흥미로운 논문이다.
진짜 간단하게 요약해서
기존 RL은 reward가 scalar인데 이는 code를 실행하면 뜨는 compiler error등 풍부한 feedback을 반영하기 부족하다.
그렇기에 이 논문은
model이 처음 생성한 답 [질문, 답] sequence에서 피드백을 받은 후 피드백을 답 이전에 붙여서 다시 logit을 구한다. [질문, 피드백, 답]과 같이.
그러면 답에 대한 logit distribution이 피드백을 incotext learning으로 반영한 더 정확한 logit이 될꺼니까
이를 스스로 distillation을 진행해서 학습하는 것이다.
매우 아이디어가 심플하고 좋은 논문이라고 생각한다.
Abstract & Introduction
위 내용과 동일하다 기존의 scalar reward는 풍부한 정보를 담기 힘들기 때문에 reward를 풍부하게 주는 것이 중요한데 기존의 방법들은 strong teacher model이 따로 필요한 경우가 대부분이었다.
그렇기에 이 논문은 스스로 self-distillation하면서 풍부한 feedback signal을 받으면서 강화학습을 할 수 있도록 만들었다.
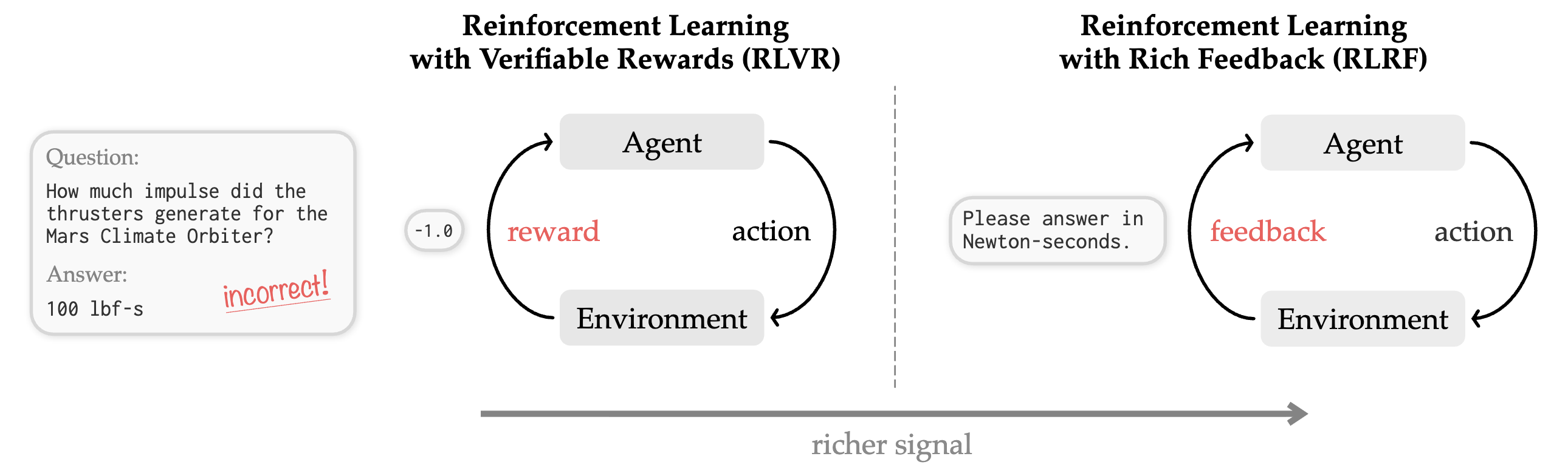
위 내용이 왼쪽이 기존의 scalar reward, 오른쪽은 풍부한 reward

위 내용은 기존과 다른 점을 보여주는 표.
on-policy로 모델이 스스로 답을 만들어보면서 rich한 signal을 받을 수 있고 환경으로부터 feedback을 받음.
SDPO: Self-Distillation Policy Optimization
진짜 심플한데

위 내용처럼 question을 보고 모델이 답을 만들고 지금은 code니까 compiler로부터 feedback을 받는다.
이후 그 feedback 를 question에 붙이고 다시 logit을 구하고 distillation을 진행.
이때 Teacher, student의 차이를 로 표현하는데 이 의미는 Teacher은 낮게 주고 student는 높게주면 -가 되고 이게 지금 그림의 + 부분, 즉 잘못된 부분이다.
