
논문
https://arxiv.org/pdf/1812.07179.pdf
깃허브
Abstract
- 비교적 저렴한 센서인 카메라는 깊이 정보의 부재로 인해서 3D object detection시에 낮은 정확도를 가집니다. 하지만 이 논문은 낮은 정확도의 원인을 카메라의 depth정보의 부재가 아닌 depth의 representation의 문제라고 주장합니다.
- Image로 depth map을 만든 뒤 이것으로부터 Pseudo-LiDAR 신호와 비슷하게 data를 생성하여 기존과 다른 representation으로 3D object detection을 진행합니다.
- KITTI dataset에서 평가되었고 SOTA 성능을 냈습니다.
Introduction
문제제기
현존하는 3D object detection 알고리즘은 크게 LiDAR(Lidar Detection and Ranging) 에 의존하는데 그 이유는 3차원 데이터를 정확하게 추출하기 때문입니다. 비록 Detection 정확도 측면에서는 LiDAR를 쓰는 것이 적합 하나 여러가지 이유로 이 방식을 대체하기를 원하고 있습니다.
- LiDAR의 가격
- 하나의 장비에 지나치게 의존하며 생기는 안정성 문제
따라서 광학 카메라(monocular 또는 stereo)를 통한 이미지 기반 데이터를 이용하는 것이 필요하다고 할 수 있습니다.
기존 연구
-
기존의 연구들에서 3D Object detection을 위해서 monocular depth estimation이나 stereo disparity estimation을 사용하는 경우가 있었습니다. 그러나 이러한 방법은 LiDAR-based에 비해 낮은 성능을 가지고 있습니다.
-
LiDAR-based model과의 성능 차이에 대한 분석 중 가장 많이 언급되는 이유로 image-based depth estimation의 경우엔 예측된 depth의 정확도가 낮아서 생기는 차이 때문이라는 이유가 있습니다.
저자의 주장
-
그러나 이 논문에서 저자들은 stereo 이미지 데이터, LiDAR를 사용한 3D object detection 성능 차이가 depth estimation에서의 불일치가 아닌 ConvNet-based 3D object detection 알고리즘(stereo-based)에서 적용되는 3D 데이터들의 불완전한 표현방식이라고 주장하고 있습니다.
-
이것을 평가하기 위하여 stereo-based 3D object detection에 두 단계의 접근방식을 사용하였습니다.
-
Stereo 혹은 monocular 카메라로 수집된 이미지의 depth map으로 부터 3D point cloud 데이터로 변환합니다. 이것을 peudo-LiDAR라고 부르겠습니다. LiDAR와 유사한 방식의 데이터로 모사하기 위해서 입니다.
-
변환 된 데이터에 LiDAR 기반의 3D Object detection를 적용합니다. 이렇게 3D depth 정보를 pseudo-LiDAR 데이터로 변환하면서 이미지 기반의 3D object detection 알고리즘 성능이 높아졌음을 주장합니다.
Contribution
- Camera를 통해 얻은 stereo image기반의 3D object detection과 LiDAR를 통해 얻은 PCD기반의 3D object detection간의 성능차이의 중요한 원인이 무엇인지 실험을 통해 밝혔습니다.
- Pseudo-LiDAR 방식의 데이터 표현을 도입하여 stereo-based 3D object detection의 성능을 향상시켰습니다.
Conclusion
- 본 논문에서는 이미지와 LiDAR 기반의 3D 객체 검출 간의 간극을 줄이는 핵심 요소는 3D 정보의 표현일 수 있다는 것을 보여줍니다. 새로운 알고리즘을 도입하지 않아도 비효율성을 수정함으로써 훨씬 나은 결과를 얻을 수 있습니다.
- 이미지 기반의 3D Object Detection이 발전함으로 인해 비싼 LiDAR의 중요성이 상대적으로 작아질 수 있습니다. 또는 LiDAR의 백업으로써 기능을 톡톡히 해낼 수 있을 것 입니다.
