AE에서 Tokenizer의 중요성
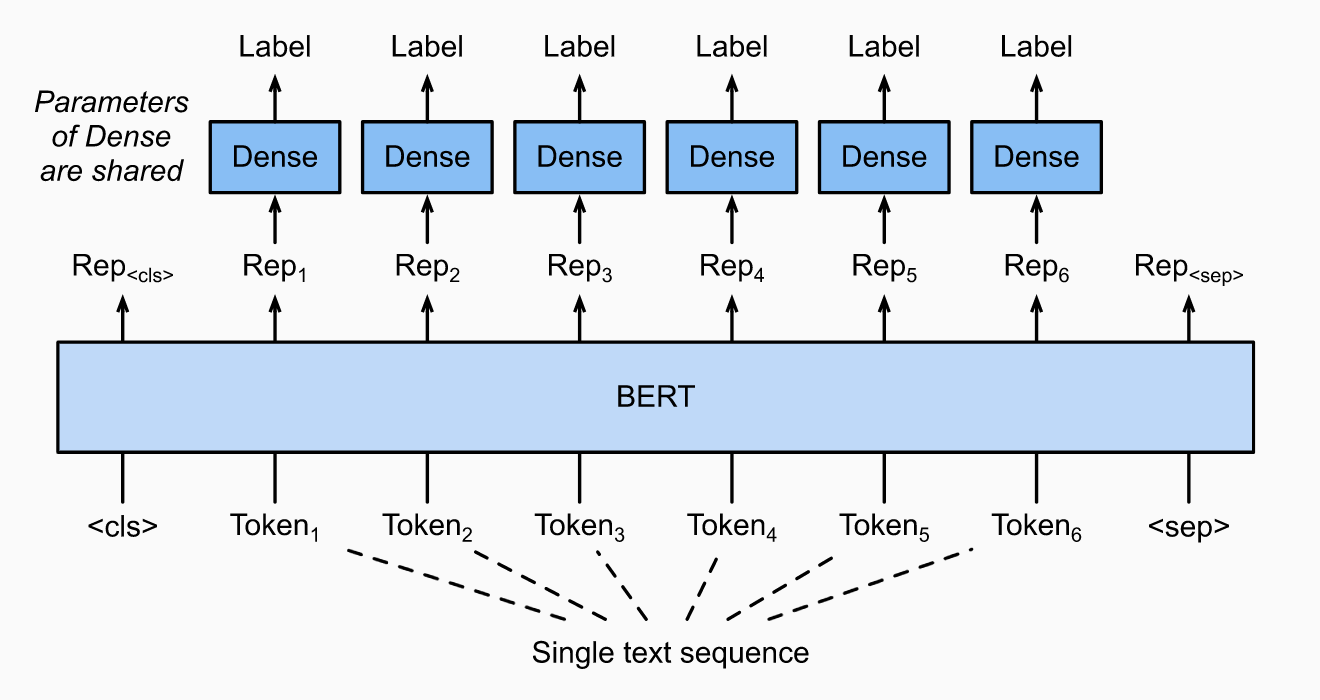
Aspect Extraction은 보통 token classification으로 진행된다. 문장 내에서 핵심이 되는 단어(aspect)가 시작되는 지점과 끝나는 지점을 B,I,O tagging 형태(begin, in, out)로 찾아낸다. Bert와 같은 PLM 모델에서 token들의 마지막 states들을 공통된 weight를 갖는 레이어에 통과시켜서 각각 classification을 하게 만든다. 아래는 BERT를 활용해 POS tagging과 같은 token classification task를 진행하는 방식.
이미지 출처
따라서 transformers를 활용하여 AE task를 수행할 때도 aspect 단어들을 얼마나 잘 포함할 수 있도록 tokenize 할 수 있는지가 중요하다. 게다가 PLM의 성능을 활용하기 위해서는 input text가 동일한 tokenizer로 잘려야 하기 때문에 이왕이면 사전 학습 때부터 활용된 tokenizer를 그대로 사용할 수 있다면 최상이다.
리뷰 데이터에 잘 어울리는 토크나이저는?
결론부터 말하자면 카카오의 khaiii 토크나이저가 가장 활용해 볼만했다. 앞서 직접 데이터를 수집했다는 포스팅을 올린 적이 있는데 (데이터 수집에 관한 포스팅) 그 데이터들을 가지고 aspect words를 추출해내면서 여러 토크나이저들을 테스트해보았다.
- mecab
- KoBERT (wordpiece) - SKT
- KorBERT (morphs) - ETRI
- khaiii - KAKAO
이게 먼저 정해져야 다시 aspect를 추출하는 작업 (이 부분은 정리해서 포스팅해볼 예정)을 진행해보고, 새로 모델을 학습시키든지 기존 한국어 BERT를 활용하면서도 라벨링을 잘 해줘서 fine-tune이나 post-training 정도로 진행할지 결정할 수 있다.
