Introduction
- Deep conv network는 이미지 분류의 돌파구였다. conv network는 이미지의 low/mid/high level의 특성을 찾아내고 이 레벨은 깊이가 깊어질수록 풍부해진다.
결국 network의 깊이가 성능에 중요한 영향을 미친다.
- layer를 계속 쌓게 되면 vanishing, exploding gradient 문제가 발생해서 네트워크가 수렴하지 않는데 이 문제는 initialization과 Normalization layer으로 어느정도 해결하였다.
- 그러나 layer를 많이 쌓게 되면 또 다른 degradation문제가 발생 이는 더 깊은 네트워크가 오히려 낮은 정확도를 가지게 함. 이러한 degradation은 overfitting의 문제가 아님 training 단계에서 부터 높은 error를 가지기 때문
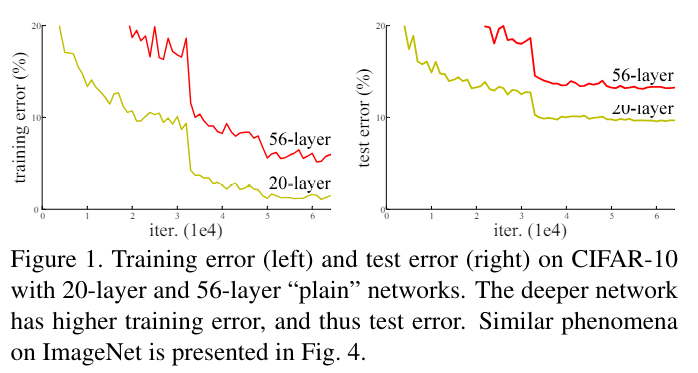
위 이미지는 plain network에서 layer 수에 따른 error 비교 위를 보면 56-layer가 20-layer보다 더 높은 training, test error을 가진다는 것을 알 수 있음. 결국 overfitting과는 다른 문제임을 알 수 있음 - 이 논문에서는 degrading 문제를 residual network로 해결
residual network
- residual network의 구조는 다음과 같음.
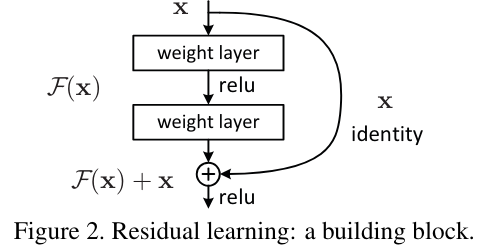
이 구조에서 밖으로 나가는 mapping을 H(x)라고 한다면 내부 블럭이 계산하는 F(x)는 H(x)-x로 매핑이 될 것이다. 결국 H(x)=F(x)+x로 매핑이 된다.
논문에서는 original mapping을 optimize하는 것보다 residual mapping을 optimize하는 것이 더 쉽다고 가정. 예를 들어서 만약 극단적으로 identity mapping이 optimal이면 F(x)는 zero mapping이 되기만 하면 됨.
Deep residual learning
3.1 Residual learning
-
기존에도 layer를 여러번 쌓으면 모든 함수가 표현이 가능하다. 그러나 여기에서는 명시적으로 F(x)=H(x)-x를 표현한다. 명시적으로 표현하는 것과 암묵적으로 표현하는 것에는 학습의 어려움 정도가 다르다.
-
결국 layer에서 H(x)=F(x)+x가 되고 layer가 엄청나게 깊어져도 F(x)=0이 되면 H(x)=x 즉 identity mapping이 됨으로써 기존의 20 layer 보다 56layer가 training error이 더 높은 상황을 방지한다. 왜냐하면 최소한 identity mapping으로 나머지 26 layer를 채우면 20layer와 동일하게 만들 수 있기 때문이다. 결국 degradation 문제를 방지할 수 있다.
-
결국 degradation은 일반 multiple non-linear layers에서 identity mapping으로의 수렴이 잘 이루어지지 않는 것을 의미하기도 한다. 만약 identity mapping이 optimal이라면 identity로 갔을 것이기 때문.
