다 읽고 간략하게 리뷰 작성
감상평
최근 인공지능 community에서 transformer를 대체하는게 나왔다고 되게 핫한데 나는 아니라고 생각한다.
애초에 recurrent loop에 transformer의 구조가 들어가기 때문에 대체하는게 아니라 옛날에 EfficientNet과 같이 어떻게 더 효율적으로 사용할 수 있을까 에 더 가깝다고 생각한다.
그러한 측면에서 recurrent하고 adaptive한 구조에 따른 KV caching과 inference trick으로 2배 정도의 token throughput을 만든 것은 흥미롭다.
성능은 hyperparam tuning에 따라 매우 근소한 상승을 보여주는데 상승이 꾸준하지 못하고 이정도의 갭은 hyperparam에 따른 상승 값으로 볼 수 있을 것 같기에 성능보다는 efficiency한 모델로 보는 것이 맞을 것 같다.
Abstract
기존 language model은 scaling을 함으로써 매우 뛰어난 성능을 보임. 하지만 computational, memory 요구량이 매우 과해서 training과 deployment가 비싸다.
기존의 효율적으로 만드는 방법은 recurrent하게 동일한 param을 여러번 재사용해서 param을 줄이는 방법과 adaptive computation을 활용해서 계산량을 줄이는 방법이 있지만 이 두가지 방법 모두 다 적용하는 것은 아직 활발히 연구가 되지 않았다.