테스트 방식
사실 '실험' 이라고 이름 붙이기가 어려웠다. 어떤 통계적인 방법으로 비교해보기가 어려웠기 때문이다. (아마 aspect를 나름대로 추려낸 다음, 여러 토크나이저로 문장들을 잘랐을 때 그 aspect들을 온전히 포함하고 있는 비율로 비교하면 괜찮을 것 같긴 하다) 일단은 눈으로 비교해본 후, best tokenizer를 활용해 다시 한번 통계적으로 aspect를 추출해보는 작업을 할 생각이다. (기존에 단순 빈도와 TF-IDF 유사 방식으로 aspect를 뽑았을 때에는 속도를 위해 mecab을 사용했다)
- mecab은 Konlpy.tag으로 사용할 수 있다.
- KoBERT는 'monologg/kobert'에 공개된 버전을 사용했다.
- KorBERT는 ETRI 페이지에서 access key를 받아 API를 호출하여 사용했다.
- Khaiii는 카카오의 github을 clone 하여 설치 가능하다.
KorBERT(best), KoBERT(bad), Khaiii(usable)
결론은 제목과 같다. KorBERT의 형태소 분석기가 BEST로 보였으며, 성능 좋은 wordpiece 방식을 사용한 KoBERT는 리뷰 AE task에서는 사용하기가 어려울 것 같다. 다만, KorBERT는 모델은 서약서를 쓰고 사용할 수 있지만, 모델에 넣기 위한 형태소 토크나이저는 API 형태로 제공되며 일 5,000건 밖에 되지 않아서 연구에 사용하기가 쉽지 않을 것 같다.
아래 몇가지 사례를 담아본다.
1. 배, 송...
남치니 생일로 준비했는데 너무너무너무 만족하네요 딱 배송도 잘 맞춰서 왔구요 소독기도 와서 너무 좋아요^^ 가격도 다른곳 보다 저렴하게 잘산거같아요 매장은 혜택이 아무것도 없드라고요 ㅠㅠ 판매자님 감사합니다^^
위 리뷰에는 '배송', '가격', '소독기' 라는 aspect word가 들어있다. mecab으로 자른 결과를 활용해서 aspect를 추출했기 때문에 mecab은 모든 단어를 포함한다.
Wordpiece 방식을 사용하는 KoBERT는 배송을 하나의 단어로 인식하지 못하고 있다. 이는 정답 labeling을 매우 어렵기 만들며, 모델에 들어갈 때 각각 다른 토큰으로 들어가야 하기 때문에 설령 BIO tagging으로 B와 I가 잘 나온다고 하더라도 모델이 그 단어를 온전히 aspect 단어라고 받아들일지도 의문이다. 리뷰 전체의 감성분석(sequence classification)에서는 매우 좋은 성능을 보이는 KoBERT이지만 토큰 단위 classification으로 활용하기가 쉽지 않아 보인다. KorBERT와 Khaiii는 무난하게 활용 가능해 보인다.

2. 심박수
애플스토어에서 나이키 44mm 사려고 약 한달넘게 계속 방문한 끝에 구매 했습니다. 이마트, 매장 방문해서 구매하려고 노력많이했으나, 드디어 애플 스토어에서 구해서 구매하게되었습니다. 역시 애플워치 너무 쓰기 편하고, 운동하기에 딱 좋습니다. 나이키 버전을 기다린 보람이 있습니다. 운동하기에 적합하고 심박수 체크 도움이 많이 됩니다. 핸드폰 무음일때 워치가 진동으로 알려주고 가격대비 너무 좋다고 생각합니다. 가성비에도 좋고 핸드폰 se 쓰고 있는데 워치도 se 셋트산 느낌입니다. 너무 잘 사용하고 있고, 판매자 님께 감사합니다. 안전하게 잘 받았습니다. 감사합니다.
위 리뷰는 가격, 운동, 심박수라는 aspect를 갖는다. khaiii가 mecab과 유사하게 심박수를 하나의 단어로 인식하고 있다. 또한 '가성비'와 같은 단어도 좋은 aspect 후보가 될 수 있는데 (이 부분은 직접 하나씩 추가해줘야 할 듯하다) 잘 묶어서 토크나이징하고 있음을 알 수 있다.


3. KorBERT가 가장 적합한데...
배송 빠르고 좋아요. 2개 구입했어요.
위와 같은 리뷰는 가장 흔한 리뷰이다. 배송이라는 단어를 mecab은 정확하게 인식하고 있기 때문에 aspect로 선정이 되었는데 khaiii는 제대로 자르지 못하고 있다. KorBERT는 항상 평균 이상의 적절한 토크나이징을 보인다. 역시 이걸 활용한 사전 학습 모델도 있고 가장 적합한 토크나이저로 보이는데...

