1. Introduction
-
visual recgnition은 이제 feature engineering이 아니라 network engineering이 되어가고 있다.
architecture design은 갈수록 hyper parameter이 많아져서 매우 어려워지고 있는데 VGGnet과 ResNet에서 같은 block을 쌓아서 만드는 네트워크가 등장해서 hyper param의 선택지가 줄어들게 되었고 깊이는 매우 중요한 요소가 되었다.
이러한 block을 쌓는 방법은 모델을 robust하게 만들어서 안정적인 결과를 내게 만들어주었다. -
반면에 inception model은 split-transform-merge의 형태로 진행을 한다.
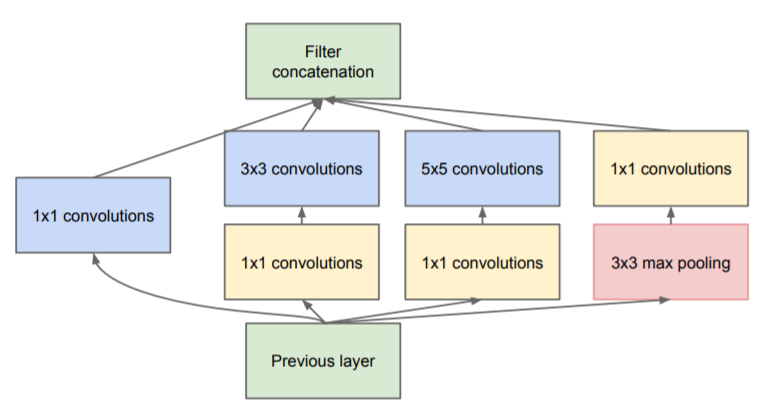
이런 구조에서 입력은 1x1 conv layer를 통해 dim이 감소하게 되고 split되게 된다. 그리고 3x3, 5x5 등의 layer를 통해 transform이 이루어지고 concat을 통해 합쳐지는 구조이다. -
그러나 이런 inception 구조는 매우 까다롭다. 필터의 개수, 사이즈가 각각의 transformation에서 stage-by-stage로 정리가 되어야 하고 정리를 한다고 해도 새로운 데이터셋/작업에 적용하기가 힘들다.
-
결국 이 논문에서는 ResNet, VGGnet 등에서 채택한 같은 block을 쌓는 구조와 inception model에서 채택한 split-transform-merge 구조를 함께 적용을 하고 resnet에서 적용한 skip connection도 적용을 하였다.
-
이러한 구조로 비슷한 param과 computation으로 더 나은 정확도에 도달할 수 있었다.
3. Method
3.1 Template
VGGnet, ResNet과 비슷하게 block을 쌓는 구조인데 블럭들은 같은 위상을 가진다.
그리고 2가지의 특성을 가지는데
- 같은 공간 구조를 제공하는 블럭들은 같은 hyper param을 가진다. (width, filter size 등)
- block의 spatial map이 절반으로 down sampling이 된다면 block의 width도 2배로 증가한다. -> feature size가 감소하면 channel의 증가
이러한 규칙을 통해 Template module만 만들면 된다.
3.2 Revisiting Simple Neurons
기존의 간단한 뉴런은 다음과 같은 구조이다.
간단하게 x를 weight와 곱하고 더하는 구조이다.
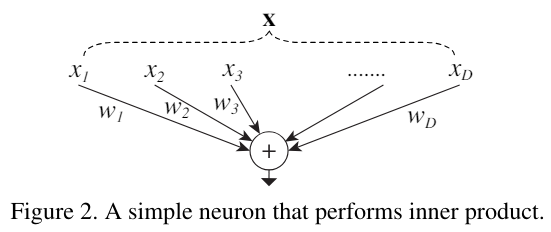
그러나 이 구조도 split-transform-merge의 구조로 나타낼 수 있는데 위 그림과 같다.
vector X를 각각 요소로 나눈(split) 다음 weight를 곱하고(transform) 더하는(merge) 구조이다.
3.3 Aggregated Transformations
-
simple neuron에서 xi*wi와 같이 transformation을 하는 대신에 일반적인 함수를 통해 진행을 한다. 수식은 다음과 같다.
