오늘 리뷰할 논문은 word2vec 논문이다. 논문의 목표는 10억 개 이상의 단어를 가진 큰 데이터셋으로부터 high-quality word vectors를 배우는 것이다.
아래 포스트를 먼저 읽으면 도움이 될 것이다.
- [NLP 논문 리뷰] Efficient Estimation Of Word Representations In Vector Space (Word2Vec)
- [논문리뷰] Efficient Estimation of Word Representations in Vector Space(Mikoloiv, Word2Vec)
논문에서는 비슷한 단어가 서로 가까울 뿐 아니라 multiple degrees of similarity를 가질 수 있다는 점에 착안한다. 그리고 단어들 사이 linear regularities를 보존하는 새로운 architecture을 제안해 vector operation의 정확도를 극대화하고자 한다. 이때 similarity of word representations이 단순한 syntactic regularities를 넘어선다고 하는데 word vector에 단순한 algebraic operation을 수행하니, 예를 들어 vector(”King”) - vector(”Man”) + vector(”Woman”)를 하니 vector("Queen")이 나타난 것이다.

먼저 논문에서 사용한 여러 모델들의 model complexity(O)부터 짚고 넘어가겠다. model complexity는 모델을 완전히 학습하기 위해 접근해야하는 parameter 수로 정의된다. E는 training epoch, T는 training set 내의 단어 수, Q는 모델 architecture마다 각자 정의된 값이다.
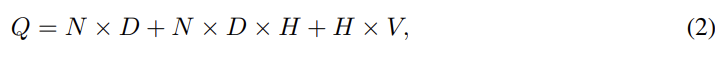
Feedforward Neural Net Language Model (NNLM)의 경우 input, projection, hidden, output layer로 구성된다. (예측할 단어 이전의) N개 단어를 1-of-V coding으로(V는 vocabulary size) input에 넣으면 공유된 projection matrix로 NxD 차원의 projection layer(P)로 project된다. P 다음의 hidden layer(size H)는 vocabulary 내의 모든 단어에 대한 probability distribution을 계산하여 V차원의 output을 내놓는다. 그래서 computational complexity Q는 위와 같다.

Recurrent Neural Net Language Model (RNNLM)는 NNLM의 한계를 극복하고자 제안되었다. context length N을 명시해야하는 NNLM과 달리 RNN은 그럴 필요가 없기 때문이다. RNN은 projection layer가 없으며 input, hidden, output layer만 존재한다. 또 RNN의 특별한 점은 time-delayed connections을 사용하여 hidden layer을 자기자신과 연결하는 recurrent matrix인데, 이로써 일종의 short term memory 역할을 한다. word representations D가 hidden layer dimension H와 같기 때문에 Q는 위와 같다.
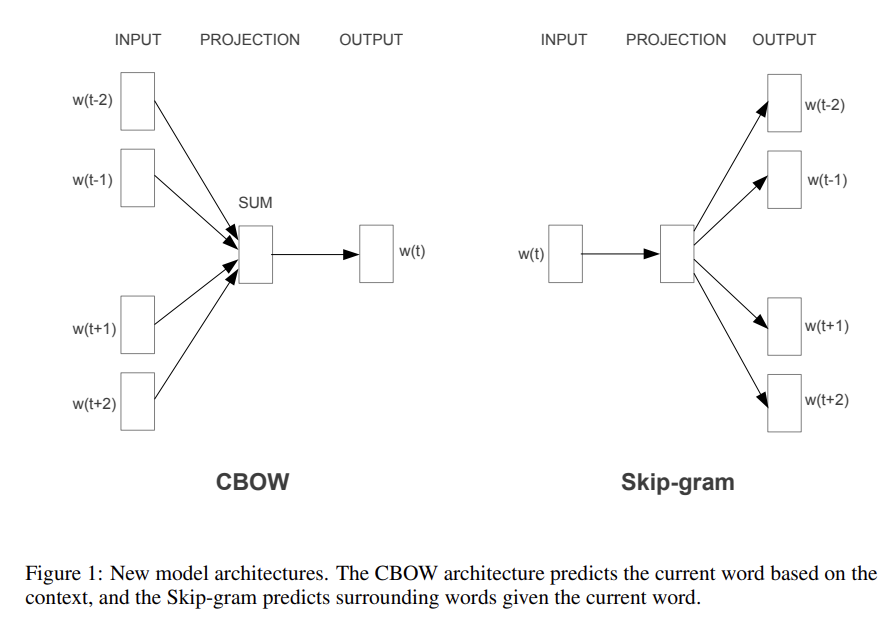
위의 2개가 기존의 모델을 사용한 것이었고, 여기선 단어의 distributed representations를 학습하는 새로운 Log-linear Models 2개를 소개한다. 위의 두 모델들은 non-linear hidden layer 때문에 대부분의 complexity가 발생했다. 그래서 논문은 neural networks보다는 덜 정확할 수 있어도 더 효율적으로 학습하는 더 간단한 모델들을 찾는다. 새 모델들은 2단계로 학습되는데, 1. 단순한 모델을 이용해 continuous word vectors를 학습하고 2. 그 이 distributed representations of words 위에 N-gram NNLM가 학습된다.