- 이미지의 해상도가 높아진다면 더 효과적인 detection을 할 수 있을 것 입니다.
- 미래에는 LiDAR와 pseudo-LiDAR가 서로 융합하여 보완하며 더 나은 결과를 얻을 수 있을 것 입니다.
Pseudo-LiDAR
이차원 이미지의 깊이 정보를 사용하여 3D 포인트 클라우드를 생성하는 방법
Related Work & Prior Knowledge
- monocular depth estimation & stereo disparity estimation
- Point cloud
- Image-based 3D object detection
- Epipolar Geometry
- triangulation
- horizontal focal length(수평 초점 거리)
Approach
Depth Estimation
https://darkpgmr.tistory.com/83
거리측정이 가능한 별도의 센서가 없이 영상만을 이용해 주변환경을 인지하기 위해선 Depth Estimation 과정이 필수적으로 수행되어야 합니다. 카메라가 2개가 있을때 카메라의 위치가 다르기 때문에 같은 물체를 관찰함에도 불구하고 이미지에 시차(Disparity)가 발생합니다. 이 Disparity는 거리에 따라 달라지기 때문에 거리를 역산할 수 있게 됩니다.
Stereo Disparity Algorithm
스테레오 이미지 쌍(일반적으로 왼쪽 이미지와 오른쪽 이미지)에서 깊이 정보(D)를 추출하기 위해 사용되는 알고리즘입니다. 두 이미지 간의 각 픽셀 위치의 차이(Disparity)를 계산하여 상대적인 깊이 정보를 나타낼 수 있습니다.
두 카메라 간의 수평적인 위치의 차이(수평 오프셋)이 b인 카메라 쌍에서 촬영한 왼쪽과 오른쪽 이미지 쌍 을 얻습니다.
두 이미지간의 픽셀 또는 패치 간의 차이(Disparity Map)인 와 (수평 오프셋), (왼쪽 카메라의 수평 초점 거리)의 연산을 통해 깊이 정보 를 알아낼 수 있습니다.
- : pixel coordinate
- : depth map
- : disparsity map
- : horizontal focal length
- : horizontal offset
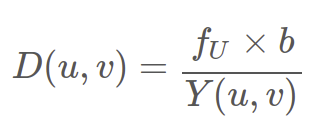
알고리즘에 대한 추가 설명을 해보자면,
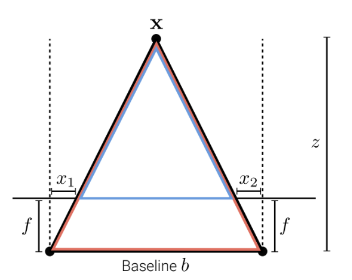
위 그림에서 (disparsity map)에 해당하는 것이 이고, 라는 삼각형의 닮음 비로 = 가 도출됩니다.
Pseudo-LiDAR Generation
Image에서 깊이 정보를 사용하여 pseudo-LiDAR 신호를 생성하는 방법을 설명하고 있습니다. 깊이 정보를 추가 channel로 사용하여 각 픽셀의 3D위치를 결정하는 방법을 제시하고 있습니다.

-
깊이(Depth) : 이미지에서 특정 픽셀 의 깊이는 로 주어집니다.
-
너비(Width) : 좌표는 이미지의 특정 픽셀 의 값과 카메라 중심에 해당하는 픽셀 위치 와의 차이, 그리고 수평 초점 거리 를 사용하여 계산됩니다.
-
높이(Height) : 좌표는 이미지의 특정 픽셀 의 값과 카메라 중심에 해당하는 픽셀 위치 와의 차이, 그리고 수직 초점 거리 를 사용하여 계산됩니다.