-
수식에서 는 bottleneck 구조를 채택해서 low dim embedding으로 변환하고 transform을 진행하는 부분이고 C는 caridinality의 크기를 뜻하며 transformation set의 크기를 뜻한다.
-
원래 기존의 width(한 layer의 크기)의 크기는 inner product의 크기를 나타냈지만 cardinality는 complex transformation의 수를 나타낸다.
실제 aggregated transformation에서는 skip connection을 추가해서 다음과 같이 표현이 된다.
이 수식은 다음 그림과 같이 구현이 된다.
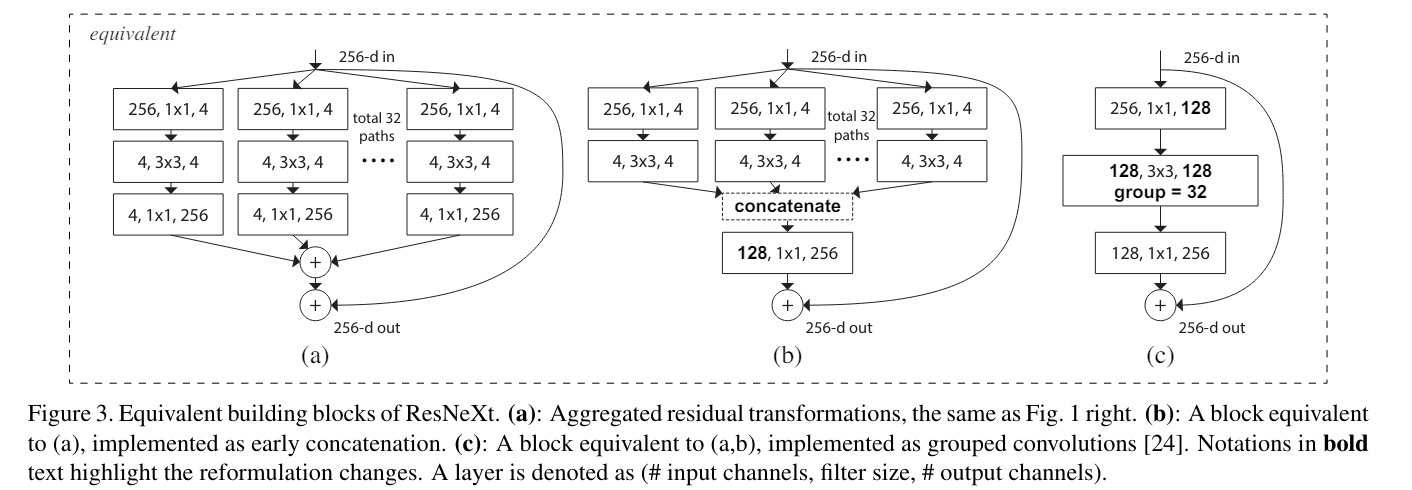
(a)는 수식을 그대로 작성한 것이고
(b)는 (a)를 수정해서 concate하는 방식으로 변경한 것이다. (a)와 동일하다.
(c)는 group convolution을 적용한 것이다. 연산은 (b)와 동일하며 매우 간단하게 표현이 가능하다.
group convolution을 간단하게 설명하자면 input channel을 group으로 나누어서 각각 group에 대해서 연산을 진행하고 다시 합치는 방법이다.
추가로
(a), (b)이 두 레이어가 동일한 이유는
A1B1+A2B2=[A1,A2][B1;B2] (여기에서 ,은 수평 ;은 수직)의 매트릭스 곱과 동일한데
우선 (a)에서 C=2라고 가정하고 Ai를 last layer 즉 위 그림에서 4, 1x1, 256 layer의 weight 라고 정의하고 Bi를 두번째 layer 즉 4, 3x3, 4의 output 이라고 정의하면 최종 나가는 output은 A1B1+A2B2이다.
그리고 (b)에서 역시 last layer 즉 128, 1x1, 256의 weight를 [A1, A2]라고 가정하고 2번째 layer의 각 값들을 [B1; B2]라고 가정하면 결국 나오는 값은 [A1,A2][B1;B2]이기 때문에 (a)의 값과 동일하다.
