매우 심플하고 재밌는 논문이라서 공유한다.
그런데 옛날에 STaR 논문도 스스로 question과 answer를 보고 중간 과정을 만드는데 그거의 강화 버전인 것 같다.
Abstract
현재 LLM의 Computation은 엄청나게 증가하고 있지만 high quality data는 거의 고갈이 되었다. 그렇기에 computation이 엄청나게 많아져도 data가 없어서 학습을 하지 못하는 상황인데
이 논문은 data의 utility를 어떻게 더 끌어낼 수 있을까? 에 관한 논문이다.
심플하게 data를 llm을 이용해 augmenetation을 하면 더 성능이 늘어난다는 내용인데 내용이 매우 심플하고 성능 증가가 생각보다 강력해서 공유하면 좋겠어서 글을 작성한다.
Introduction
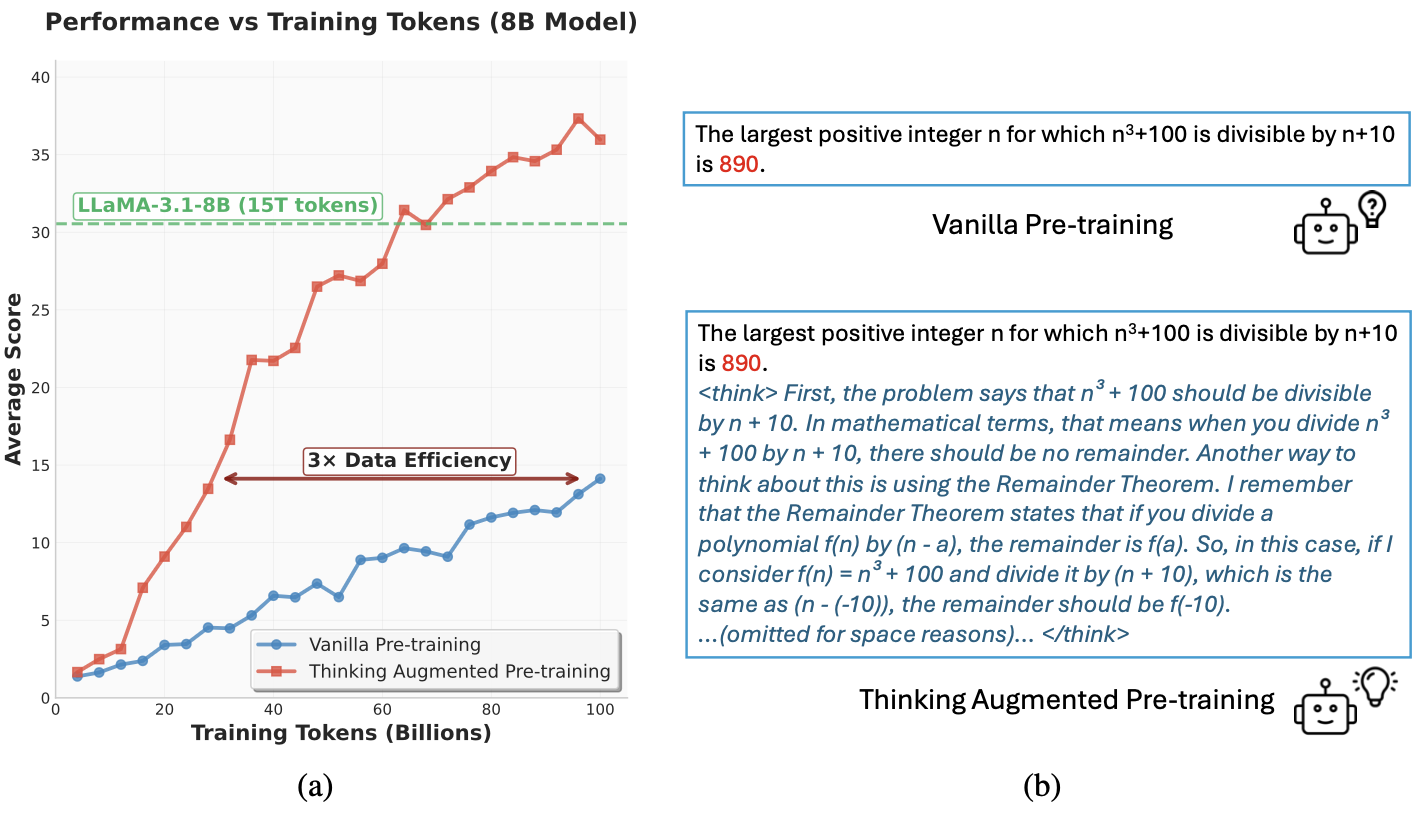
진짜 과장 안보태고 위 그림만 보면 논문의 핵심을 다 이해할 수 있다.
