요약
사람이 시각, 청각, 촉각 등의 감각 신호를 통해 머리 속에서 world model을 만드는 것과 유사한 방식을 deep learning에 접목한 논문.
감각 신호를 토대로 future을 예측할 수 있고 이를 활용해 매우 간단한 agent로 좋은 성능을 보일 수 있다.(사람이 무의식적인 반사신경처럼)
그리고 이렇게 만든 world model을 바탕으로 사람이 꿈을 꾸는 것처럼 가상의 환경을 만들어서 학습하고 실제 환경으로 transfer을 할 수 있다.
Abstract
reinforcement learning environment를 구축하는 생성형 neural network를 만드는 것을 탐구하였다.
world model은 environment의 공간적, 시간적 representation을 효과적이고 빠르게 학습할 수 있다.
world model에서 나온 feature을 agent의 input으로 넣음으로써 compact하고 simple한 policy를 구축할 수 있었다.
심지어 agent를 world model이 만든 dream 속에서 훈련할 수도 있다. 그리고 이렇게 훈련한 agent를 다시 실제 environment에 transfer하는 것도 가능하다.
1. Introduction
사람은 각자의 제한된 감각을 바탕으로 세계에 대해서 심리적인 world model을 만들 수 있다. 그리고 사람의 결정과 행동은 이렇게 만들어진 model을 바탕으로 이루어진다.
이때 일상생활 중에서 들어오는 무수히 많은 정보를 처리하기 위해서 우리의 뇌는 추상적인 공간적, 시간적 representation을 학습한다.
실제로 우리는 특정 장면을 목격하고 이를 추상화한 설명을 기억하는 것이 가능하다. 추가로 또다른 증거가 있는데 우리의 뇌는 특정 상황에 대해서 인지한 것을 우리의 뇌의 internal model의 future prediction에 따라서 처리를 한다고 한다.
우리 뇌는 predictive model을 활용해서 내적으로 사전에 미리 예상을 할 수 있고 실제로 위기가 닥쳤을 때 따로 계획을 세울 필요 없이 빠르게 대처할 수 있다.
- 야구선수를 예시로 야구선수는 공이 오는 것을 보고 휘두른다. 이때 배트를 휘두를지 결정하는 시간은 매우 짧다. 밀리초 단위인데 이는 시각 정보가 뇌에 가고 결정을 내리는 시간(0.1초)보다 더욱 짧은 시간이다. 이렇게 빠른 공을 칠 수 있는 이유는 공이 어디로 갈지 예상할 수 있는 능력 덕분이다.
결국 의식적은 인지 없이 뇌가 무의식적으로 미래를 예상하는 것이다.
많은 강화학습 문제 중에서 artificial agent는 과거와 현재의 상태에 대한 좋은 representation과 RNN등을 활용한 미래에 대한 좋은 예상 모델로부터 이익을 얻을 수 있다.
매우 큰 RNN 모델이 더 좋은 표현을 학습할 수 있고 더 좋겠지만 실제로 기존의 논문들은 작은 network를 사용하였다. 왜냐하면 RL 알고리즘은 credit assignment 문제가 발생하는데 (이는 어떤 행동이 궁극적으로 보상에 얼마나 기여했는지 정확히 결정하는 것이다.) 이에 따라서 전통적인 RL 알고리즘은 대용량의 weight를 학습하기 어렵다. 실제로 작은 network를 사용하는게 더 빠르게 좋은 policy로 수렴한다.
이 논문은 large neural network를 활용하는데
이를 나눠서 학습한다. 큰 world model과 작은 controller model로 나눈다.
큰 world model을 학습해서 environment를 unsupervised learning으로 학습하고 작은 controller model을 학습해서 어떻게 행동을 고를지 학습한다.
2. Agent Model
간단하게 보는 것을 작은 representation으로 축소하고 이렇게 만들어진 과거 정보를 활용해서 memory component(RNN)이 예측한다. 이후 agent가 decision을 만든다.