-
실제 문제에서는 identity mapping이 최적일 가능성이 낮지만 이러한 H(x)=F(x)+x의 변환이 도움을 준다.
만약 최적 함수가 identity mapping에 가깝다면 새로운 함수를 만들어내는 것보다 identity mapping을 참조해서 변동을 만들어내기 쉽기 때문이다.
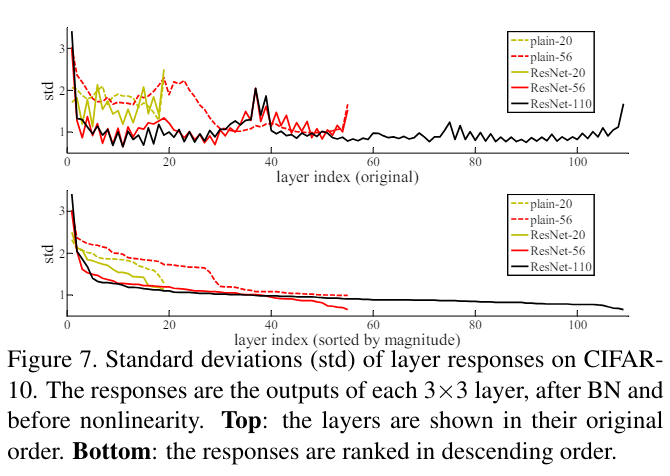
실제로 학습된 결과를 분석한 위 이미지를 보면 plain보다 resnet에서 output의 표준편차가 적다. 즉 identity mapping을 참조해서 변동이 생기기 때문에 기존 흐름에서 큰 변화가 생기지 않는 것이다.
3.2 Identity Mapping by Shortcuts
- 논문에서는 building block을 다음과 같이 표현한다.
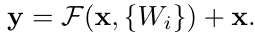
위 식에서 x는 input이고 y는 output이다. F는 학습하는 residual mapping인데 shortcut과 연결되는 블럭이다. 이전에 introduction의 그림에서 weight 2개가 연결된 블럭이다. - 여기에서 중요한 부분은 shortcut의 차원이 바뀔 때인데 우선 X의 dim이 F의 dim(cnn에서는 channel)과 동일해야 한다. 만약 동일하지 않다면 X에 W를 곱해서 수정이 가능하다.
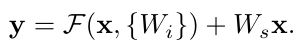
- 또한 여기에서 F 즉 residual block의 내부 구현은 유동적으로 가능하지만 1개의 layer만 넣으면 안된다. 만약 1개만 넣으면 Wx+x가 되는데 이는 사전에 이점이 없다는 것이 확인된 형태이다.
3.3 Network Architectures
-
논문에서는 VGG net을 참고하였는데 여기에서 영감을 받아 2가지 형태의 3x3 Conv layer가 들어간다.
- same feature map, filter number
- feature map이 절반으로되고 fiter number이 2배가 됨 이는 계산의 크기를 유지하기 위함.
-
또한 feature map의 down sampling은 cnn을 stride 2로 설정하여 적용.
