추후 작성예정
Abstract
최근의 contrastive leanring은 빠르게 supervised와 비슷할 정도로 성장을 하였지만.
이러한 방법은 많은 양의 feature 쌍 비교가 필요하고 이는 너무 비싸다.
이 논문은 SwAV알고리즘을 제시하는데 이는 compare가 필요 없는 학습 알고리즘이다.
이 알고리즘은 데이터를 클러스터링 하는데 이때 같은 데이터에 대해서 다른 view를 만든 데이터를 비슷한 클러스터에 할당하기 때문에 비교가 필요없다.
또한 swapped prediction 방법을 제시하는데
이는 code of the view를 다른 view의 representation으로부터 예측한다.
또한 새로운 augmentation multi-crop을 제시한다.
1 Introduction
최근 vision분야의 self-supervised learning의 SOTA는 contrastive leanring이다.
이는 다음 2가지로 구성된다.
1. contrastive loss(infoNCE 등).
2. set of image transformations.
contrastive loss는 이미지의 parir들을 비교하고 동일한 이미지의 trasnform은 가깝게 만들고 다른 이미지를 밀어낸다.
그러나 모든 pair를 비교하기에는 computational cost가 너무 비싸다.
이에 따른 대안은 task를 근사하는것이다.
대표적인 것은 clustering-base task로 이미지 각각을 차이로 보는 것이 아니라 이미지의 그룹들을 구분하는 것이다. 즉 비슷한 이미지들이 모인 cluster의 차이를 보는 것.
그러나 데이터셋 전부를 모아서 클러스터를 만들어야 하기 때문에(이전에 리뷰한 deep cluster) 데이터셋이 커지면 클러스터(code)를 재구축 할 때마다 너무 많은 비용이 소모된다.
이 논문은 이러한 code를 online하게 다른 view 들의 code 사이의 일관성을 유지하는 방법을 제시한다.
cluster의 assignment를 비교하는 것은 explicit한 pair비교를 요구하지 않는다.
특히 이 논문에서는 swapped prediction의 문제로 만들었는데 이는 하나의 code of the view에서 다른 view의 representation을 예측한다.
추가로 이 논문에서는 image transformation의 방법을 제시하는데
이는 Multi-crop이다.
이를 통해서 memory나 computational을 요구하지 않고 다양한 뷰를 구성할 수 있다.
이때 저자들은 신기한것을 발견하였는데 small-part of the view를 global한 이미지에 매핑하는 것은 큰 성능의 향상을 이끌어 낸다고 한다.
이미지의 작은 부분과 직접적으로 작용하는 것은 feature의 bias를 더 강하게 넣을 수 있기 때문에 이를 다른 size의 mix를 사용함으로써 피한다고 한다.
이러한 방법으로 SOTA의 성능을 얻었다고 한다.
3 Method
self-supervised한 online clustering 방법이 메인이다.
이전의 offline clustering 방법은 2개의 개별 step이 필요하였는데
- cluster assignment step with entire dataset
- training step with cluster assignment(code)를 예측하는 작업
이 논문의 online clustering은 code가 target이 아닌 동일한 이미지의 view들 사이의 일관성을 강화하기 때문에 contrastive instance learning에서 영감을 받았다고 한다.
위에서 contrastive instance learning의 영감을 준 논문은 Unsupervised Feature Learning via Non-Parametric Instance Discrimination이 논문인데
특이한 논문이라서 조금 더 작성한다.
이 논문의 대강 구조는 supervisd로 학습된 데이터는 각각의 label에 따라서 무엇이 정답인지만 예측을 하는데 실제 예측한 결과를 보면 사람과 같이 되게 비슷한 내용을 비슷하게 예측한다.
레오파드 그림을 보고 재규어와 비슷하게 예측. 이는 사람이 보기엔 당연하지만 0과 1로 label만 보고 학습한 CNN 구조에서 얻을 수 있는 결과로 보기엔 이상하다.
이 논문은 이렇게 인공지능이 모델의 유사성을 학습할 수 있다고 보고 결과를 이용해서 같은 종류의 이미지는 서로 유사성을 학습하고 다른 종류의 이미지는 구별하는 시도를 한다.
이 논문은 contrast를 각 view를 이미지 feature로 비교하는 것이 아니라 cluster assignment로 진행하는 것으로 볼 수 있다.
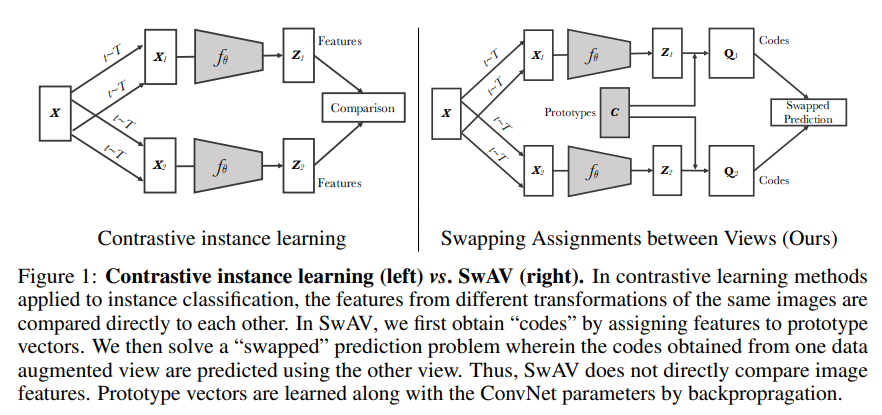 구조는 위와 같은데
구조는 위와 같은데
이미지의 feature 를 가지고 각 code 즉 assignment를 계산해서 를 만든다.
