video from Joseph Redmon
Abstract
YOLO introduces an innovative approach to object detection by simplifying the traditional multi-step process into a single regression task. Instead of handling detection in stages, YOLO uses a unified neural network to predict bounding boxes (localize objects within rectangular frames) and class probabilities (object types) in a single computation. This end-to-end architecture enables YOLO to achieve impressive speeds, processing up to 45 frames per second, with Fast YOLO reaching an exceptional 155 frames per second.
Introduction
I’ll be covering the research paper:
YOLO, You Only Look Once: Unified, Real-Time Object Detection.
YOLO was a major breakthrough in computer vision because it introduced a much faster and simpler way to detect objects in images and videos.
Before YOLO, object detection typically involved very slow multi-step processes that weren’t ideal for real-time applications. Methods like Deformable Parts Model (DPM) and Region-based Convolutional Neural Networks (R-CNN). Both while accurate, required significant processing time and wasn’t practical for real-time use. Dividing classification into two steps, determining whether an object exists and what object it is, made classification computationally expensive and relatively slow.
YOLO approached this problem by combining object detection into a single and unified task, making it much more time efficient. In fact, humans do not go through different steps when recognizing objects in images. Therefore, the paper names their methodology "You Only Look Once," meaning that if you just look at the image, the object in it appears right away.
image from YOLO Paper
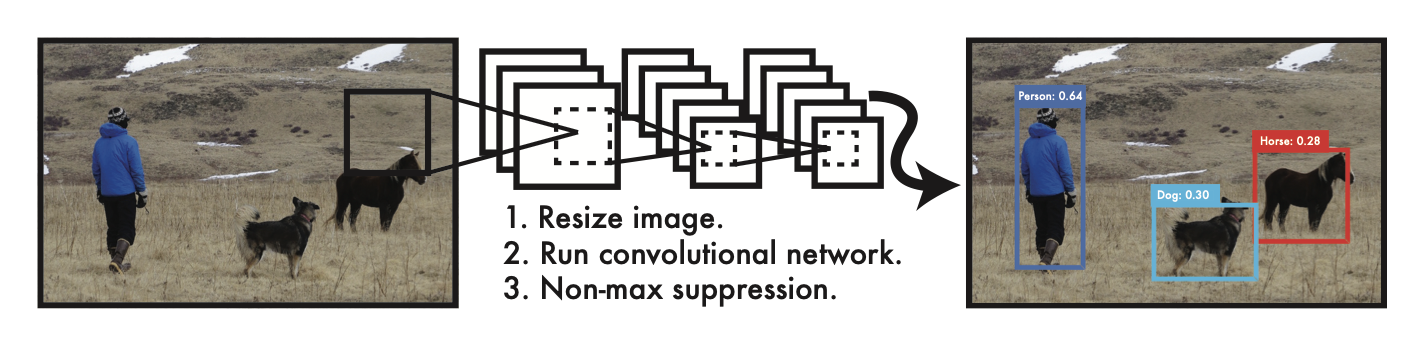
YOLO has three straightforward steps:
1. resizing the input image (typically 448x448 pixels) to process multiple images uniformly.
2. running a convolutional network to predict bounding boxes and class probabilities as a single, unified task.
3. using non-max suppression to filter out overlapping bounding boxes
This allows YOLO to learn the entire image and process images at up to 45 frames per second, and even 150 frames per second with Fast YOLO. This means that it can process videos in real time (with a latency of less than 25 milliseconds).
Structure
The structure is built around its unique approach to Unified Detection, where bounding box coordinates and classification tasks are handled by a single neural network.