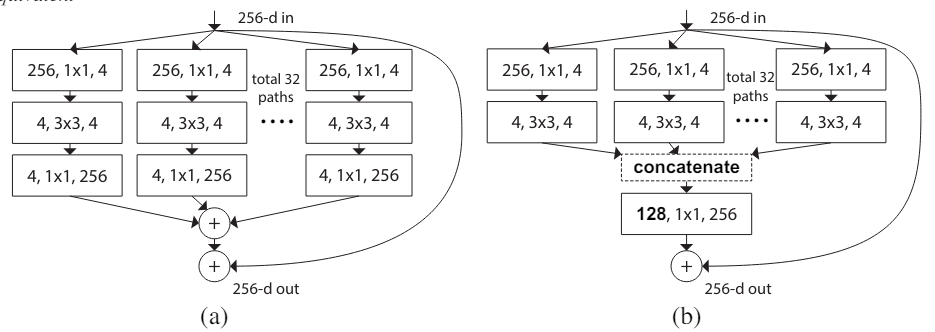
- 이 때 깊이가 2 이하인 block은 유의미한 topologie를 생성하지 못해서 의미가 없다. 3이상이 되어야 의미가 생긴다. 2 이하는 그냥 넓은 네트워크다.
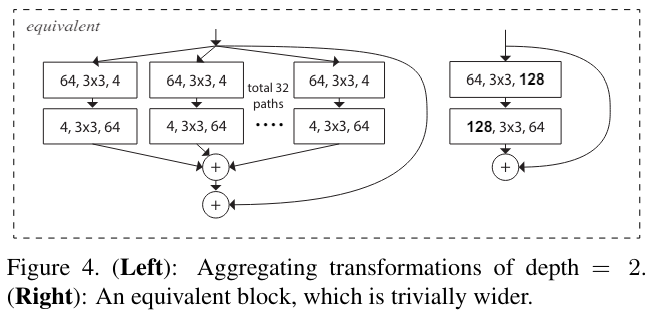
위 그림은 depth가 2인 예시이다.
3.4 Model Capacity
모델의 param과 계산량을 유지하고 성능 증가량을 측정하는 것이 목표이기 때문에 bottleneck의 width를 조정해서(위 그림의 4) input과 output의 크기는 유지한 채로 계산량을 유지했다.

계산량을 유지하기 위해 C에 따른 bottleneck의 width
4. Implementation details
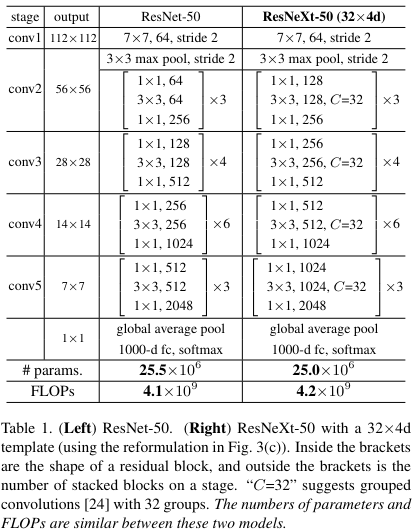
- shortcut은 identity를 기본적으로 쓰지만 dim이 증가할 때에는 Deep Residual Learning for Image Recognition의 type b 즉 1x1 conv layer를 이용하였다.
- 이미지 크기의 downsampling은 stride가 2인 첫번째 block의 첫번째 3x3 layer를 통해서 진행하였다.
- SGD 사용
- mini-batch 256
- 8 GPU (batch 32 per GPU)
- weight decay 0.0001
- momentum 0.9
- learning rate 0.1에서 시작해서 3번 10으로 나눈다.
- He initialization
모델은 위 모델들 그림에서 (c) 즉 group conv의 형태로 구현이 되었으며
convolution이 끝난 직후 BN과 ReLU를 순차적으로 적용하였다. 그러나 마지막 ReLU는 shortcut과 add 전에 적용이 되었다. (ResNet과 동일하게 만들기 위해서)
5. Experiments
5.1 Experiments on ImageNet-1K
cardinality를 늘렸을 때 같은 연산량으로 기본 resnet에 비해서 training 단계에서부터 더 낮은 loss를 보였다 이는 regularization이 아니라 더 좋은 representation의 효과로 보인다.