이를 통해 dense한 credit assignment가 가능하다.

위 내용이실제 template이고
정답 맞춘 경우가 있으면 그 답도 Correct solution으로 넣어준다.
나머지는 좀 trick인데
전체 vocab에 대해서 KL을 구하면 너무 비용이 크니까 메모리 최적화를 위해서 Top-K (100개)의 logit만 가지고 계산을 했다고 함.
그리고 teacher은 student랑 100% 동일하진 않고 EMA로 하고 KL도 Jensen-shannon divergence로 구하면 더 안정적이고 뛰어난 성능을 보였다고 함.
experiments
실험 결과는 너무 많아서 짧게 작성하겠다.
Learning without Rich Environment Feedback
feedback이 많이 없는 scalar의 경우 맞는 답을 context로만 넣어줌.
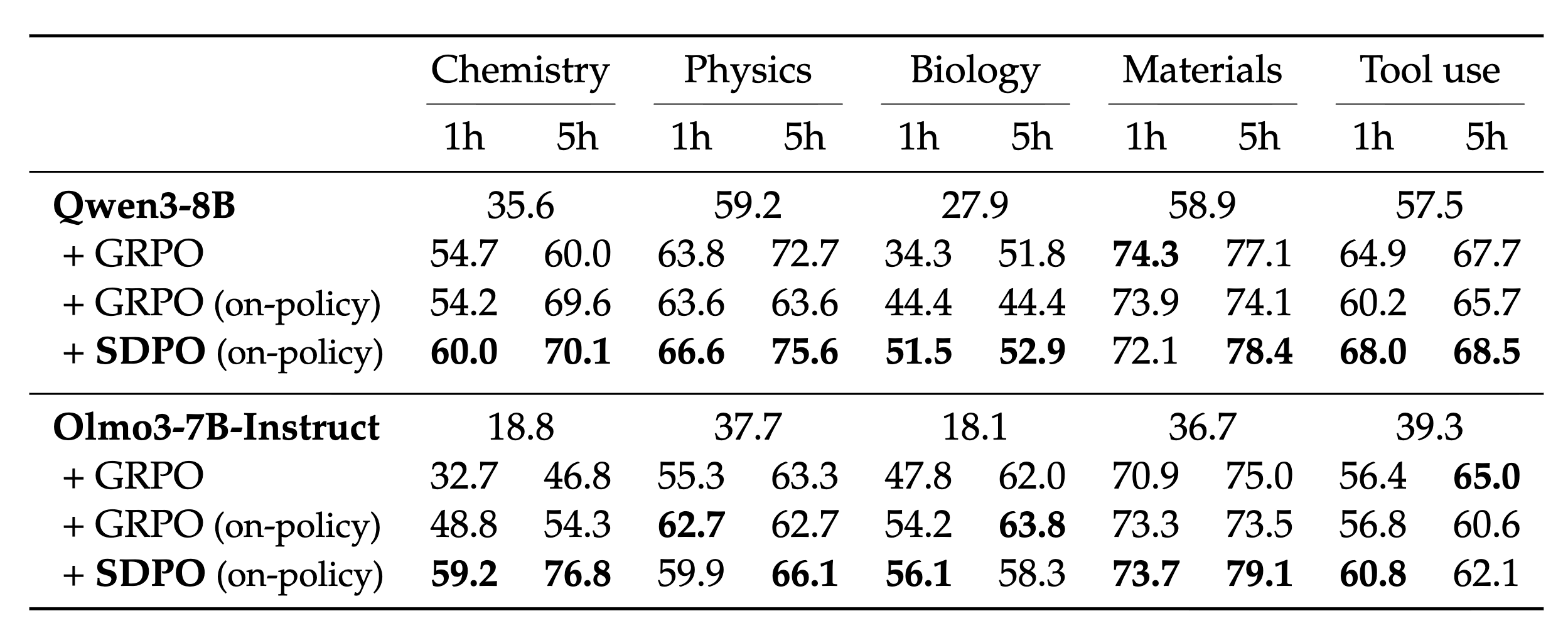
GRPO를 이긴다.
