Goal
이번 포스팅에서는 지난 포스팅에서 학습한 모델에 대한 성능 평가와 최종 테스트 과정에 대해 다룬다.
[1] 모델 성능 평가
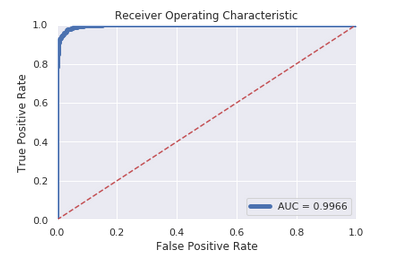
본 프로젝트에서는 분류 모델에서 많이 사용되는 AUROC 평가 지표를 사용해 학습이 완료된 모델의 성능을 평가했다.
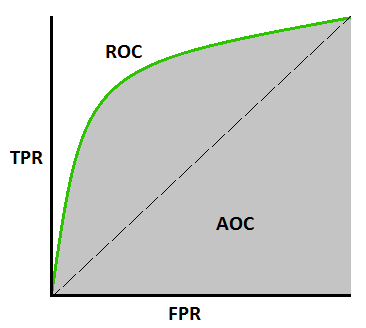
AUROC에 대해 설명하려면 ROC Curve에 대해 알아야 한다.
ROC 곡선
임계값을 변경해가며 데이터에 대한 이진분류기의 성능을 하나의 그래프로 표시한 것으로 각 X, Y축은 아래와 같다.
- X축 : 실제 정상 데이터를 이상 데이터로 예측한 비율 FPR(False Positive Rate)
- Y축 : 이상 데이터를 이상 데이터로 정확하게 예측한 비율 TPR(True positive rate)
AUROC 지표
- 분류 모델의 성능 지표로, ROC 곡선의 아래 면적 값을 의미한다.
- AUROC를 통한 모델 평가 시 AUROC 값은 0.5 이상이어야 하고 1에 가까울수록 좋은 성능이다.
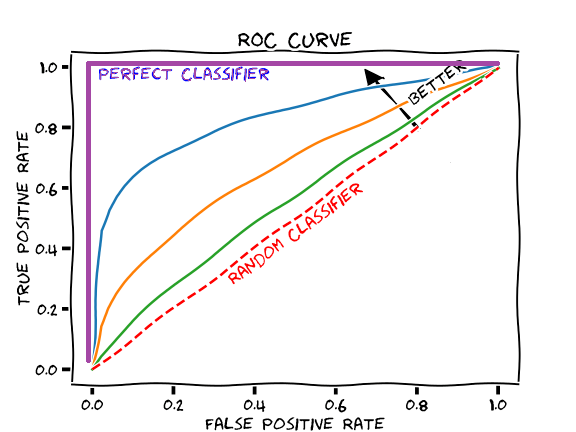
출처: https://glassboxmedicine.com/2019/02/23/measuring-performance-auc-auroc/
[2] 테스트
평가 지표 종류
모델에 대한 성능 평가 이후 테스트 데이터에 대한 최종 테스트를 진행한다.
분류 모델의 평가 지표로는 아래와 같은 것들이 있다.
각 데이터 셋의 특성에 맞게 알맞는 평가지표를 사용해야 한다. (매우 중요)
- 정확도 (Accuracy) : 전체 데이터 중 제대로 예측한 비율
- 정밀도 (Precision) : 예측한 정답 중 실제 정답의 비율
- False를 True라고 판단하면 안되는 데이터의 경우 정밀도를 사용하는 것이 좋다.
- 재현율 (Recall) : 실제 정답 중 예측된 정답의 비율
- True를 False로 오인하면 안되는 데이터의 경우 재현율을 사용하는 것이 좋다.
- F1 점수 (F1 Score) : 재현율과 정밀도의 조화평균으로 재현율과 정밀도가 얼마나 조화를 이루는지에 대한 점수이다.
- 클래스 불균형 문제가 있는 데이터의 경우 F1 Score를 사용하는 것이 좋다.
