1. Introduction
많은 NLP 시스템과 기술에서 단어 간의 유사성 개념이 존재하지 않는다. 이는 단순한 모델에 방대한 양의 데이터를 학습시키는 것이 복잡한 모델에 적은 양의 데이터로 학습시키는 것보다 성능이 좋기 때문이다.
하지만 유사성을 무시한 이런 단순한 기법은 모델의 성능을 끌어올리는 데에 한계가 있는 등의 문제가 있다.
One-Hot Encoding
자연어 처리에서 컴퓨터에게 인간이 사용하는 언어를 입력하기 위해서는 수치화가 필요하다.
표현하려는 모든 단어에 대한 벡터를 만들고 해당하는 단어에는 1을, 나머지 단어에는 0을 부여한다.
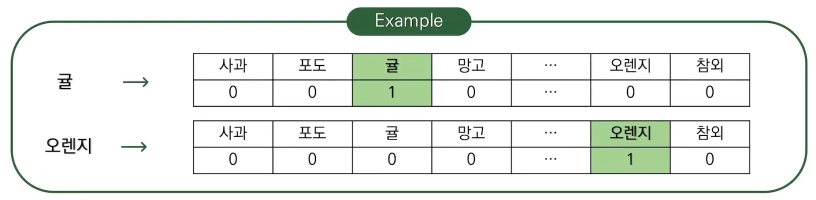
- 차원이 높고, 대부분이 sparse한 벡터가 되기에 정보를 추출하기 어려워진다.
- 단어 간 similarity에 대한 정보를 담고 있지 않다.
위의 문제점들로 단어 자체가 가지는 의미를 다차원 공간에 표현하는 Distributed Representation을 제안했다.
Vector Representation of Words
‘Words that occur in similar contexts tend to have similar meanings.’
다시말해, ‘비슷한 분포를 가지는 단어들은 비슷한 의미를 갖는다’는 가정으로 시작된다.
ex. ‘공부’, ‘열심히’, ‘바쁘다’ 등의 단어들이 주로 함께 등장
→ 이 단어들을 벡터화 했을 때 의미적으로 가까운 단어이다.
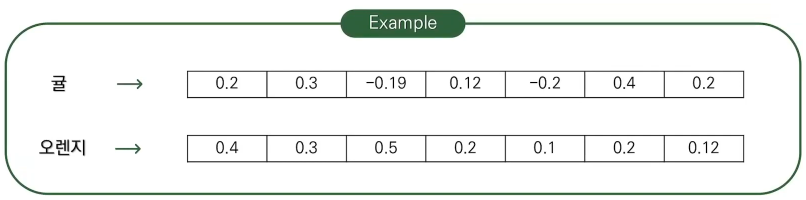
원핫 인코딩의 모든 원소들이 값을 가진 벡터로 표현한다.
이점:
- 단어 간의 similarity를 계산할 수 있다. 분산 표현된 벡터들은 단어 간의 유사도를 측정할 수 있게 된다. 공간 상에 맵핑했을 때 가까이 있는 단어들은 유사도가 높고, 반대의 경우는 유사도가 낮다고 판단 할 수 있다.
- Algebric operation이 가능하다. 또한 벡터 간의 연산을 통해 관계를 추론해낼 수 있다.
₩
king-queen, man-woman 간의 벡터가 각각 같은 방향을 갖는다.
→ 비슷한 관계임을 추론할 수 있다.
Goals of the Paper
본 논문의 목표는 대량의 data로부터 높은 수준의 word vector를 학습하는 기술을 제안하는 것이다.
따라서 비슷한 단어는 가까워야 할 뿐만 아니라 유사점을 가지고 있어야 한다.
또한 학습 시간과 정확도에 워드 벡터의 차원가 데이터의 양이 어떠한 영향을 주는지 실험을 통해 살펴본다.
덧붙여 모델 비교를 위한 Computational Complexty를 다음과 같이 정의한다.
💡 **Computational Complexty:**
2. Previous Work
이 논문 이전에 제시된 word embedding 모델에 대해 설명한다.
Feed-Forward Neural Net Language Model (NNLM)
- Input Layer 현재 보고 있는 단어 이전의 단어들이 one-hot 벡터로 인코딩 되어 input으로 들어간다. 이때 는 Vocabulary의 크기, 은 input에 들어간 이전 단어의 개수이다.
- Projection Layer matrix는 Vocabulary보다 저차원인 에 벡터로 사용되어 Projection Layer에 들어간다. Projection matrix는 matrix가 되어야 한다.
- Hidden Layer Projection layer의 값들은 개의 노드를 가지는 hidden layer로 들어가 각각의 단어의 확률을 계산한다.
- Output Layer 출력값을 정답 단어의 one-hot 벡터와 비교하여 loss를 계산하고 가중치를 업데이트 한다.
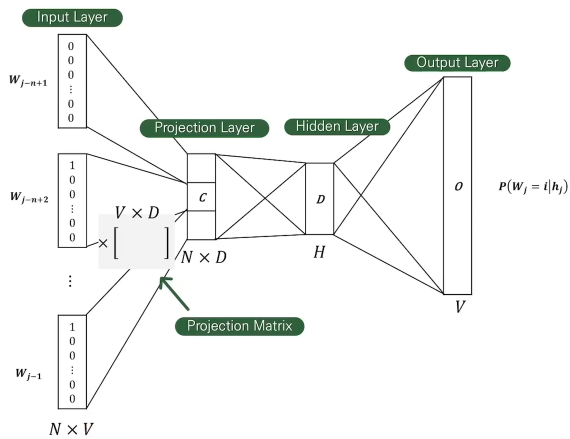
한계:
- History로 사용할 단어의 개수를 고정해주어야 한다.
- History만을 보고 예측하기 때문에 미래 시점의 단어들을 고려하지 않는다.
- Computational Complexity:
Recurrent Neural Net Language Model (RNNLM)
Projection Layer가 없다는 특징을 가지고 있다.
History 단어의 개수를 설정해줄 필요 없이 input으로 들어오는 단어를 순서대로 읽는다.
그리고 Hidden Layer의 값이 다시 Input Layer로 들어온다. (Recurrent)
→ Short-term memory 역할로, 과거 단어를 보는 역할을 한다.