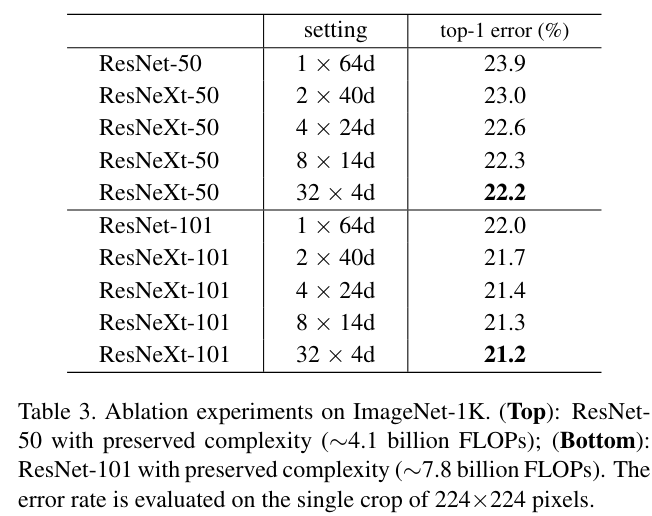
위 표에서 알 수 있듯이 bottleneck의 width가 어느정도 이상으로 줄어들면 점점 정확도 증가량이 감소한다. 그래서 논문에서는 4D 이상으로 유지해서 실험한다.
또한 논문에서는 deeper, wider network와 cardinality를 비교하였는데 결과는 다음과 같다.
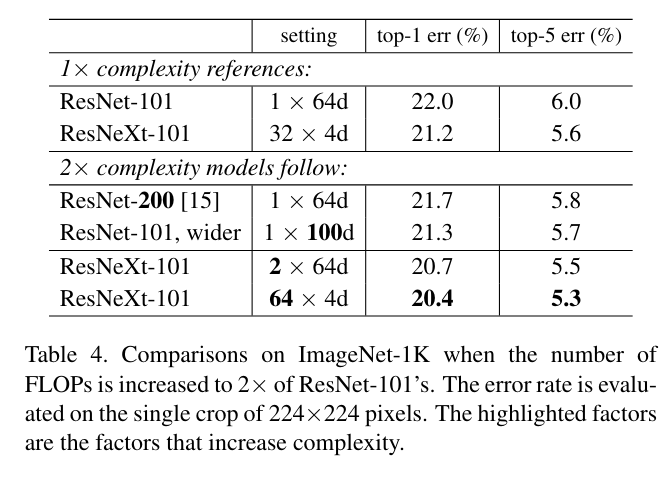
표의 윗 부분은 기존의 계산량을 유지한 모델이고 밑은 2배로 복잡하게 만든 모델이다. deeper(ResNet-200), wider, cardinality는 1x64d에서 C=2, 32x4d에서 C=64로 변경한 모델이고
위의 결과를 본다면 deeper한 것보다 기본적으로 32x4d가 이미 좋다.
결국 cardinality가 wider, deeper한 network보다 효율적이라는 것을 의미한다.
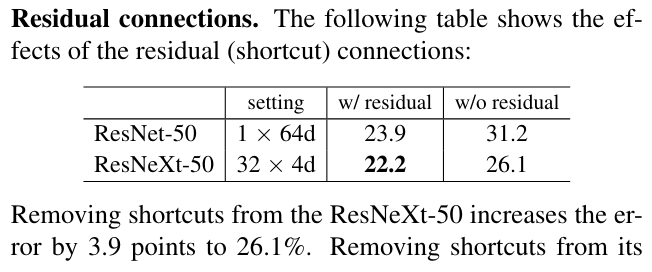
위 표는 residual의 skip connection을 제외하고 학습시켰을 때이다. 역시 매우 안좋게 오류가 나오고 떨어졌지만 ResNext는 더 좋은 representation 능력을 가지고 있기에 더 좋은 성과를 낸다.