Learning with Rich Environment Feedback
error message처럼 coding에서 feedback이 매우 풍부한 경우
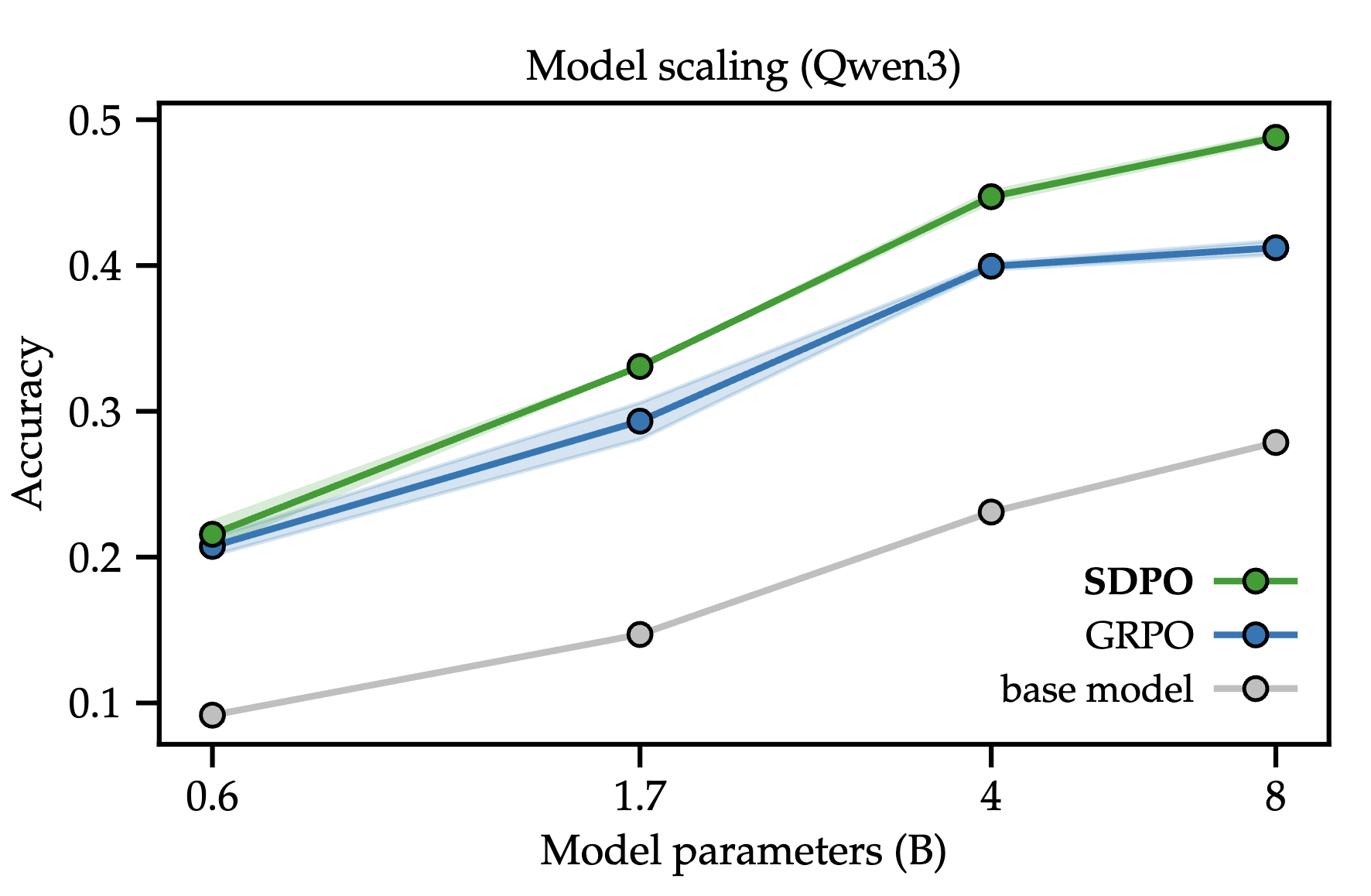 GRPO를 이기고 scale이 커져도 성능 향상이 유지된다.
GRPO를 이기고 scale이 커져도 성능 향상이 유지된다.
이는 in context learning ability가 커져서 그런 것으로 보임.