이 논문은 이러한 2가지 효율적으로 만드는 방법을 동시에 활용하면서 동시에 KV 캐싱을 통해 뛰어난 inference 속도를 만들면서 뛰어난 성능을 보인다.
Introduction
위에 적은 내용이랑 거의 비슷하다.
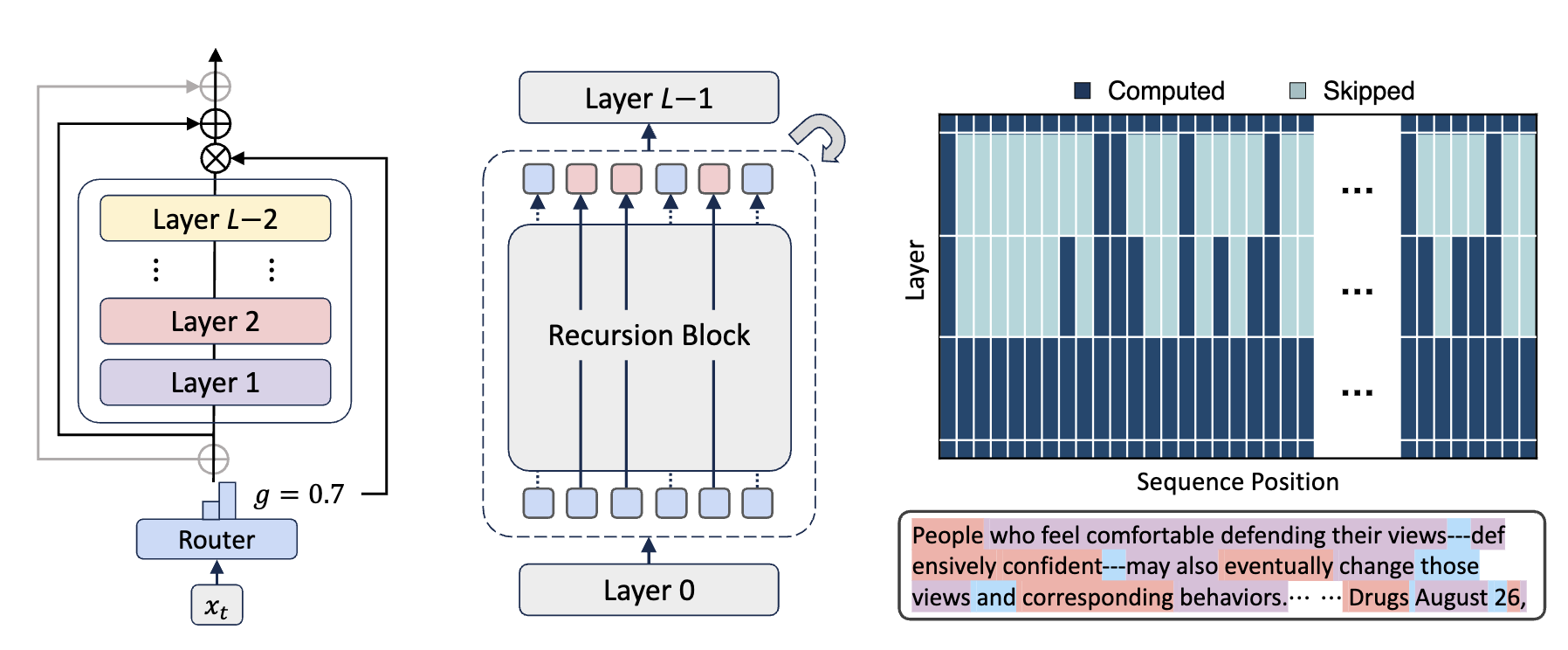 위 그림이 전체 구조인데 간단하게 왼쪽은 Router가 이 layer 묶음을 통과할지 아니면 지나갈지 결정하고 지나가면 gating의 값을 곱해준다. (x모양)
위 그림이 전체 구조인데 간단하게 왼쪽은 Router가 이 layer 묶음을 통과할지 아니면 지나갈지 결정하고 지나가면 gating의 값을 곱해준다. (x모양)
중간은 전체 구조로 왼쪽과 같은 recursion block이 여러번 반복되어 다음 layer로 진행한다.
오른쪽은 실제 돌아가는 computed되는 그림이고 필요한 부분에 더 많은 연산량을 투입한다.
Method
Preliminary
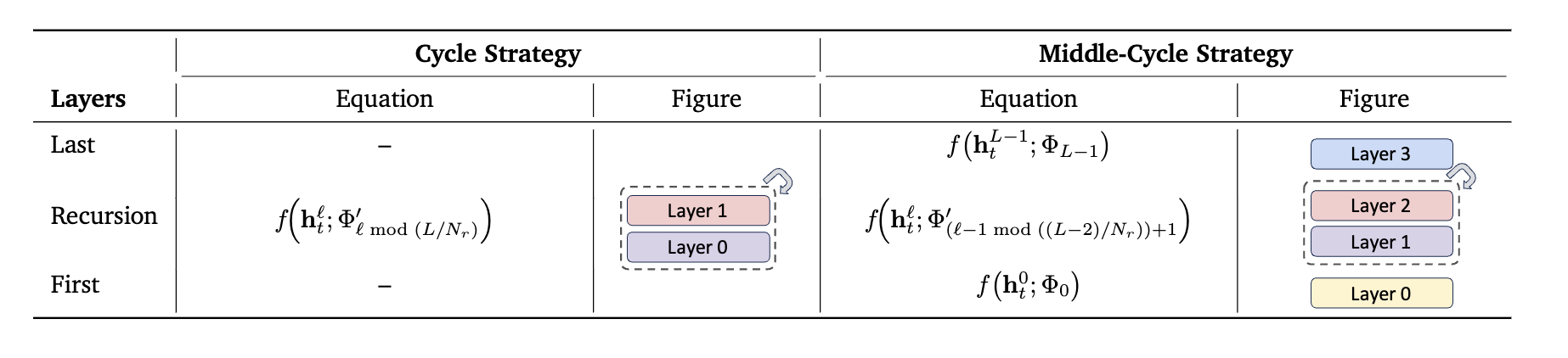 위 내용은 사실 그렇게 중요한건 아닌데 cycle 방법에 따른 차이점인데
위 내용은 사실 그렇게 중요한건 아닌데 cycle 방법에 따른 차이점인데
우선 cycle과 sequence 방법의 차이점을 알아야한다.
