
LSTM
RNN 계열 모델의 일종으로서 sequential 데이터를 줄줄이 입력 받아 인코딩하는 모델이다. 최근 10일 간의 주식거래 관련 데이터를 활용해 오늘의 가격 변동을 예상하는 등의 sequential task에 활용할 수 있다.
vanilla RNN과의 차이는 게이트의 수에 있다. Sequence가 너무 길어질 경우 앞선 먼 시점 입력 데이터의 정보가 거의 남아있지 않을 수 있기 때문에(vanishing gradient problem) forget, input 게이트를 별도로 만들어서 이전 시점에서 넘어온 데이터를 얼마나 잊을지, 현재 시점 데이터를 얼마나 받아들일지 계산한다.
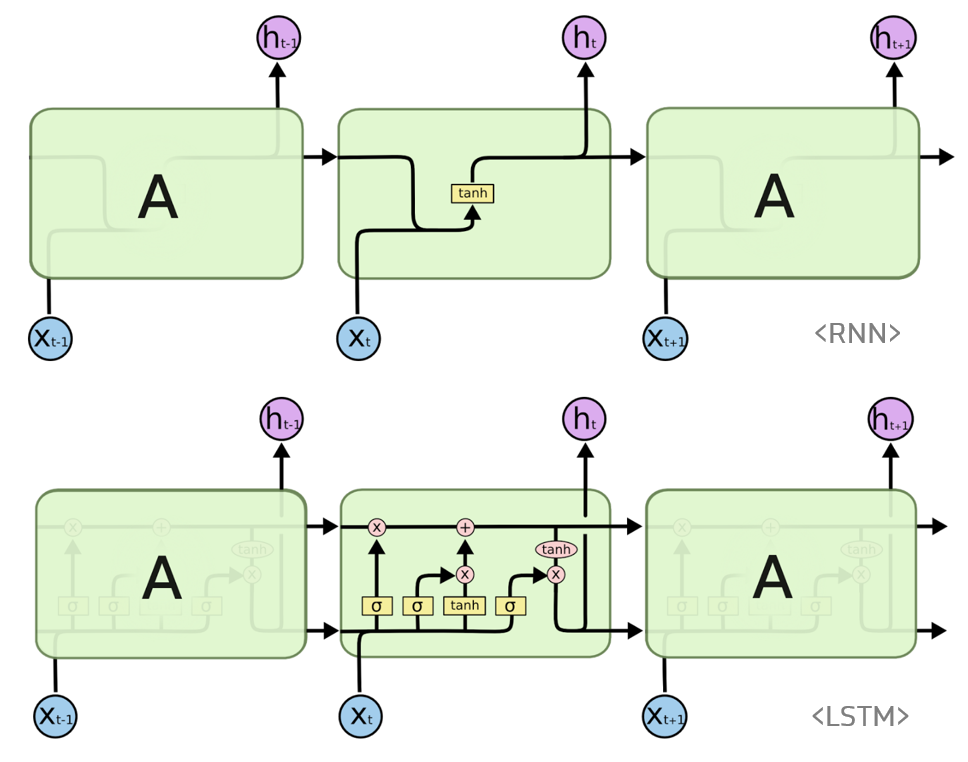
출처는 ratsgo's blog
데이터셋의 변형
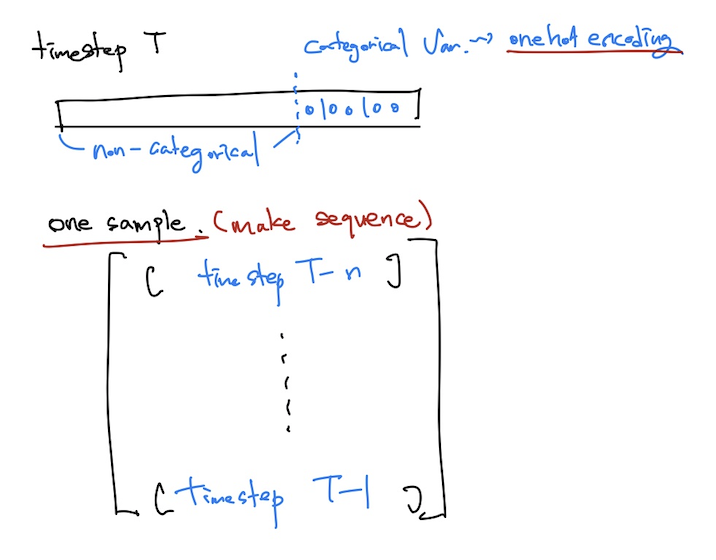
1. categorical 변수들을 one-hot encoding 해서 non-categorical 변수 뒤에 붙여준다.