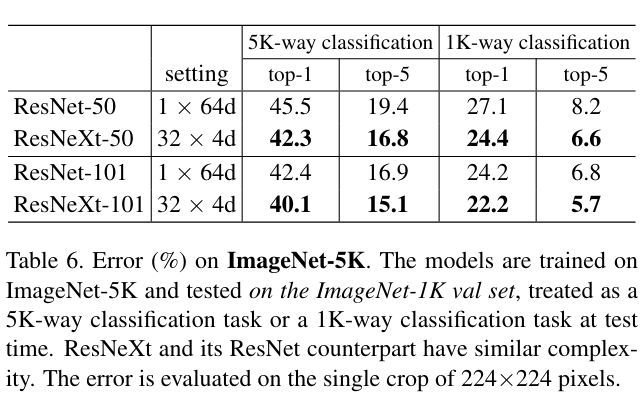
5.2 Experiments on ImageNet-5K
모델이 학습하는 과정에서 정체된 모습이 보였는데 논문에서는 이러한 정체가 모델의 능력 때문이 아니라 데이터의 복잡성이 부족해서라고 이야기했다.
그렇기에 더 복잡한 ImageNet-5K를 이용해서 테스트를 진행하였는데
ImageNet-1k보다 조금 더 큰 차이로 좋은 성과를 보였다.
코드 구현
cifar10 즉 32x32인 이미지를 위해서 조금 수정한 모델이다.
추가로 resnet의 기본 bottleneck model은 여기에서 볼 수 있다.
# resnext paperhttps://arxiv.org/pdf/1611.05431
class ResNextBlock(nn.Module):
def __init__(self, in_channel, inner_channel, out_channel, cardinality=32, is_downsample=False, stride=None):
super().__init__()
if stride is None:
stride = 2 if is_downsample else 1
self.seq = nn.Sequential(
nn.Conv2d(in_channel, inner_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(inner_channel),
nn.ReLU(),
nn.Conv2d(inner_channel, inner_channel, kernel_size=3,
stride=stride, padding=1, groups=cardinality, bias=False),
nn.BatchNorm2d(inner_channel),
nn.ReLU(),
nn.Conv2d(inner_channel, out_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channel),
)
if is_downsample:
self.downsample = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=1,
stride=stride, bias=False),
nn.BatchNorm2d(out_channel),
)
else:
self.downsample = nn.Identity()
def forward(self, x):
return F.relu(self.seq(x) + self.downsample(x))