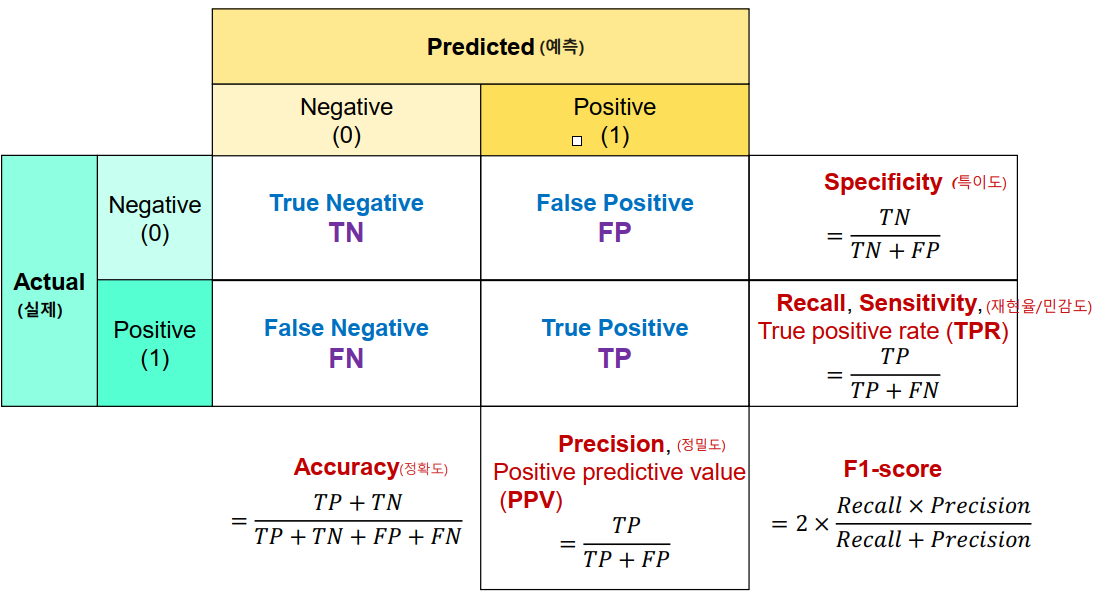
출처 : https://ysyblog.tistory.com/72
평가 지표 선택
본 프로젝트에서는 클래스 불균형 문제가 없기 때문에 정확도(Accuracy)를 선택했다.
도출한 방법은 위의 Accuracy 공식인 TP+TN / TP+TN+FP+FN 으로 구하면 되는데
일일히 구하지 않고 Confusion Matrix를 사용해서 TN, FP, FN, TP를 한번에 구해서 Accuracy를 측정했다.
Confusion Matrix (혼돈 행렬)
- 분류 모델이 성능을 평가할 때 사용하는 지표
- 테스트 데이터 분류 결과의 TN, FP, FN, TP 값을 계산해준다.
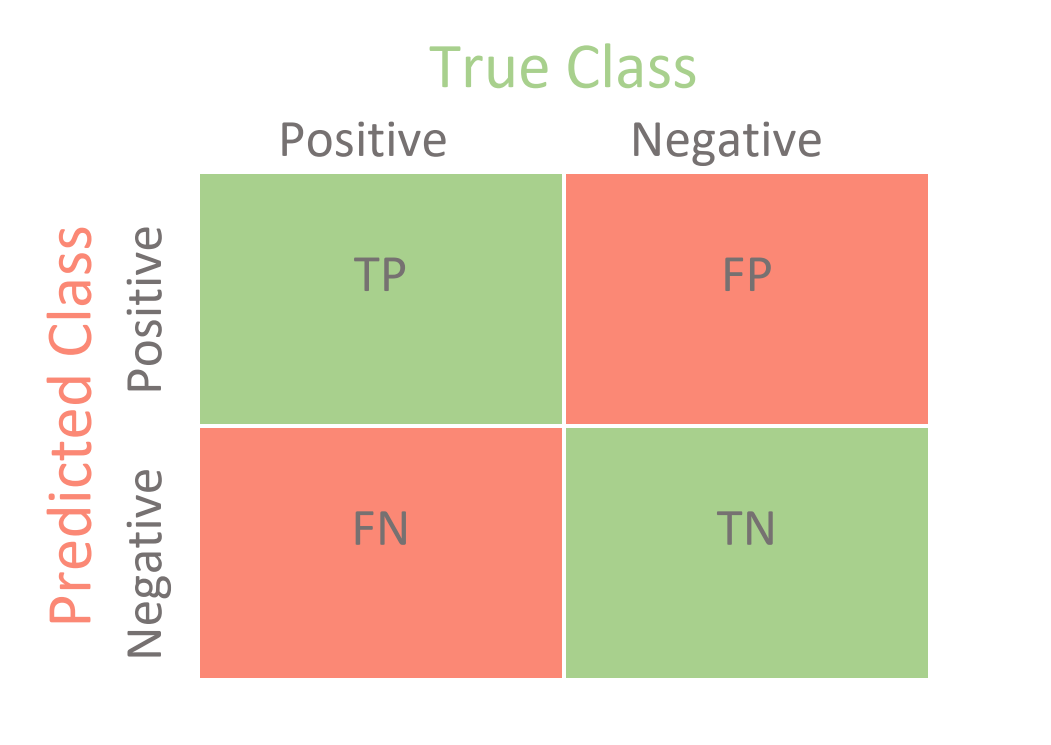
