나도 아직 100% 이해하지는 못했는데 일단 까먹을까봐 정리해둔다.
틀린부분이 있을 수 있으니 혹시 읽는 사람이 있으면 참고했으면 좋겠다.
MCMC란?
markov chain monte carlo이고 핵심은 결국 다음과 같다.
우리의 목표는 '직접 샘플링하기 어려운 목표 분포(Target Distribution)'를 따르는 샘플을 얻는 것이다. 이를 위해 목표 분포를 Stationary Distribution으로 갖는 Markov Chain을 설계하고, 그 체인을 따라 이동하며 수집한 샘플들로 Monte Carlo 추정을 수행한다.
이를 이해하기 위해서 하나씩 분리해서 보자
monte carlo
우선 monte carlo는
대수의 법칙 느낌으로 sample을 많이 만들어서 그걸 통해 추정을 하는 방식이다
예를 들면 가 있을 때 이 값은 인데 적분을 하기 힘들 때 에서 를 여러번 sampling해서 평균을 근사하는 방법이다.
markov chain
사실상 이게 핵심이다
markov chain에서 markov는 markovian하다는 용어로 많이 사용이 되는데
간단하게 미래의 상태가 현재의 상태에만 dependent하다는 것이다.
일때
makovian하다면 로 직전의 상태에만 dependent하다는 것이다.
그렇기 때문에 간단하게 이렇게 간단하게 표현이 가능하다.
이때 markov chain의 중요한 성질이 있는데 특정 조건이 맞을때 markov chain을 transition을 여러번 반복하면 stationary 분포로 수렴을 하게 된다는 것이다.
특정 조건은 엄밀하지는 않지만 지금은 심플하게
특정 분포 가 있고 A에서 B의 transtion 확률 가 있을 때
로 들어오는 transition과 나가는 transition이 동일하면 stationary distribution으로 수렴을 하게 된다.
결국 우리는 stationary distribution으로 수렴하는 성질을 활용하고 싶은 것이다.
핵심
이제 다시한번 더 핵심을 보자
우리는 결국 우리가 샘플링이 가능한 분포에서 뽑은 샘플을 목표로하는 분포를 stationary distribution을 가지는 markov chain을 통해서 monte carlo 방법을 통해 뽑는 것이 목표이다.
아마 위 내용이 이해가 될 것이다.
Metropolis-Hastings
MCMC의 방법에는 여러가지가 있겠지만
대표적인 것 하나를 설명하겠다.
방법은 매우 간단한데
핵심은 현재 샘플 이 있을 때 proposal distribution 에서 candidate 를 으로 샘플할 때 목표 분포가 라면
acceptance rate 의 확률로 새로운 샘플로 받아들여서 로 할지 아니면 버리고 기존을 유지할지 고르는 것이다.
왜 이렇게 나오는 걸까?
앞서 이야기했듯이 핵심은
를 맞춰서 stationary distribution을 유지하는 것이다
이때 를 좀 더 엄밀하게 표현하자면 현재 proposal distribution 에다가 받아들일 확률인 acceptance rate 를 곱해서
로 표현할 수 있다.
위 내용을 대입하면
로 표현할 수 있고
여기에서 로 정리하면
가 나오게 된다.
이때 라고 하면
가 된다.
acceptance rate는 이기 때문에
여기에서 의 기준에서 만약 이면 이기 때문에 최고 transition을 사용해 1을 넣으면 는 maximum 1이 되고
만약 이 되면 역시 동일하게 가 되어야 하기 때문에 이 되어 최고치가 이 된다.
그렇기에 이 되면 stationary distribution에 수렴하게 되어 sampling을 여러번 반복하게 되면 목표로 하는 분포로 수렴하게 된다.
이때 비율을 사용하기 때문에 target 분포 가 normalized되어있지 않아도 된다.
분모, 분자에 모두 normalizer 가 동일하게 들어가면서 사라지기 때문
코드
import numpy as np
import matplotlib.pyplot as plt
# 1. 목표 분포 (Target Distribution)
# 정규화 상수 없이 '모양'만 정의합니다. (평균 3, 표준편차 1인 정규분포 형태)
def target_distribution(x):
# exp( - (x - 평균)^2 / (2 * 표준편차^2) )
return np.exp(-0.5 * (x - 3)**2)
# 2. 메트로폴리스-헤이스팅스 알고리즘
def run_metropolis_hastings(start_value, iterations):
current_x = start_value
samples = [] # 방문한 위치들을 기록할 리스트
for i in range(iterations):
# A. 제안 (Proposal): 현재 위치에서 살짝 움직여본다 (랜덤 워크)
# 0.5의 표준편차를 가진 노이즈를 더함
proposed_x = current_x + np.random.normal(0, 0.5)
# B. 비교 (Ratio): 목표 분포의 높이 비교
# P(new) / P(old)
ratio = target_distribution(proposed_x) / target_distribution(current_x)
# C. 결정 (Accept/Reject)
# ratio가 1보다 크면 무조건 수락 (min(1, ratio) 로직과 동일)
# ratio가 1보다 작으면 그 확률만큼 수락
acceptance_prob = min(1, ratio)
if np.random.rand() < acceptance_prob:
current_x = proposed_x # 이동 수락!
