[ASC] Aspect의 주목도가 높았던 단어들을 적극 활용하여 감성분석 해보기

실험 모델
앞선 포스팅에서 high-attention score를 갖는 단어를 뽑아내보았다. 여기서는 그 단어들에 추가적인 토큰을 더하고, 이렇게 정해진 토큰들을 어떻게 pooling 할지에 따라 여러 가지 변형 모델을 구성해서 실험한 결과를 다룬다. 결과보다는 과정 속에서 BERT, transformer encoder 내부 구조를 파봤다는 점에서 공부에 도움이 많이 되었던 것 같다.
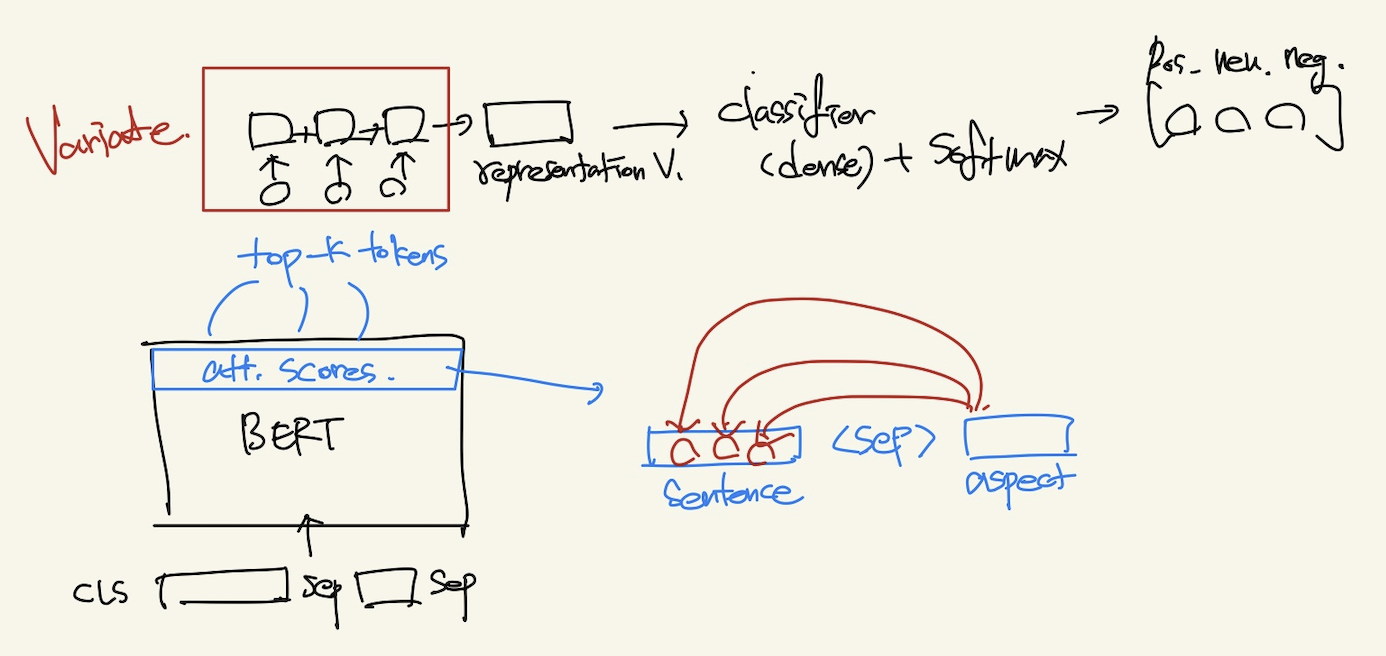
실험을 할 부분은 위 그림의 Variate 빨간 박스이다. 아래 요소들을 다양하게 조합해가면서 실험해보았다.
Pooling의 재료
- top-k attention score words (3 or 4)
- [CLS] 토큰
- [ASP]: text pair로 붙은 aspect words의 final hidden states
- [SEP] 토큰: 하나 또는 양쪽 두 개 모두.
