MySQL InnoDB 에서 Record Lock, Gap Lock, Next Key Lock 원리와 사용시 주의점(Record Lock 사용시에는 적절한 인덱스가 있는 컬럼으로 사용해야한다.)
MySQL
N줄 요약
- InnoDB 스토리지 엔진 레벨의 락이 존재하며 해당 락은
Record Lock,Gap Lock,Next Key Lock(Record Lock + Gap Lock)이 있다.- InnoDB 에서 레코드는 인덱스(Clustered Index)로 관리되며 해당 인덱스에 락이 걸린다.
Gap Lock은 행과 행 사이 존재하지 않는 범위에 대해 락을 걸 수 있으며supremum pseudo-record라는 가상의 레코드를 만들어서 락을 건다.- Record 락은 인덱스를 통해 탐색한 레코드에 락을 걸기 때문에 적절한 인덱스가 추가되어있지 않는 쿼리를 통해 락을 걸면 의도하지 않은 범위에 락이 걸릴 수 있으니 주의해야한다.
들어가며
MySQL은 계층적으로 전체 애플리케이션이 있고 내부적으로 스토리지 엔진(InnoDB, MyISAM) 이 존재한다.
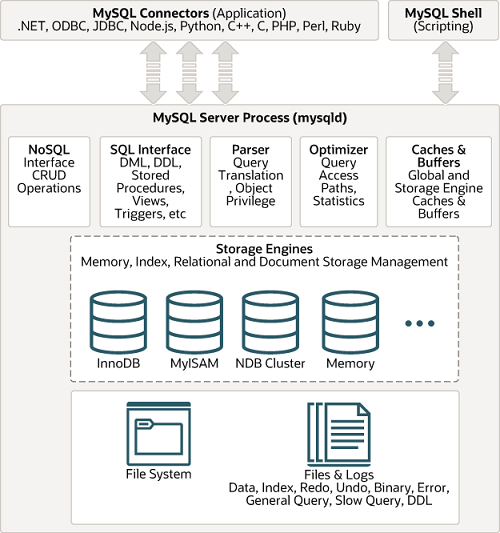
위 사진의 전체 구조가 MySQL 애플리케이션이고 내부적으로 계층형으로 파서, 옵티마이저, 스토리지 엔진 등 계층형 구조로 이루어져있다.
이런 계층형 구조에 맞게 MySQL이 제공하는 Lock 메커니즘 역시
- 전체 MySQL 애플리케이션 레벨에서 사용가능한
Named Lock- 스토리지 레벨에서 제공하는 락 (
Auto Increment Lock,Record Lock,Gap Lock,Next Key Lock)
으로 계층적으로 별도의 락킹 기법이 존재한다.
저번 글에서는 Named Lock 이 무엇이고 해당 락 사용시 어떤점을 주의해야 하는지에 대해 주안점을 두고 알아봤다면, 이번에는 스토리지 엔진 레벨에서 동기화를 위해 사용하는 락에 대해 먹어보면서 어떤 특징이 있는지 알아보자.
구체적으로 Record Lock, Gap Lock, Next Key Lock 의 동작 구조와 어떤식으로 락이 걸리는지 그리고 해당 락을 사용시에 주의점에 주안점을 두고 정리해본다.
Storage Engine(InnoDB) 에서 제공하는 Lock?
스토리지 엔진이라고 표기했지만 이 글에서는 범용적으로 많이 사용하는 InnoDB Storage Engine 에서 제공하는 Lock 기법에 대해 다루려고 한다.
Storage Engine 자체적으로 여러 요청이 동시다발적으로 처리되는 상황에서 동기화 메커니즘을 위한 락킹 기법을 제공하는데 테이블 레코드 단위로 락을 걸 수 있다.
MySQL 8.0 공식문서에서는 다음과 같이 Record Lock 을 안내하고 있다.