이제 두 모델에 대해 알아보자. 첫 번째는 Continuous Bag-of-Words Model이다. NNLM과 비슷한데 대신 non-linear hidden layer가 제거되고 (projection matrix뿐 아니라) projection layer가 모든 단어 사이에 공유된다. 즉, 모든 단어가 같은 위치로 project되어 그들의 vectors가 average되는 것이다. NNLM과 달리 이전(history) 단어만 사용하는 게 아니라 이후(future) 단어도 사용하고, 단어의 순서가 projection에 영향을 끼치지 않기 떄문에 bag of words라고 불린다. Q는 위와 같다.
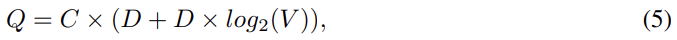
두 번째 모델은 Continuous Skip-gram Model이다. CBOW와 달리 context에 기반해 현재 word를 추측하는 게 아니라 같은 문장의 다른 단어를 바탕으로 단어의 classification을 최대화하는 것이다. 즉, current word를 continuous projection layer를 가진 log-linear classifier의 input으로 넣어 현재 단어 앞뒤로 특정 범위의 단어들을 예측하는 것이다. 범위가 증가할수록 word vector의 quality도 늘어나지만 computational complexity도 늘어난다. Q는 위와 같으며 C는 단어 사이 최대 거리다. train할 때 각 input(=current) word마다 [1:C]사이 랜덤한 수 R를 뽑아 word 앞뒤로 R개 단어를 correct label로 삼아 학습한 것이다.
모델의 성능을 비교하기 위해 기존의 논문들은 예시 단어와, 그와 가장 비슷한 단어를 표로 그려놓고 직관적으로 이해한다. 하지만 여기서는 word vector를 연산해서 단어 사이의 관계들까지 이해한다. 예를 들어 X = vector(”biggest”)−vector(”big”) + vector(”small”)를 연산해 X와 cosine similarity가 가장 가까운 word를 찾아 "smallest"를 찾는 식이다. 또 이렇게 high dimensional word vectors를 큰 데이터에 대해 학습시키면 단어 간 semantic relationships도 알 수 있다.
