참고
- https://talktato.tistory.com/15
- https://velog.io/@im_ngooh/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-Pointpillars-Fast-Encoders-for-Object-Detection-from-Point-Clouds
논문
https://arxiv.org/pdf/1812.05784.pdf
Abstract
- Point cloud를 vertical하게 encoding하여 사용한다.
- 3D에서 2D로 바뀌게 되어 2D Convolution으로 연산을 할 수 있어 연산량이 많이 줄어 속도가 빠르다.
Introduction
- CV분야가 매우 발전함에 따라, object detection 기술을 lidar point cloud에 얼마나 적용할 수 있는지에 대한 연구가 계속 진행되어왔다.
- 이미지와 point cloud간의 큰 차이는 1. image는 dense하고, point cloud는 sparse 하다는 것과 2. image는 2d이고, point cloud는 3d라는 것이다.
- 따라서 일반적인 image convolutional pipeline만으로는 point cloud에서의 object detection을 잘 해낼 수 없다.
- 그래서 몇몇의 연구들은 point colud의 image로의 projection 또는 3D Convolution의 사용에 집중했다.
- 최근의 방법들은 point cloud를 Bird’s Eye view에서 바라보는 방법을 많이 사용한다. 이러한 방법은 물체의 scale 정보를 유지시켜주고, occlusion을 감소시킨다는 장점이 있다.
그러나, 이러한 BEV를 CNN에 직접 사용하기에는 너무 sparse하여 효과적이지 않다. - 이 문제에 대한 해결으로써, ground plane을 regular grid로 나누어 각각의 gird에 hand crafted feature encoding을 진행하는 방법도 고안되었으나, 일반화되기 쉽지 않다는 단점이 있다.
- VoxelNet은 3d object detection 분야의 첫 end to end 모델로, 공간은 voxel로 나누고, 각각의 voxel에 PointNet을 적용하여 feature encoding을 한 후, 3d convolutional middle layer를 지난 후 RPN을 적용해 3d detection을 진행한다.
- 이는 성능은 좋지만, real time detection에 사용하기에는 너무 느리다.
- 최근에는 SECOND가 등장하여 속도를 올렸으나, 여전히 3D convolution을 사용하기에 느린 점이 있다.
3d detection 분야의 발전 현황. 일반적인 image와 달리 3d이며 sparse 하다는 특징이 존재하여, 여러 방법 중 BEV와 3D Convolution을 사용하는 방법이 사용되고 있다. 최근 VoxelNet의 등장으로 end to end model이 등장하였고, SECOND가 속도를 많이 향상시켰으나 이는 여전히 real time task에 적용하기에 매우 느리다.(3D Convolution 때문)
- 이 논문은 2D convolutional layer만 가지고 3d object detection 을 진행하는 end-to-end 학습 모델인 PointPillars를 제안한다.
- PointPillars는 vertical column인 pillar로 공간을 나누고, 이 pillar를 통해 feature를 학습하여 3d oriented box를 예측하는 새로운 형식의 인코더이다.
- PointPillars는, fixed encoder를 사용하지 않고 pillar를 학습하여 feature encoding을 진행함으로써, pointcloud에 표현된 전체 정보를 활용할 수 있다.
- voxel이 아니라 pillar를 사용함으로써, vertical direction을 직접 나누어주지(binning) 않아도 된다.
- pillars는 2D convolution에 사용될 수 있기 때문에 매우 빠르고 효율적이다.
- PointPillars는 KITTI Dataset에 대해 3D, BEV에서 모두 최고 성능을 내었다.
PointPillars의 특징 및 장점에 대해 이야기하고 있다. 1. PointPillars는 공간을 Pillar로 나누어 이로부터 특징을 학습하는 새로운 인코더이다. 2. 이는 vertical binning을 직접 진행하지 않아도 되고, 2D Convolution에 활용할 수 있어 매우 빠르고 효율적이다.
Conclusion
- 이 논문에서는 Point Cloud에 사용될 수 있는 end to end deep network이자 encoder인 PointPillars를 제안하였습니다.
- KITTI dataset에서 기존 모델에 비해 가장 좋은 성능과 가장 빠른 속도를 보였다.
