
W2V의 Skipgram 방식으로 상품군별 쇼핑리뷰 corpus를 학습시키고, aspect seed와 유사한 단어들을 추출해내는 과정.
1. 상품군별 Word2Vec 학습
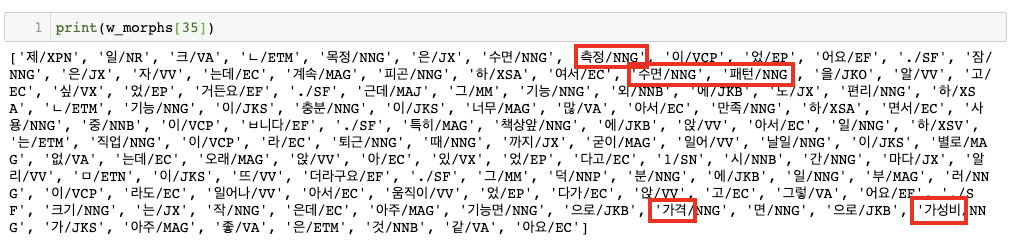
morphs로 쪼개진 리뷰들이 List[List[str]] 형태로 담겨 있어야 한다. 그리고 gensim 라이브러리를 사용해주면 굉장히 간단하게 학습된다. 스마트워치 리뷰 데이터를 300차원의 dense vector로 바꿔줄 거고, 한번 학습시 좌우 5개의 단어를 예측해달라. 그리고 코퍼스 내에서 최소 5번 이상은 등장하는 단어들만을 대상으로 하며, sg=1: skipgram 방식을 사용하겠다는 뜻이다.
from gensim.models import Word2Vec
model_w = Word2Vec(w_morphs, vector_size=300, window=5, min_count=5, sg=1)학습 후 model_w라는 개체에 lookup matrix 관련 정보가 담기게 된다.
2. Most similar words를 후보군에 포함하기
앞서 선정한 seed words와 관계가 많은 단어들을 뽑아낼 것이다. 일단 얼마나 학습이 잘 되었는지 most_similar를 뽑아봤는데 어? 생각보다 괜찮다 라는 생각이 먼저 들었던 것 같다. 스피커의 저음 관련된 내용을 뽑을 때, 중저음, 베이스음, 고음 등은 함께 aspect words에 포함되어도 좋겠다. 마찬가지로 립스틱 리뷰에서 색상과 관련해서 색깔, 색, 컬러, 칼라, 컬러감 등을 모두 aspect로 추출해도 문제가 없다. (물론 걸러주는 것은 내가 직접 해야할 거 같다.. 데이터셋을 만들 때에는..)

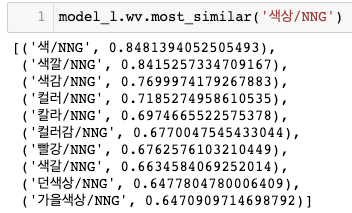
Seed word들을 loop 돌면서 각각 most similar word를 뽑아내고, 거기서 'NNG'(일반명사) 형태소들만을 pool에 담았다. 그리고 중복된 단어들을 제거해서 최종적인 aspect의 candidates를 선정할 수 있었다.

3. 출력 후 직접 걸러내기

위 그림 그대로 수동 작업을 했다. 한줄에 하나씩 단어를 txt로 출력해놓고 적합한지 직접 판단해서 부적절한 단어들을 지워주었다.. 그래도 한번 걸러놓은 단어들이라 양이 그렇게 많진 않았다. 해놓고 나서 든 생각인데 pre-defined 카테고리를 만들어두고 그 카테고리에 속할 수 있는 단어들만 남겨놓자는 마인드로 진행했으면 더 좋았을 것 같다.
디자인: 색깔, 크기, ...
기능: 운동, 수면, 알람, ...
배송: 택배, 배달, ...
이렇게 스마트워치에 대한 카테고리를 미리 4~5개 뽑아놓고, 그 안에 속할지를 판단해보면 기준이 좀 더 명확했을 것 같다. 아마 이 부분은 다시 작업을 해야할지도 모르겠다.
결과가 생각보다 나쁘지는 않네?

무드가습기 리뷰의 aspect이다. '사이즈라', '가격도', '디자인도', '이가격' 처럼 '사이즈', '가격' 등에서 변형되어서 토크나이징된 단어들도 aspect로 잡아낼 수 있게 됐다. khaiii를 사용해서 token classification을 할 때는 이런 단어들이 aspect로 labeling되어 있어야 하기 때문에 만족스러운 결과라 볼 수 있었다.
오타나 문법에서 조금 벗어난 표현들도 aspect에 포함할 수 있었다. '다자인', '싸이즈', '무등등', '새척'은 '디자인', '사이즈', '무드등', '세척'을 나타낸다는 걸 알 수 있는데, 이것들도 그대로 aspect에 포함시킬 수 있기 때문에 올바르게 labeling을 할 수 있을 것 같다.
이젠 이 단어들을 포함하는 리뷰들에 직접 B I O 태그와 또는 aspect word의 위치(토큰 번호)를 라벨링 해주는 작업을 하고 출력해보면 되겠다.
아직 데이터 전체를 공개하기가 어려워서 작업한 노트북 파일을 깃허브에 올리진 못했다. 만약 이 라벨링 데이터가 Aspect base로 리뷰를 이해하는데 도움이 되는 것 같으면 추후에 공개해볼 생각이다.

안녕하세요. 리뷰 데이터 분석 프로젝트를 진행하는 중인데 많이 도움이 되었던 것 같습니다. 감사합니다
마무리가 정리가 되어있지 않아 아쉽습니다. 혹시 github 만드셨다면 링크 알려주시면 공부할 때 많은 도움이 될 것 같습니다.