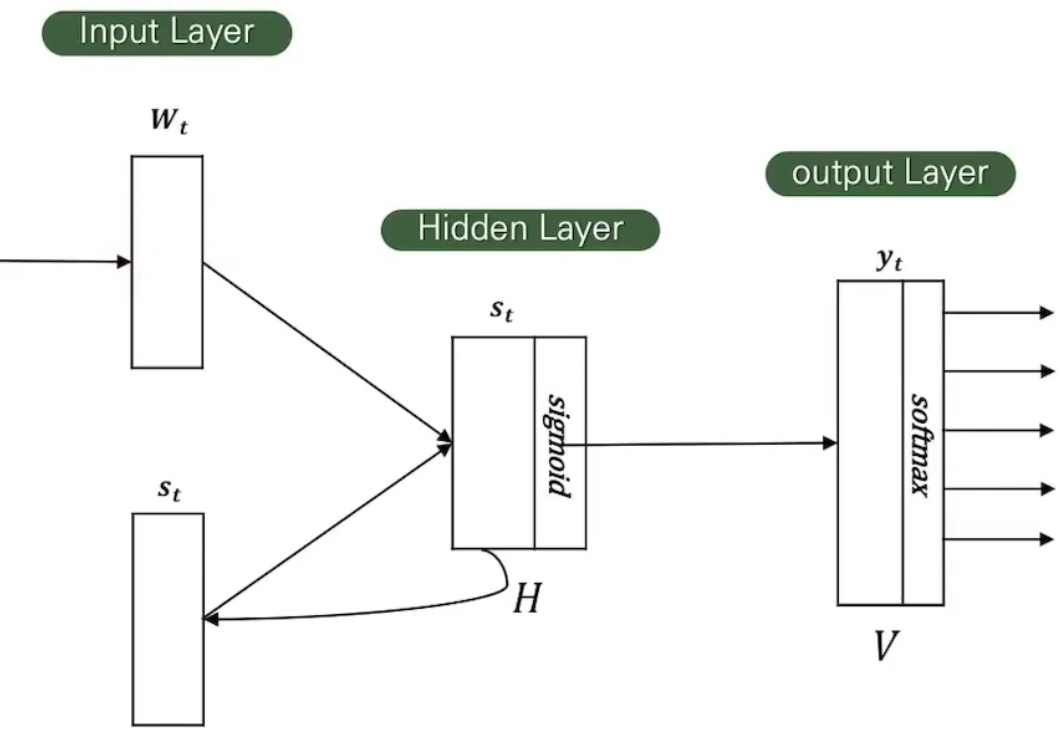
이점:
- Input으로 사용할 단어의 수를 정해줄 필요 없이 학습할 단어를 순차적으로 입력하면 된다.
- Word representation에 사용되는 matrix D는 hidden layer H와 같은 dimension을 갖는다.
- Computational Complexity:
3. Word2Vec
자연어 처리 특성상 많은 데이터를 학습시켜야 해서 학습 속도가 중요하다.
이에, Computer complexity 관점에서 앞선 모델들을 개선하는 모델을 제안했다.
Model Structure
- Distributed representation of words를 학습하는 모델이다.
- Complexity의 대부분이 model의 non-linear hidden layer로부터 야기된다.
→ Feedforward NNLM의 structure를 따른다.
Structure:
- Continuous Bag-of-Words Model (CBOW)
- Continuous Skip-gram Model (Skip-gram)
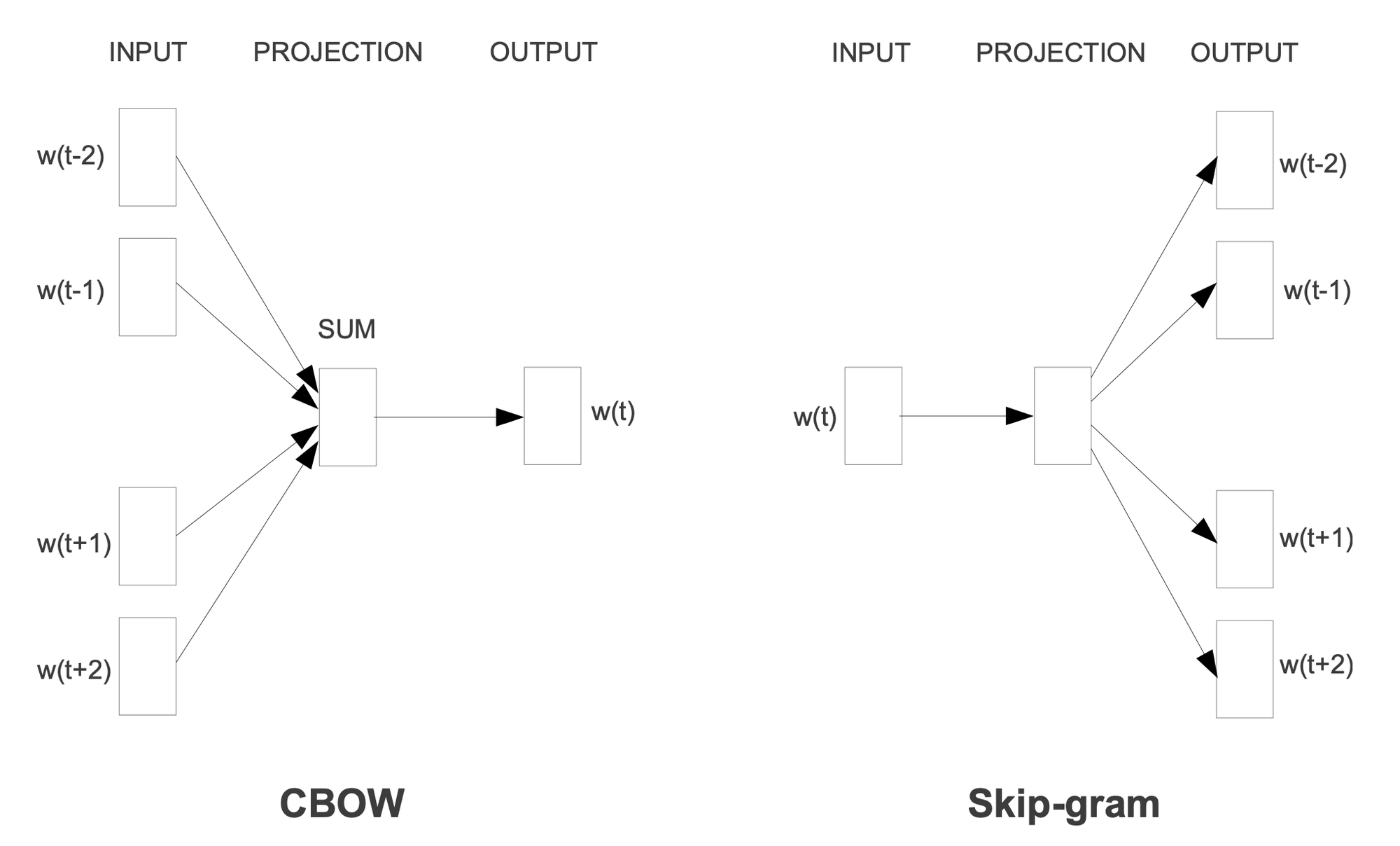
Continuous Bag-of-Words Model
과거의 워드의 순서가 projection의 영향을 받지 않는 ‘Bag-of-Words Model’을 사용한다. 또한 context에 앞으로 나올 단어들을 사용하는 continuos한 distributed representation을 사용한다는 점에서 Continuous Bag-of-Words Model이라 표현된다.