9개의 layer를 3번 반복으로 줄인다고 할때
cycle -> [(0,1,2), (0,1,2), (0,1,2)] 즉 전체 layer를 통과하는 것을 3번 반복.
sequence -> [(0,0,0),(1,1,1),(2,2,2)] 즉, 0번째 layer를 3번 돌리고 1번째 layer를 3번 돌리고 ... 이렇게 진행
밑에 내용 읽으면 알겠지만 cycle이 더 잘 작동하는 것으로 보인다.
그리고 위 테이블은 왼쪽은 그냥 cycle, 오른쪽인 Middle-cycle로 첫번째 layer과 마지막 layer는 기존처럼 fixed인데 중간에 cycle layer가 들어간다.
이 middle cycle 구조.
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach 이 논문에서 제시한 구조와 동일하다.
나머지는 크게 중요하지 않아보인다.
Mixture-of-Recursions
여기에서 각각 Routing 방법 2가지, kv caching 2가지 이렇게 제시가 된다.
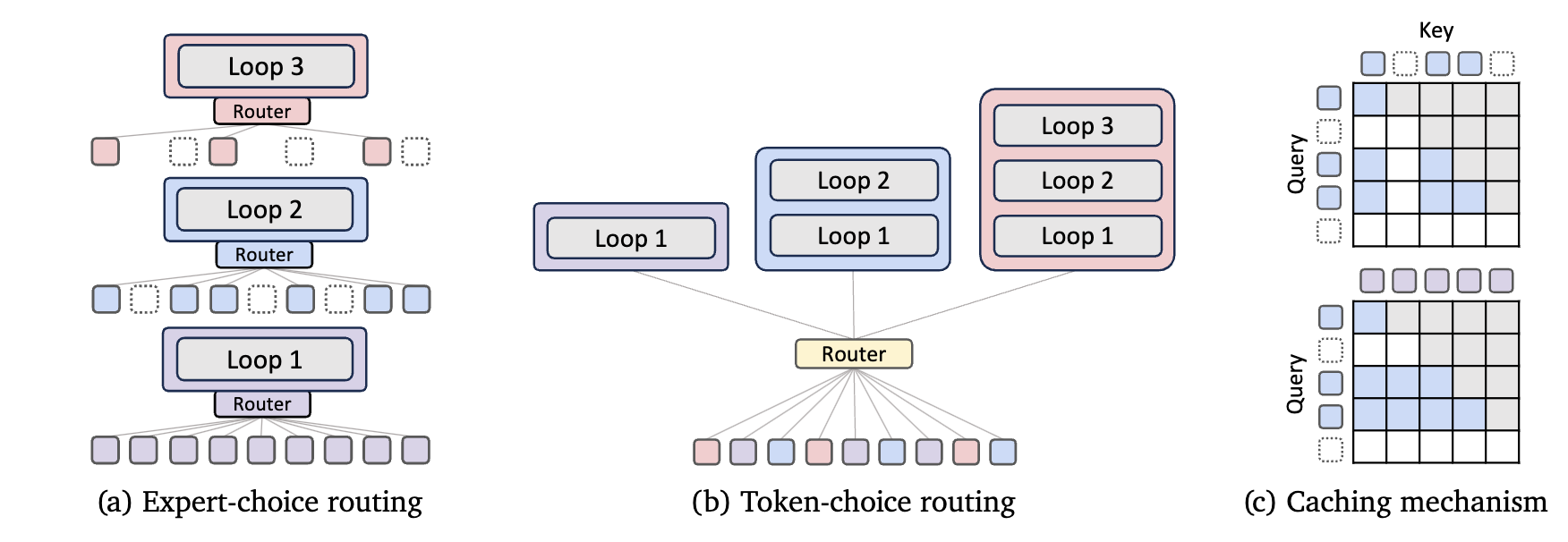
Routing 방법
-
Expert-choice routing: 위 그림처럼 간단하게 내부 recurrent loop가 여러개 있을 때 각 loop마다 어떤 token을 계산할지 고르는 형태. 이때 이전 loop에서 선택된 token만 계산한다.