-
shortcut의 down sampling은 2가지 방법으로 구현이 가능
A. identtiy mapping인데 dim을 늘리기 위해 나머지 공간을 0으로 채우고 feature map을 절반으로 줄이기 위해 stride 2로 이동
B. dim을 늘리는 1x1 cnn을 stride 2로 적용
3.4 Implementation
224x224 이미지 기준
1.각각 conv layer, activation 사이에 BN(batch normalization) layer 삽입
2. weight는 He initialization으로 적용
3. 미니배치 256
4. learning rate는 0.1에서 시작해서 고원(plateaus)에 도달하면 10을 나누는 식으로 진행
5. 학습 60x10^6 iteration 진행
6. SGD에 weight decay 0.0001, momentum 0.9 적용
7. no dropout
4. Experiments
4.1 ImageNet Classification
-
주로 실험에 관한 내용이다. imagenet classifier에서
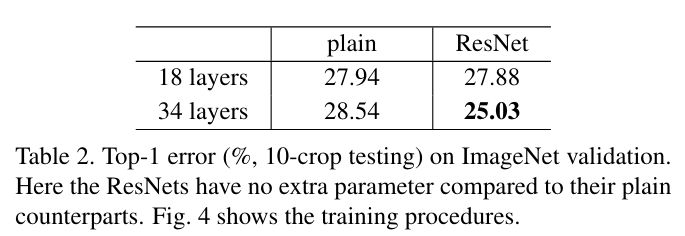
위와 같은 결과가 나왔는데 이는 plain network에서는 degradation problem이 나타난다 (38 layer가 18layer보다 error이 더 높음) 반면에 resnet은 해결이 되었다. -
degradation 문제는 gradient exploding, vanishing 등의 문제가 아니다. 왜냐하면 직접 forward, backward 연산이 정상적인 것을 확인하였고 plain network에도 BN(batch normalization)이 적용이 되었기 때문에 어느정도 gradient 문제에 robust 하기 때문.
-
resnet에는 identity mapping을 사용해서 extra parameter가 없는데도 오히려 error가 줄어든 것을 볼 수 있음. 이는 간단한 shortcut 만으로도 degradation을 처리할 수 있는 것을 보여줌. 그리고 이제 layer의 depth를 더 늘려서 성능을 얻을 수 있음을 의미함.
-
18 layer와 같은 얕은 resnet에서는 큰 성능의 증가가 없었지만 plain network와 비교해서 빠른 loss 감소를 보임
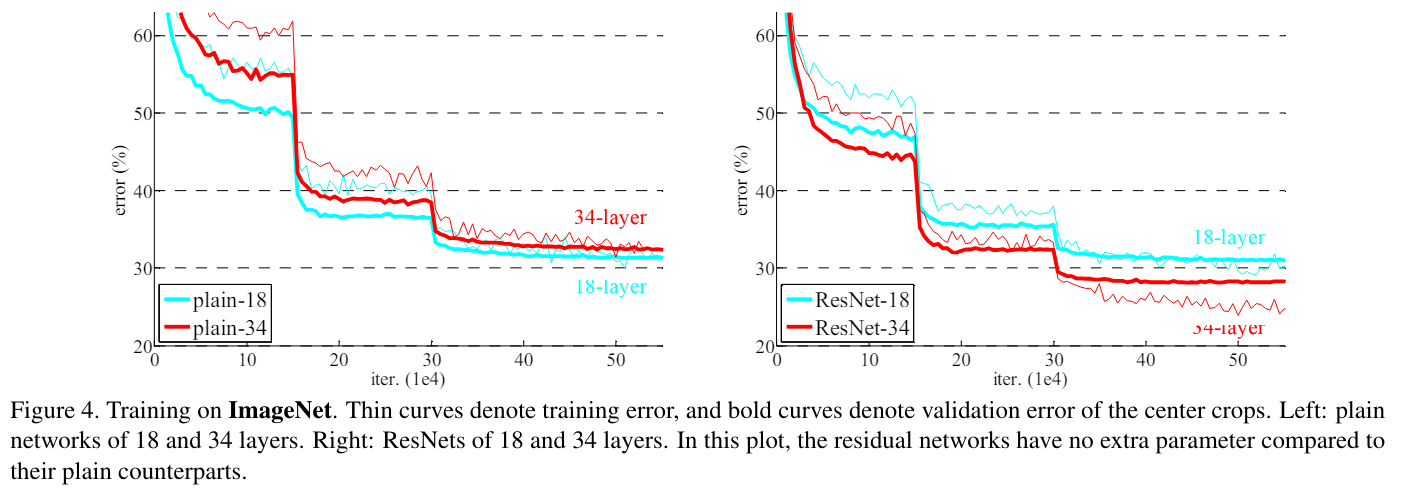
이는 resnet의 형태가 더 쉬운 학습을 보여준다는 것을 의미함.
identity and projaction shortcut
-
이 부분은 위의 내용과 조금 차이가 있는 실험이라서 따로 나누었다. 이전에 identity mapping 즉 parameter가 없이 그냥 매핑만 해주는 경우에 우리는 성능 증가를 볼 수 있었다. 그러나 shortcut에는 3가지의 옵션이 존재한다.