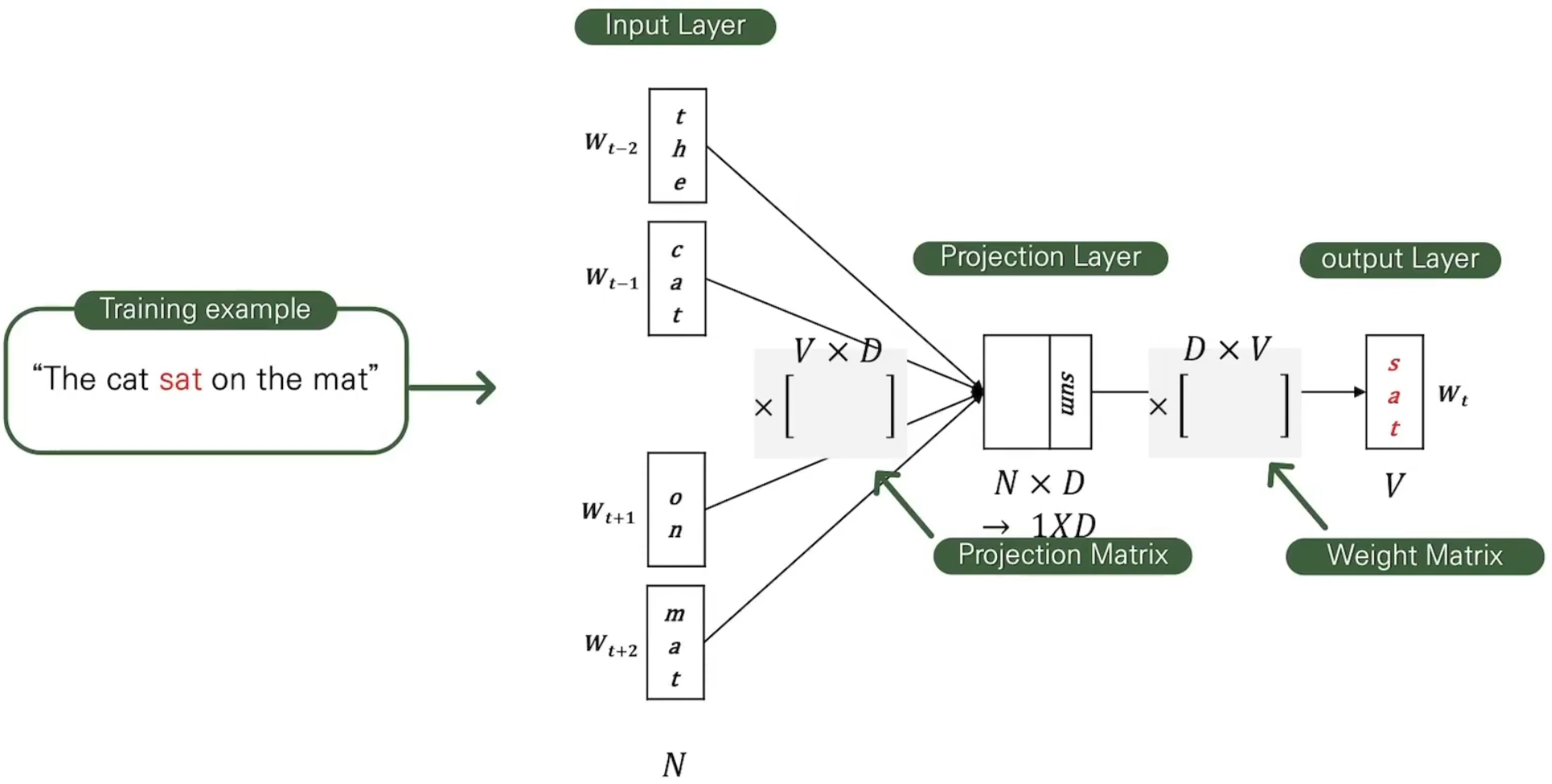
문장의 중간 단어가 정해지고, 앞뒤 2개의 단어가 one-hot 벡터로 input에 들어간다.
그리고 이 one-hot 벡터들은 projection matrix에 의해 projection 되고, 단어별로 프로젝션된 벡터들을 더해 하나의 벡터로 만든다.
벡터는 모든 어휘에 대한 확률을 개선하기 위해 다시 weight matrix를 이용해 벡터로 만든다. 그리고 이 벡터는 softmax로 확률값을 만들고, 가장 높은 확률을 가지는 단어가 중심 단어로 예측된다.
Continuous Skip-gram Model
또 다른 방식은 중심 단어를 input으로 해서 주변 단어를 예측하는 Skip-gram Model이다.