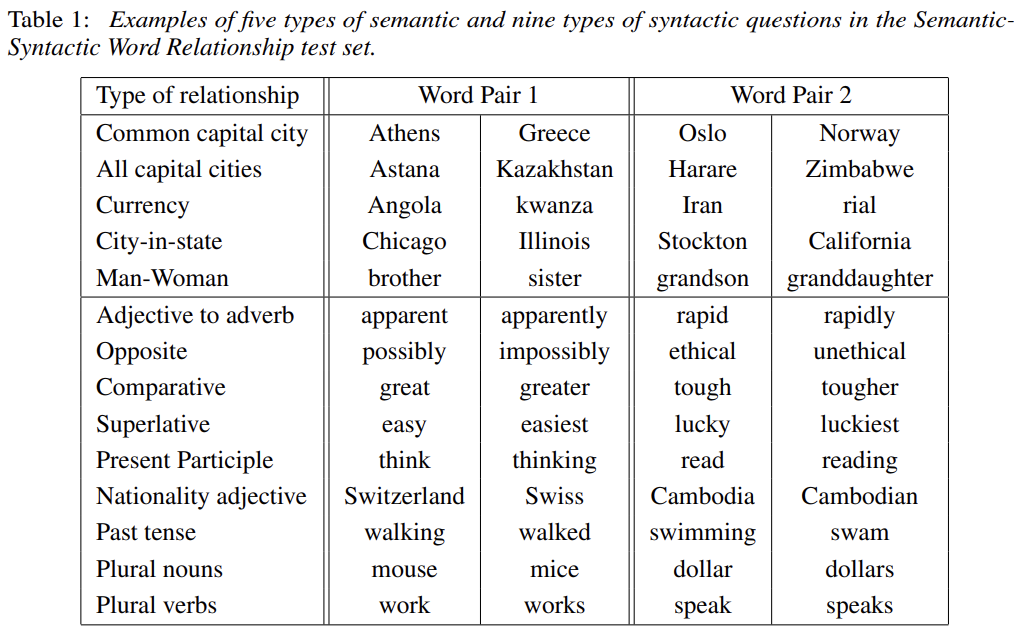
논문은 word vector의 quality를 측정하기 위해 위와 같이 5종류의 semantic 질문과 9종의 syntatic 질문을 정의한다. 총 8869 semantic, 10675 syntactic questions을 만들었으며 test set에는 한 단어짜리(single token words)만 존재한다.
question들에 대해 vector를 compute했을 때 가장 가까운 단어가 question의 correct word와 정확히 일치해야지만 문제가 맞았다고 본다(즉, synonym은 답으로 인정하지 않는다).
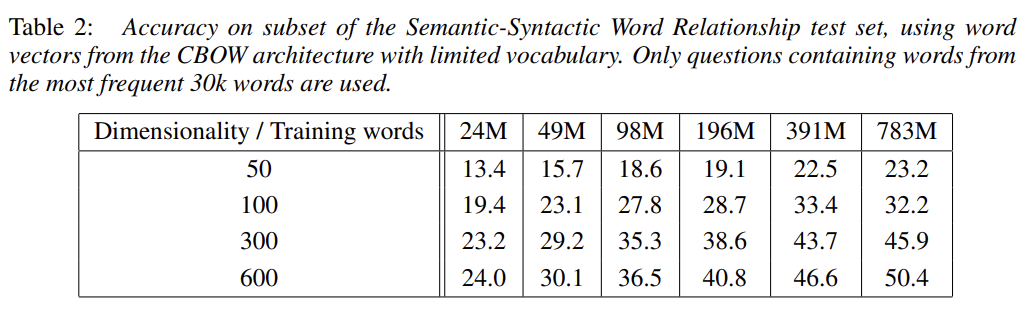
위의 표는 word vector의 dimensionality와 training set크기에 따른 정확도를 보여준다. 너무 dimension이 크거나 너무 train set이 크면 오히려 정확도가 떨어지거나 정확도 증가율이 감소한다. 이는 dimension가 train set이 동시에 커져야한다는 것을 보여준다.
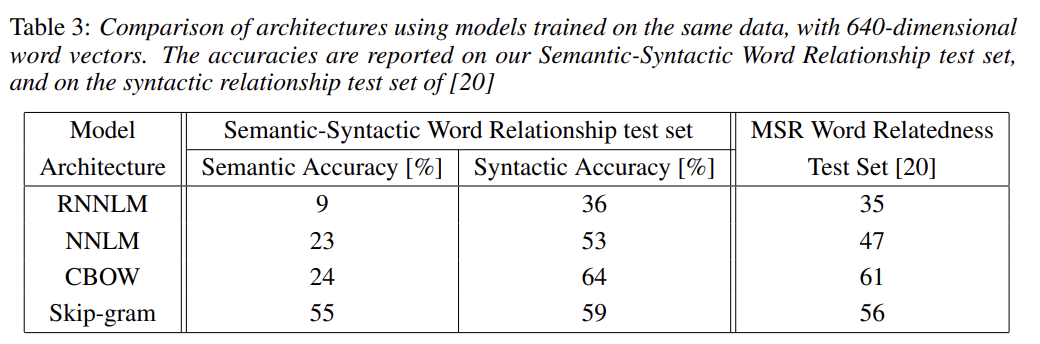
위의 표는 앞에서 설명한 모델들의 성능을 비교한 것이다. RNN은 syntactic question에서 잘 작동하고 NNLM은 RNN보다 상당히 더 잘 작동한다. CBOW는 NNLM과 syntatic에선 더 잘 작동하고 semantic에선 비슷하다. Skip-gram은 syntatic에선 CBOW보다 못하지만 semantic에선 훨씬 좋다.