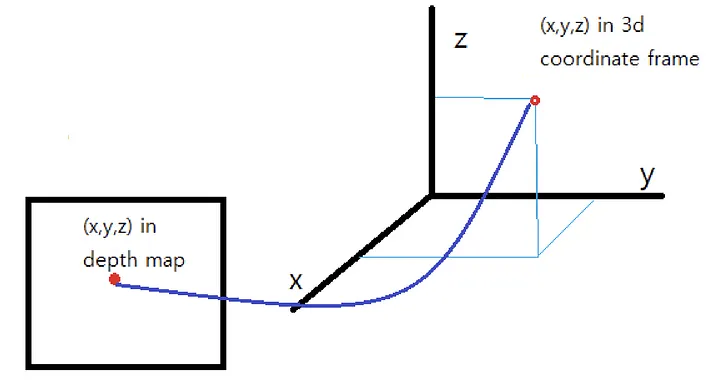
이러한 계산을 통해 모든 픽셀을 3D 좌표로 역투영하여 (N)개의 픽셀에 대한 3D 포인트 클라우드 를 생성할 수 있습니다. 이 때, (N)은 픽셀 수를 나타냅니다.
위 과정을 통해 생성된 Point Cloud를 pseudo-LiDAR signal라고 합니다.
LiDAR vs. Pseudo-LiDAR
LiDAR와 pseudo-LiDAR의 특성과 차이, 상호 작용 방식에 대한 설명입니다.
pseudo-LiDAR는 stereo image를 가지고 특정 알고리즘을 통해 깊이 정보를 추출하고, 그걸 기반으로 3D좌표를 얻습니다. 말 그대로 pseudo(가상)의 데이터를 생성하는 것이죠.
본 논문에서는 기존 LiDAR탐지 기법과 최대한 호환되도록 하기 위해, pseudo-LiDAR데이터에 몇 가지 추가적인 후처리 단계를 적용합니다.
실제 LiDAR 신호는 특정 높이 범위에서만 나타나기 때문에, 그 범위를 벗어나는 pseudo-LiDAR 점들은 무시합니다. 예를 들어 가상의 LiDAR 소스에서 1m 높이 이상의 모든 점들을 제거합니다. 따라서 관심 대상인 대부분의 객체(ex: 자동차와 보행자)가 있는 부분에만 집중해 정보 손실을 최소화할 수 있습니다.
라이다 센서 이미지와 이미지 정보가 서로 좋은 영향을 끼칠 수 있습니다.
- LiDAR data로 학습했다면, Image based classifier로 fine tuning할 수 있습니다.
- LiDAR 센서가 오작동한다면, Image기반 알고리즘으로 보완이 가능합니다.
3D Object Detection
stereo/monocular image를 이용해 Depth map을 추출해 pseudo-LiDAR Point cloud를 만들었다면, 기존에 있는 3D Object Detector를 사용하여 작업을 수행할 수 있습니다.

논문에선 작업을 수행하기 위해 multimodal(monocular images + LiDAR 등)정보를 고려하였는데 이것은 실제 visual 정보와 pseudo-LiDAR 데이터를 결합하는 관점에서 자연스러운 판단이라고 생각해서였습니다.
3D object detection을 수행하기 위해 1)Frustum PointNet, 2)AVOD(Aggregate View Object Detection)를 3D Object Detector로 선택하였고, 각각의 경우를 나누어 실험을 진행하였습니다.
1) AVOD(Aggregate View Object Detection)
Pseudo-LiDAR 데이터로부터 BEV(Bird's Eye View)관점으로 정보를 표현하였습니다. 3D 정보들이 2D image로 변환되며 width와 depth는 이미지의 spatial dimension이, height는 image의 색상의 채널공간이 변환됩니다.
