문제 & 데이터셋

출처: kaggle notebook
캐글에 게시된 intel image classification 데이터셋을 활용하여 간단하게 이미지 분류기 앙상블 모델을 실험해보았다. 실제 현업에서 마지막 classifier에 ML 모델을 도입하여 성능 개선을 이뤄본 경험이 있어 다른 데이터셋에도 적용해보고 싶었기 때문이다.
데이터셋은 아래와 같은 6개의 클래스, 총 24.3k장으로 구성되어 있다. EDA를 직접 자세히 진행해보지는 않았으나 산과 바다, 거리, 빌딩 등 비교적 명확한 경계를 가지고 있는 이미지들로 보인다. 다시 말해 성능이 꽤 높게 나올 수 있음을 뜻한다.
buildings
forest
glacier
mountain
sea
street
아이디어
이미지든 자연어든 ai 모델로 분류를 진행할 때, 데이터를 embedding(또는 feature) 벡터로 나타낸 후 해당 벡터들을 활용하여 최종 분류(classification)를 진행하게 된다.
모델에는 Transformer 기반의 모델들이 들어가기도 하고 이미지에서는 CNN 기반의 Resnet, EfficientNet, Convnext 등이 간단히 사용되기도 한다.
모델에서 뽑아준 vector의 각각 숫자들을 하나의 feature로 보고, 머신러닝 모델의 input으로 넣어준다는 아이디어로 모델링을 진행하였다.
모델
여기에서는 모델은 이미지+텍스트 멀티 모달(Multi-model) 학습이 진행된 CLIP(Resnet 50x16)을 활용하면서 Classifier 부분에 전통적인 Machine Learning 모델은 SVM(Support Vector Machine)을 사용하였다. SVM에 대해서는 별도로 docs를 참고해보시길.
코드
모델
# CLIP feature extractor
class CLIPextractor(nn.Module):
def __init__(self, pretrain_name='RN50x16'):
super(CLIPextractor, self).__init__()
model, preprocess = clip.load(pretrain_name)
self.clip = model.visual
self.input_resolution = model.visual.input_resolution
print("model.visual.output_dim :", model.visual.output_dim) # 768
def forward(self, input):
return self.clip(input)
# SVM classifier
regr = SVC(kernel='rbf', random_state=seed)학습
모델에서 768 dimension의 feature vector들을 추출한 후 간단하게 regression 모델에 fit을 진행해주면 된다. 자세한 코드는 아래 github repo를 참고.
# feature extract
def feature_extract(model, loader, device):
model.to(device)
_ = model.eval()
features = torch.tensor([])
labels = list()
with torch.no_grad():
for batch in tqdm(loader):
image, label, _ = batch
image = image.to(device)
feature = model(image).detach().cpu()
features = torch.cat([features, feature])
labels += label
return features, labels
# SVM fit
regr.fit(np.array(train_features), np.array(train_labels))TEST
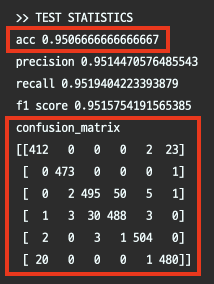
테스트셋에서 대해 accuract 95%, confusion matrix를 보면 틀린 케이스가 거의 없음을 알 수 있다. 공개된 캐글 notebook을 볼 때 테스트셋에 대해 95% 이상 성능을 보이는 경우가 눈에 띄지 않는다. 코드상으로 간단하지만 강력한 방식이라 할 수 있겠다.
links
github/jonas-jun/img_cls_ensemble
kaggle/intel-image-classification