class ResNext(nn.Sequential):
def __init__(self, class_num=10):
super().__init__(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1,
bias=False), # 3,32,32 -> 64,32,32
nn.BatchNorm2d(64),
nn.ReLU(),
ResNextBlock(64, 128, 256, is_downsample=True,
stride=1), # 256,32,32 -> feature size를 유지하고 64를 256으로 증가시키기 위함
ResNextBlock(256, 128, 256),
ResNextBlock(256, 256, 512, is_downsample=True), # 512 16x16
ResNextBlock(512, 256, 512),
ResNextBlock(512, 512, 1024, is_downsample=True), # 1024 8x8
ResNextBlock(1024, 512, 1024),
ResNextBlock(1024, 1024, 2048, is_downsample=True), # 2048 4x4
ResNextBlock(2048, 1024, 2048),
nn.AvgPool2d(4),
nn.Flatten(),
nn.Linear(2048, class_num),
)
테스트 결과
cifar10 데이터로 200epoch 테스트
lr=0.1
multistepLR = 100,150에 *0.1
momentum = 0.9
batch size = 128
weight decay = 0.0001
acc 정확도
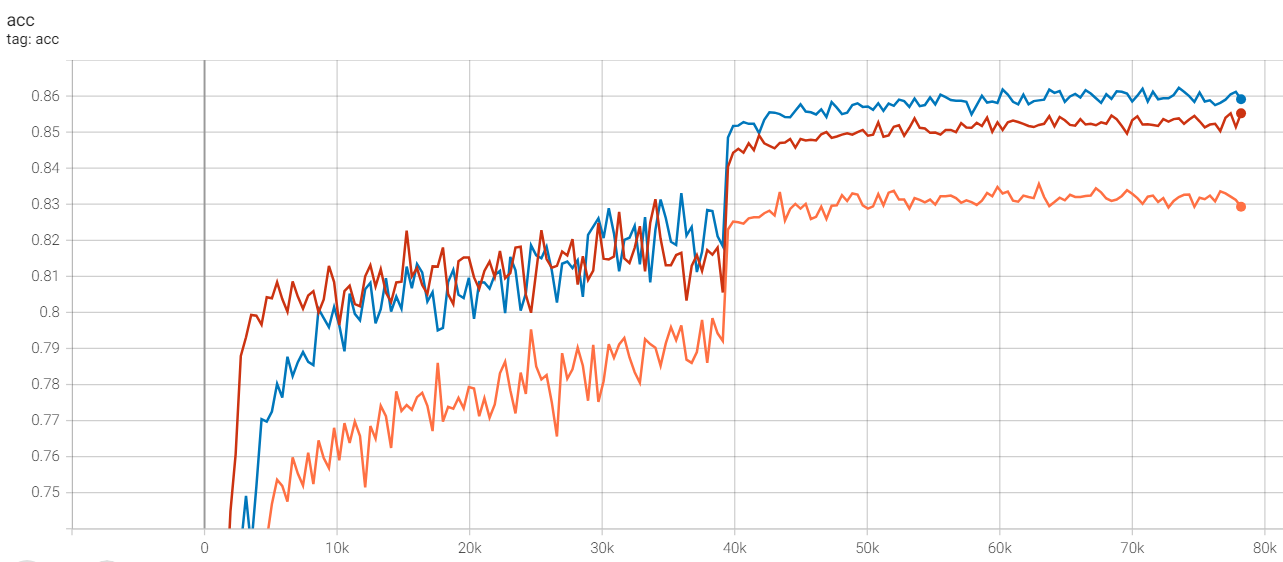
빨간색 - resnet18
주황색 - resnet18_bottleneck
파란색 - resnext
resnext가 초반에는 낮지만 후반에는 높은 모습을 보여준다.
bottleneck은 기본 모델보다 낮은데 이는 bottleneck 구조에 의한 정보의 손실이라고 추측
loss
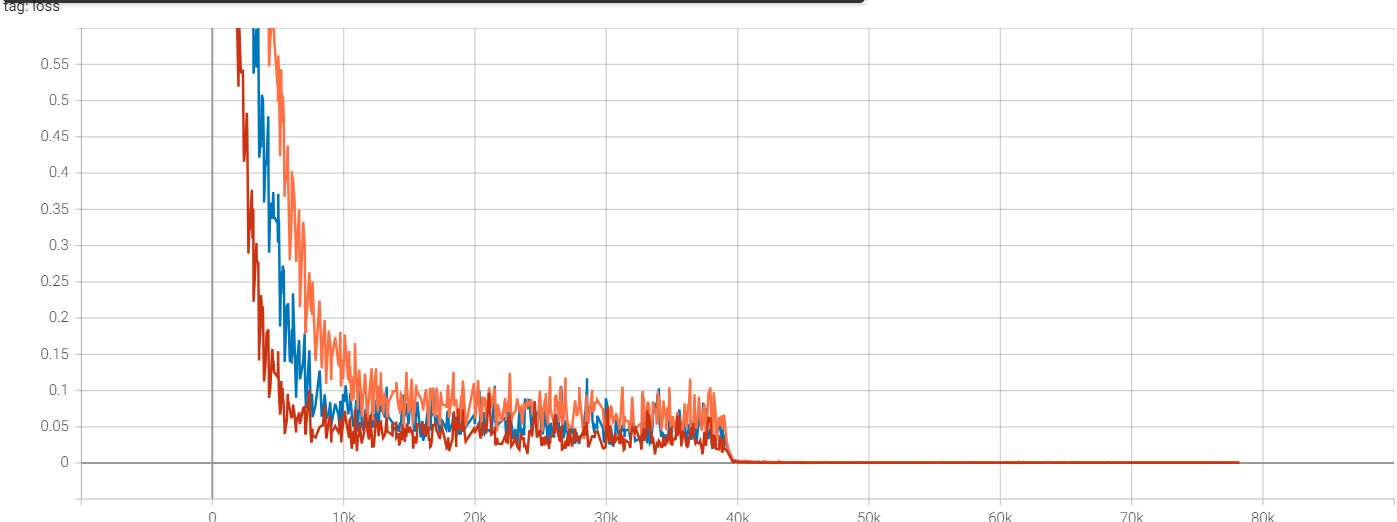
빨간색 - resnet18
주황색 - resnet18_bottleneck
파란색 - resnext
초반에 resnet18이 매우 빠르게 감소를 하지만
후반에는 거의 동일해진다.
또한 resnext가 lr이 처음 0.1곱해지는 100epoch에서 급격하게 정확도가 상승한다.