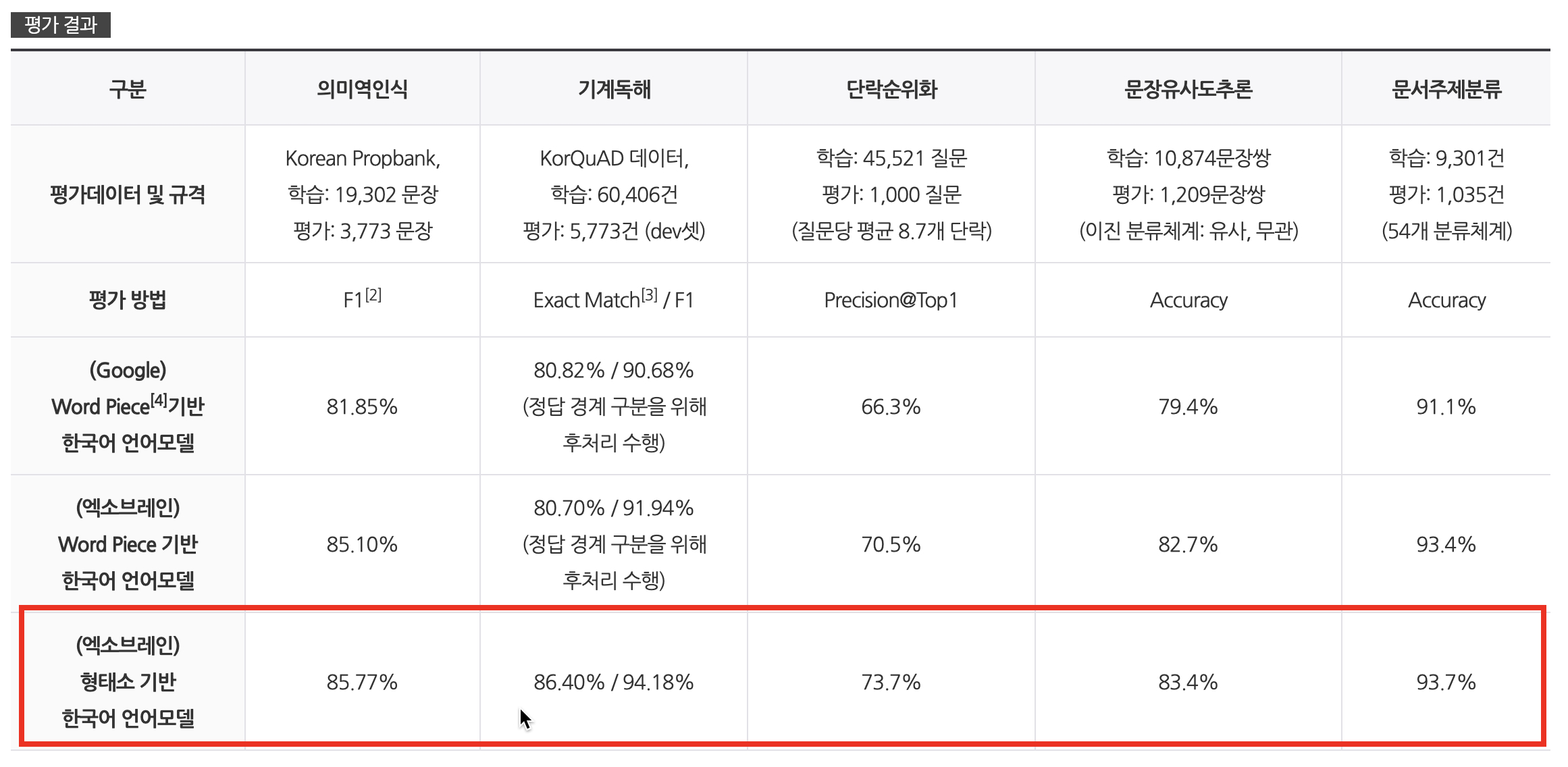
약 100여 개의 리뷰들을 찍어본 결과, 우선 리뷰는 참 분석이 어려워 보였다. 온라인 구어체이고 모바일로 많이 남기는 만큼 띄어쓰기나 오타가 많은 편이기 때문이다.
KorBERT의 토크나이저가 그나마 리뷰에서 핵심 aspect를 추출하기에 가장 좋아보였다. 하지만 API 사용 문제가 있어서 Khaiii를 사용해볼 생각이다. Khaiii로 토크나이징과 customized TF-IDF를 수행해서 통계적으로 다시 aspect를 추출해볼 계획이다. Mecab에 비해 약 3배 정도의 시간이 소요된다고 하는데, 최종적으로 khaiii의 성능을 확인해보고 어떤 토크나이저를 사용할지 확정을 해야겠다. ETRI가 공개한 결과에 따르면 한국어의 경우 형태소 기반의 모델의 성능이 좋다고 하니 khaiii를 사용해서 형태소+품사 기반(단어/품사)으로 학습을 진행해보는 건 어떨지도 고려해봐야겠다.