PointPillars
1. Prior knowledge
- SSD(Single Shot Detector)
- VoxelNet
- Deconvolution(upsampling)
2. Network
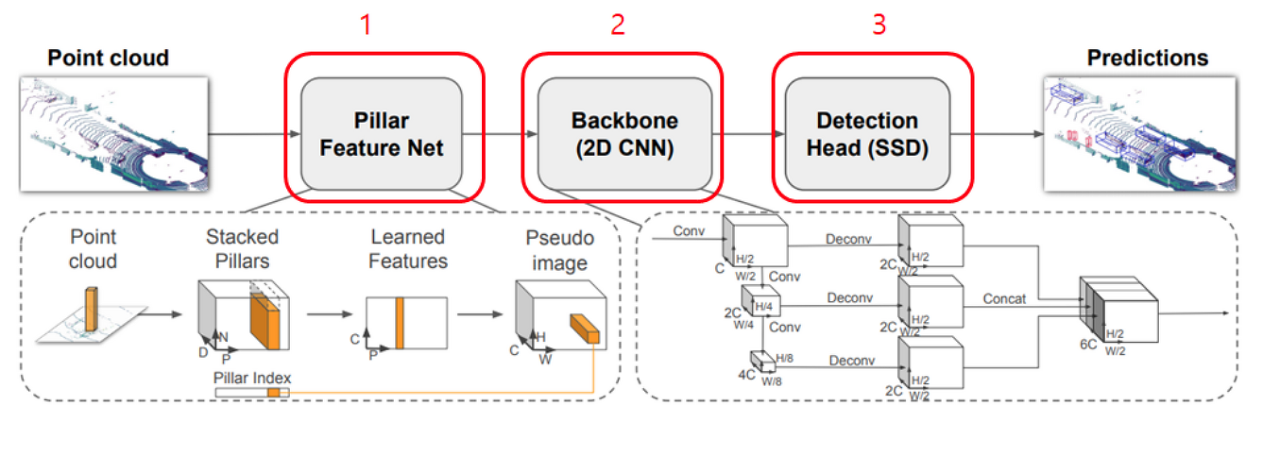
2.1. Pillar Feature Net (Pointcloud to Pseudo-image)
2D Convolution 연산을 위해 pseudo-image로 point cloud를 변환하는 feature encoder network이다.
Point cloud -> Stacked Pillars
-
point cloud → l = (x, y, z, r) , (r은 reflectance, 반사된 빛의 강도) 좌표로 구성되고 이를 pillars로 변환할 때는 z 축에 대한 limit가 없기 때문에 hyper parameter가 필요가 없다.
-
(D, P, N)의 사이즈 tensor로 encoding 된다.
D → pillar의 coordinate
P → 샘플 당 non-empty pillar의 개수
N →pillar 당 point의 개수 -
pillar → (x, y, z, r, x_c, y_c, z_c, x_p, y_p) → 9 dimension으로 encoding 된다.
c는 pillar 안의 모든 point들의 arithmetic mean(산술평균)이다.
p는 pillar의 중심 좌표 x, y -
pillar의 대부분은 비어있는 상태이다.
(Voxel과 마찬가지인 상태, sparse 한 특성 때문이다.) -
sample or pillar에 너무 많은 data가 있을 땐 Random Sampling을 진행하고 적을 땐 Zero Padding을 진행한다.
-
Batch Norm과 ReLU를 지나서 최종적으로 (C, P, N) size의 tensor를 생성한다.
그 이후 channel에 대해 max pooling을 이용해 (C, P) size tensor를 생성한다. -
Encoding을 한 후에 original pillar의 위치로 feature들을 돌려놓아 (C, H, W)의 pseudo-image를 생성한다.