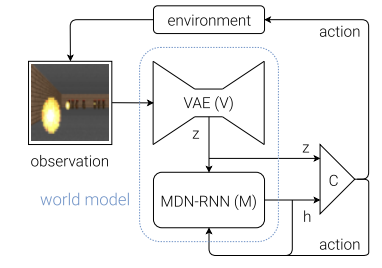
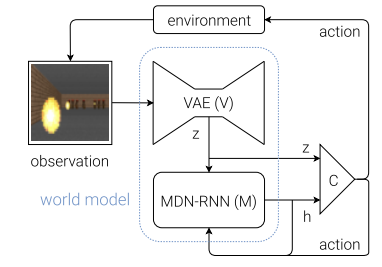 전체 구조는 위와 같다.
전체 구조는 위와 같다.
2.1. VAE (V) Model
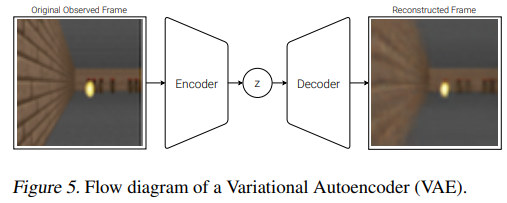
앞서 언급했다시피 high dim 이미지를 작은 vetor representation으로 축소하는 과정이다.
V의 목적은 compressed representation을 학습하는 것이다.
간단하게 varitional autoencoder를 활용했다고 한다.
2.2. MDN-RNN (M) Model
시간에 따라서 무슨 일이 일어났는지를 저장하는 memory이다.
가 만드는 현재 상태를 바탕으로 가능한 미래 를 예측한다.
대부분의 환경이 확률적이기 때문에 를 결정하기 보다는 확률 함수 를 만들도록 학습하였다.
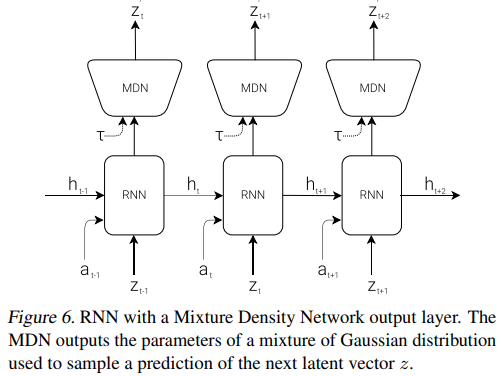 위 그림에서 MDN이 가 가질 수 있는 가우시안 분포를 예측한다.
위 그림에서 MDN이 가 가질 수 있는 가우시안 분포를 예측한다.
RNN이 다음 latent vector 의 분포 확률을 잘 예측하도록 학습한다.
정확하게는 RNN은 를 구성한다.
2.3. Controller (C) Model
environment로부터 누적 보상을 최대화 하기 위한 선택을 하는 모델이다.
이전에 VAE가 사람의 눈, RNN이 기억이라면 controller는 선택하는 뇌이다.
실제 논문에서는 C를 V와 M에 비해 매우 작게 구현해서 대부분의 complexity는 V와 M에 있다.
C는 single linear layer로 구성이 되어있어서 와 를 action 로 매핑한다.
이때 는 concat되어있다.
2.4. Putting V, M, and C Together
앞에서 봤던 그림이다.
아래는 pseudo code이다.

C에 최소한의 weight를 넣은 것은 중요한 이점을 준다. 최신 deep learning 방법론이 발달하면서 더 많고 큰 모델의 학습이 가능해졌지만 병렬 학습이 가능한 cnn, rnn 기반 V와 M에 대부분의 복잡도를 밀어넣고 C에는 적은 weight만 할당 함으로써 빠르게 학습이 가능할 뿐만 아니라
중요한건 과거의 단순한 구조에서 사용하던 진화 방법 등의 RL 알고리즘을 적용할 수 있다.
실제로 C를 학습하기 위해서 CovarianceMatrix Adaptation Evolution Strategy (CMA-ES)의 방법을 골랐다.
이는 수천개의 param으로 이루어진 solution space에서 잘 작동하기 때문이다.
1개의 machine에서 여러개의 cpu core를 활용해서 병렬적으로 학습하였다.
3. Car Racing Experiment
이제 실험 부분이다.
3.1. World Model for Feature Extraction
environment는 "CarRacing-v0"이다.
 이 환경에서 track은 random으로 생성되고 agent는 주어진 시간 내에 최대한 많은 타일을 visit하는 것이 reward이다.
