Goal
이번 포스팅에서는 데이터 전처리 방법과 실제 구현 코드에 대해서 설명한다.
[1] 데이터 셋
데이터 셋 개요
본 시리즈에서 사용하는 데이터 셋은 19년도에 인하공업전문대학교 실험실에서 취득한 에스컬레이터 모형의 체인 소음 데이터를 사용한다.
<데이터셋 상세 내용>
- 데이터 형태 : 1열짜리 소음 데이터 (엑셀 파일)
- 샘플링 레이트 : 20Khz
- 데이터 양 : 1,200만개 (약 10분동안 취득)
- 레이블 : 정상 데이터 / 감속기 기어의 이(Tooth)가 1개 빠진 상태에서 취득한 이상 소음 (검증 / 테스트 시에만 사용)
- 에스컬레이터 모형

- 엑셀 형태의 데이터
[2] 전처리 방법
실제 구현된 코드를 보기 전 로우 데이터를 LSTM AE 네트워크의 입력데이터로 만들기 위한 세가지 전처리 과정을 소개한다.
데이터 형태 변환
-
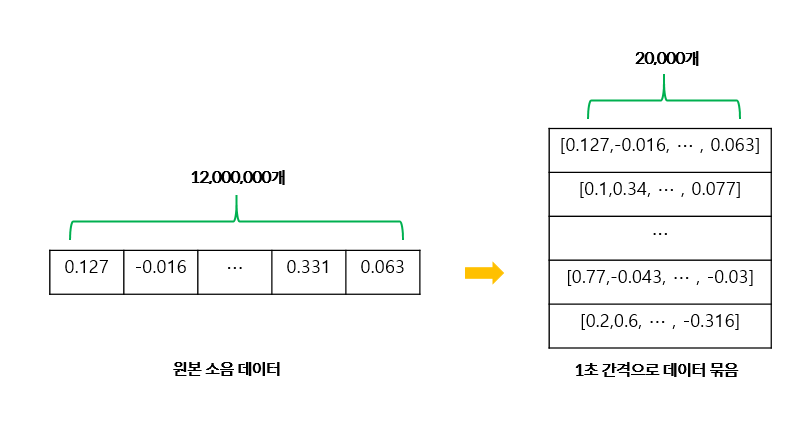
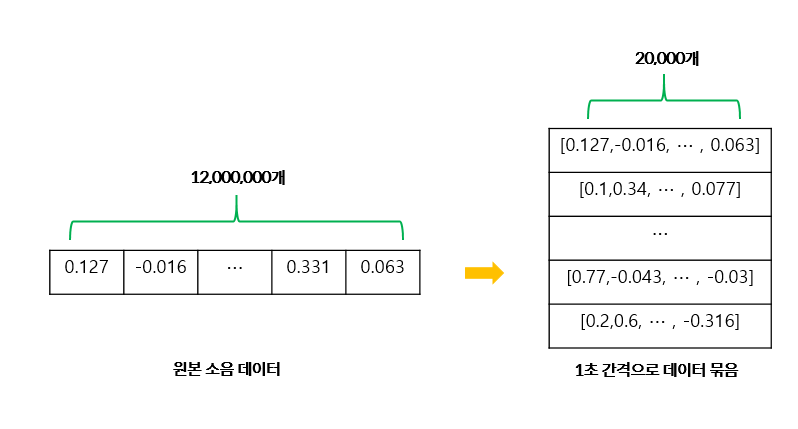
로우 데이터는 1,200만 개의 1열짜리 형태로 이루어져 있는데, 1초 동안 들어온 소음 데이터를 1개의 입력 데이터로 사용하기 위해 20,000개씩 600열로 형태를 변환하였다.
-
데이터 형태 변환 흐름 예시
데이터 정규화
학습 시 알고리즘은 데이터가 가진 특성을 비교해서 정상 데이터의 패턴을 찾는다.
그런데, 데이터가 가진 특징(Feature)의 스케일이 차이가 들쑥날쑥하면 학습에 부정적인 영향을 끼치게 된다.
이런 문제를 방지하고자 데이터의 특징이 동일한 정도의 스케일(중요도)로 반영되도록 하는 것이 정규화(Normalization)이다.
정규화 방법에는 Min-Max 정규화, Z-score 정규화, 표준 정규화(Robust) 등 많은 방법이 있는데, 본 포스팅에서는 가장 많이 사용되는 Z-score 정규화를 진행했다.