다른 기존의 모델들과 비교한 표, epoch/dimensionality/train data로 비교한 표도 있는데 리뷰에서는 생략하겠다. 해당 내용은 논문의 Table 4, Table 5에서 확인 가능하다.
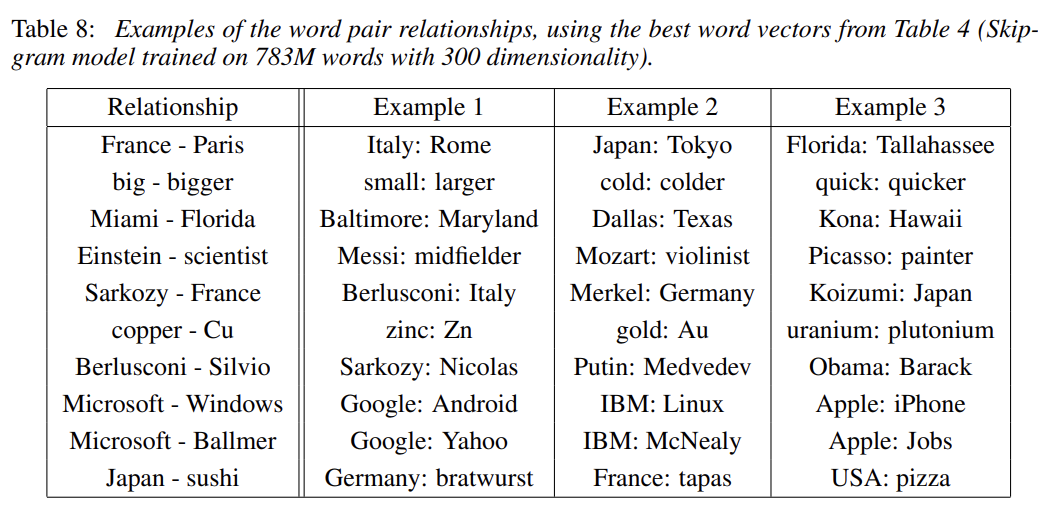
위의 표는 skip-gram 모델이 학습한 relationship의 예시다. 1열 1행을 예로 들어 France - Paris + Italy를 하면 Rome이 나오는 식이다.
논문은 accuracy를 향상시킬 방법도 제안하는데, 하나 말고 여러 relationship example을 제공하여 relationship vector를 average하면 semantic-syntactic test에서 정확도를 향상시킬 수 있다. 또 out-of-the-list word를 선택하는 task에서도 word vector가 잘 작동하는데, list의 word vector들을 평균낸 후 average vector에서 가장 먼 단어를 고르면 된다.
Strengths
- computational complexity에 신경을 쓴 노력이 보인다.
- word vector에서 끝나지 않고 그 관계에 집중한 시도가 참신했다.
- 기존엔 정성적 분석밖에 못했지만 이 논문에선 정량적 분석 방법을 제시해 다른 모델과 비교가 가능한 툴을 제공했다.
Weaknesses
- 여전히 computational 한계가 있는 것 같다.
기존에도 word vector 접근이 존재하긴 했는데 few hundred of millions of words를 50 - 100차원으로 밖에 못 만들었다. 유의미한 지평을 열어준 논문 같다.
이것도 내용이 신기해서 한 번 코드로 실습해보고 싶다.