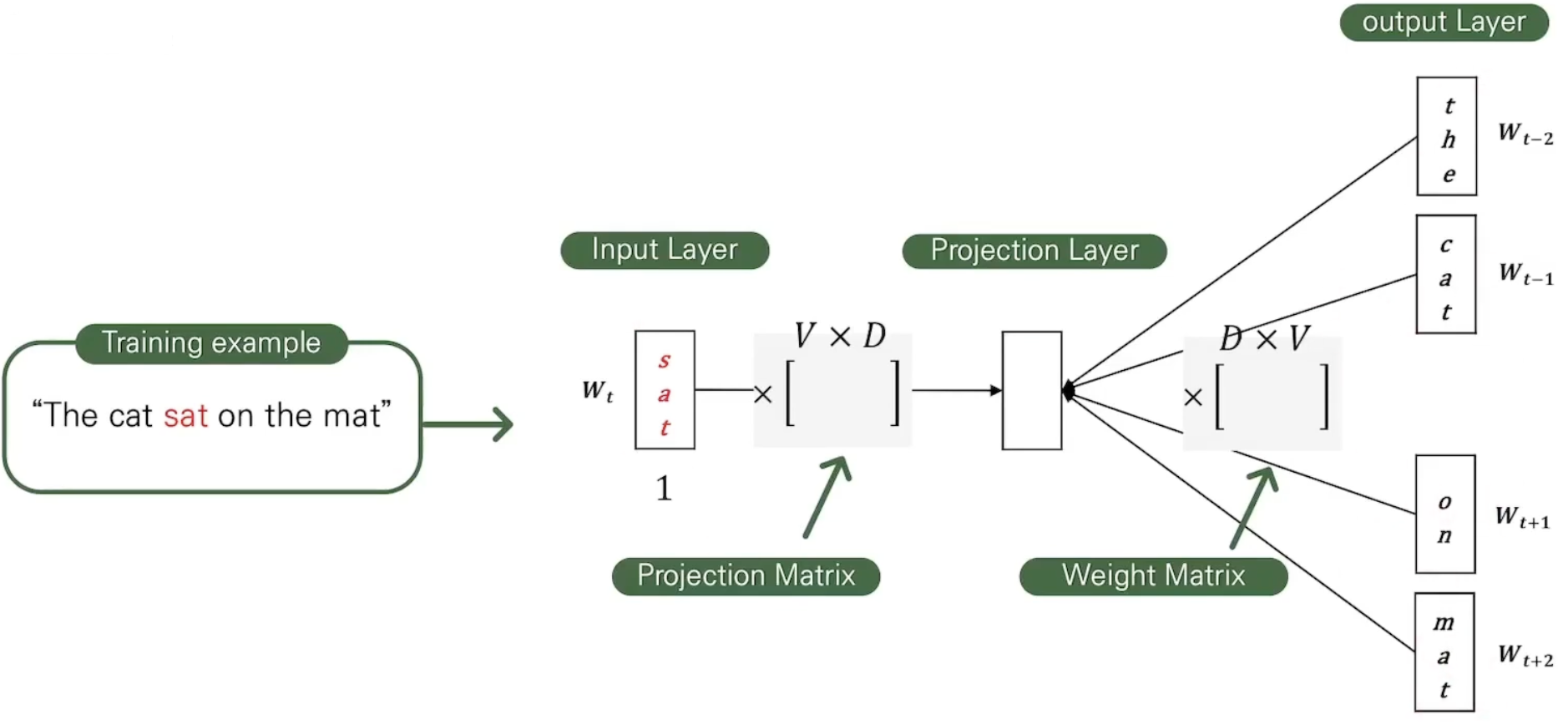
이 모델은 현재 가지고 있는 단어의 주변 시계의 단어를 샘플링하여 예측한다. 가까이 있는 단어일수록 현재 단어와 더 관련있는 단어임을 나타내기 위해 가까이 있는 단어를 더 높은 확률로 택한다.
중심 단어가 one-hot 벡터로 input에 들어가고, 결과적으로 벡터가 되고 이는 주변 단어로 뽑은 단어의 개수 만큼 반복된다.
Ex: “The fat cat sat on the mat”