- 정규화 종류 별 예시
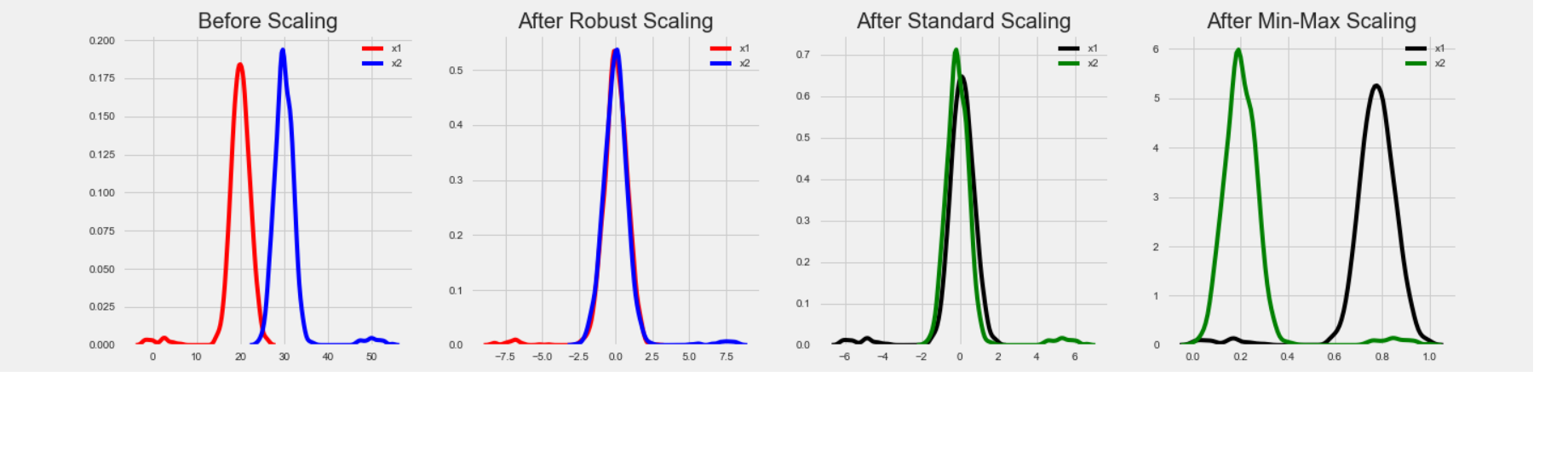
출처 : https://www.geeksforgeeks.org/standardscaler-minmaxscaler-and-robustscaler-techniques-ml/
데이터 차원 변환
LSTM AE는 네트워크 셀이 LSTM 셀로 되어있다.2번까지 진행된 데이터는 2D 형태이기 때문에 LSTM 셀의 입력 형태로 맞추기 위해 각 데이터셋을 아래와 같이 3차원 형태로 변환한다.
- (20,000, 600) => (N, 1, 600)
[3] 구현 코드
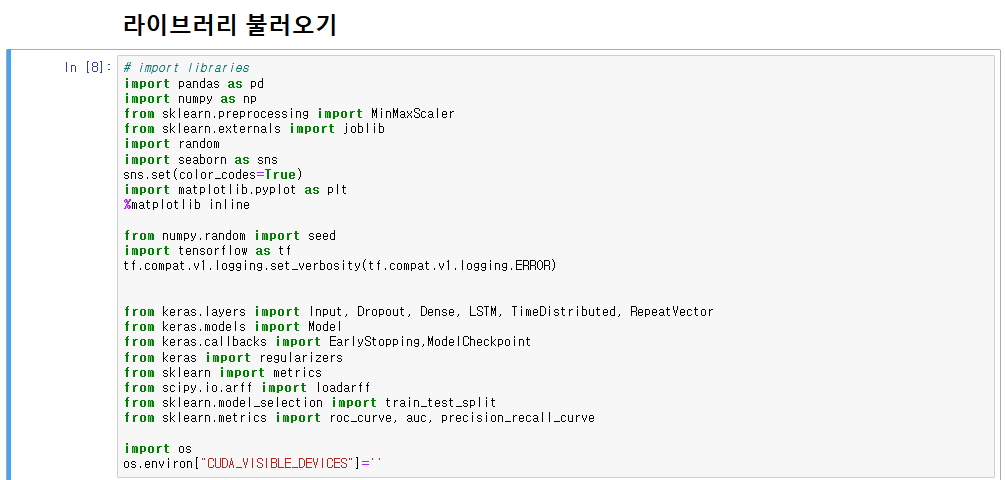
0. 라이브러리 불러오기
- 본 프로젝트에서 구현 시 사용할 라이브러리를 불러온다.