의외로 aspect words가 [SEP] 토큰과의 연관 스코어가 높았기도 하고, 문장 내 특정 word들을 결과물로 활용하고자 하는 연구들에서 특정 word 앞 뒤에 특별한 토큰을 붙여서 그것들의 hidden states들을 활용하는 경우들이 있어서 aspect word의 앞뒤에 붙은 [SEP]을 재료로 사용해보았다.
Pooling의 방식
- Mean pooling: 위에서 고른 재료들은 모두 같은 dim을 갖고 있기 때문에 단순 mean이나 max로 representation vector를 얻는다.
- RNN(LSTM or GRU): 각각의 단어들이 순차적으로 encoding 될 수 있도록 RNN 계열의 레이어에 넣어줌. (여기서는 score순이 아니라 문장에서 등장한 순서대로 넣어 보았다)
- Mean pooling 대신 Max나 concatenation을 사용해보기도 했는데 mean이 가장 성능이 좋았다.
주요 실험 조합
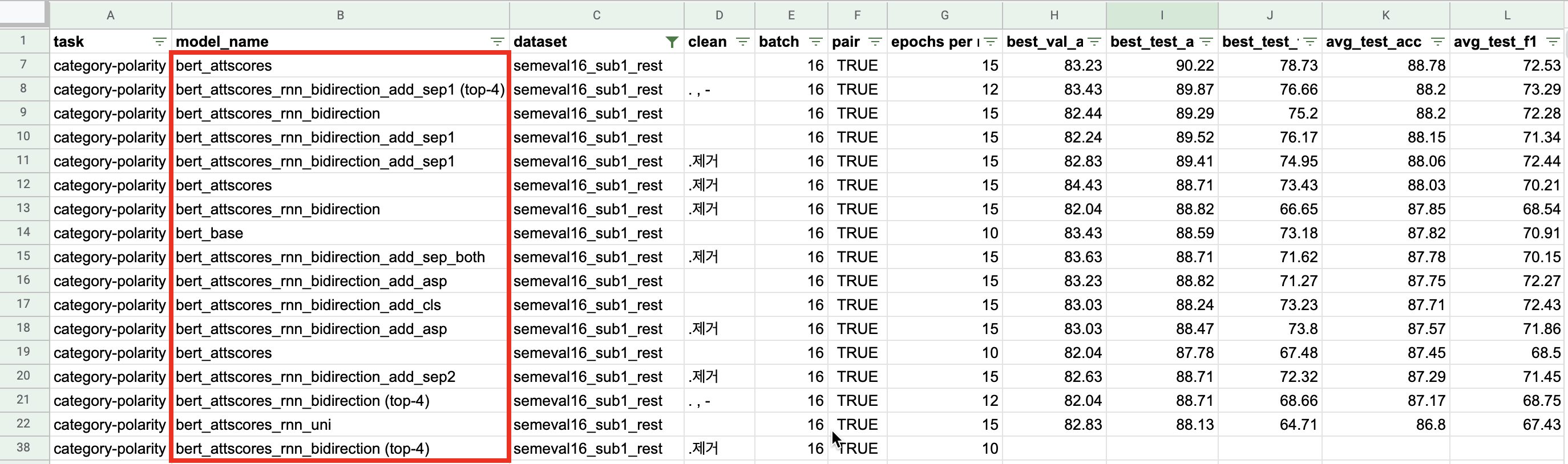
아래 이미지는 실험 결과 중 semeval16 레스토랑 데이터셋만 필터링 한 것이다. 다양한 model_name에서 알 수 있듯 다양한 조합들을 테스트해보았는데 그 중 결과가 괜찮았던 조합을 소개한다. 다만... 데이터셋이 작고 큰 차이가 아니라 결론은 "너무 단순한 task이다", "문장 속 Aspect word와 opinion word를 찾아내는 데로 나아가야겠다" 로 귀결되었다.
- top-k attention 단어들로 mean pooling: top-k 단어의 final hidden states를 평균해서 해당 문장의 representation vector로 함. 최종 Dense layer로 classification.
- top-k att. 단어와 앞쪽 [SEP]토큰을 sequential하게 bi-GRU로 인코딩: top-k 단어와 [SEP] 토큰을 sequence로 보고 bi-directional GRU를 통과시켜 나온 벡터를 해당 문장의 representation vector로 함. Aspect와 관련된 단어들 + [SEP] 토큰에 aspect words의 의미가 많이 담겨있을 거라고 추측.