계산하는 방법은 다음과 같이 로 t번째 token을 r번째 loop에 대한 gating 점수를 구하고 상위 top-K개를 골라서 즉, loop layer를 통과시킨다.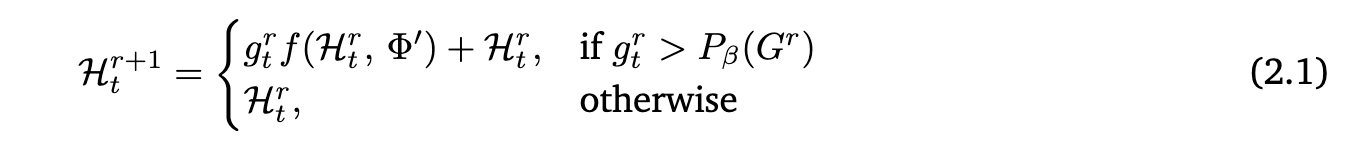
-
Token-choice routing: 이는 loop에 본격적으로 들어가기 전에 모든 token마다 얼마나 loop를 돌릴지 정하고 가는 형태.
각 token에 loop마다 점수를 구하고 가장 점수가 높은 loop만큼 돌린다. 수식은 앞의 수식과 거의 동일한데 신기한건 중간에 skip-connection처럼 더하지를 않고 마지막에만 첫번째 layer의 output 값을 더해준다.
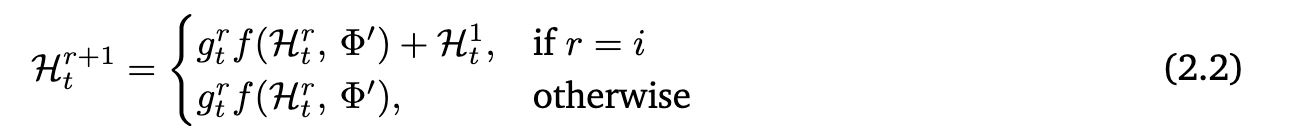
이때 각 방식의 문제점이 있는데
Expert-choice 방식은 training 때 각 token에 topk를 할당시키는데 이는 information leak의 문제가 발생한다.
왜냐하면 training 때에는 전체 sequence를 받기 때문에 어떤 token이 계산이 더 필요하고 어떤게 덜 필요한지 알 수 있지만
inference time에서는 현재까지 생성한 sequence만 보기 때문에 Top-K로 선택하는 token이 미래에 생성이 될 token까지 고려해서 진행되어야 하기 떄문이다.
expert-choice를 막기 위해서 information leak을 방지하는 방법은 논문에서 2가지 제시하는데
보조 router: training 때 사용하는 router말고 inference time에 사용하는 router를 학습하는데 이때 각 token마다 이 token이 선택이 될지 말지를 고려해서 binary cross entropy로 학습이 된다. 그렇기에 전체 token을 보지 않기에 information leak완화 가능
보조 loss: main gating에 binary cross entropy loss를 보조로 넣어준다. 그러면 전체 gating 예측을 0과 1 극단적으로 진행하게 될 것인데 이때 부분적인 sequence를 보고 1이면 고르고 0이면 버리는 식으로 inference time에 활용이 가능하다.
kv caching 방법
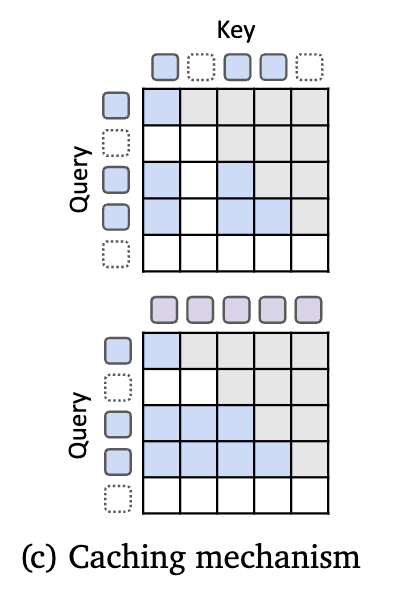 Recursion-wise KV caching: 이 방법은 위에 그림이며 attention이 현재 loop를 도는 token끼리만 진행. 이러면 attention cost와 cache 요구량이 매우 줄어든다.