이 환경에서 track은 random으로 생성되고 agent는 주어진 시간 내에 최대한 많은 타일을 visit하는 것이 reward이다.
agent의 control은 왼쪽,오른쪽 바퀴 조작, accel, brake이다.
V를 학습하기 위해서 environment에서 10000개의 data를 랜덤으로 rollout 하였고 agent가 environment를 random하게 explore하게 하였으며 action 와 result observation을 기록하였다.
이후 VAE를 통해 원본과 복구한 이미지를 유사하게 만드는 방식으로 학습함으로 representation을 학습하였다.
이렇게 학습한 V모델을 활용해서 t시간의 이미지를 로 바꿀 수 있고 이를 활용해서 MDN-RNN 모델을 학습할 수 있다.
위에서 저장한 와 만든 를 활용해서 RNN을 학습한다.
를 mixture of Gaussian으로 학습한다.
이 실험에서 world model은 environment의 reward에 대한 지식이 하나도 없다.
오직 Controller model C만 정보를 가지고 있다.
이때 C에는 867개의 param만 존재하기 때문에 CMA-ES와 같은 알고리즘이 매우 적합했다고 한다.
3.2. Procedure
위 내용의 요약이다.
1. random policy를 활용해서 10000개의 rollout을 진행한다.\
2. VAE를 학습한다
3. MDN-RNN을 학습한다.
4. Controller를 정의한다.
5. CMA-ES로 와 를 학습한다.
이때 param은 대부분 V와 M에 있다.
3.3. Experiment Results
V Model Only
운전을 잘 하도록 하는 것은 observation에 대해서 좋은 representation만 있으면 어려운 문제가 아니다.(LIDAR 장비로 얻은 좋은 정보를 가지고 학습한 모델은 매우 쉽게 학습하여 잘 작동 하였다고 함.)
이러한 점에서 착안해서 C가 V에만 access할 수 있게 하고 로 구성해서 실험을 진행.
이 실험 결과로
agent는 여전히 운전을 할 수 있었지만 운전이 흔들리고 트랙을 벗어나는 등 불안정 했다고 한다.
실제 스코어가 이었다고 한다.
이는 다른 A3C와 같은 방식과 비슷했다고 한다.
C에 hidden layer를 넣으면 로 상당히 증가를 하긴 하지만 environment를 solve하기에 즉 최고점을 달성하기에는 부족했다고 한다.
Full World Model (V and M)
representation은 predictive power이 없고 그 순간만 담는 것을 알게 되었다.
미래에 대한 예측 이 시간 에서 에 의해서 나온 다는 것은 가 agent에 주기 좋은 feature이라는 것이다.
와 를 주는 것은 현재에 대한 정보와 미래에 대한 정보를 주는 것이다.
이렇게 모든 정보를 주었을 때 주행은 안정적이고 코너 역시 매우 효과적으로 돌았다.
이때 중요한 것은 미래를 plan ahead와 rollout 등으로 미리 계획할 필요 없이 RNN을 통해서 미래를 알 수 있기 때문에 야구선수가 반사적으로 공을 치는 것처럼 매루 빠른 의사결정이 가능하다.
 매우 높은 성적을 받은 모습니다.
매우 높은 성적을 받은 모습니다.
또한 이전의 Deep RL모델의 경우 frame의 pre-processing이 필요한 경우도 있었지만 world model에서는 그냥 RGB input을 그대로 사용하였다.
3.4. Car Racing Dreams
이 부분이 되게 신기한데
world model은 미래를 model할 수 있기에 실제 environment가 아닌 이적인 car racing scenario를 만들 수 있다.
우리는 현재 상태에서 MDN-RNN을 바탕으로 을 만들어낼 수 있다.
이렇게 만들어낸 을 실제 상황으로 보고 다음 input으로 넣는다.
위와 같은 방법으로 말 그대로 꿈같은 car racing을 진행할 수 있으며 학습한 C 모델을 환각 환경에서 적용해서 test를 진행하고 학습할 수 있다.
 말 그대로 꿈을 꾸는 것이다.
말 그대로 꿈을 꾸는 것이다.
4. VizDoom Experiment
4.1. Learning Inside of a Dream
위에서 우리는 실제 환경에서 학습한 agent가 dream에서도 잘 작동하는 것을 보았다.