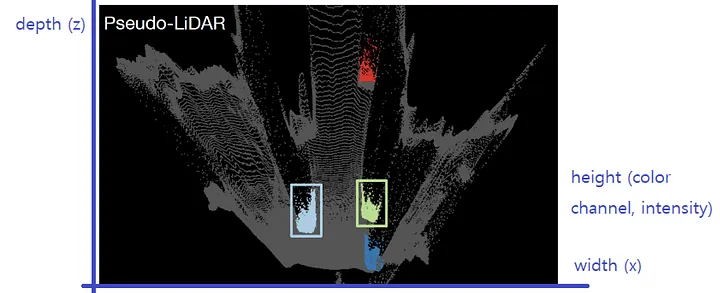
2) Frustum PointNet
pseudo-LiDAR 데이터를 3D point cloud로 다루었습니다. 여기서 frustum PointNet 방식은 2D object detection을 3D 상의 frustum으로 사영(projection) 한 다음, 각각의 3D frustum에서 point-set를 추출하기 위하여 PointNet를 적용합니다.
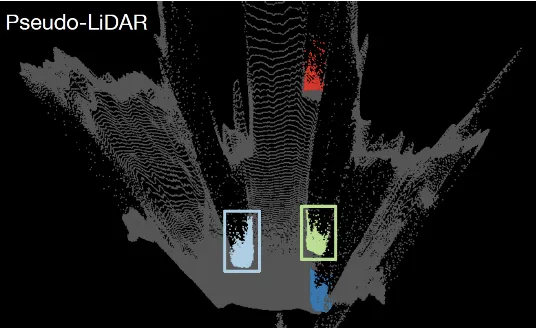
Data Representation Matters
Image를 통해서 3D Object Detection을 할 때 이미지와 같은 2D data를 기반으로 하는 것 보다 Point cloud를 만든 후 이러한 3D data를 기반으로 하는 것이 더 적합한 이유에 대해 설명하겠습니다.
2D 데이터를 기반으로 하면
-
2D image의 3D 세계를 2D 평면에 투영하는 과정에서 여러 객체가 겹치거나 멀리있는 객체가 작게, 가까운 객체가 크게 나타나는 등의 왜곡이 발생할 수 있습니다.
-
Convolution연산을 할 때 이러한 왜곡이 같은 patch내에 있는 픽셀들 사이에서 일어난다면 실제 세계와 맞지 않는 결과를 만들어낼 수 있습니다. Point cloud 같은 3D data로 표현하는 것이 실제 세계의 구조와 더 잘 일치합니다.
이와 대조적으로 point cloud 데이터(3D points) 에 3D convolution을 적용하거나 birds’s-eye view slices(BEV, 2D points)의 pixel에 2D convolution를 적용하는 경우는 실제 물리적으로 픽셀 영역이 가까운 부분들입니다. 따라서 이러한 경우의 operation들은 실제 물리적으로 의미가 있고 학습이 더 잘 되거나 정확한 모델을 구성할 수 있습니다. 이러한 점을 확인하기 위해서 그림 3(Figure 3) 과 같은 상황을 가정해서 실험을 진행 하였습니다. 즉 depth-map에 직접 2d convolution 을 적용해 본 것 입니다.
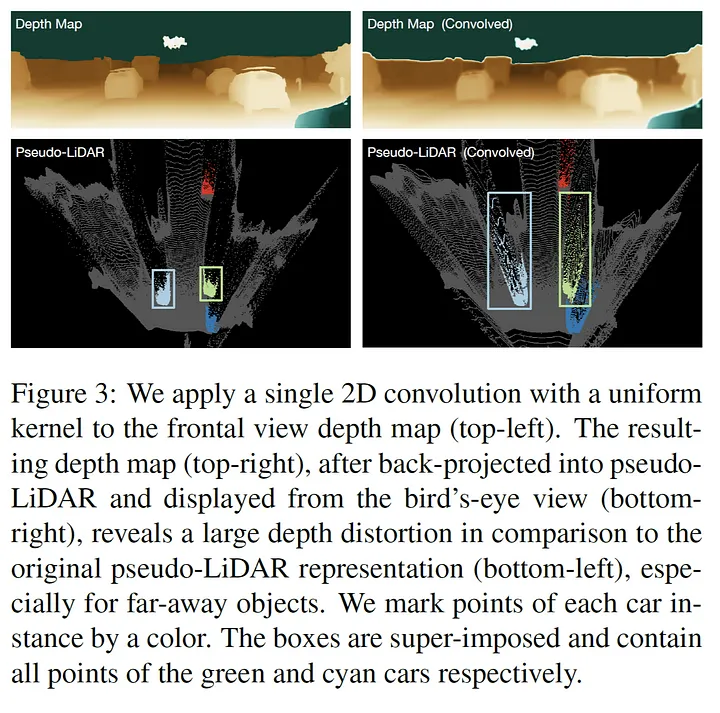
Figure3의 오른쪽 그림은 depth map에 2D convolution을 적용하고 3D 좌표로 변환한 것입니다. Depth map의 흐린 부분에서 부정확한 데이터 결과가 나오는 것을 확인할 수 있습니다.