A. dim을 증가시키는 shortcut 에는 zero padding을 적용하고 나머지에는 identity mapping
B. dim을 증가시키는 shortcut에 projection weight적용(1x1 conv 등) 나머지에는 identity mapping
C. 모든 shortcut에 projection을 적용
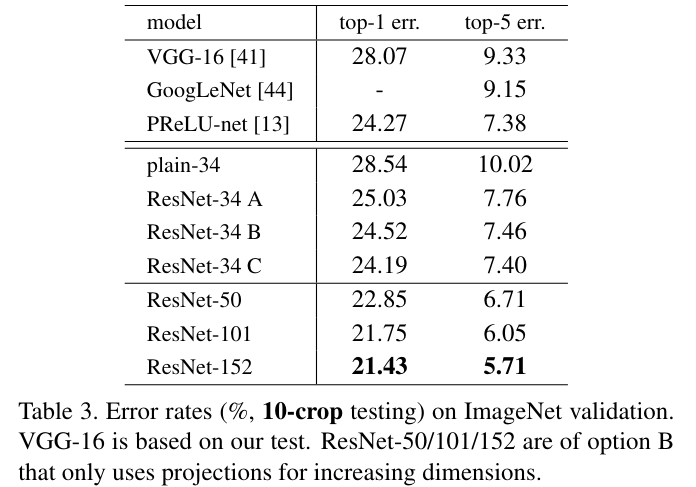
-
위 내용은 A, B, C의 테스트 결과인데 보면 A<B<C의 순서이다.
오히려 정확도가 증가하는 모습을 보여주는데 논문에서는 이를 단순히 weight param 증가의 효과로 보고있다. -
그리고 큰 차이가 없는 것을 통해 degradation 문제에서 shortcut의 weight는 필수가 아닌 것을 보여준다는 것을 알 수있다.
Deeper Bottleneck Architectures.
- 깊은 model을 적은 시간에 구축하기 위한 블럭이다. 기존의 2개의 3x3 layer로 구성대신 3개의 1x1, 3x3, 1x1 layer로 구성 1x1 layer는 dim을 축소하고 늘리는 역할. 3x3 layer는 실질적인 conv 계산 역할을 한다.
- 1x1 layer로 차원을 축소해서 계산을 함으로써 학습에 필요한 계산량을 줄일 수 있다.
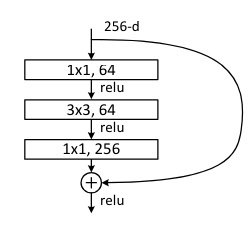
구조는 이와 같이 256dim을 64로 줄이고 3x3 conv로 계산한 다음 256dim으로 복구한다.
Analysis of Layer Responses.
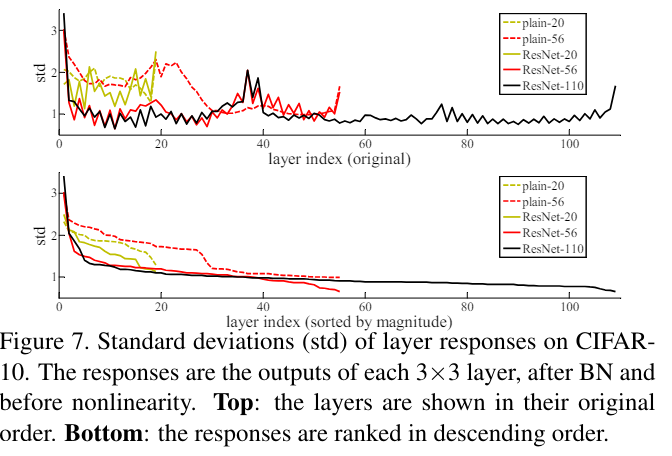
- resnet block의 conv layer의 출력과 plain net의 출력을 비교하였을 때 resnet block의 conv layer 출력이 더 0에 가깝다 이는 identity mapping에 근접하기 위해 conv layer의 출력이 zero로 가까워 진다는 것을 의미한다.