image from YOLO Paper
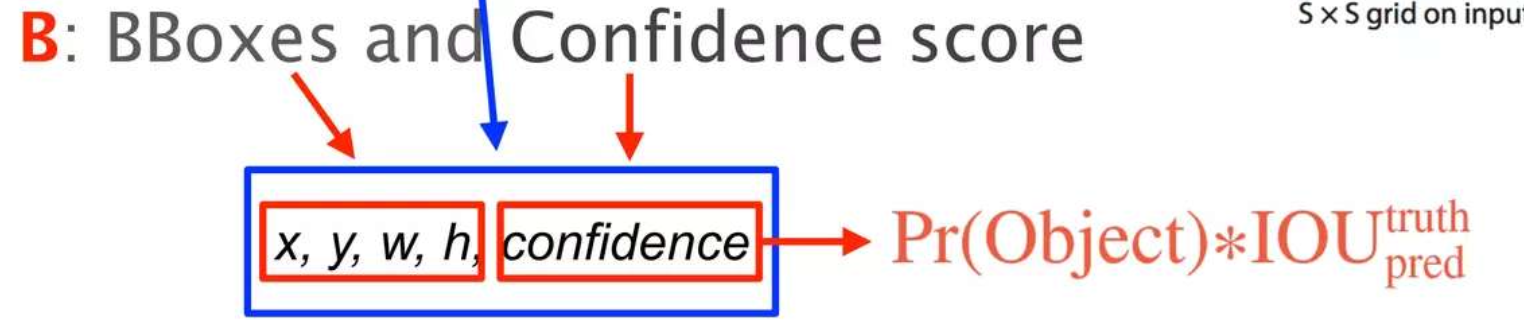
- Divides the image into S x S grids. (The paper gives an example with S = 7)
- Features are extracted through a CNN, and a prediction tensor containing essential information (i.e bounding box coordinates, confidence score) is created.
- B bounding boxes and confidence scores are predicted.
- BBox is defined by center coordinates (x, y), width (w) and height (h).
- Confidence is the probability that an object is present in the bounding box, which is expressed in the form of the product of Pr(Object) and IOU (intersection over union).
image from slidshare
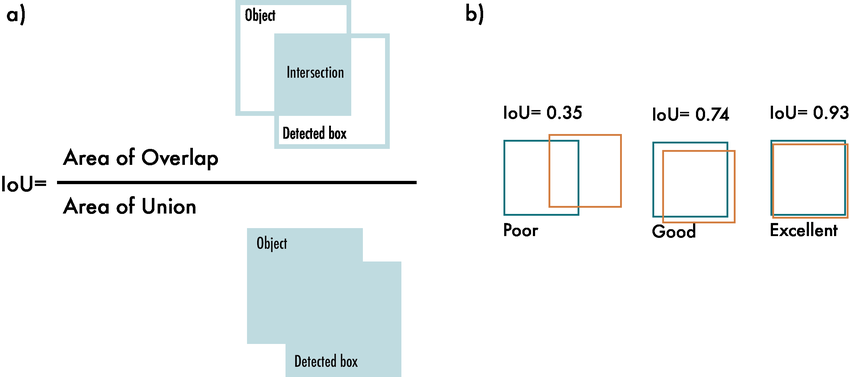
Whats IoU?
- provides a measure of how closely the model’s predicted box fits the true object.
1 = perfect match
0 = no overlap
- Each grid cell has C conditional probabilities, P(Classi|Object), which represents the likelihood that an object belongs to a specific category (i.e cat,bicycle, etc).
The goal of YOLO’s Unified Detection approach is to handle all these tasks object detection, localization, and classification in one pass, directly from the input image.
Network Architecture
It is said that YOLO used a slightly modified version of GoogLeNet's network architecture.
image from slidshare
The network consists of 24 convolutional layers followed by 2 fully connected layers. These convolutional layers extract visual features, and alternating 1 × 1 convolutional filters are used to keep the number of features manageable.
As you can see in the figure above, the first 20 convolutional layers reflect the structure of GoogLeNet because it was optimized for extracting detailed features efficiently. After the 20 layers, YOLO adds 4 more convolutional layers and 2 fully connected layers where bounding boxes and classifying objects tasks are done.
Training
Now that we explained the architecture, if you are familiar with training models, this section will be easy to understand.
image from slidshare
The first 20 convolution layers are pretrained with ImageNet's dataset which contains 1000 different classes. This means that the model starts by learning to recognize patterns and features that are useful for a wide variety of objects.
As explained in the previous section, the remaining 4 Convolutional + 2 Fully Connected Layers are used to learn the specific task of object detection. Therefore they are finetuned.
What's Finetuning?
It involves updating the weights of the entire network, both the pretrained and the new layers, using a smaller and more specific dataset.