애초에 Method도 1페이지도 안된다.
오른쪽 그림을 보면 기존 llm은 주어진 text를 그대로 학습을 시키는데 이는 데이터를 그냥 주어진 그대로 학습하는 것이다. 이때 특정 token은 예측하기 매우 어려운데 이를 valuable token이라고 한다.
valuable token을 학습하는 것은 매우 좋은데
사람도 쉬운 문제만 많이 푸는 것은 큰 도움이 안된다. 어려운 문제를 풀어야 그 과정에서 배우는 것이 많다.
valuabel token을 학습하기에는 매우 어렵다.
그래서 이 논문은 위 그림의 (b)와 같이 기존 data 뒤에 llm을 이용해서 만든 설명을 덧붙여서 학습을 진행한다.
이렇게 만든 데이터로 학습을 진행하면 동일한 token을 학습 하더라도 성능이 매우 뛰어나게 향상이 된다.
개인적으로 매우 인상깊었던게 보통 thinking process agumentation의 형태는 x가 prompt, z가 thinking, y가 answer이면 x->z->y의 순서로 데이터를 만드는데
이 논문은 특이하게 x->y->z로 thinking process가 뒷부분에 들어가있다.
그래서 보통 x->z로 thinking을 생성해서 이를 보고 y를 예측하도록 학습하는 것이 전형적인 COT 같은 상황인데 학습 단계에서 x만 보고 y를 예측하도록 학습하고 x,y를 보고 z 그러니까 문제와 답을 보고 설명을 보도록 학습해도 앞부분 예측에 성능 증가가 있다는 것이 너무 신기했다.
최근 트렌드인 thinking process가 늘어나도 오히려 답을 더 못 맞추는 경우가 있다는 논문이 많이 나오고 있는데 이 논문의 결과도 이와 비슷하게 매우 흥미로운 것 같다.
이 논문은 모든 process가 사람의 annotation이 필요 없기 때문에 scalability가 가능하고.
진짜엄청나게 신기한 사실은
models trained on such augmented data can, as our experiments demonstrate,
surpass the performance of the thinking generation model itself.
그러니까 thinking generation을 만든 모델보다 그 데이터로 학습한 모델의 성능이 더 뛰어나다는 것이다.
나는 이게 처음에 data차원의 distillation으로 생각했는데 distillation한 모델보다 성능이 더 뛰어나다는 것은 그 뒤에 뭔가 더 있다는 이야기 같다. 그리고 궁금한게 만약 이거를 계속해서 반복하면 재귀 개선이 가능할까?? 나는 AGI를 위해서는 재귀 개선이 핵심이라고 생각해서 매우 궁금하다.
THINKING AUGMENTED PRE-TRAINING
 논문의 내용은 그냥 위처럼 proompt를 줘서 llm한테 설명을 만들으라고 한 다음에 그거를 데이터에 data, explain 의 형태로 붙여서 학습시킨다는 것이다.
논문의 내용은 그냥 위처럼 proompt를 줘서 llm한테 설명을 만들으라고 한 다음에 그거를 데이터에 data, explain 의 형태로 붙여서 학습시킨다는 것이다.
진짜 이게 다이다.
재밌는 표현은 dynamic allocation of training compute라는 표현을 쓰는데 test-time computation에서 보통 어려운 token을 예측하기 위해서 compute를 더 쓰는게 일반적이다.
이 논문은 설명을 하는 과정에서 이와 비슷하게 어려운 token을 설명하는 length가 더 길어지기 때문에 그 token을 학습하기 위해서 사용되는 compute가 자연스럽게 더 소모된다는 것이다.
