진행하는 식으로 policy와 value-function에 동일하게 진행됨.
로 gradient가 계산이되며
advantage 는 로 계산이 된다.
간단하게 action을 하였을 때 얻는 value에서 현재 state에 대한 value를 빼서 action에 대한 순수 value를 구하는 것이다.
 알고리즘은 위와 같다.
알고리즘은 위와 같다.
value-vased가 parallel actor을 사용하고 gradient update를 여러번 중첩했다가 한번에 사용해서 stability를 증가시키는 것처럼
와 가 분리되어있는 것처럼 보이지만 실제로는 일정 부분의 weight를 공유한다.
논문의 저자는 cnn을 기준으로 softmax output을 policy에, linear output을 value function에 사용하였고 나머지 non-output layer를 전부 공유한다고 한다.
policy에 entropy를 추가하는 것이 역시 환경 탐색에 좋았다고 하는데
와 같이 entropy regularization을 더해주는 것이 좋다고 한다.
는 hyper param이다.
Optimization
SGH with momentum, RMSprop(with out shared statistics, with shared statistics) 등 3가지 방법을 사용하였다고 함.
이때 아타리 게임 기준
RMPprop + shared statistics가 더 robust했다고 함.
5. Experiments
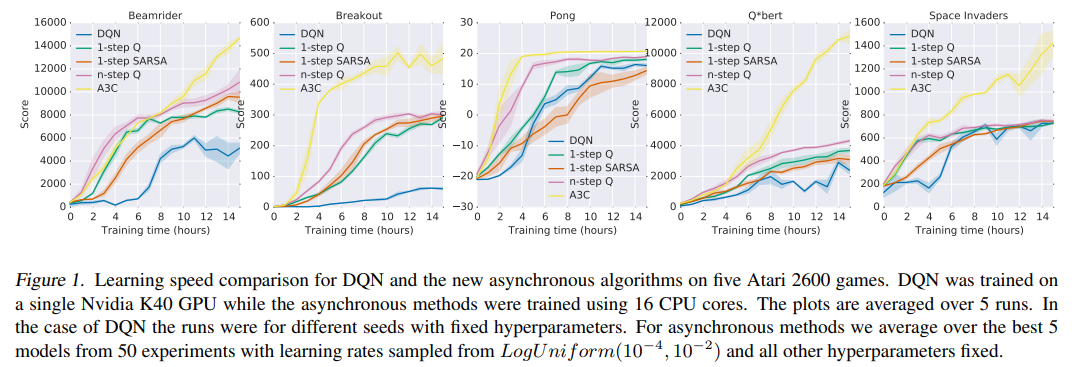 다른 알고리즘들 보다 매우 안정되고 빠르게 score가 증가한다.
다른 알고리즘들 보다 매우 안정되고 빠르게 score가 증가한다.
5.5. Scalability and Data Efficiency
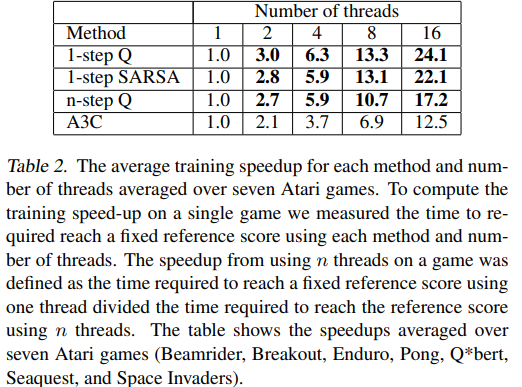 thread의 숫자에 따라 학습의 속도를 측정한 표.
thread의 숫자에 따라 학습의 속도를 측정한 표.
기준은 특정 socre에 얼마나 빨리 도달하느냐에 따라서 측정
task와 알고리즘에 따르면 특정 score에 도달하기 위해서 필요한 step은 일정하다고 함.
결국 이 결과는 동일한 시간에 얼마나 많은 데이터를 빠르게 처리할 수 있었냐의 결과와 exploration이 얼마나 향상되었냐의 차이
놀라운건 Q-learning과 Sarsa는 linear을 넘어선 결과를 보임. 이는 단순하게 computational cost로는 설명할 수 없는 결과.
이는 one-step의 과정에서 multiple thread가 bias를 줄일 수 있기에 나온 결과라고 추측.
5.6. Robustness and Stability
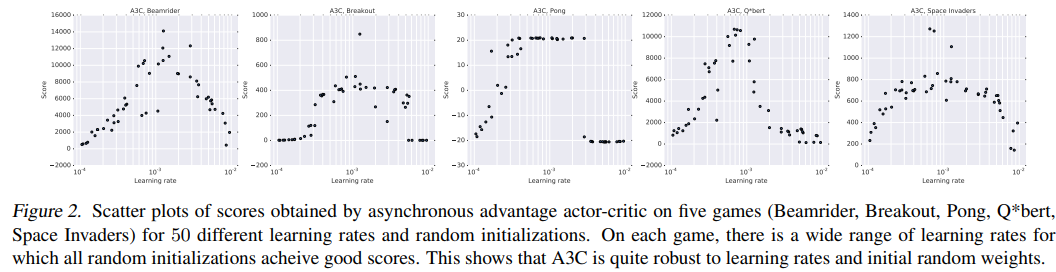 임의의 lr과 random initialization에 대해서 다른 것과 비교해서 상대적으로 강건함.
임의의 lr과 random initialization에 대해서 다른 것과 비교해서 상대적으로 강건함.
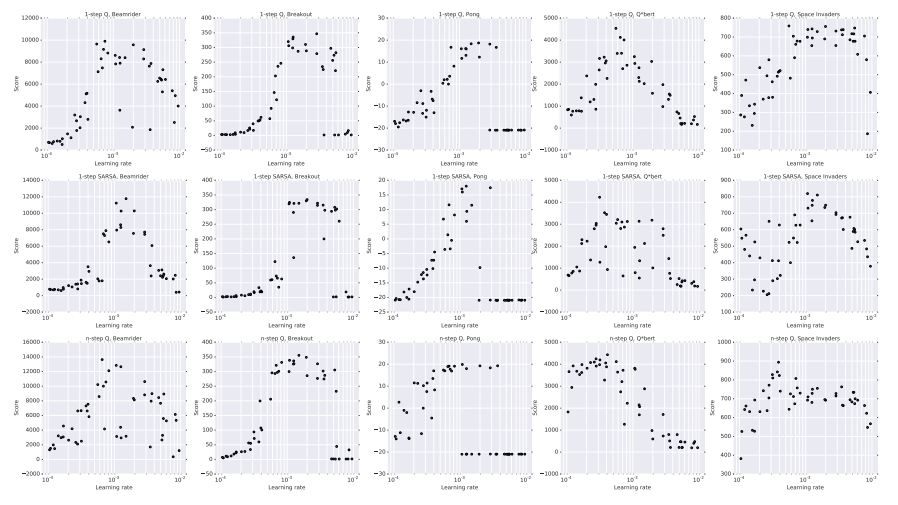 이는 다른 알고리즘의 모습
이는 다른 알고리즘의 모습
y축을 보면 더 잘 비교됨.