YOLO is finetuned using PASCAL VOC dataset, which is designed specifically for object detection. Next, the image resolution is increased from 224x224 (used in the original classification pretraining) to 448x448.
image from slidshare
As shown in the figure above, YOLO’s training process involves determining which of two bounding boxes best represents an object of a specific class within a grid cell. For each bounding box, ( x ) and ( y ) denote the center coordinates, ( w ) and ( h ) represent the width and height, and ( c ) signifies the probability that an object is present within this box. This approach allows YOLO to predict both the location and the likelihood of objects in the image.
YOLO Algorithm?
Below is a simplified step by step example to visually understand the process.
Predict Grid
image by Zoumana Keita

The first step will be diving the input image into N cells, in this case 4x4 . Each cell is going to be responsible for detecting the class (object type) with its confidence/probability value.
Predict Box
image by Zoumana Keita
Next, YOLO finds bounding boxes (rectangles) around each object in the image. Each bounding box is represented by a vector, Y = [c, x, y, h, w, c1, c2].
- c is the probability that a grid cell contains an object. Grid cells in red, for example, have pc > 0.
- Yellow cells, where c = 0, are unlikely to contain objects.
After obtaining the bounding box predictions, YOLO computes class probabilities for each grid cell. The final prediction for each class is obtained by multiplying the confidence score of the bounding box with the class probabilities. (The number of class scores depends on how many classes the model is trained to recognize.)
Below is a more detailed image of what the vector represents:
image by Zoumana Keita
- c1 and c2 in this example, they correspond to two classes: Player and Ball. However, we can choose the amount of classes that we want to have.
Filter Overlapping Boxes
image by Zoumana Keita
Each object can have multiple grid boxes as prediction candidates, but not all are relevant.
The IOU score helps us filter them:
- We set an IOU threshold, like 0.5.
- Boxes with IOU ≤ threshold are ignored; only those with IOU > threshold are kept.
In the example above, it originally had two candidate grids, but only “Grid 2” was selected.
Setting a threshold may not always be enough, therefore Non-Max Suppression is used. NMS uses IoU to decide which boxes to keep. If a box overlaps significantly with another box (i.e. has a high IoU with it), NMS will remove the box with the lower confidence score.
image from slidshare
Results
To evaluate the performance of YOLO, experiments were conducted using the PASCAL VOC 2007 Dataset.
The results were categorized into two groups: Real-Time Detectors and Less Than Real-Time Detectors.
image from YOLO Paper
For Less Than Real-Time, the Faster R-CNN series achieved the highest mean Average Precision, but it struggled with low frames per second, making it unsuitable for real-time applications. Therefore, YOLO is the second best with both mAP and FPS scores, showing its efficiency.
image from YOLO Paper
When combining YOLO with Fast R-CNN, the hybrid approach achieved an mAP of 70.7%, outperforming Fast R-CNN alone by 2.3%. However, this method was slower than using YOLO by itself, which remains a fast detector.
Through these comparisons we can observe that YOLO focuses on improving speed, so while its accuracy is somewhat lower, it is still capable of real-time detection.
Limitations
Despite some limitations, YOLOv1 was very innovative for its time. The paper briefly mentions a few limitations:
- Difficulty detecting small or closely grouped objects due to spatial constraints.
- Difficulty generalizing to unusual object shapes, losing precision with finer details because of its downsampling.
- Error treatment is less effective with small bounding boxes, where even slight inaccuracies can lead to larger IOU losses.
Conclusion
YOLO’s speed is a key advantage (45 FPS, Fast-YOLO can achieve up to 155 FPS) making it suitable for use in real-time applications, though it has to sacrifice accuracy for this efficiency. Its adaptability across different fields, from healthcare to agriculture, demonstrates its versatility.
I chose to study YOLO because, during my recent internship at a Dental Startup, another intern fine-tuned YOLO to analyize dental x-rays which sparked my interest.
This research paper was easier to understand than I expected. I’m looking forward to studying YOLOv2 and later versions to see how they address the original model’s limitations in both speed and accuracy.
References
YOLO Paper
Step by Step Example
YOLO Demo
YOLO slideshare Materials
DeepSystems YOLO