출처 : https://towardsdatascience.com/confusion-matrix-for-your-multi-class-machine-learning-model-ff9aa3bf7826
[3] 구현 코드
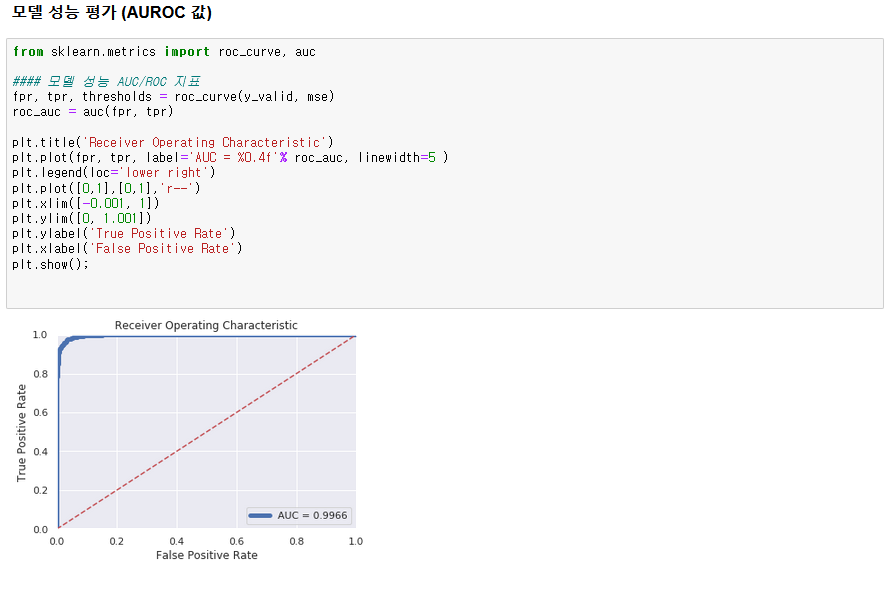
1. 모델 성능 평가
- 검증 데이터에 대해 Sklearn의 roc_curve 라이브러리를 사용해서 임계값 별 FPR, TPR 값을 도출한다.
- Sklearn의 auc 라이브러리를 사용해 AUROC 값을 도출하고, Matplotlib의 Pyplot을 사용해 시각화 한다.
- AUROC : 0.9966
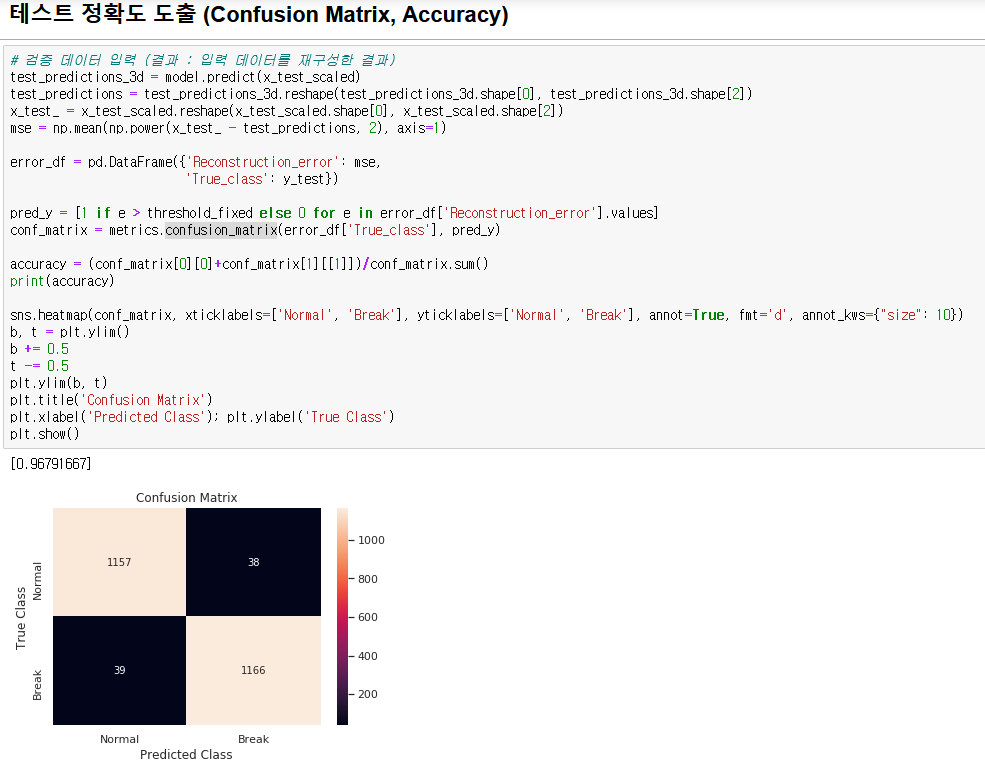
2. 테스트
- 테스트 데이터에 대해 Sklearn의 confusion_matrix 라이브러리를 사용해 TN, FP, FN, TP 값을 2차원 리스트 형태로 받는다.
