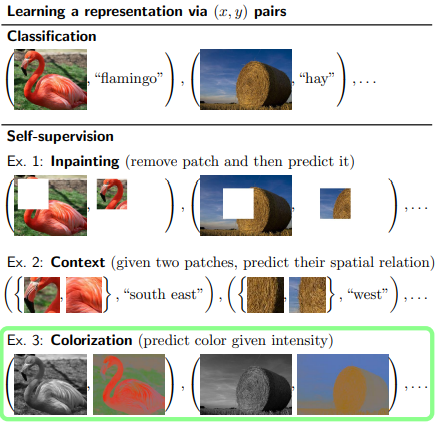
Abstract
이 논문에서는 colorization을 proxy task로 두어서 self-supervised learning을 향상시키는 것에 중점을 두었다.
이미지를 intensity 즉 명도를 주고 색을 예측하게 한다.

1. Introduction
처음에 annotation을 만드는 것이 비쌈을 지적하며 시작한다.
그래서 unsupervised learning 등 여러가지 annotation을 사용하지 않는 방법이 활발하게 연구중이라고 한다.
여기에서 신기했던 부부은
labeled data의 장점은 discriminative loss를 사용하는 것이라고 언급한다. 그리고 discriminative loss는 reconstruction이나 likelihood based loss보다 representation learning에 적합하다고 한다.
그리고 self-supervion은 unlabeled data을 데이터의 부분적인 연관성에 적용해 discriminative loss를 사용하는 방법이라고 언급한다.
실제로 이전 직쏘퍼즐 논문에서 conv layer를 얼리고 학습하는 실험을 통해 self-supervised learning으로 representation을 잘 학습하였다고 언급하였다.
그리고 논문의 주요 주제인
self-supervised colorization을 소개한다.
간단하게 이미지를 명도와 색으로 나누고 색을 예측하는 것이다.
3. Colorization as the target task
- 색깔 채우기가 주 목적인 모델 설명
흑백의 사진의 색채를 자동으로 채우는 모델을 학습하는 연구가 활발하게 진행중이다. 최근의 방법은 CNN 모델을 활용해서 색을 예측하거나 색의 분포를 예측하는 것이다.
분포를 예측하는 모델은 최종 색을 예측하기 전에 color histogram 예측을 진행한다.
이 문단에서는 색상화(colorization) 훈련 방법을 설명하고 있습니다.
특히 미적 감각이 있는 색상을 생성하기 위해 내린 설계 결정을 다시 살펴보고 이러한 결정들이 표현 학습(learning representations)에 미치는 영향을 고려합니다.
3.1 Training
Loss
여기에서는 2가지의 loss를 고려하였는데
- 의 color 값의 regression loss (L:lightness, (a,b): color vector)
- KL divergence for hue/chroma(색상/채도) histogram
뒤의 KL divergence는 7x7의 window로 각 target pixel에서 계산하고 색상과 채도에 대해서 32개의 bin으로 나눈다.
이 부분이 잘 이해가 가지 않았는데 histogram의 bin을 보고 이해가 갔다.
bin은 histogram의 막대이다. 즉 32는 나누는 구간의 개수이다.
1개의 pixel에 대해서 7x7의 윈도우 주변의 값들을 histogram을 32구간으로 나눠서 구하고 쫙 펴서 각 분포에 대해서 KL divergence를 진행하는 것이다.
여기에서 우리는 colorization을 하는 능력이 아니라 representation을 학습하는 능력만 평가한다.
그렇기 때문에 loss는 적절하게 조절되어야 한다.
Training
학습
- SGD
- momentum 0.9
- Xavier initialization
- batch normalization (without re biasing, re scaling)
- image randomly mirrored, randomly scaled
- colorization 3 epoch
4. Colorization as a proxy task
- 색깔 채우기 모델을 이용한 pre-train
이제 colorization model을 visual representation에 활용하는 것으로 변경해보자.
4.1 Training
downstream task는 colorization from scratch network로 부터 학습이 되었다.
즉 위에서 color을 학습한 모델로 학습
중요한 consideration
Early stopping.
train 데이터를 90/10으로 나누고 10%는 validation으로 overfitting을 확인.
validation loss가 줄지 않으면 lr을 줄인다. -> 2번 반복후 학습 종료
Receptive field.
이전에 semantic segmentation에서 receptive field의 중요성을 보여준 논문이 많다.
이를 위해서 dilated conv를 적용하는게 가능하지만 filter를 다시 학습하기 어렵기 때문에 2개의 block(2,2 max pooling, 3x3 conv with 1024 feature)을 마지막에 추가해서 receptive field를 늘렸다.
5. Results
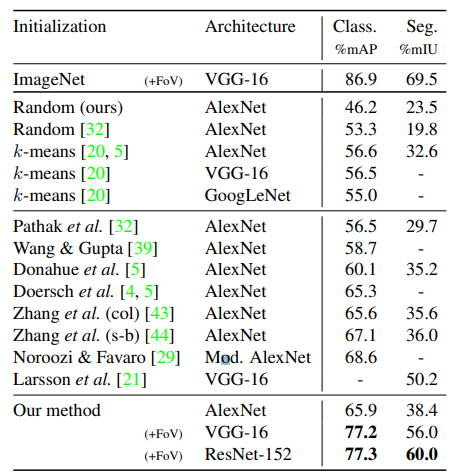 다른 initialization 방법들과 비교한 결과
다른 initialization 방법들과 비교한 결과
supervised pretraining(아마 제일 위)이 아닌 결과 중에서 가장 높은 성능을 보였다. Segmentation에서 38.4%의 성능 역시 다른 AlexNet model 중에서 가장 좋은 성능이다.