따라서 이러한 실험을 통해 Depth map에 2D convolution을 직접 적용하는 것 보다 그것의 3D 좌표 변환을 통한 pseudo-LiDAR 데이터의 2D convolution적용이 더 효과적임을 알 수 있습니다.
Network
본 논문에서 말하는 pseudo-LiDAR는 특정한 '네트워크 구조'를 나타내는 것이 아니라, 이미지를 사용하여 LiDAR와 유사한 3D 포인트 클라우드를 생성하는 아이디어를 의미합니다.
Input
KITTI object detection benchmark 데이터를 사용하였고 총 7,481개의 학습데이터와 7,518장의 테스트 데이터가 포함되어 있습니다. KITTI 데이터셋은 Velodyne LiDAR point cloud 데이터로 구성되어 있고, stereo 정보 및 카메라 calibration matrix 정보-image rectification 및 실제 real coodinate(x,y,z) 을 구하기 위해 필요-가 제공됩니다.
Process
1. Depth Estimation
1.1. Stereo Disparity Estimation
Dense disparity estimation을 하기 위해서 PSMNet, DISPNet, SPS-STEREO 알고리즘을 사용하였습니다.
1.2. Monocular Depth Estimation
Monocular depth estimation을 수행하기 위하여 DORN 알고리즘을 사용하였습니다.
2. Pseudo-LiDAR Generation
앞의 두 방식을 통해 얻은 Depth map 데이터에 카메라 calibration정보(초점 거리, 렌즈 왜곡, 카메라의 위치와 방향 등)을 사용하여 Velodyne 3D point cloud data로 변환합니다.
이 시스템에서 1M 이상 height 좌표들은 모두 제거되어 처리하였습니다. 여기서 카메라 calibration 정보가 없으면 pseudo-LiDAR를 구성할 수 없음에 유의해야 합니다.
3. 3D Object Detection
3D object detection을 하기 위해서 Frustum PointNet과 AVOD 알고리즘을 선택하였습니다. 두 알고리즘들은 LiDAR와 monocular 이미지를 사용합니다.