2.2. Backbone(2D CNN)
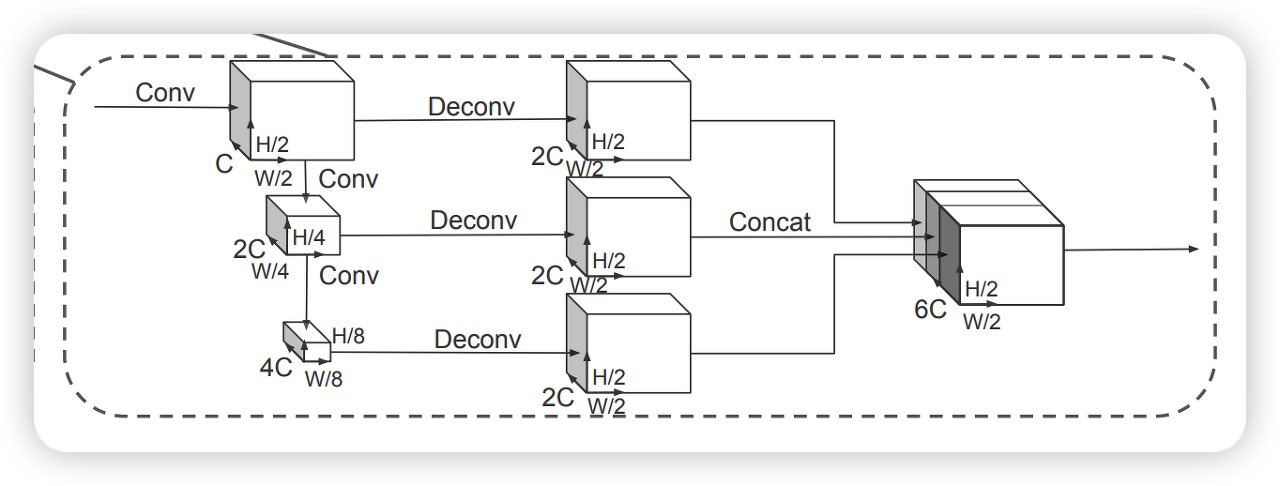
- pseudo-image를 high-level representation으로 바꿔주는 2D conv network이다.
- VoxelNet에서와 유사하게 여러개의 2D conv block을 지나고, 각각의 block을 deconv하여 high resolution feature들의 concatenate feature를 얻는다.
- backbone은 두 가지 sub-network로 이루어진다.
2.2.1 Top-down Network
- 여러개의 (S, L, F) Block들로 이루어져 있는데, 각각의 블록에서는 S크기의 stride를 하고, L개의 3x3 2D conv layer를 지나며, BN과 ReLU를 포함하는 F크기의 output channel을 가진다.
- Block layer의 첫 번째 conv만 S/Sin의 stride를 가지며 그 후 conv들은 stride 1을 가진다.
2.2.2 Deconvolutional Network
- 각각의 top-down block의 feature들을 upsampling하고 concatenate하여 final feature를 얻어낸다.
- 이는 transposed 2D convolution, BN, ReLU를 통해 진행된다.
- 결국 final output feature는 서로 다른 stride를 통해 얻어진 모든 feature들의 종합이다.
2.3. Detection Head(SSD)
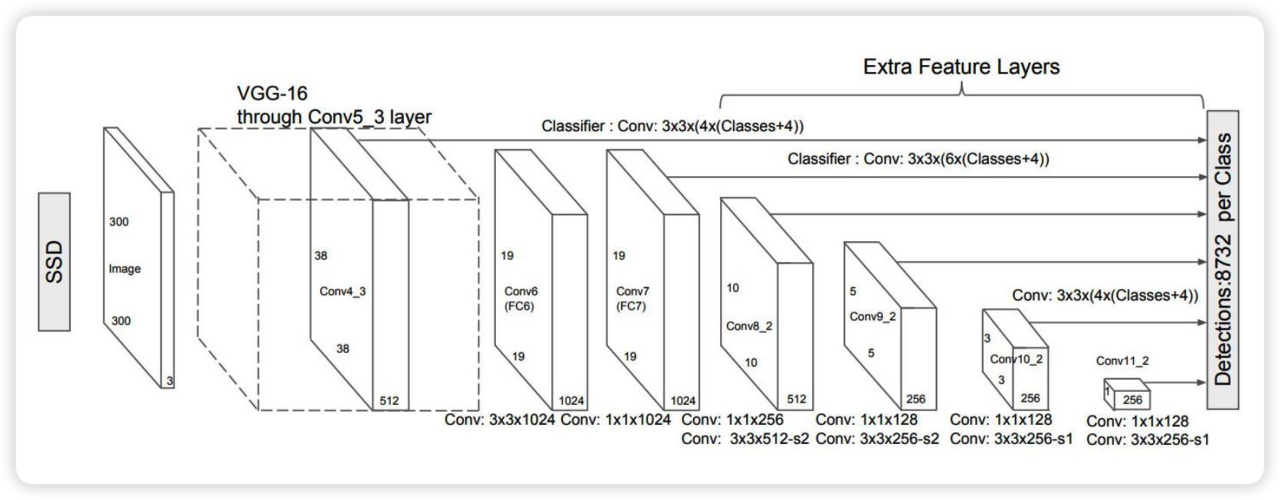
3D bounding box를 regression하는 부분이다.
- single stage detector인 Single Shot Detector(SSD)를 사용한다.
- 3D Detection에 사용하기 위해 height와 elevation을 추가로 regression한다.