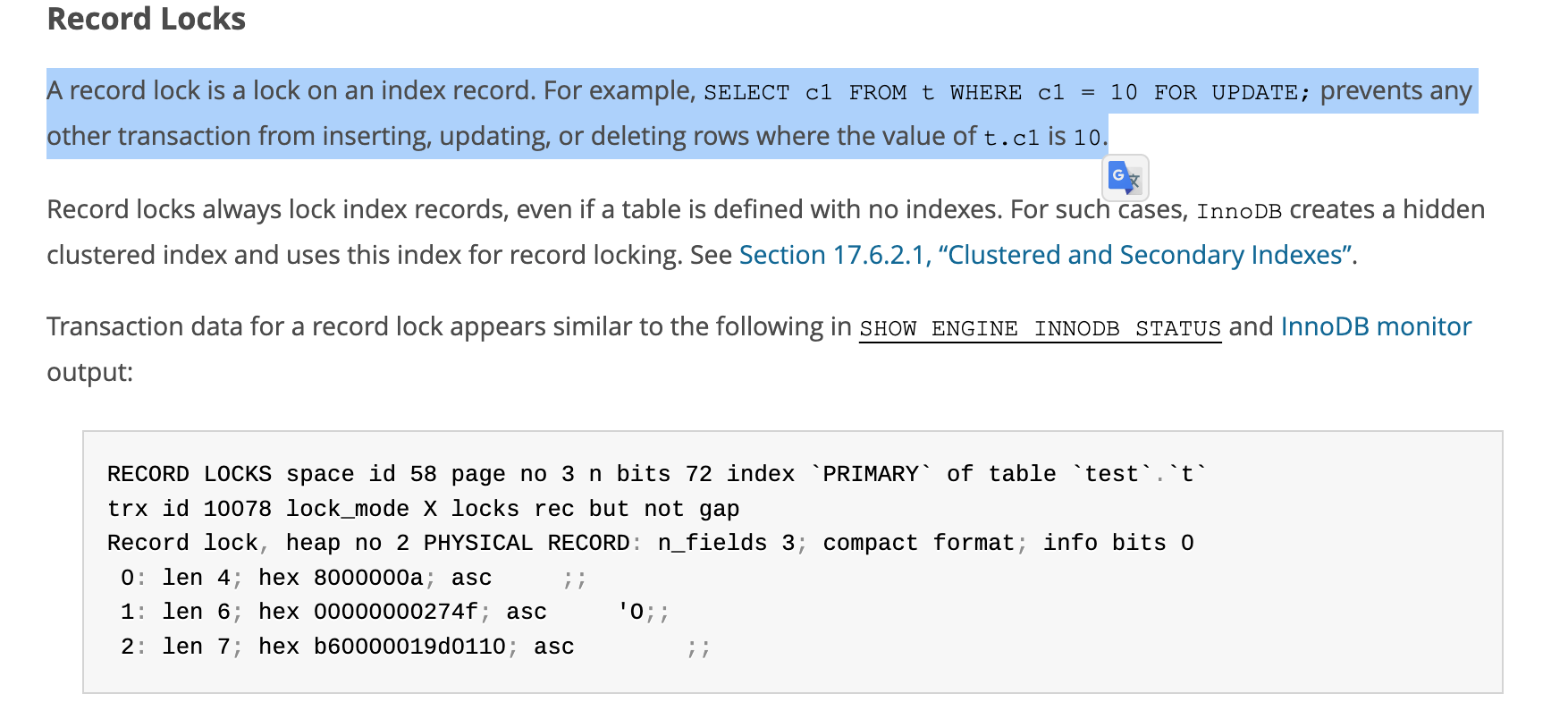
레코드 잠금은 인덱스 레코드에 대한 잠금입니다.
예를 들어, 레코드 잠금은SELECT c1 FROM t WHERE c1 = 10 FOR UPDATE;
다른 트랜잭션이 해당 인덱스의 값이t.c1 = 10인 행을 삽입, 업데이트 또는 삭제하는 것을 방지 합니다.