else:
current_x = current_x # 거절! (제자리 유지)
samples.append(current_x) # 기록 (중요: 거절당해도 현재 위치를 또 기록함)
return samples
# --- 실행 ---
np.random.seed(44)
# 엉뚱한 곳(0)에서 시작해서 10,000번 이동
total_iterations = 10000
chain_samples = run_metropolis_hastings(start_value=0, iterations=total_iterations)
# --- 시각화 ---
plt.figure(figsize=(12, 5))
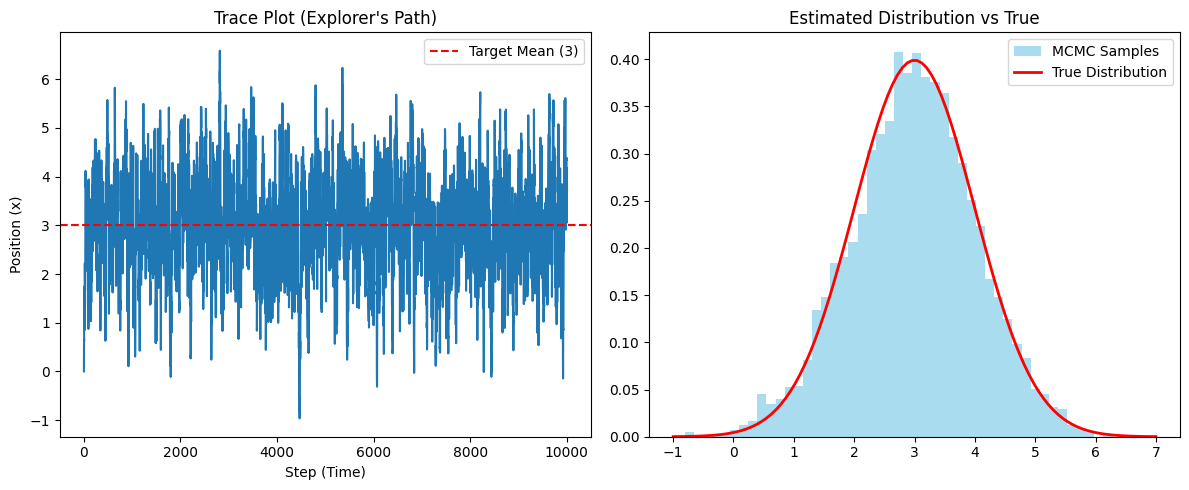
# 1. Trace Plot: 탐험가가 걸어온 길
plt.subplot(1, 2, 1)
plt.plot(chain_samples)
plt.title("Trace Plot (Explorer's Path)")
plt.xlabel("Step (Time)")
plt.ylabel("Position (x)")
plt.axhline(3, color='r', linestyle='--', label='Target Mean (3)')
plt.legend()
# 설명: 처음엔 0에서 시작했지만 금방 3 근처로 가서 진동하는 것을 볼 수 있음
# 2. Histogram: 발자국을 쌓아보니...
plt.subplot(1, 2, 2)
plt.hist(chain_samples, bins=50, density=True, color='skyblue', alpha=0.7, label='MCMC Samples')
# 실제 목표 분포 곡선 그리기 (비교용)
x = np.linspace(-1, 7, 100)
# 정규분포 공식 (비교를 위해 정규화 상수 포함)
true_pdf = (1 / np.sqrt(2 * np.pi)) * np.exp(-0.5 * (x - 3)**2)
plt.plot(x, true_pdf, 'r-', lw=2, label='True Distribution')
plt.title("Estimated Distribution vs True")
plt.legend()
plt.tight_layout()
plt.show()코드에서 만 쓰고 이 없는 이유는 현재 x좌표를 기준으로 대칭적이라서 사라지기 때문 즉, A에서 B로 가는 확률이랑 B에서 A로 갈 확률이 동일.
결과