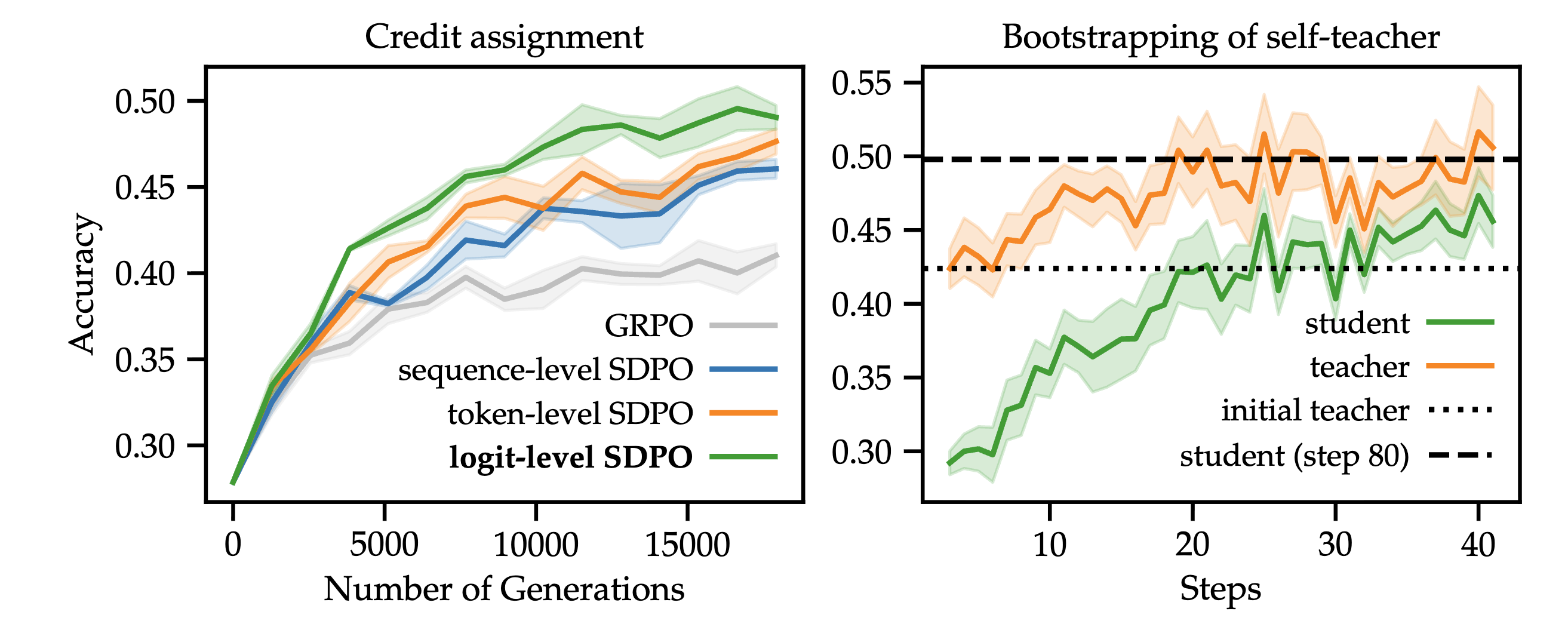
위 그림의 왼쪽은 credit assignment 실험을 위해서
GRPO는 전체 sequence에 대해서 1개의 scalar지만
SDPO는 token당 logit으로 dense하게 reward를 주기 때문에 엄청 dense하게 reward를 주는 것을 보여줌
실험을 구성했는데
sequence는 GRPO처럼 seqeuence 전체에 대해서 동일한 reward를 준거고
token-level은 실제로 골라진 1개의 token에 대해서만 reward를 준거고
logit-level은 앞서 세팅처럼 Logit에 대해서 상위 100개 logit에 dense하게 reward를 준건데
보면 logit level이 매우 성능이 좋다. 그다음 token 그리고 sequence로 credit-assignment가 매우 중요함을 보여줌.
오른쪽 부분은 teacher도 학습이 진행되는데 teacher의 accuracy가 어떻게 될지 확인한건데 teacher도 점점 성능이 증가한다.
재밌는건 student가 40step만 학습해도 초기 teacher의 점수를 넘어서지만 teacher도 업데이트가 되면서 성능이 증가해서 student가 더 증가할 여지가 생긴다.
나는 이런 방향으로 AI의 학습이 진행되어야 한다고 생각한다. 스스로 발전하는. 사실 사람이 supervision하는 것도 사람이 upperbound가 되는 것인데 나중에는 이것도 넘어서야 하지 않을까 싶다.