그러면 반대도 가능할까?(꿈에서 학습하고 실제 상황에 적용)
만약 월드 모델이 충분히 정확하다면 실제 환경을 대체할 수 있을 것이다.
결국 agent는 실제 환경을 보는 것이 아니라 world model이 보여주는 것을 보게 된다.
이를 VizDoom에서 실험을 하였다.
이 게임에서 agent는 monster가 쏘는 총알을 피해야 한다.
이 게임은 또한 explicit한 reward가 없다. 결국 자연선택을 모방해서 cumulative reward는 rollout 동안 생존할 수 있는 time step으로 정의될 수 있다.
각 rollout은 최대 2100 step으로 진행이 되며 평균 생존시간이 750 이상일 경우 문제가 해결되었다고 본다.
4.2. Procedure
설정은 car racing과 거의 비슷하지만 몇가지가 다르다.
여기에서는 agent를 훈련할 수 있는 environment를 구축하고 싶기 때문에 다음 frame 를 예측할 뿐만 아니라 죽을지 말지도 예측을 한다.
이는 또는 로 정의하고 binary로 표현이 된다.
M model이 next observation과 done state도 prediction할 수 있기 때문에 RL을 학습할 수 있는 모든 상황을 갖추었다.
M을 Gym environment와 같이 활용해서 모델을 학습하였다.
이 상황에서는 V가 필요 없다. real pixel을 압축할 필요가 없기 때문.
이렇게 학습한 agent를 real environment로 transfer하기는 매우 쉽다. 동일한 구조이기 때문.
이 내용을 요약하면 다음과 같다.
1. random policy로 10000 rollout을 진행한다.
2. VAE를 학습한다. 로 압축하게 된다.
3. MDN-RNN을 학습한다.
4. controller C를 정의한다.
5. CMA-ES를 사용해서 를 학습한다.
6. 실제 환경에서 이렇게 학습된 모델을 사용한다.
4.3. Training Inside of the Dream
이렇게 dream에서 학습된 모델은 dream 안에서 900 정도의 점수를 받았다.
여기에서 신기한 점은 RNN-based의 world model은 raw image data로부터 game environment를 mimic하게 학습이 된다. 이때 그냥 이미지 만으로 game의 중요한 요소들을 시뮬레이션할 수 있다.
game logic, 적의 행동, physics, 3D rendering 등등.
실제 최신 논문 중에서는 diffusion model을 게임 엔진으로 사용한 논문도 있다.
GameNGen
M 모델에서 만약 agent가 왼쪽으로 움직이게 action을 고르면 M모덱 역시 left로 움직이도록 representation을 바꾼다.
또한 벽이 있으면 더이상 가지 못하게 한다.
그리고 monster가 여러개의 fireball을 날리면 이를 추적하는 것도 가능하다.
그러나 현실과는 다른 부분은 가상 환경은 uncertatinty를 추가해서 게임을 더 어렵게 만드는 것이 가능하다. 을 샘플링하는 과정에서 tempereture 를 증가해서 불확실성을 늘릴 수 있다. fire ball이 랜덤하게 움직이거나 아무런 이유가 없이 agent가 죽을 수도 있다.
이렇게 어렵게 학습한 agent가 실제 환경에서 더욱 잘 작동한다고 한다.
4.4. Transfer Policy to Actual Environment
이렇게 학습한 모델을 실제 환경에 넣으면 1100step까지 생존하였는데 이는 게임클리어 점수는 750을 많이 넘은 모습이다.
또한 이는 virtual environment에서 얻은 점수보다 더 높은 점수였다.(4.3에 따르면 virtual은 900점)
심지어 V 모델은 frame의 정보를 정확하게 담는 것이 힘들었음에도(몬스터의 수 등) 불구하고 agent는 좋은 policy를 학습할 수 있었다.
4.5. Cheating the World Model
어릴때 우리는 게임에서 버그? 같은 방법으로 의도되지 않은 다양한 이점을 얻을 수 있었다.(추가 체력, 벽 뚫기 등등) 이러한 방법으로 어려운 게임을 쉽게 클리어할 수 있었는데 그러나 이렇게 함으로써 개발자가 의도한 게임을 마스터하는 기회를 잃을 수도 있다.
self-supervised leanrning에서 따지면 short cut에 대한 이야기이다.