Experiments
3.1 PRE-TRAINING UNDER ABUNDANT DATA
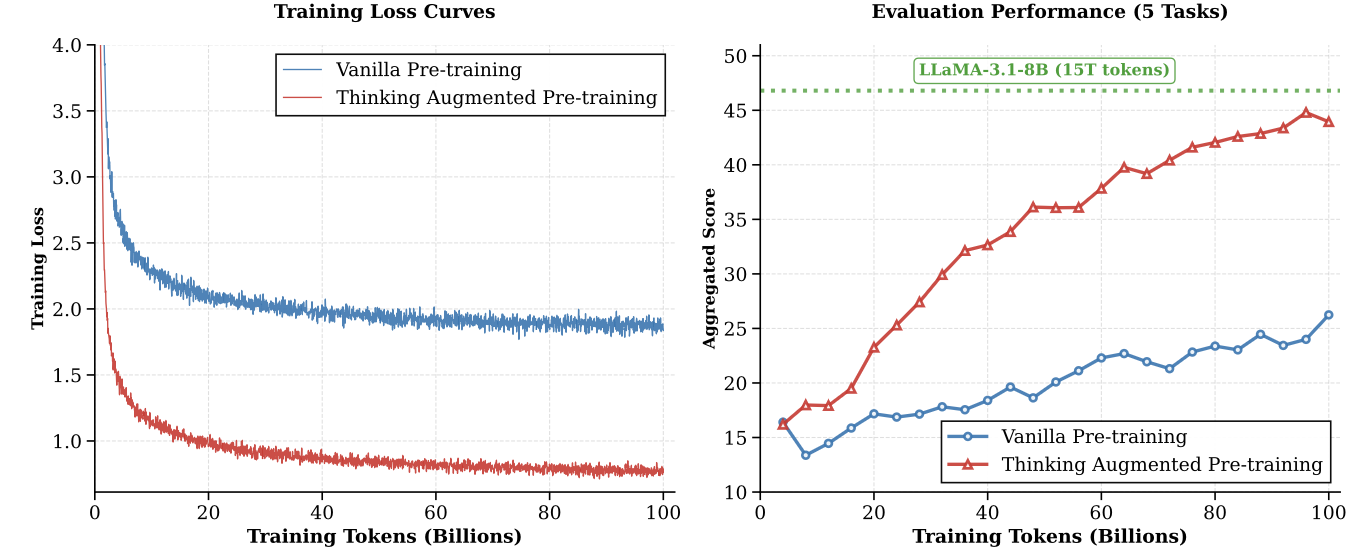
확인해보니까 Qwen3-8B 이용해서 pre-training 단계의 thinking을 만들고
위와 같이 Thinking을 이용한 모델이 기존 학습 방법으로 했을 때 엄청나게 차이가 나는 것을 보여준다.
재밌는건 동일한 token을 학습하기 때문에 기존 모델이 거의 3배 가깝게 더 많은 document를 보았는데도 그렇다.
즉, 1개 1개 샘플에 대한 깊은 이해가 더 중요하다는 것을 보여준다.
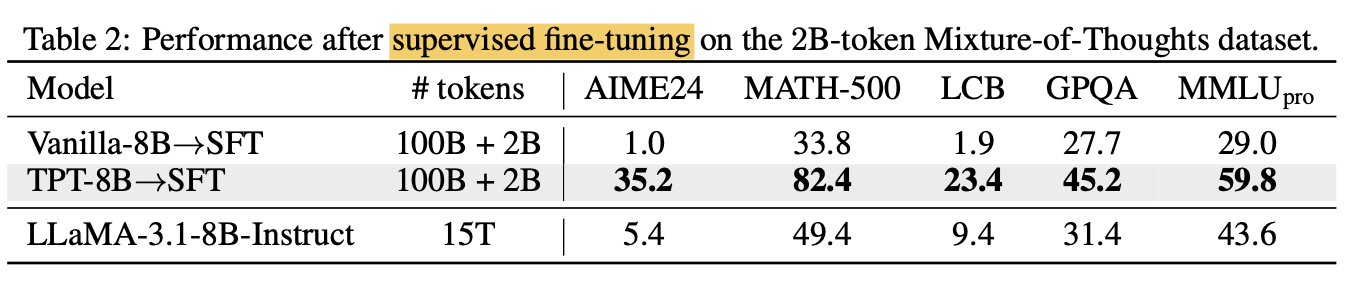 SFT Fine-tuning까지 해서 비교하면 15T 정도로 학습한 모델보다 더 잘하는 성능을 보여준다.
SFT Fine-tuning까지 해서 비교하면 15T 정도로 학습한 모델보다 더 잘하는 성능을 보여준다.