Output
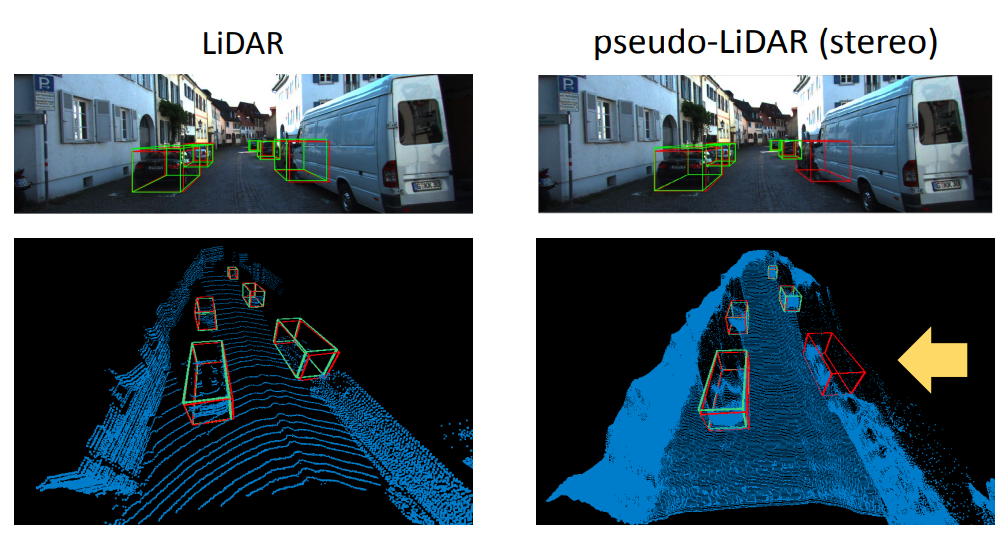
LiDAR vs. Pseudo-LiDAR vs. Frontal View

왼쪽과 중간의 결과값은 각각 LiDAR를 통해 얻은 PCD와 스테레오 이미지를 통해 얻은 pseudo-LiDAR PCD를 이용하여 3D Object detection을 수행한 결과입니다. 오른쪽의 결과값은 단순히 stereo camera를 통해 frontal view의 형태의 데이터를 이용하여 3D object detection을 수행한 결과입니다.
Ground-Truth Box의 위치는 빨간색, Object Detection의 결과는 녹색으로 표시되어 있습니다.
육안으로 봐도 LiDAR와 pseudo-LiDAR를 통해 얻은 결과값은 가까운 거리에선 detection이 정확하게 일치하고 있는 것을 확인할 수 있습니다. 그러나 거리가 먼 영역일수록 depth estimation이 부정확하여 detection이 실패하는 경우가 많음을 확인할 수 있습니다.
Stereo방식의 frontal-view 기반의 detection은 가까운 영역에서조차 부정확함을 알 수 있습니다.
LiDAR vs. Pseudo-LiDAR

Bounding Box
오른쪽 위와 왼쪽 이미지에서 보이는 박스 중 빨간색은 LiDAR를 통해 얻은 것이고, 초록색은 pseudo-LiDAR를 통해 얻은 것입니다. 둘 다 상당히 일치하는 것을 확인할 수 있습니다.
Point Cloud
왼쪽 이미지를 보면 파란색 점이 pseudo-LiDAR를 통해 얻은 PCD이고, 노란색 점이 LiDAR를 통해 얻은 PCD입니다. Point들이 상당히 일치하는 것을 확인할 수 있고, 특히 pseudo-LiDAR를 통해 얻은 점이 훨씬 dense하게 추출되어있음을 확인할 수 있습니다.
Object Occlusion
Object occusion이 발생한 경우, 즉 객체가 다른 객체 또는 환경에 의해 부분적으로 또는 완전히 가려져 보이지 않는 경우엔 object detection이 실패하는 모습을 볼 수 있습니다. object occlusion이 Stereo matching을 통해 depth estimation을 하는 것 부터 어렵게 만들기 때문입니다.
반면 LiDAR를 이용한 detection은 문제 없이 잘 작동한 것을 볼 수 있습니다.
참고
- https://talktato.tistory.com/46
- https://jinu0418.tistory.com/129
- https://velog.io/@ingeol/Pseudo-LiDAR-from-Visual-Depth-Estimation-Bridging-the-Gap-in-3D-Object-Detection-for-Autonomous-Driving
- https://jml-note.tistory.com/entry/Pseudo-LiDAR-from-Visual-Depth-EstimationBridging-the-Gap-in-3D-Object-Detection-for-Autonomous-Driving
- https://medium.com/aimmosubscribe/paper-review-pseudo-lidar-from-visual-depth-estimation-bridging-the-gap-in-3d-object-detection-198153b37288