중심 단어를 ‘sat’이라 할 때, 주변 단어 ‘cat’과 ‘on’이 one-hot 벡터로 인코딩 되어 input에 들어간다.
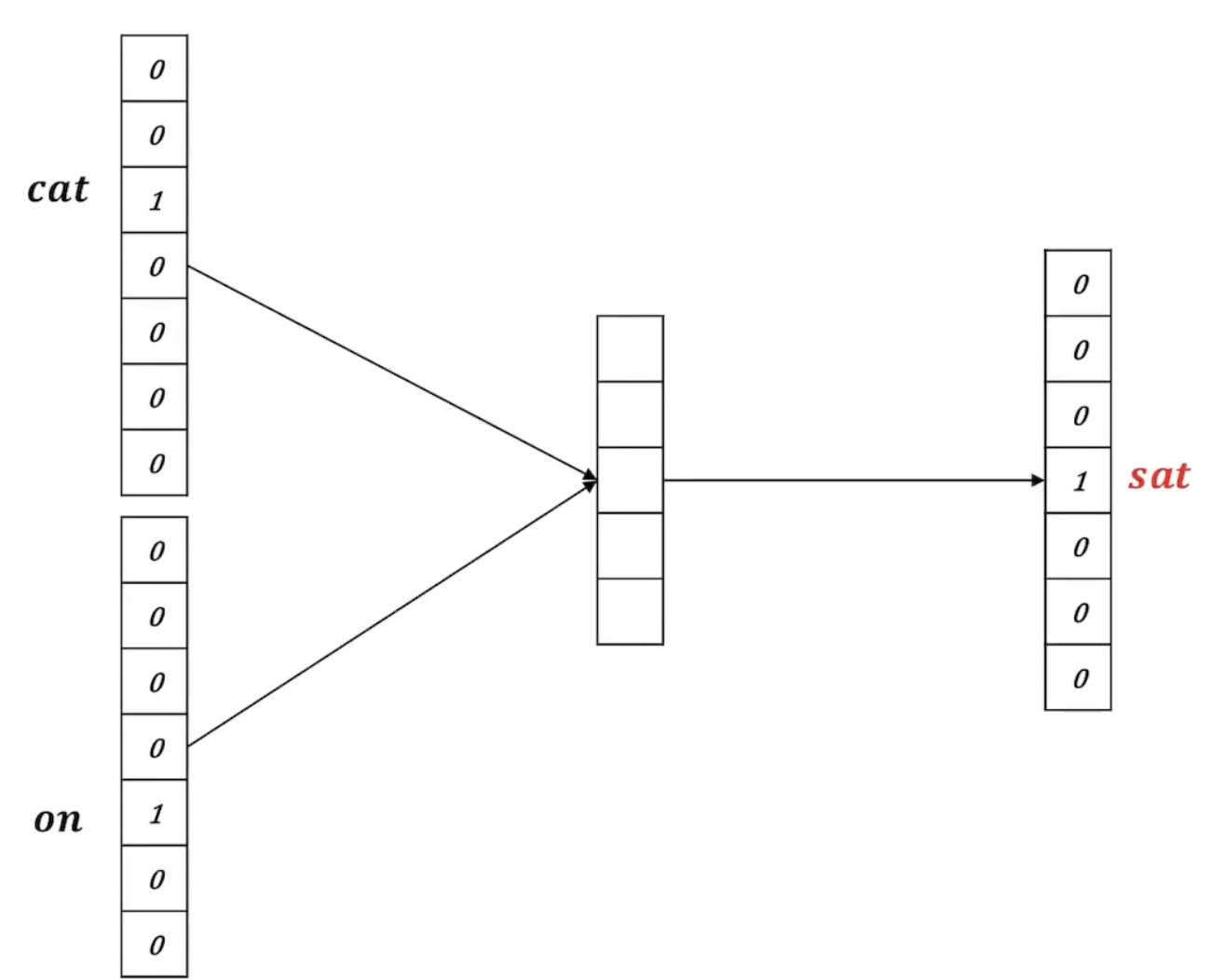
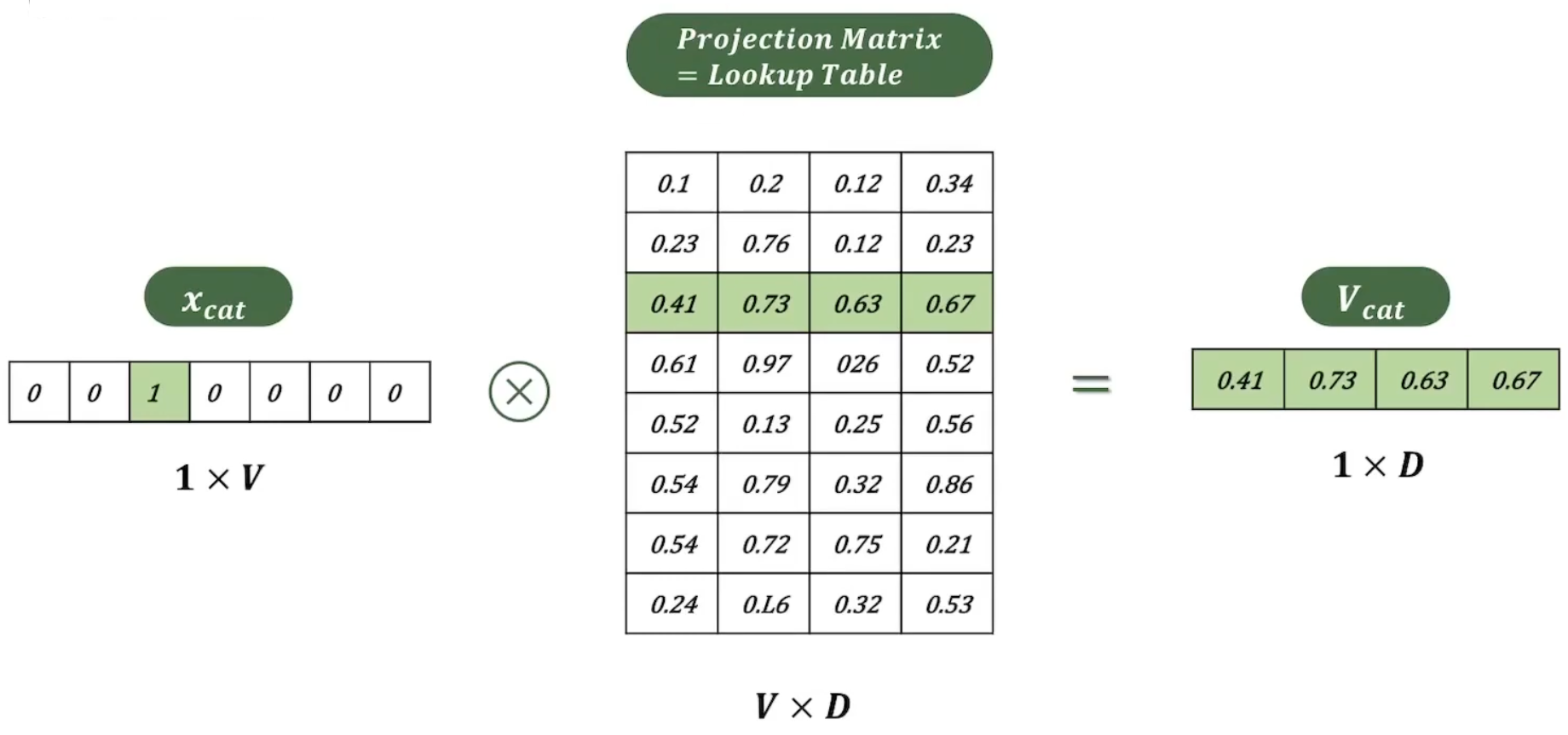
Projection되는 과정
‘cat’ 단어에 해당하는 one-hot 벡터는 ‘cat’ 외의 단어는 전부 0으로 표현된다. 따라서 projection matrix와 곱해지면 ‘cat’에 해당하는 행만 읽게 되는 것과 같아지고, 차원은 로 축소된다.