코드 구현
- resnet18을 cifar10 -> 32x32 image를 분류하기 위해 만든 모델 기존과 조금 차이점이 존재함.
class ResBlock(nn.Module):
def __init__(self, in_channel, out_channel, is_downsample=False):
super().__init__()
self.is_downsample = is_downsample
stride = 2 if is_downsample else 1
# conv2d 기본적으로 he uniform initialization을 사용하기에 따로 설정 x
self.seq = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=3,
stride=stride, padding=1, bias=False,),
nn.BatchNorm2d(out_channel),
nn.ReLU(),
nn.Conv2d(out_channel, out_channel, kernel_size=3,
stride=1, padding=1, bias=False,),
nn.BatchNorm2d(out_channel),
)
# option B: downsample -> shortcut을 cnn으로 구현
if self.is_downsample:
self.downsample = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=1,
stride=stride, bias=False),
nn.BatchNorm2d(out_channel),
)
else:
self.downsample = nn.Identity()
def forward(self, x):
return F.relu(self.seq(x) + self.downsample(x))
class Resnet18(nn.Sequential):
def __init__(self, class_num=10):
super().__init__(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
ResBlock(64, 64), # 64, 32x32유지
ResBlock(64, 64), # 64, 32x32유지
ResBlock(64, 128, is_downsample=True), # 128, 16x16
ResBlock(128, 128),
ResBlock(128, 256, is_downsample=True), # 256, 8x8
ResBlock(256, 256),
ResBlock(256, 512, is_downsample=True), # 512, 4x4
ResBlock(512, 512),
nn.AvgPool2d(4), # 512, 1x1
nn.Flatten(),
nn.Linear(512, class_num),
)
bottle neck 모델
class ResBottleNeckBlock(nn.Module):
def __init__(self, in_channel, out_channel, is_downsample=False, stride=None):
super().__init__()
if stride is None:
self.stride = 2 if is_downsample else 1
else:
self.stride = stride
self.in_channel = in_channel
self.out_channel = out_channel
mid_channel = out_channel // 4
self.seq = nn.Sequential(
nn.Conv2d(in_channel, mid_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(mid_channel),
nn.ReLU(),
nn.Conv2d(mid_channel, mid_channel, kernel_size=3,
stride=self.stride, padding=1, bias=False),
nn.BatchNorm2d(mid_channel),
nn.ReLU(),
nn.Conv2d(mid_channel, out_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channel),
)
if is_downsample:
self.downsample = self._identitymap
else:
self.downsample = nn.Identity()
def forward(self, x):
return F.relu(self.seq(x) + self.downsample(x))
def _identitymap(self, x):
x = x[:, :, ::self.stride, ::self.stride]
dim = self.out_channel//self.in_channel # in_channel을 out_channel로 만들어야함
for _ in range(dim//2): # 2배 -> 1번 4배 -> 2번
x = torch.concat((x, torch.zeros_like(x)), dim=1)
return x
class ResBottleNecknet18(nn.Sequential):
def __init__(self, class_num=10):
super().__init__(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
ResBottleNeckBlock(64, 256, is_downsample=True, stride=1),
ResBottleNeckBlock(256, 256),
ResBottleNeckBlock(256, 512, is_downsample=True),
ResBottleNeckBlock(512, 512),
ResBottleNeckBlock(512, 1024, is_downsample=True),
ResBottleNeckBlock(1024, 1024),
ResBottleNeckBlock(1024, 2048, is_downsample=True),
ResBottleNeckBlock(2048, 2048),
nn.AvgPool2d(4),
nn.Flatten(),
nn.Linear(2048, class_num),
)