Recursion-wise KV caching: 이 방법은 위에 그림이며 attention이 현재 loop를 도는 token끼리만 진행. 이러면 attention cost와 cache 요구량이 매우 줄어든다.
Recursive KV sharing: 아래 그림이며 처음에 모든 토큰은 loop를 1번은 돈다. 이때 처음 loop를 돌아서 나온 K, V 값을 저장하고 계속계속 활용하는 방식.
Experiments
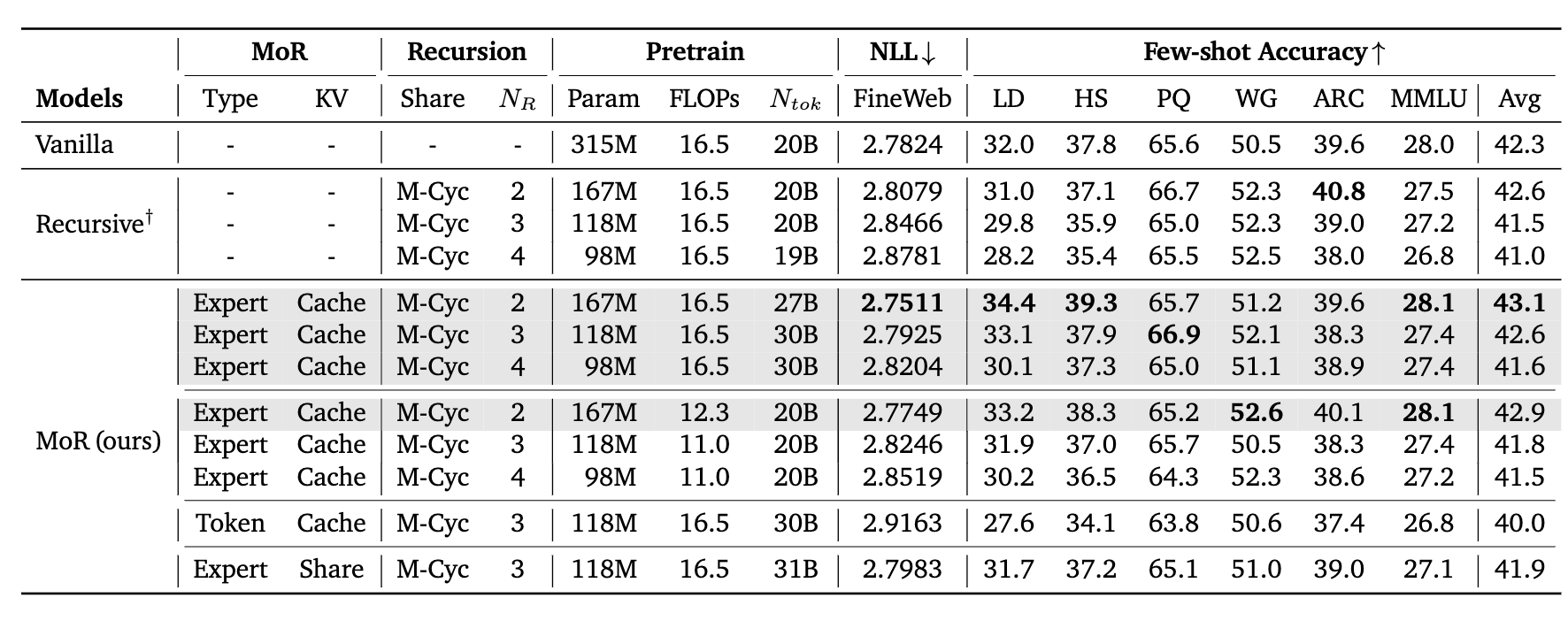
동일한 Flops로 학습하였을 때 naive transformer보다 적은 param으로 더 좋은 점수를 보임.
