앞서 작성했던 글에 이어서 파이썬으로 코드를 구현해보려고 합니다.
전체 코드는 아래와 같고, 각 부분에 대해 설명을 좀 달아볼게요.
import boto3
import os
from dotenv import load_dotenv
load_dotenv()
# Initialize a boto3 client with the provided credentials
client_polly = boto3.client(
'polly',
region_name=os.environ.get('AWS_REGION_NAME'),
aws_access_key_id=os.environ.get('AWS_ACCESS_KEY_ID'),
aws_secret_access_key=os.environ.get('AWS_SECRET_ACCESS_KEY')
)
# Text to synthesize
text = """
Hello, this is a test message for AWS Polly.
"""
# Request speech synthesis
response = client_polly.synthesize_speech(
Text=text,
OutputFormat='mp3',
VoiceId='Matthew' # You can change the voice here
)
# Saving the audio
if "AudioStream" in response:
with open("output.mp3", "wb") as file:
file.write(response['AudioStream'].read())
print("Audio file saved as output.mp3")
else:
print("Could not stream audio")먼저 AWS 서비스를 파이썬 내에서 사용하려면 boto3을 통해 AWS에 접근해야 해요.
boto3.client(서비스명, 리전명, 액세스키아이디, 시크릿엑세스키)를 통해 AWS client 객체를 생성할 수 있고, 이 객체를 통해 AWS 에게 필요한 API 를 호출할 수 있어요.
client_polly = boto3.client(
'polly',
region_name=os.environ.get('AWS_REGION_NAME'),
aws_access_key_id=os.environ.get('AWS_ACCESS_KEY_ID'),
aws_secret_access_key=os.environ.get('AWS_SECRET_ACCESS_KEY')
)리전명, 엑세스 키 등에 사용된 환경변수는 dotenv를 통해 설정해 줬는데요,
액세스 키 등의 정보는 돈과 관련된 중요 정보다 보니 숨겨놓을 필요가 있었어요.
환경 변수들은 프로젝트 최상위 디렉터리에. env에 고이 모셔놓고,. gitignore에. env를 추가해서 레포지토리에 올라가지 않게 해 줘요!
# .env
AWS_ACCESS_KEY_ID = 'aaaaaaaaaaaa'
AWS_SECRET_ACCESS_KEY = 'xxxxxxxxxxxxxx'
AWS_REGION_NAME = 'ap-northeast-2'그러고 나서 코드 내에 load_dotenv()를 선언해 os.environ.get('AWS_ACCESS_KEY_ID')로 원하는 값을 가져와서 사용해요.
개발서버, 상용서버 등. env를 나눠 사용할 수 있지만 여기선 다루지 않기로 해요~
# Text to synthesize
text = """
Hello, this is a test message for AWS Polly.
"""
# Request speech synthesis
response = client_polly.synthesize_speech(
Text=text,
OutputFormat='mp3',
VoiceId='Matthew' # You can change the voice here
)이제 만들어진 boto3 클라이언트를 통해 polly에 음성 합성을 요청할 수 있는데요,
synthesize_speech 메서드에 간단한 매개변수들을 넘겨주면 음성 합성을 할 수 있어요.
가장 간단하게 Text 에는 합성하고자 하는 텍스트를, VoiceId 에는 사용하고 싶은 voiceId를 넣으면 돼요.
어떤 voiceId 를 사용할 수 있는지는 앞서 작성했던 글을 참조하셔도 되고, voices in Amazon Polly에 가서 확인해 보셔도 좋아요.
참고로 synthesize_speech에서 추가로 설정할 수 있는 매개변수들은 Boto3 docs에 자세히 나와있으니 살펴보세요! 다음 글에서 streamlit을 활용해서 좀 더 발전된 사용 형태를 보여드리긴 할 거예요.
이렇게 합성 요청만 한다고 끝은 아니고, response에 담겨 온 AudioStream을 파일로 만들어줘야 해요.
# Saving the audio
if "AudioStream" in response:
with open("output.mp3", "wb") as file:
file.write(response['AudioStream'].read())
print("Audio file saved as output.mp3")
else:
print("Could not stream audio")open file 방식을 사용하여 스트림을 파일로 만들어서 떨궈줘요.
만들어진 파일 예시도 첨부하니 한 번 들어보세요!