- top-k att. 단어만으로 bi-GRU 인코딩
- top-k att. 단어와 두 개의 [SEP] 토큰: Aspect words 앞 뒤의 [SEP] 토큰 모두를 top-k 단어 뒤에 붙여서 bi-GRU로 인코딩
- top-k att. 단어와 aspect words: Aspect words (두 개의 [SEP] 토큰 사이의 단어들)와 top-k 단어들을 bi-GRU로 인코딩
- top-k att. 단어와 [CLS] 토큰: top-k 단어들과 [CLS] 토큰을 함께 bi-GRU로 인코딩
주요 코드
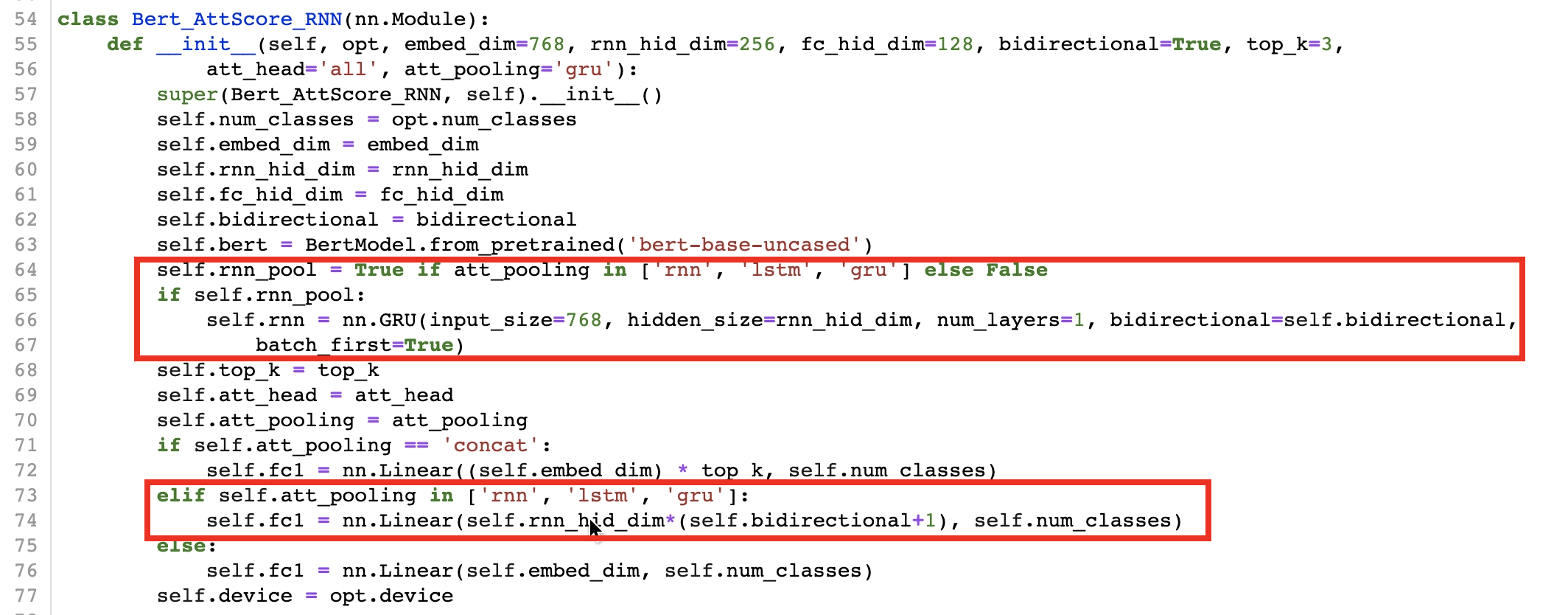
RNN pooling을 하기 때문에 최종 classifier(Linear layer) 전에 GRU layer를 만들어준다. 한 방향과 쌍 방향(bi-directional) 모두 테스트를 해보았는데 주로 4~5개로 이뤄진 짧은 시퀀스들이기 때문에 쌍방향으로 인코딩 해주는 방식이 효과가 좋았다. 아래 이미지처럼 최종 FC layer의 input size를 rnn_hidden_dim에 bi-directional+1 값(1 또는 2)를 곱해준 숫자로 정의해준다.
