Abstract
최근 CNN의 feature 학습 능력이 computer vision 분야를 바꿔놓았다.
그러나 feature을 성공적으로 학습하기 위해서는 label이 된 데이터가 필요한데 이러한 데이터는 매우 비싸다.
그렇기 위해 labeling을 하지 않고 feature을 학습하는 방법론이 급부상하고 있는데
이 논문에서는 회전시킨 2d 이미지를 인식하는 간단한 학습을 통해 모델이 semantic feature을 성공적으로 학습할 수 있음을 보인다.
1. Introduction
최근 진행된 CNN의 도입은 컴퓨터 비전 영역에 많은 진보를 가져왔다.
특히 많은 labeled data를 바탕으로한 vision representation으로 image understanding task에 강했다.
그러나 supervised learning은 매우 비싸고 많은 양의 데이터를 얻기 힘들다.
이에 따라서 annotation free task를 이용해 학습을 진행하는 self-supervised learning을 통해 unlabeled data로 visual representation을 학습시키려는 시도가 많다.
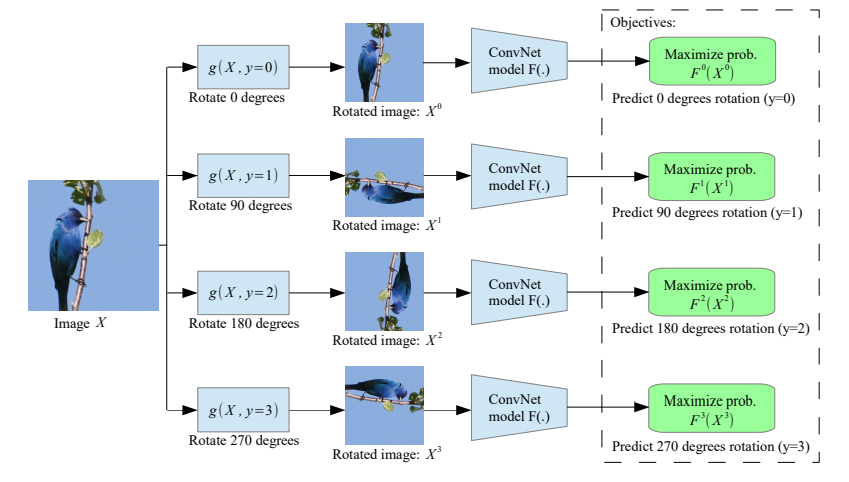
이 논문에서는 이미지의 기하학적 구조의 변경을 알아채게 학습을 하는 방법을 제시하였다.
구체적으로 geometric transform의 set을 만들고 각 이미지에 적용이 되어서 모델의 input으로 들어간다. 그리고 모델은 어떤 transform이 적용이 되었는지 맞춘다.
좋은 학습을 위해서는 이러한 geometric transformation을 잘 정하는 것이 중요하다.
논문에서 제안하는 방법은 이미지를 0도, 90도, 180도 270도 돌린 transform이다.
모델은 4 way classification으로 이미지가 어떻게 회전했는지 예측한다.
 이 과정에서 모델은 이미지가 회전하였는지 알기 위해서 object에 대한 이해가 필요하고 object가 뭔지, 위치가 어디인지, 포즈가 어떤지 학습해야 한다.
이 과정에서 모델은 이미지가 회전하였는지 알기 위해서 object에 대한 이해가 필요하고 object가 뭔지, 위치가 어디인지, 포즈가 어떤지 학습해야 한다.
2. METHODOLOGY
2.1 OVERVIEW
이 ConvNet 모델이라고 할 때 주어진 이미지의 transformation을 예측한다.
이 때 K개의 transformation의 set은
이라고 하자
X에 label y를 가진 transform이 적용이 되면 로 표현이 가능하다.
ConvNet 모델 는 (는 label을 모른다는 뜻)를 input으로 받고 가능한 y의 확률들을 예측하는 것이다.
학습은 이렇게 표현이 되고
loss는 이렇게 구성이 된다.
(앞에 target 부분이 없는데 그냥 cross-entropy라고 생각하면 될 것 같다.)
2.2 CHOOSING GEOMETRIC TRANSFORMATIONS: IMAGE ROTATIONS
위 공식에서 geometric transformation 는 image의 semantic feature을 잘 학습할 수 있는 task여야 한다.
논문에서는 rotation을 제시
에서 이다.
Forcing the learning of semantic features
ConvNet이 이미지의 의미를 이해하지 못하면 rotation을 확인할 수 없다.
결국 rotate를 파악하기 위해서는 object의 위치, type, 이미지에서의 주요한 object 등을 알아야 한다.
이러한 가정을 테스트하기 위해 conv layer의 activation cell의 공간에 따른 값에 따라서(값이 크면 집중 높음) attention map을 만들어보았는데
 ConvNet이 정말로 눈, 코, 입, 꼬리 등 object의 high-level 구조에 집중을 하고 있었다.
ConvNet이 정말로 눈, 코, 입, 꼬리 등 object의 high-level 구조에 집중을 하고 있었다.