그런데 이간 잡담인데 최근 논문들을 보면 LLaMA4는 쓰는 것을 거의 한번도 못봤다. 진짜 버려진 모델이구나...
3.2 PRE-TRAINING UNDER CONSTRAINED DATA
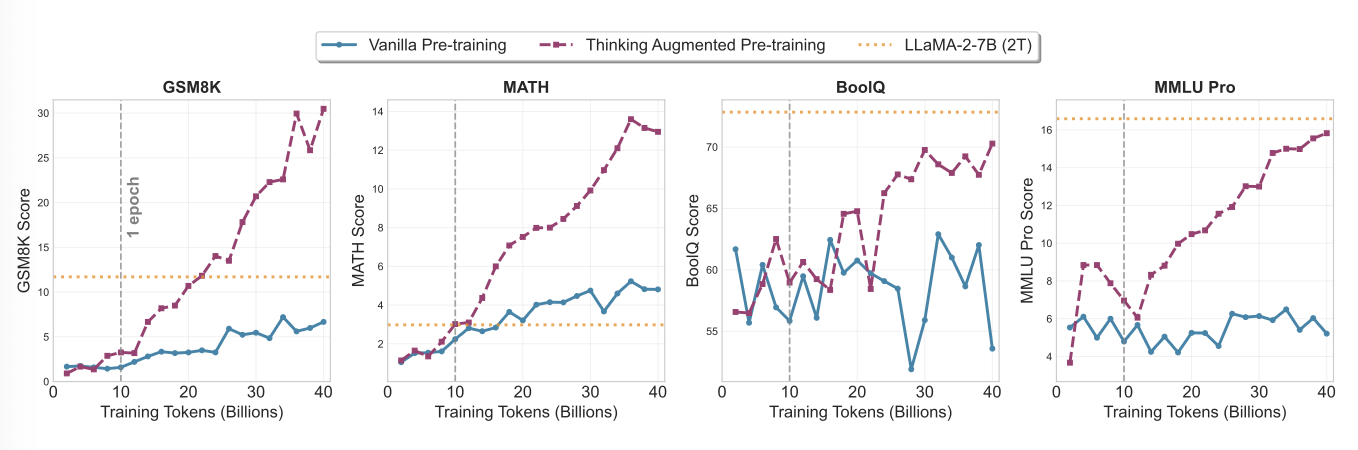
여긴 간단하게 앞에는 데이터 많다고 보고 100B 정도 학습했는데 실제로는 데이터가 적고 학습 compute는 많을 수 있다. 그래서 데이터는 10B고 학습은 40B로 vanilla model은 4epoch 학습하고 augmentation model은 1번만 보는데
이것도 vanilla model은 pleatue하는데 augmentation을 넣는 모델은 잘한다.
3.3 THINKING AUGMENTED MID-TRAINING
이거는 scratch부터 학습하는게 아니라 학습된 모델을 추가로 학습시키는 것이다.
여기서 data augmentation은 DeepSeek-R1-Distill-Qwen-7B model을 이용했다고 한다.