예를 들어서 이전에 진행된 실험에서 agent가 특정 방향으로 움직이면 virtual environment의 monster들은 fireball을 발사하지 않았다고 한다.
심지어 fireball이 생성되고 있어도 특정 움직임을 하면 fireball이 사라졌다고 한다.
왜냐하면 우리의 world model은 실제 환경의 확률적 근사 모델에 불과하기 때문이다.
실제로 이전에 봤다시피 몬스터의 숫자가 정확하게 묘사되지 않았다.
여기에서 논문의 표현이 되게 웃긴데
공중의 물체가 떨어지는 것을 배운 아이가 자신이 슈퍼히어로가 되어 하늘을 가르며 날아가는 것을 상상하는 것처럼. 상상한다.
이러한 방식으로 world model에서 실제 현실에서 발생하지 않는 것을 agent가 이끌어내서 사용할 수 있다.
그리고 우리는 agent에 hidden state도 주는데 이는 agent가 기존 player처럼 눈으로 게임을 보는 것이 아니라, 게임 내부의 메모리, 상태 등의 정보를 알 수 있음을 이야기한다.
이에 따라서 누적 보상을 최대화 하기 위해서 hidden state를 어떻게 조작할지를 배우게 될 수 있다.
이러한 약점은 adversarial policy를 찾기 쉽게 만들어준다. 결국 dream 내에서는 잘 작동하지만 실제 상황에서는 잘 작동하지 않는 policy를 학습할 수 있다.
결국 이에 따라서 이전의 다양한 dynamic model environment 연구에서도 실제 environment를 100% 대체하지 못했던 것이다. 왜냐하면 100%가 아니라 조금이라도 문제가 생긴다면 agent가 악용할 여지가 생기기 때문이다.
이때 결정론적 모델은 (동일한 input에 동일한 output을 내는) 조금이라도 잘못되면 바로 고장이 나고 악용이 될 수 있지만 PILCO와 같은 bayesian model의 경우 불확실성 추정을 통해 예측 신뢰도를 높이고 불확실성을 고려하도록 하였다. 하지만 완벽하지 않은 예측을 완전히 해결하지 못하였다.
learning to think 논문에서는 RNN M이 항상 믿을만한 predictor가 아니어도 괜찮다고 한다. 진화 기반의 RNN C는 오류가 있는 M을 무시하거나 중요한 부분만 추출할 수 있다고 한다. - 그러나 이거는 이 논문에서 사용된 방법은 아니다.
이 논문에서 사용된 방법은 step by step으로 상황을 생성하는 옛날 것에 더 가깝고 RL과 RNN을 결합하는 대신 learning to think와 같이 단순한 C에 진화를 통합해서 단순성과 일반성을 모두 갖추었다.
C모델이 M 모델의 불확실성을 악용하는 것을 막기 위해서
위의 베이지안 모델의 방법과 같이 결정론적으로 예측하는 것이 아니라 MDN-RNN을 바탕으로 실제 환경의 가능한 분포를 예측 함으로써 1차로 방지를 하였다. 그냥 를 조절해서 randomness를 조절하면 된다.
또한 혼합 밀도 모델은 여러개의 가우시안 분포를 활용해서 VAE로 압축하기 힘든 확률적인 상황(fire ball을 발사 등)을 모델할 수 있다.
예를 들어 를 0.1로 설정하면 M을 사실상 결정론적 모델과 동일하게 만들 수 있고 이를 통해서 C를 학습할 수 있는데 이는 M의 Mode collapse를 일으키게 만든다.
모드 붕괴는 혼합 가우시안 모델이 특정 모드에만 집중하게 되는 현상.
fireball을 발사하지 않는 상황에서만 머무르게 됨.
결국 virtual 상황에서는 최고점을 기록하지만 실제에서는 처참하다.
아래는 를 조절하였을 때의 점수분포이다.
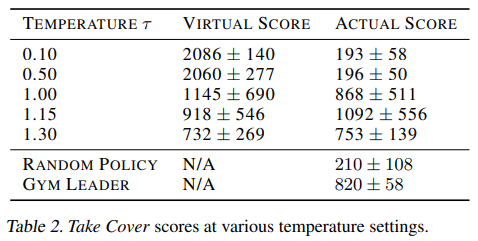
를 적절하게 높게 줘서 virtual을 적절히 어렵게 만드는 것이 실제 게임의 점수를 올리는 것에 많은 영향을 주었다.