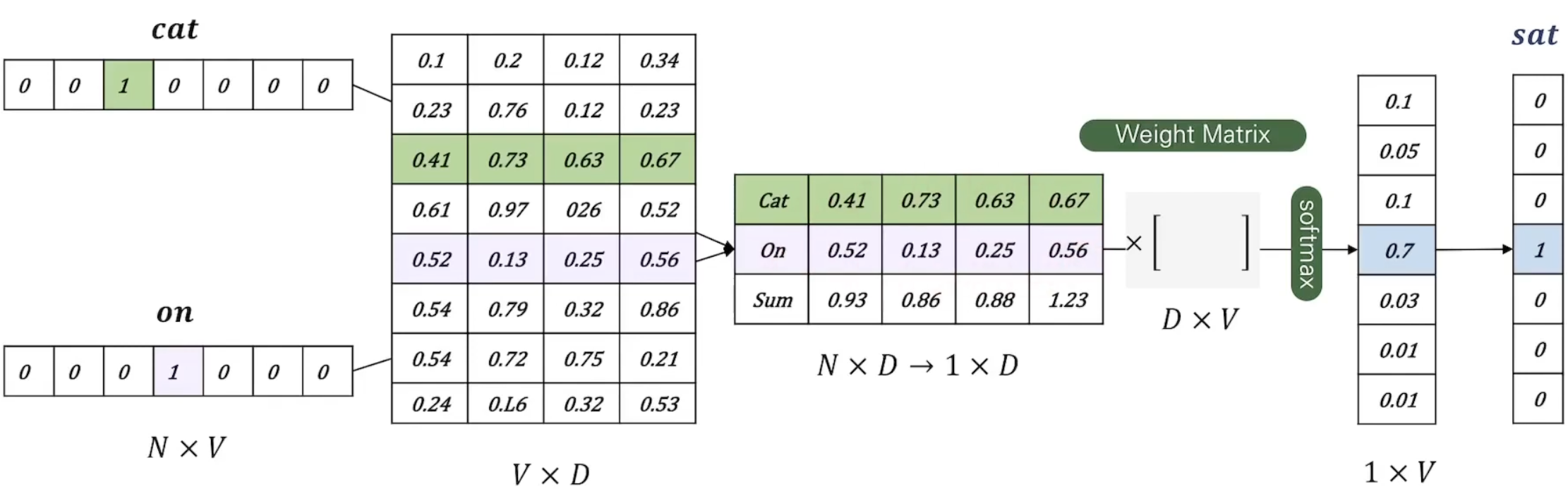
앞선 상황으로 다시 돌아와, ‘cat’과 ‘on’ 두 단어는 projection matrix에 의해 matrix가 되고, 이는 다시 합쳐저 matrix가 된다. 그리고 다시 weight matrix에 의해 벡터가 된다.
벡터에 softmax를 취하고, 이를 통해 얻은 결과를 정답과 비교하여 weight를 업데이트 한다.
Computational Complexity
위의 모델들에 의해 개선된 Computational Complexity를 계산해보자.
CBOW
: 현재 단어를 중심으로 개의 단어를 차원으로 projection하는 복잡도.
: 차원의 projection layer로부터 개의 단어들 각각의 단어의 output layer를 계산하는 복잡도.
Skip-gram
: 현재 단어 하나만 projection하는 복잡도 + projection된 단어 개의 output(확률값) 계산하는 복잡도.
: 개의 단어에 대해 진행해야 하므로 만큼 곱해준다.
2가지 모델 모두 앞선 모델들보다 개선된 시간 복잡도를 갖지만, 여전히 의 곱 만큼 복잡도가 있기에, 학습이 빠르게 진행되기는 어렵다.
는 단어들의 확률값을 구하기 위해 단어마다 softmax를 취하면서 발생하는 복잡도이다.
따라서 높은 성능을 위해서 vocabulary가 커질수록 복잡도는 증가한다.
이 trade-off를 해결하기 위해 ****CBOW와 Skip-gram은 모든 단어에 대해 확률값을 계산하지 않는 Hierachycal Softmax를 사용한다.
4. Complexity Reduction
Hierachical Softmax
단어들에 대해 모든 단어가 리프 노드로 오는 풀-트리를 만들어 단어별 확률을 계산한다.
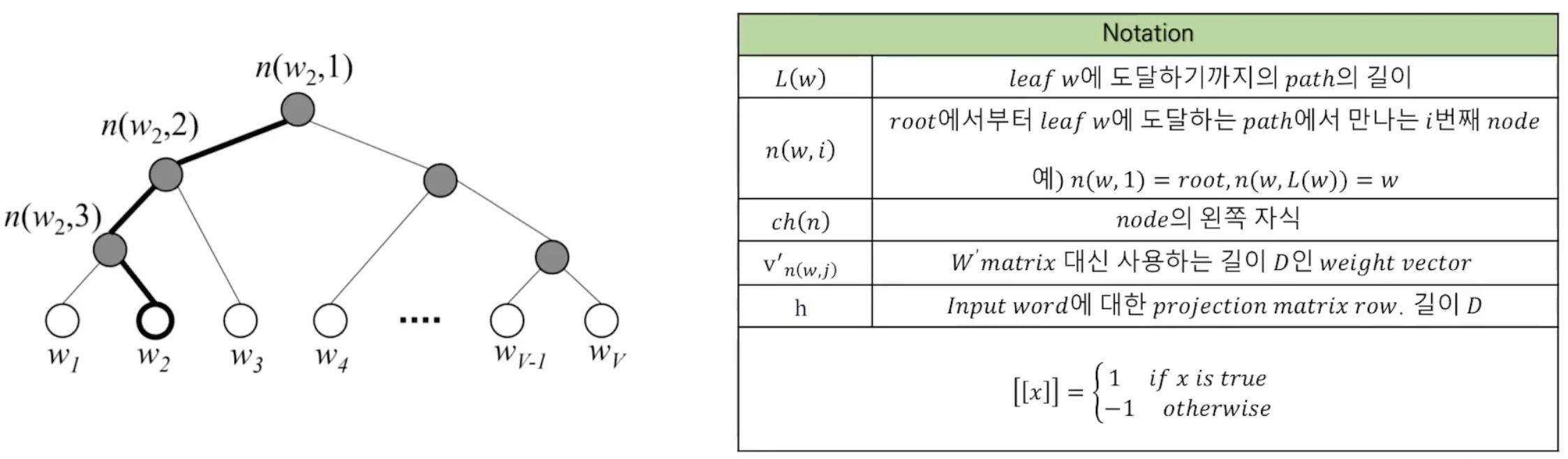
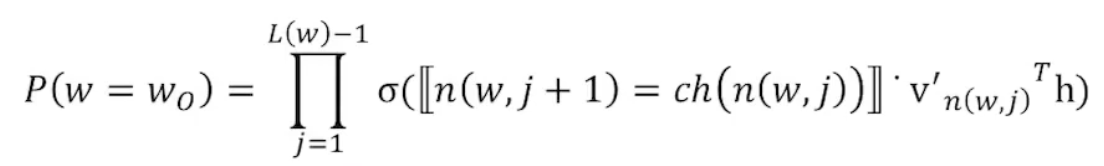
다른 단어에 대한 확률을 구하지 않고도 특정 단어의 값을 구할 수 있다.