- 공식을 사용해 정확도(Accuracy)를 도출한다.
- 테스트 결과 정확도 : 0.9679
3. 테스트 결과 시각화
- 테스트 데이터를 모델에 입력한 결과인 MSE값을 PR Curve로 설정한 임계값과 비교하여 정상/이상을 구분하였다.
- 그 결과 아래와 정상 데이터와 이상 데이터를 잘 분류 해내는 것을 확인했다.
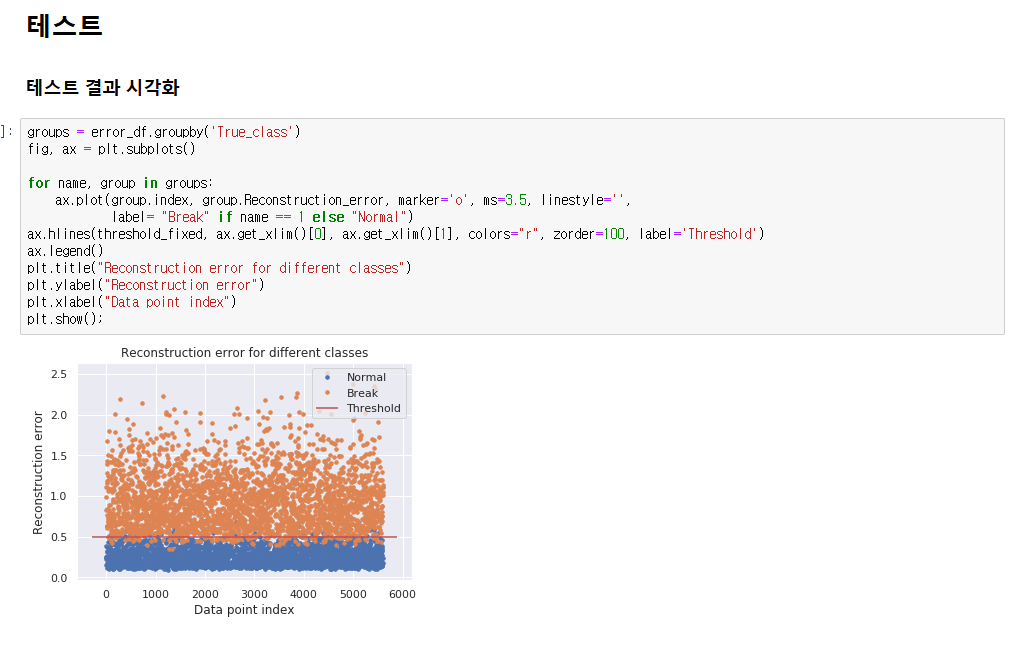
[4] 결론
- 딥러닝을 사용한 이상 탐지 방법론 중 정상 데이터만 사용하여 학습하는 비지도 학습 기반의 LSTM AE 딥러닝 알고리즘을 사용해 에스컬레이터의 이상을 감지하는 모델을 생성했다.
- 정밀도-재현율 그래프를 사용해 최적의 임계값을 설정했고, AUROC를 사용해 모델 성능을 평가한 결과 0.9966이라는 높은 수치의 결과를 도출했다.
- 최종적으로 테스트 데이터에 대해 Accuracy 지표를 사용해 도출한 결과 0.97이라는 높은 정확도를 기록했다.
- 이번 실험에서는 결과적으로 높은 정확도로 이상 데이터를 탐지해냈지만, 사용한 데이터 세트가 현장의 소음이 섞이지 않은 데이터이기 때문에 현장의 소음이 섞인 데이터를 확보 후 추가 연구를 진행할 예정이다.

6년차 서버 개발자입니다!