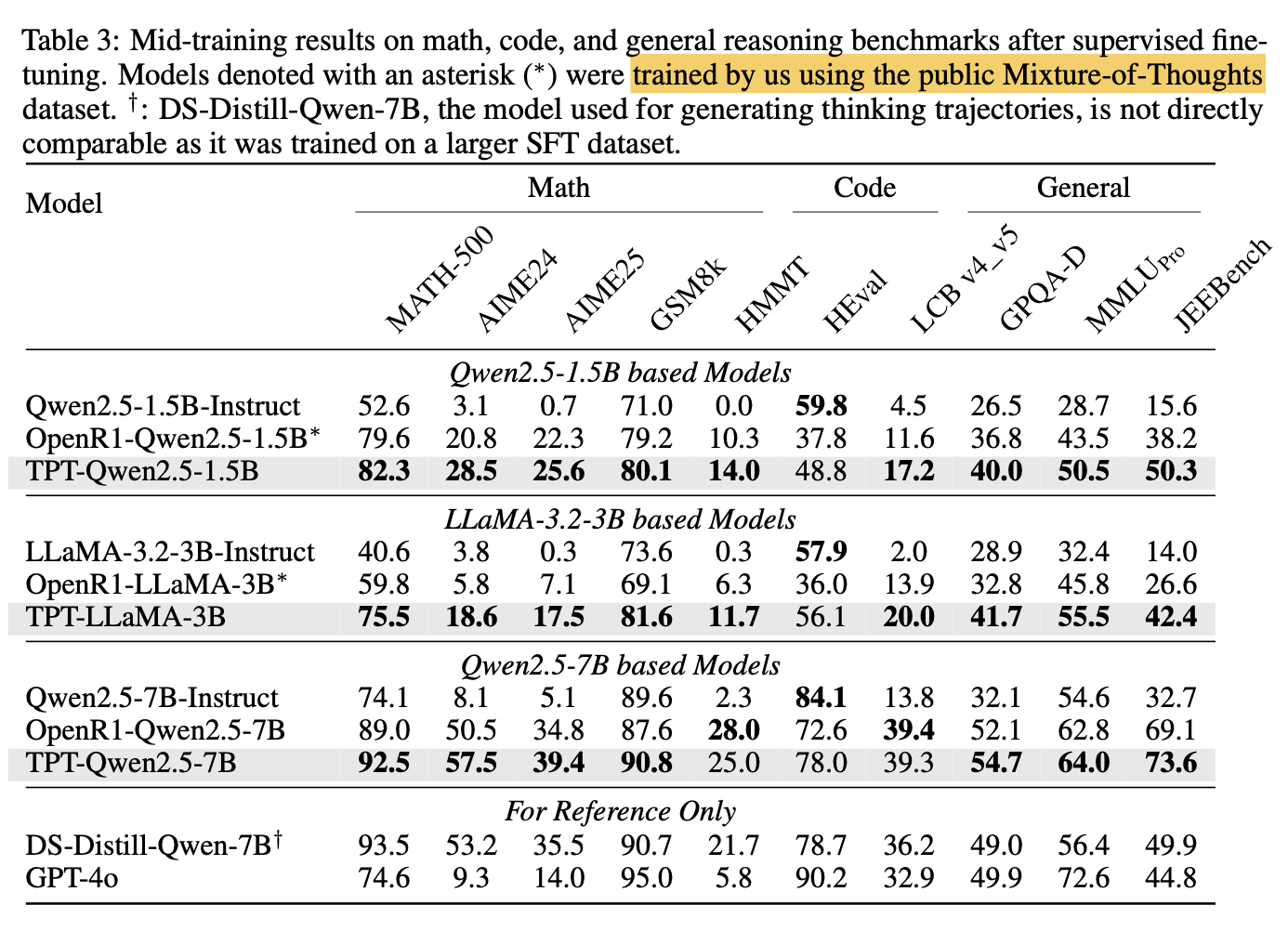
이거는 정확한 데이터 설명이 애매한데
기존 Augment로 생성한 데이터 vs 기존 데이터로 학습한 모델에다가 Mixture of Thoughts 데이터를 SFT로 학습한게 Mixture of expert에도 augment를 했다는지는 모르겠다.
일단은 그대로 사용한 것 같다.
기존 모델보다 더 잘하는 것을 보여주고 심지어 TPT-Qwen2.5-7B의 경오 data generation을 진행한 DS-Distill-Qwen-7B model보다 더 잘한다.
4 ANALYSIS OF THINKING PATTERNS
thinking Generation의 내용을 분석하기 위해서 essential-web-v1.0에서 2만개의 문서를 긁어와서 생성하고 길이를 분석
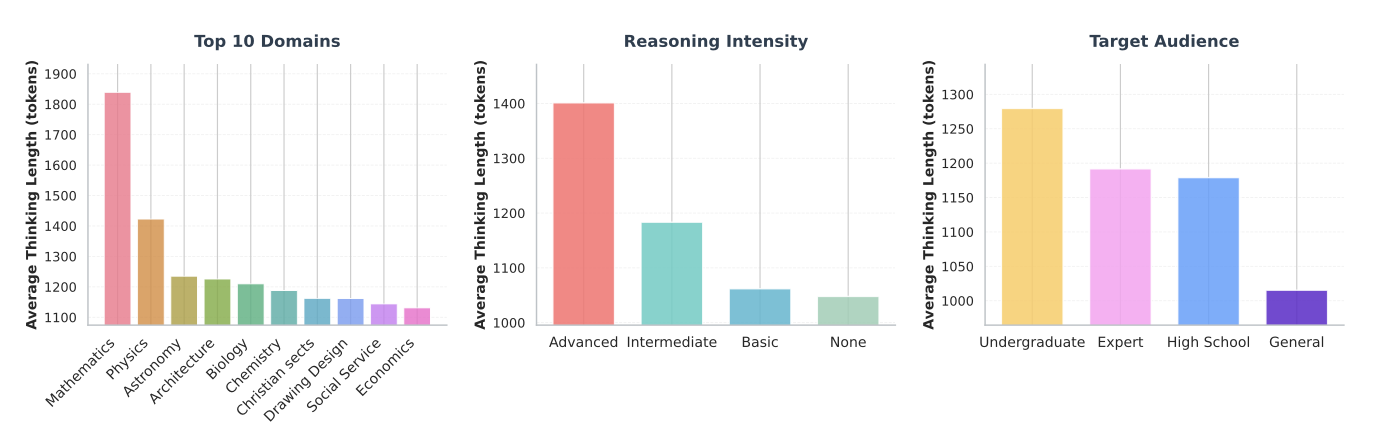
수학, 물리, 천문학 등 어려우면 길이가 매우 길다.