거의 AWS에서 제공한 example을 가져다가 설명을 한 수준이긴 하지만, 궁금한 부분 있으면 문의하세요!
이번에 작성한 코드는 github에서도 보실 수 있어요 :)
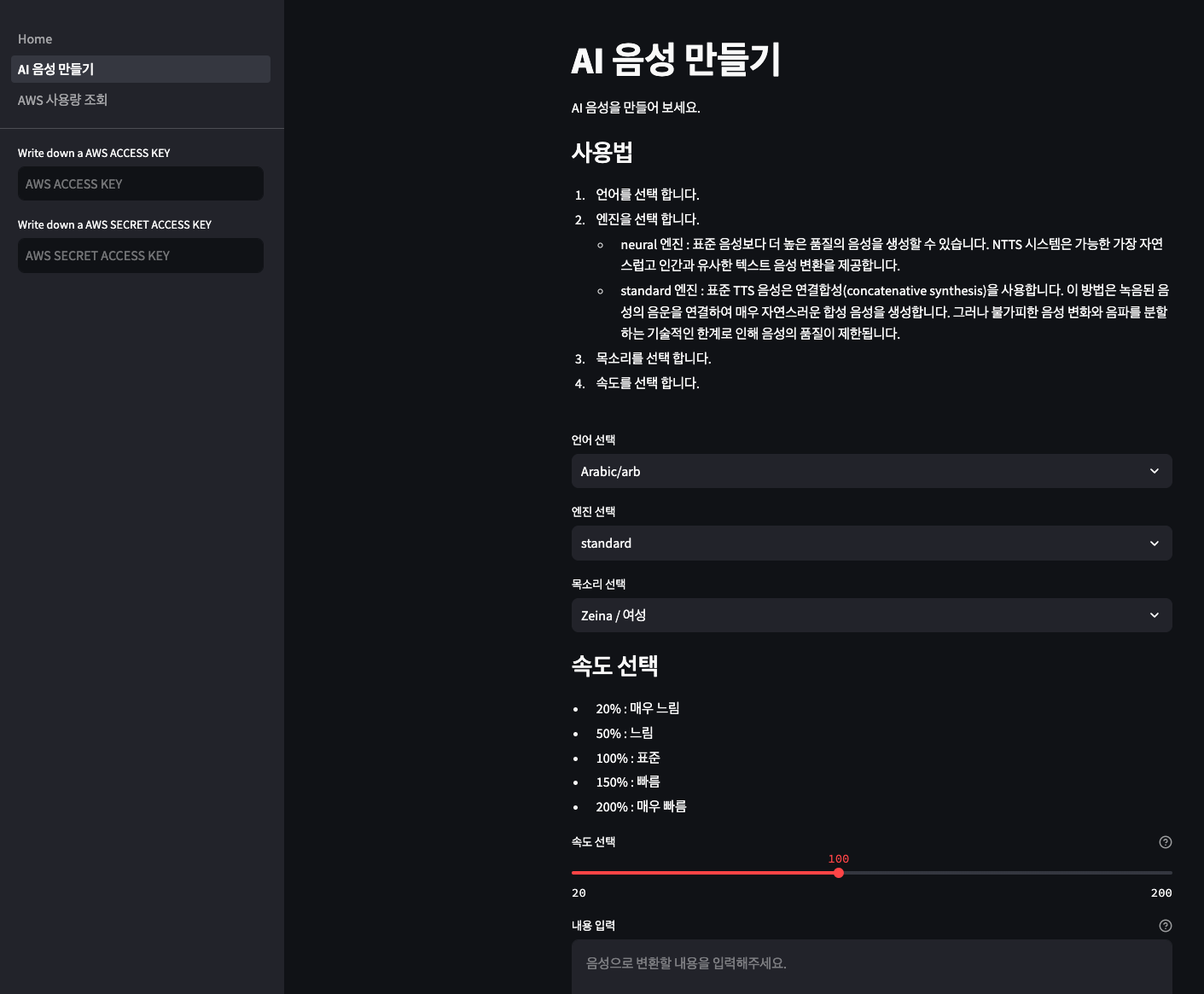
다음 글에서는 Streamlit으로 속도, 언어, 목소리 등을 설정하는 부분까지 포함한 예시 프로젝트를 보여드릴게요.
깃헙에는 이미 구현되어 있어요!
아래처럼 구현되어 있답니다.