또한 alexnet 모델의 first layer의 weight를 실체화 했을 때 다음과 같이 나오는데
 self-supervised learn 모델이 더욱 다채롭고 다양한 edge가 있다.
self-supervised learn 모델이 더욱 다채롭고 다양한 edge가 있다.
Absence of low-level visual artifacts
이미지를 돌리는 것의 또다른 이점은 따로 low-level cue를 찾기 힘들기에 shortcut을 학습하는 것이 힘들다.
반면에 이미지 scaling 등으로 이미지의 비율이 바뀌면 모델이 찾기 너무 쉽다.
Well-posedness
보통 사람이 찍은 이미지의 오브젝트는 똑바로 서있는 방향이다.
그러기에 회전하는 것으로 쉽게 rotation recognition task를 만들 수 있다.
무엇이 회전을 시킨건지 명확하다.
반면에 이미지 scaling을 한것은 무엇이 원본인지 찾기 어렵다.
Implementing image rotations
이미지 rotation을 하기 위해서 이미지를 flip하거나 transpose하였다.
예를들어 90도의 경우 이미지를 transpose하고 수직으로 flip했다
180도의 경우 이미지를 수직, 수평으로 flip하였다.
270도의경우 수직으로 flip하고 transpose하였다.
3. EXPERIMENTAL RESULTS
평가를 위해 CIFAR-10과 ImageNet 데이터를 활용하였다.
transfer learning, semi-supervised learning 등 다양한 가정의 테스트도 진행하였다.
self-supervised rotation learned 모델을 RotNet model이라고 표기하였다.
3.1 CIFAR EXPERIMENTS
이 부분에서 특이했던 것은 각도를 다양하게 나눠서 테스트를 진행해보았는데 그냥 4방향이 제일 좋았다.
- 8방향은 회전하고 가운데 사각형을 자르는 식으로 구현하였다.
 아마 task가 명확하고 충분히 어려운 기준이 4가지인 것 같다.
아마 task가 명확하고 충분히 어려운 기준이 4가지인 것 같다.
또한 데이터를 모든 데이터를 4부분씩 돌려서 학습을 하는 것이 input에 들어갈 때 random으로 돌려서 넣는 것보다 더 결과가 매우 좋았다.
그렇기 때문에 batch size보다 4배 더 많은 이미지가 input에 들어갔다.
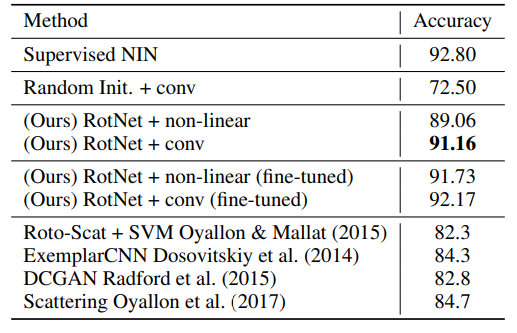
또한 transfer 결과를 보았을 때 supervised로 pretrain한 것과 차이가 거의 없다.
3.2 EVALUATION OF SELF-SUPERVISED FEATURES TRAINED IN IMAGENET
이미지넷 역시 supervised보다는 낮지만 다른 방법보다 매우 높다.
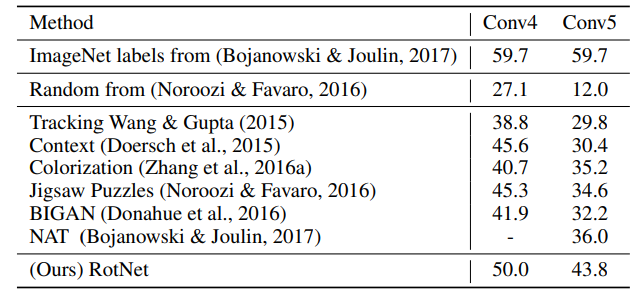
4. conclusion
이 논문에서는 이미지를 돌리는 간단한 방법으로 supervised와 비슷한 성능을 낼 수 있는 pretrain 방법을 제시하였다.
5. 구현
매우 간단하게 구현을 하였다.
모델을 불러오고 projection head를 달고
input을 돌리고 예측하는 학습 진행
class RotNet(nn.Module):
def __init__(self, device, args):
super().__init__()
self.encoder = load_model(args.model, class_num=4)
self.encoder = self.encoder.to(device)
dim_mlp = self.encoder.out.weight.shape[1]
self.encoder.out = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp),
nn.ReLU(),
nn.Linear(dim_mlp, 4),
)
def forward(self, x, _):
# (batch, 3, 32, 32)
with torch.no_grad():
label = torch.zeros(x.size(0) * 4, dtype=torch.long)
for i in range(4):
label[x.size(0) * i:x.size(0) * (i + 1)] = i
label = label.to(x.device)
arr = []
for i in range(4):
arr.append(torch.rot90(x, k=i, dims=(2, 3)))
arr = torch.concat(arr, dim=0)
# (batch*4, 3, 32, 32)
output = self.encoder(arr)
# (batch*4, 4)
return output, label