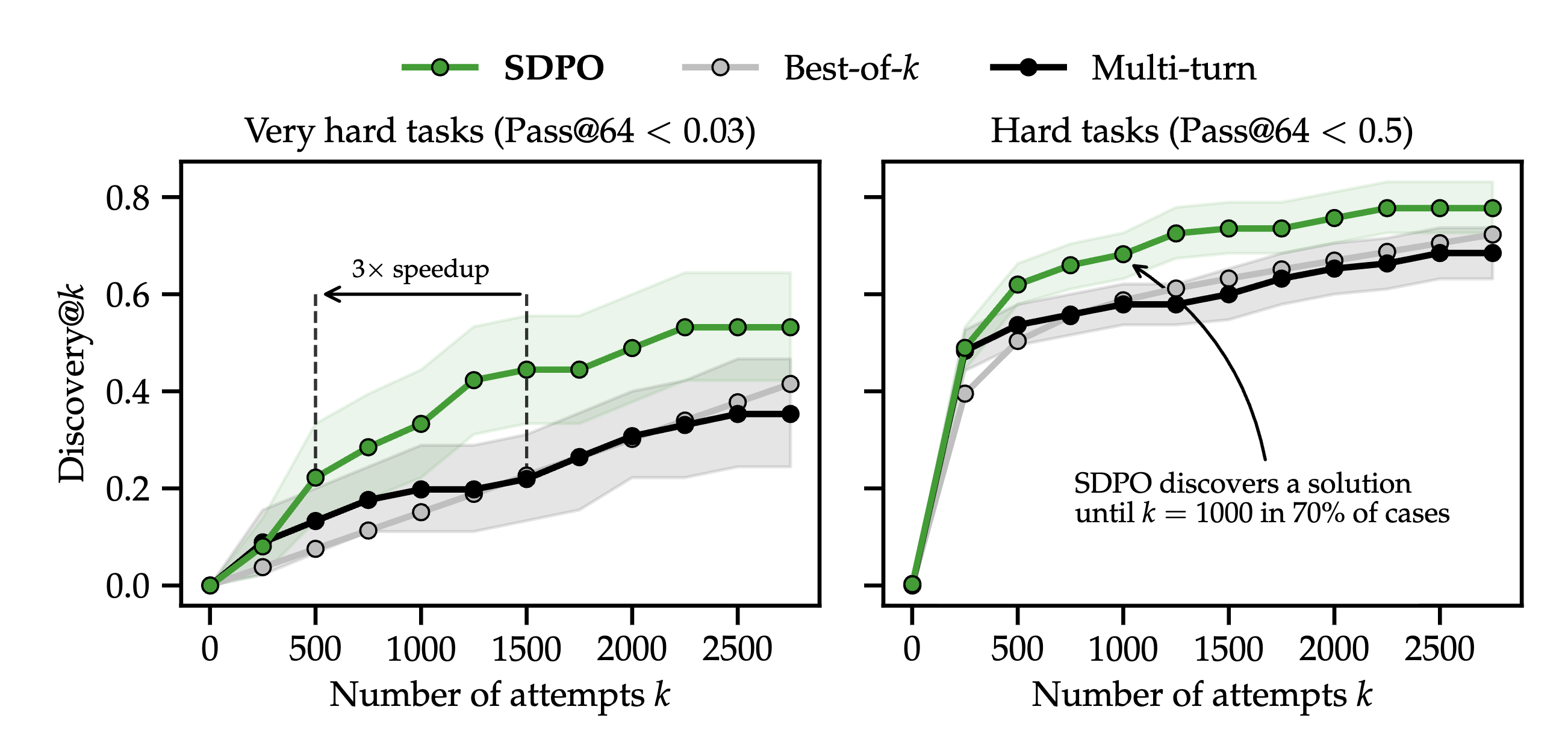
Solving Hard Questions via Test-Time Self-Distillation
현재 environment로부터 feedback을 받을 수 있는 세팅이면 test time에도 학습이 가능하다.
이를 통해서 어려운 문제를 여러번 시도해보면서 자신을 업데이트하면서 풀 수 있는데
base line은 best of N과 그냥 context를 feedback을 받아 두는 Multi-turn이다.
결과는 아래와 같이 SDPO가 더 좋은 성능을 보인다.