5. Iterative Training Procedure
위 실험에서는 task가 비교적 간단해서 world model이 random policy로 얻은 데이터 만으로도 좋은 성능을 낼 수 있었다.
그러나 environment가 더 복잡하다면?
어떤 복잡한 환경은 agent가 학습을 마친 후에도 world의 일정 부분만 탐색을 마칠수도 있다.
그렇기 때문에 더 복잡한 task의 경우 반복적인 학습 과정이 필요하다.
우리는 agent가 world를 탐색할수 있게 만들고 지속적으로 새로운 observation을 학습할 수 있게 만들어야 한다.
결국 과정은 다음과 같다.
1. M, C를 랜덤하게 초기화 한다.
2. actual environment에 N번 rollout을 한다. 모든 action 와 observation 를 저장한다.
3. M을 를 학습한다. 그리고 C를 M 내부의 reward를 가지고 optimize한다.
4. 만약 task가 끝나지 않았으면 (2)로 가서 반복.
간단한 task는 1번만으로도 충분하지만 어려우면 여러번 반복해야 한다.
또한 여기에서 간단한 trick이 있는데
우리는 M이 MDN-RNN으로 구성을 하였다. 여기에서 next frame의 probability distribution을 model하는데 만약 이게 잘 작동하지 않는다면 agent는 새로운 부분을 마주했다는 것이다.
이러한 상황에서 MDN-RNN의 loss를 재사용해서 curiosity로 활용할 수 있다.
이제 agent는 MDN-RNN의 loss가 크면 새로운 environment를 마주했다는 것으로 인지하고 더 상세히 탐색하도록 만들 수 있다. 그럼 새로운 데이터를 모을 수 있다.
이때 M모델이 와 을 예측할 뿐만 아니라 reward와 action까지 예측해야하는데 이는 어려운 task를 수행하기 위해서 필요하다.
예를 들어 만약 agent가 환경을 걷기 위해서 복잡한 motor skill이 필요하다면 world model은 C모델이 이미 학습한 걷는 방법을 학습할 수 있을 것이다.
대용량의 world model은 C 모델의 복잡한 걷는 방법을 흡수할 수 있고 이에 따라서 작은 C모델은 world model에 흡수된 motor skill에 의존해 다양한 탐색을 진행할 수 있다.
말이 좀 어려운데 쉽게 설명하자면
실제 현실에서 걷기는 방법을 학습하는 것은 매우 어렵다.
발을 어떻게 들고 어떻게 각도를 조절하고 다리를 박차고 걷는다...
이를 agent C모델이 우선 조금씩 학습을 하면 이를 world model이 흡수를 할 수 있다.
이는 memory M으로 action과 를 바탕으로 예측하는 능력을 바탕으로 흡수하는 것 같다.
이에 따라서 C모델은 더이상 걷기를 학습할 필요가 없다. 왜냐하면 M모델이 걷는 방법을 흡수해서 가지고 있기 때문이다. 그렇기 때문에 C모델은 걷는 것을 학습하는 것이 아니라 어떻게 world를 탐색할지만 학습하면 된다.이 내용이 되게 재밌는데 실제 사람도 똑같다. 어릴때에는 걷는 방법을 직접 배우지만 다 큰 성인이 되면 걷는 방법은 더이상 의식적으로 생각하지 않고 무의식적으로 걷는다.
신경과학과의 재밌는 연결성에 대해서 hippocampal replay가 있다고 한다.
이는 동물이 쉬거나 잠잘 때 어떻게 뇌가 최근 경험을 반복재생을 하는지 조사한 내용인데 최근 연구는 이러한 반복 재생은 뇌가 기억을 통합하는데에 중요한 역할을 한다고 한다.(해마에 의존적인 기억이 해마와 독립적으로 되는 과정이라고 한다.)
어떤 연구는 이러한 기억 재생이 꿈 보다는 생각에 더 가깝다고 한다.
그리고 논문의 저자는 이러한 기억과 강화학습의 연관성을 다룬 Replay Comes of Age라는 논문을 읽어보기를 권장한다.