2. 데이터를 sequential하게 묶어준다. ex) sequence length를 5로 두고 모델링을 한다면, [t-5, t-4, t-3, t-2, t-1] -> t, [t-4, t-3, t-2, t-1, t] -> t+1 처럼 5개의 sequence가 한 timestep에 input으로 활용될 수 있도록 만든다.
NLP 데이터에 비유하자면, 각 단어(timestep T에서의 vector)는 emb_dim 길이로 이뤄진 vector들이고, 이러한 단어가 sequence_length(=5)개 모인 하나의 문장이 위의 one sample이 되는 것이다. 그리고 그 문장을 모델에 넣어 class를 예측한다.
def make_seq(df, non_cat, cat, target, seq_length=5):
'''
@args
df: dataframe to transform
non_cat: non_categorical cols -> LIST
cat: categorical cols -> LIST
target: target col -> str
seq_length: how long seq to input
'''
non_cat_ = df[non_cat]
cat_ = df[cat]
target_ = df[target][seq_length:]
enc = OneHotEncoder()
enc.fit(cat_)
arr_cat = enc.transform(cat_).toarray()
data = list()
for i in range(len(arr_cat)):
data.append(np.concatenate((non_cat_.iloc[i], arr_cat[i])))
data = np.array(data)
temp = list()
for i in range(len(data)-(seq_length-1)):
temp.append(data[i:i+seq_length])
data = np.array(temp)[:-1, :, :]
print('shape of sequential input data: {}'.format(data.shape))
return data, target_Model Sturcture
모델의 구조는 아래 그림과 같다.
1. input vector들을 fc layer로 dimension을 변형시켜준다.
2. encoder(LSTM, attention, LSTM+attention)에 sequential하게 입력하여 각 sample마다 하나의 representation vector를 만든다.
3. 마지막으로 fc layer(classifier)를 거쳐 num_classes 만큼의 vector를 뽑아낸다.
4. 이 값들로 cross entropy loss를 구하게 되며, torch.max()로 예측 class를 구할 수 있다.
NLP에 비유하자면, word idx로 이뤄진 벡터들을 embed_dim으로 embedding 시켜준 후, 순차적으로 LSTM 모델에 집어넣고, 마지막의 hidden_states를 representation vector로 하여, classifier를 거쳐 감성분류 또는 multi-class classification을 하는 것이다.

base가 되는 LSTM 인코더 모델의 코드
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class AiR_predictor(nn.Module):
def __init__(self, input_dim, embed_dim, rnn_dim, fc_dim, num_classes, bidirectional, opt):
super(AiR_predictor, self).__init__()
self.input_dim = input_dim
self.embed_dim = embed_dim
self.rnn_dim = rnn_dim
self.fc_dim = fc_dim
self.num_classes = num_classes
self.bidirectional = bidirectional
self.embedding = nn.Linear(self.input_dim, self.embed_dim)
self.rnn = nn.LSTM(input_size=self.embed_dim, hidden_size=self.rnn_dim, batch_first=True, bidirectional=self.bidirectional)
self.fc = nn.Linear(self.rnn_dim*(self.bidirectional+1), self.num_classes)
self.device = opt.device
def forward(self, input_ids):
embedded = self.embedding(input_ids) # float type!!!, dropout
outputs, (hidden, cell) = self.rnn(embedded)
outputs = outputs[:, -1, :]
output = self.fc(outputs)
return outputResult
uni-directional LSTM에 5개의 sequence를 넣었을 때 bad recall score가 가장 좋았다.
- 언어와는 달리 굳이 adverse 방향으로 encoding 시킬 필요가 없고 (=bi-directional 모델에서 성능 개선이 거의 없었다)
- 대기의 질은 먼 과거보다는 가까운 과거의 영향을 많이 받기 때문에 모델에 들어가는 sequence의 길이를 너무 길게 늘릴 필요도 없어보였다.
- Data bagging 과정에서 bad, worst의 weight를 높여준 ML(Random Forest) 모델의 bad recall을 따라가지는 못했으나 보편적인 accuracy에서는 LSTM 계열 모델들의 성능이 미세하게나마 좋았다.