Ex.
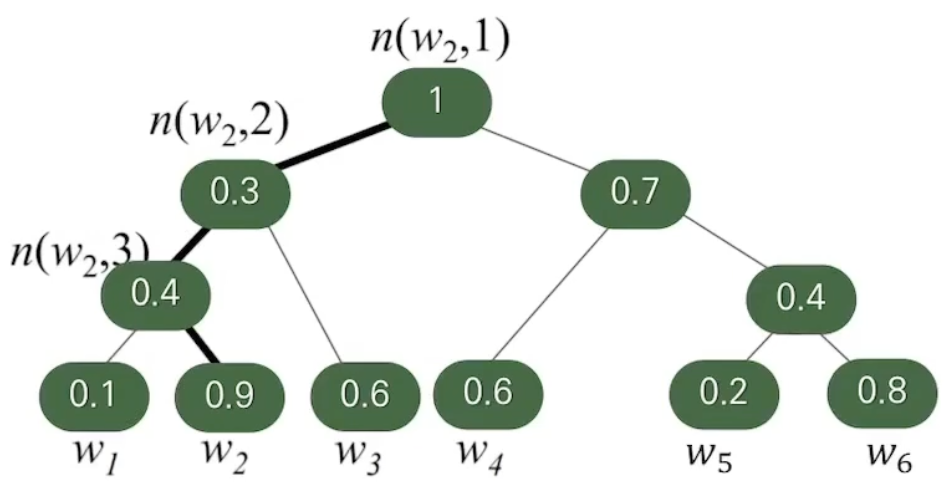
이므로 위의 식이 성립한다.
모든 단어의 값에 대한 계산 없이 전체 합이 1이 되는 확률값을 구할 수 있다.
Softmax가 모든 단어에 대해 output layer의 값을 구하던 이유는 모델이 예측한 단어가 정답일 확률을 구하기 위해 모든 단어에 대한 output 값을 더해 확률을 구했기 때문이다.
Hierarchical softmax는 정답 단어에 대한 확률만을 다른 단어의 확률을 구하지 않고도 구할 수 있게 해준다.
Binary tree의 depth는 에 비례하므로, 기존의 에서 로 복잡도를 줄일 수 있다.
💡 **모델의 최종 Computational Complexity**
5 Evaluation
Test Description
Semantic question 5가지
Syntactic question 9가지
Maximization of Accuracy
정확도를 향상시키기 위해 워드 벡터의 차원과 train set의 사이즈를 조절하여 실험하였다.
CBOW
Train set의 사이즈를 조절할 때 출현 빈도수를 기반으로 했다.
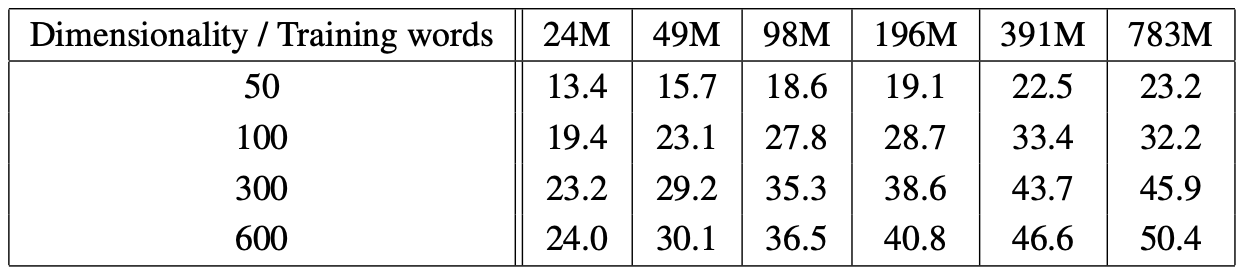
‘단순히 차원수’, ’데이터셋의 크기’ 중 하나만 조절하는 것은 성능 향상에 큰 도움이 되지 않는단 것을 확인할 수 있다.
→ 동시에 2가지 모두 증가시켜야 한다.
이므로, Training data의 양을 두 배로 늘렸을 때 복잡도가 2배 만큼 증가하는데(), 이는 vector 차원을 두 배로 늘렸을 때와 동일하게 증가한다.
→ 어느 하나를 증가시키는 것이 다르지 않기에 둘을 잘 조율해서 다 조절하는 것이 좋다고 한다.
Comparison of Model Architecture
비교 1
Word vector의 차원은 640으로 고정하고, 동일한 Training data를 사용했다.
test set에 있는 3만개의 어휘의 semantic과 syntactic word relationship 질문 모두를 사용했다.
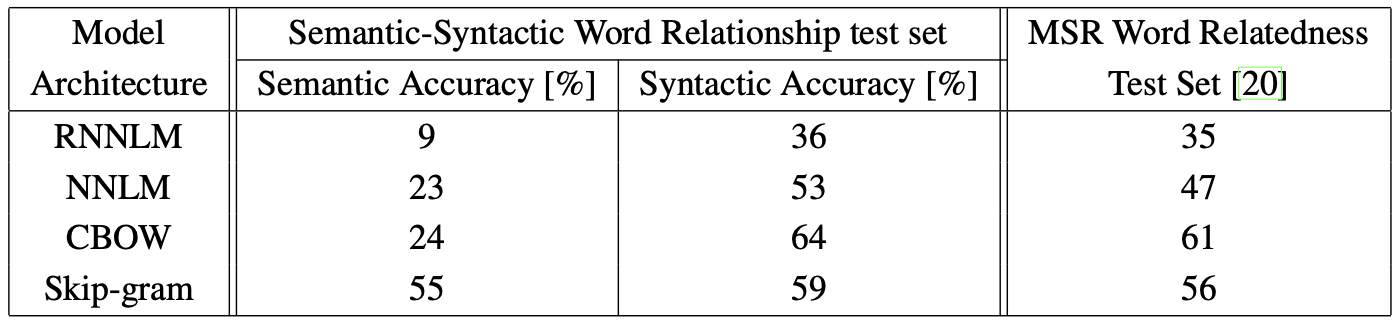
실험 결과, NNLM이 RNNLM보다 좋은 성능을 보였다. 이에 대해 NNLM이 projection layer를 거쳐 hidden layer로 들어가기 때문이라고 설명한다.