이후 다른 이미지의 feature 을 가지고 을 예측한다. 이를 에도 동일하게 하면 loss는 다음과 같다.
.
은 feature과 code 사이의 유사성을 측정하는 함수이다.
직관적으로 code과 representation이 동일한 정보를 담고 있다면 이를 토대로 예측을 할 수 있다는 것을 의미한다.
3.1 Online clustering
이전의 contrastive와 비슷한 구조인데 code를 구성하는 방법은
개의 학습 가능한 prototype vector 를 가지고 code를 계산한다.
code를 계산하는 방법은 feature과 각각의 prototype vector들의 유사도를 전부 계산해서 그 유사도를 가지고 label을 만든 vector가 code이다.
이때 가장 가까운 것이 label 1이고 나머지는 0이다.
Swapped prediction problem.
앞서 설명했던 .는 feature 로부터 code 를 예측하는 task로 볼 수 있다.
각각의 loss는 cross entropy loss이며 다음과 같다.
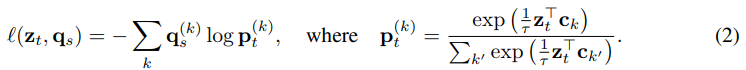 예측 는 representation 가 어느 prototype과 가장 가까운지를 나타내는 것이다. 이때 는 k번째 prototype과 가까울 확률이다. 이렇게 cross-entropy loss로 학습을 진행한다.
예측 는 representation 가 어느 prototype과 가장 가까운지를 나타내는 것이다. 이때 는 k번째 prototype과 가까울 확률이다. 이렇게 cross-entropy loss로 학습을 진행한다.
N개의 data에서 의 transform pool에서 가지고 뽑아낸 transform을 가지고 구성한 전체 loss는 다음과 같다. 여기에서 는 temperature이다.
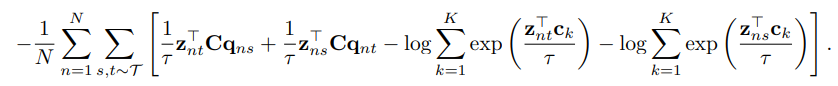 이 식은 간단하게 위 loss에서 P에 오른쪽 식을 넣으면 바로 나온다.(여기에서 오른쪽의 -log 식은 위 식의 분자이고 왼쪽은 분모이다. label p가 1인 부분이 있기에 저렇게 적용이 된다.)
이 식은 간단하게 위 loss에서 P에 오른쪽 식을 넣으면 바로 나온다.(여기에서 오른쪽의 -log 식은 위 식의 분자이고 왼쪽은 분모이다. label p가 1인 부분이 있기에 저렇게 적용이 된다.)
이는 와 에 의해서 최소화 된다.
Computing codes online
online으로 만들기 위해서는 code는 batch에 있는 이미지 만으로 계산을 해야한다.
이때 code를 prototype 로 계산할 때 batch 안의 모든 sample은 prototype에 의해서 똑같이 나뉘어져야 한다. 이는 배치 안의 이미지가 다른 코드를 가짐을 보장하며 한쪽으로 몰리는 trivial solution을 방지한다.
batch 의 feature 가 주어졌을 때 이를 prototype 로 매핑해서 코드 와 비슷하게 만들어야 한다.
이를 활용해서 feature과 code의 similarity를 maximize한다.
이를 수식으로 표현하면 아래와 같다.
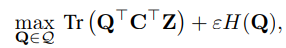 여기 수식에서 Tr은 trace를 의미한다고 한다.
여기 수식에서 Tr은 trace를 의미한다고 한다.
Trace는 행렬의 대각선 들의 합을 나타낸다고 한다.
또한 는 entropy function으로 라고 한다.
은 hyper param으로 생각된다.
엔트로피가 커지기 위해서는 확률이 균등하게 분포가 되어야 하기 때문에 matrix를 골고루 뿌려주게 된다.
이를 통해서 mapping의 smooth함을 조절한다.
너무 entropy가 강하면 즉, high 이면 모든 샘플이 유니크한 representation을 가지게 되고 uniform하게 모든 prototype에 할당되게 된다. trivial solution으로 간다.
이전에 말했던 matrix 를 equal partition으로 제한하기 위해서는 를 transportation polytope에 속하게 해야한다고 한다.
transportation polytope problem
이는 이 블로그 글에 자세히 설명이 되어있는데
공장이 A,B에서 300개 700개의 빵을 생산하고 학교 X, Y, Z에서 각각 100, 500, 100개를 수급할 때 운송 cost를 가장 적게 하면서 수급이 가능하게 하는 문제가 transportation polytope라고 한다.
이를 원래는 full-dataset에 사용이 되는데 이를 mini-batch로 제한한 form은 아래와 같다.
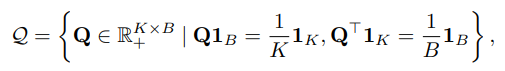
위 식은 code 가
추후 작성예정