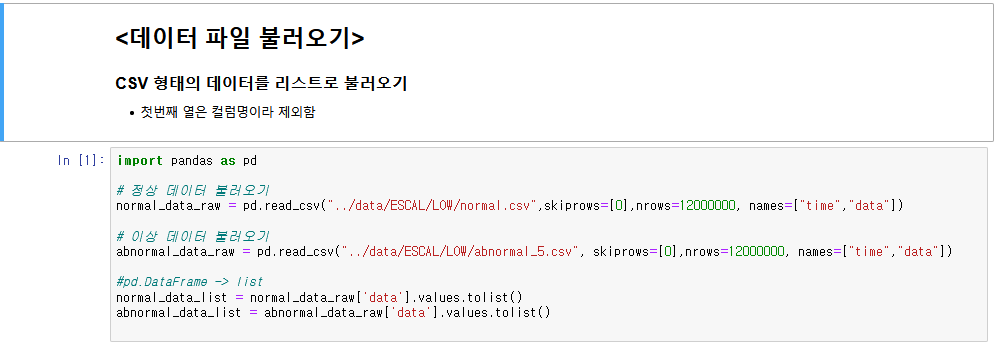
1. 데이터 불러오기
- CSV 형태로 되어있는 데이터를 pandas 라이브러리를 사용해 불러온다.
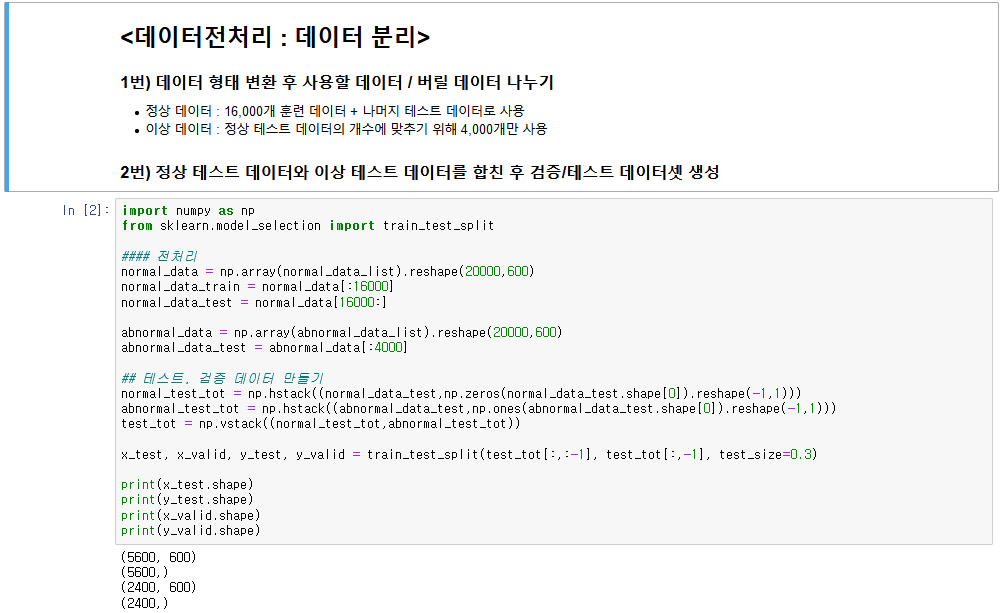
2. 데이터 셋 분리
- 정상, 이상 데이터를 아래와 같이 분리해서 훈련 / 검증 / 테스트 데이터셋을 만든다.
3. 데이터 정규화
- Sklearn의 StandardScaler 라이브러리를 사용해서 훈련 / 검증 / 테스트 데이터를 정규화한다.

4. 데이터 차원 변경
- 정규화된 훈련 / 검증 / 테스트 데이터를 LSTM 셀 입력 데이터 형태로 맞추기 위해 각각 3차원으로 차원을 변경한다.

다음 포스팅에서는 전처리한 데이터를 학습하는 과정을 다룬다.


안녕하세요! 포스트 잘 잘 읽었습니다. 혹시 사용하신 데이터셋은 어디서 구할 수 있는지 여쭤보고 싶습니다. 감사합니다.