CBOW는 syntacitc task에서 NNLM보다 큰 성능 향상을 보였다.
Skip-gram은 syntactic 질문에 대해서는 CBOW보다 약간 성능이 떨어지지만, semantic에서는 가장 좋은 성능을 보여줬다.
비교 2
데이터 사이즈와 epoch, 그리고 벡터 차원에 따른 실험을 진행한 결과이다.
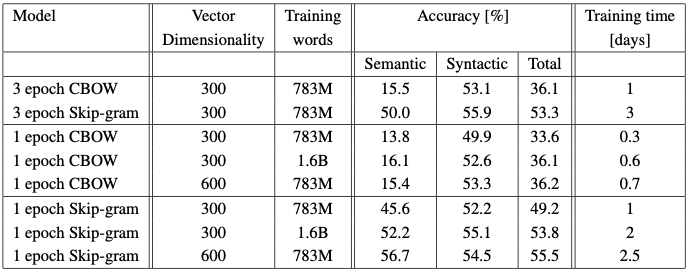
- CBOW와 Skip-gram 둘을 비교했을 때, 모든 경우에서 CBOW가 더 짧은 시간을 보였다.
- 1번째와 2번째 실험 결과를 비교했을 때, 같은 data size로 3번의 epoch을 도는 것보다, 두 배 이상의 data도 epoch 한번을 도는 것이 수행 시간도 짧고, 비슷하거나 더 좋은 결과를 낸다는 것을 확인할 수 있다.
- Training data size를 2배 이상 늘리는 것보다 vector 차원을 2배 늘리는 것이 더 큰 성능 향상이 있었다.
6 Learned Relationships
이 모델을 사용해 도출한 word vector가 단어 관계를 잘 담고 있는지 best word vector를 통해 확인한다.
Word Relationship
Best word vector들을 사용해 도출해낸 word pair relationship의 예시이다.
Skip-gram 모델에 783M개의 단어들을 300개의 차원에서 학습시켰다.
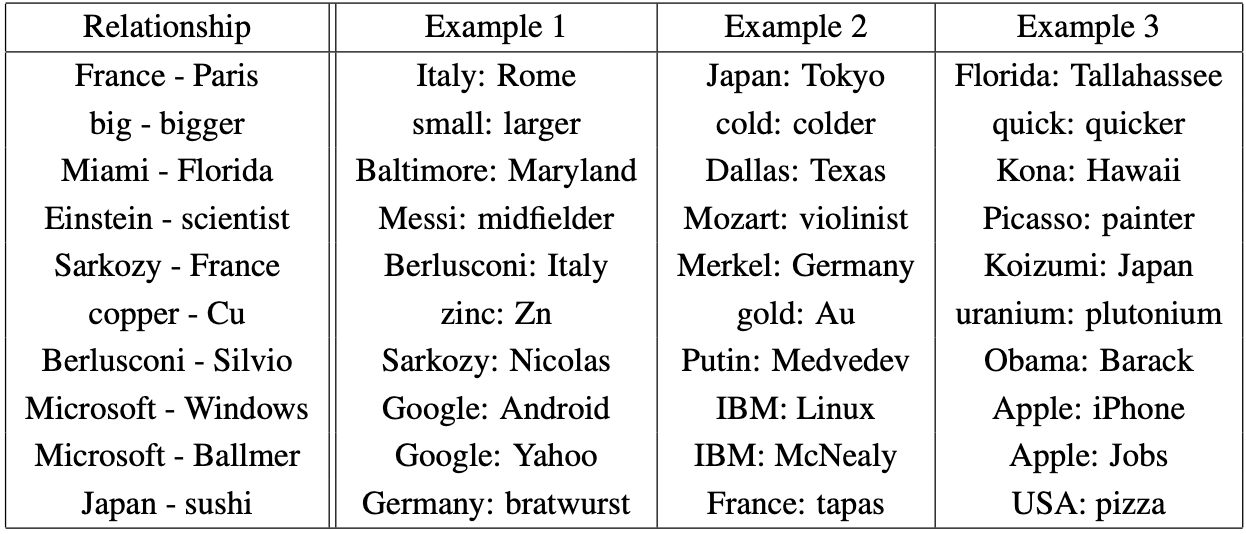
- 두 vector를 뺀 결과에 다른 벡터를 더했을 때의 결과이다.
ex. France - Paris + Italy = Rome - 이 때의 정확도는 약 60%지만, relationship example이 10개 이상 주어졌을 때, sematic-syntactic test에서 정확도가 10%까지 향상될 수 있다고 한다.
7 Conclusion
본 논문으로부터 얻을 수 있는 의의를 살펴보자.
- Hidden layer가 없는 매우 간단한 model 구조를 사용해 feedforward NNLM, RNNLM 같은 NN model과 비교했을 때 높은 퀄리티의 word vector를 train 할 수 있다는 것을 발견했다.
- 다양한 syntactic, semantic language task를 제시하여 word vector가 다양한 의미들에 의한 여러 similarity를 반영하는가를 평가할 수 있었다. ex. Algebric operation
- 이전 모델보다 낮은 계산 복잡도로 훨씬 많은 dataset으로부터 높은 차원의 정확한 word vector를 계산하는 것이 가능해졌다.
- Pre-trained embedding model로써 다양한 NLP task에 사용될 수 있다.
참고자료
https://arxiv.org/abs/1301.3781
https://cpm0722.github.io/paper-review/efficient-estimation-of-word-representations-in-vector-space
https://velog.io/@pabiya/Efficient-Estimation-of-Word-Representations-inVector-Space
논문에 대한 사전지식이 많이 없어 자료를 찾던 중 고려대학교 DBSA 연구실의 유튜브 영상을 통해 많이 도움을 받았다. 본 글 또한 아래의 영상으로부터 많이 참조했다.