Forwarding 이전에 [SEP] 토큰들과 aspect words 들의 index를 알아둔다. [CLS]는 항상 문장의 0번째 index를 갖는 반면 나머지는 문장 길이에 따라 항상 다르기 때문이다.
Huggingface의 BERT 모델에서는 [SEP]이 102번이기 때문에 input_ids에서 102의 위치를 알아두고, 두 102 토큰 사이가 자연스럽게 aspect words의 자리가 된다.
.nonzero가 참 유용했다. idx==102인 것만 True 값으로 표기가 되게 한 다음 nonzero를 해주면 True 값의 index를 쉽게 뽑아낼 수 있었다.

모든 모델들의 코드는 레포지토리의 models/bert_attscores.py에서 확인할 수 있다. github
결과
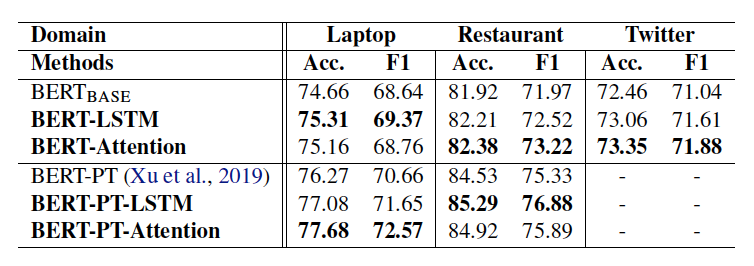
이 실험의 모티베이션이 된 Utilizing BERT Intermediate Layers for Aspect Based Sentiment Analysis and Natural Language Inference(Song, 2020)은 위와 같은 결과를 보였다고 한다. BERT의 각 layer들의 hidden states들을 다시 pooling하여 classification 했을 때 레스토랑 데이터 기준으로 80% 중반의 Accuracy를 보였다. (Post Training 후)

이번 실험에서는 같은 테스트셋과 코드를 활용했을 때 파인튜닝만으로도 80% 중후반의 accuracy를 얻었다. 이걸 베이스로 해서 위의 실험 모델들을 테스트해보았다.
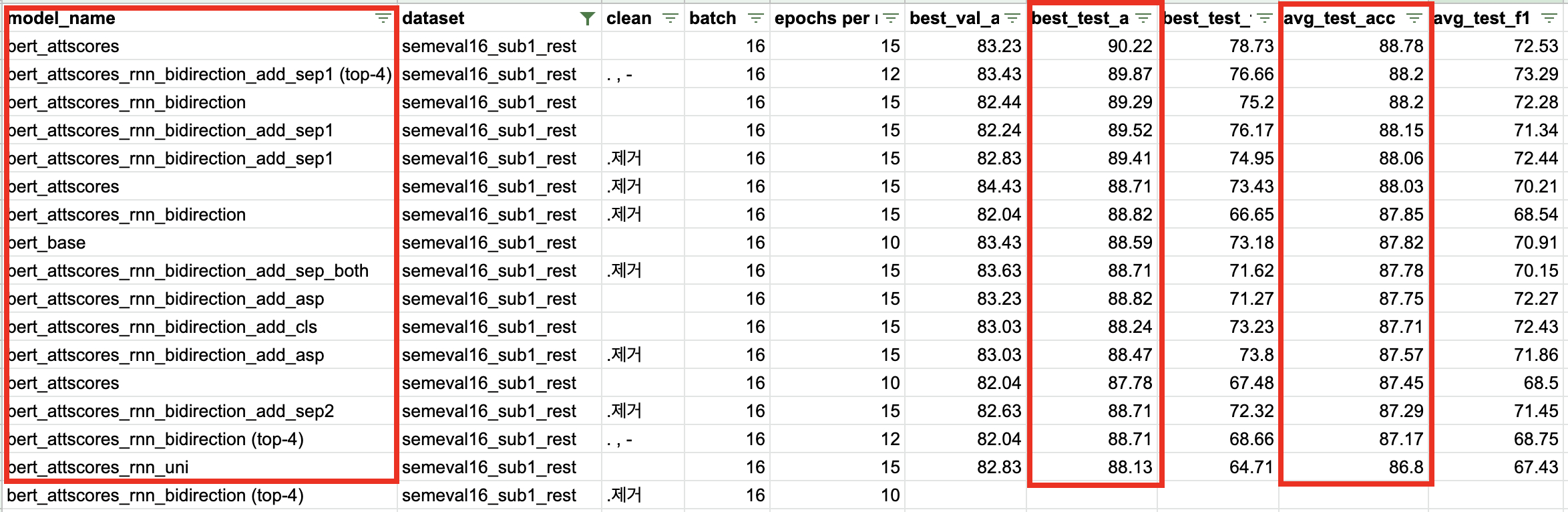
10~15 epochs 중 early stop이 됐을 때 Best Accuracy 기준으로는 88~89를 넘어가는 모델들이 많았다. 그리고 5회 run의 평균치로도 베이스라인 모델인 best base에 근사하는 경우들이 있었다.