문서에 포함된 추론의 강도가 클수록 길이가 길어지고 target은 재밌게 undergraduate에서 길이가 매우 길고 전문가에서는 약간 낮았다.
5 Ablation Studies
현재 prompting 대신 2가지 대안을 보는데
- Customized Back-thinking Model: 주어진 question과 answer pair를 주고 question에서 answer로 어떻게 갈 수 있을지 생성
- Prompt with Random Focus Point: model에게 random한 point에 focus를 두게 instruction을 준 형태. 다양한 생성이 가능하지 않을까? 하고 진행
기존의 방법이 Back-Thinking과 똑같은거 아니야? 라고 생각했는데 다시 보니까 기존의 방법은 그냥 질문에서 답으로 가는 유도과정이 아니라 내용에 대한 설명 같은 느낌이긴하다.
그래도 거의 비슷해보이긴 한데...
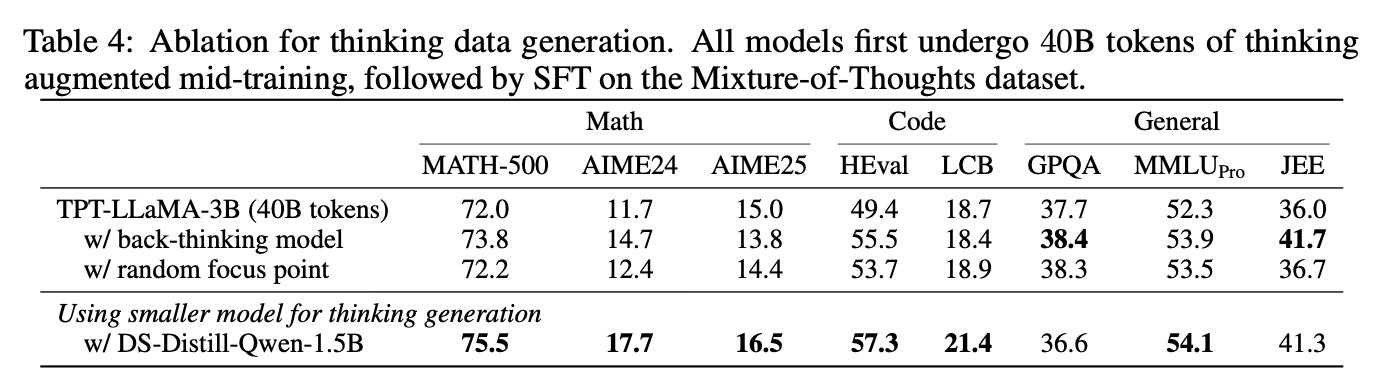 이렇게 진행했을 때 둘 다 약간의 gain이 있다.
이렇게 진행했을 때 둘 다 약간의 gain이 있다.
그런데 위에서 재밌는게 기존의 7B model 대신 1.5B로 smaller model로 generation을 하면 성능이 더 증가한다...?
무슨 다른 연구결과가 있다는데 smaller model이 downstream task 학습하기에 더 좋은 trajectory를 만든다고 한다.
나머지는 크게 중요하지 않아서 생략 데이터, sft 크기 키우면 성능 늘어난다는 이야기다.