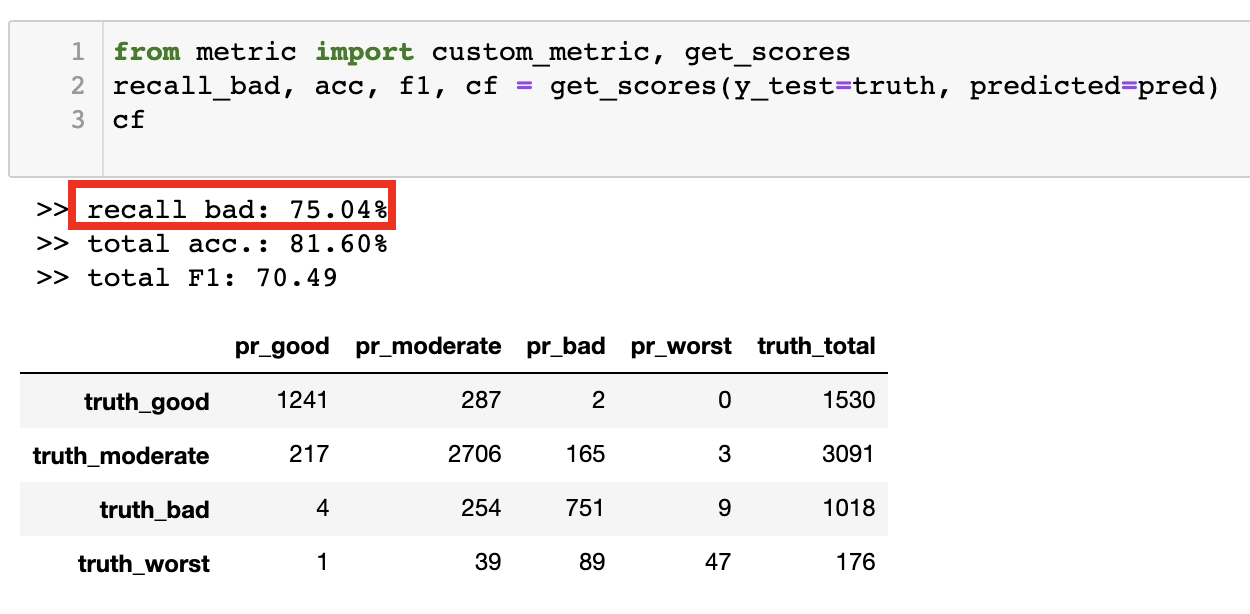
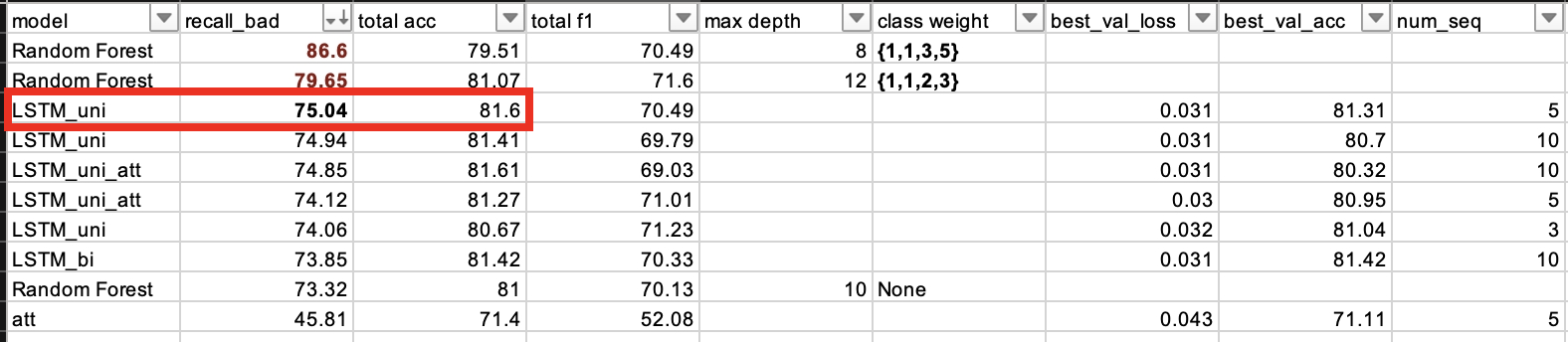
전체 코드는 > github