가장 퍼포먼스가 좋았던 모델은 위 실험 목록 중 1번(top-k 단어들의 mean pooling) 모델이었다. 같은 조건에서 90%의 best accuracy를 보였고 평균치로도 페이퍼 모델을 넘어섰다.
그리고 2,3,4,5,6번 순으로 평균 accuracy를 보였다. [SEP]토큰을 함께 넣어줬을 때 대체로 성능이 좋았으며, [CLS]토큰이나 aspect words를 넣어주는 경우에는 BertForSequenceClassifcation 구조보다 성능이 조금 떨어지는 경우가 많았다.
Development
이 실험은 며칠 동안 구조를 바꿔가면서 그리고 BERT 내부 벡터들을 끄집어내면서 진행했다. 길게 글을 써놓았지만 사실 핵심은 여기에 있다. 더 복잡한 태스크로 발전시켜야 겠다는 것..
리뷰 한 문장과 aspect 까지 input에 넣었을 때 그 감성을 추출하는 것은 단순하다.
우선, 한 문장 안에 여러 aspect가 들어있지 않을 확률이 매우 높기 때문에 단순한 Sentiment Analysis 문제로 귀결될 수 있다. 같은 문장들 속에서 다른 aspect 카테고리를 input에 주는 케이스만 가지고 accuracy를 측정했을 때에도 좋은 결과가 나온다면 그나마 유용성이 있을 것 같다.
또한, 우리는 리뷰 속에서 단순히 특정 측면에 대해 긍/부정 감성, 별점 척도 만을 파악하려고 하지 않는다. 사정 정의된 카테고리(성능, 가격, 맛, 분위기 등)와 관련된 다양한 aspect word(가습기의 분무량, 특정 음식의 가격 평가 등)와 opinion word(분무량이 적절하다, 가격이 비싼편이다, 분위기는 프라이빗하다 등) 들을 다양하게 캐치하고 싶다. 실제 네이버 플레이스 리뷰나 쇼핑 리뷰에서도 앞으로는 키워드 중심으로 쉽게 보여주려고 할 것이다. 그 일부가 아래와 같은 키워드 픽 이벤트이다.
따라서 Aspect word Extraction(AE), Opinion word Extraction(OE), Aspect-Opinion pair Extraction (AOPE) 등을 수행할 수 있는 모델이 중요하다. 아직 이를 위한 정제된 데이터셋도 마땅치 않은 상태이기 때문에 한국어 데이터셋을 구축해보는 것부터 시도해보고 있다.
유용하게 사용 중인 Classification을 위한 Trainer와 Run 코드
이 실험에서는 10~15 epochs를 한 회의 트레이닝으로 하고, 5회씩 run을 해서 각 회차마다의 BEST test 퍼포먼스의 평균값을 결과로 기록했다. custom_trainer.py에 trainer와 run class 코드가 있는데, 한번 짜 놓으니 classification task를 할 때에는 이걸 base로 응용할 수 있었다.
아래와 같이 Trainer와 Evaluator를 정의해두고 한번의 Training 싸이클이 끝나면 test set으로 evaluation까지 한 후 최종적으로 결과의 평균치와 최고 값들을 출력할 수 있게 만들어두었다.



모든 코드는 repo/custom_trainer.py