즉, 해당 락은 테이블 내부 레코드에 락을 걸고 락을 점유하는 동안은
다른 세션이 해당 레코드를 삽입/수정/삭제 하지 못하게 방지하는 메커니즘으로 보인다.
쿼리 콘솔로 Record Lock 찍어먹어보기
해당 락을 Record Lock이라고 부르며 아래 사진과 같이 동작한다.
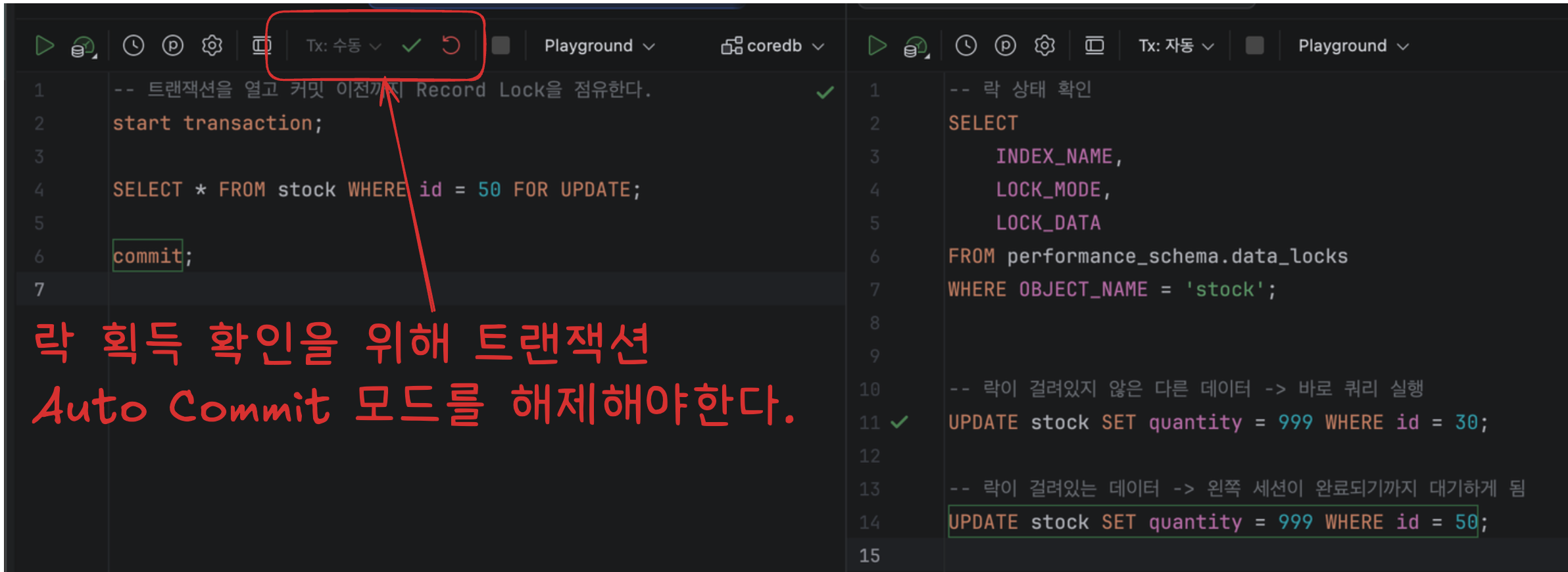
- 두개의 터미널의 동시에 띄워두고 왼쪽 세션은 Stock 테이블의 id = 50인 레코드를 Select For Update 쿼리를 통해 Record Lock 을 획득할 수 있다.
- 해당 락을 획득한 이후 오른쪽 세션을 통해 쿼리를 실행하면 id = 30 인 레코드를 업데이트 하는 쿼리를 바로 수행되지만, id = 50 을 업데이트 하는 쿼리는 바로 수정되지 않는다.
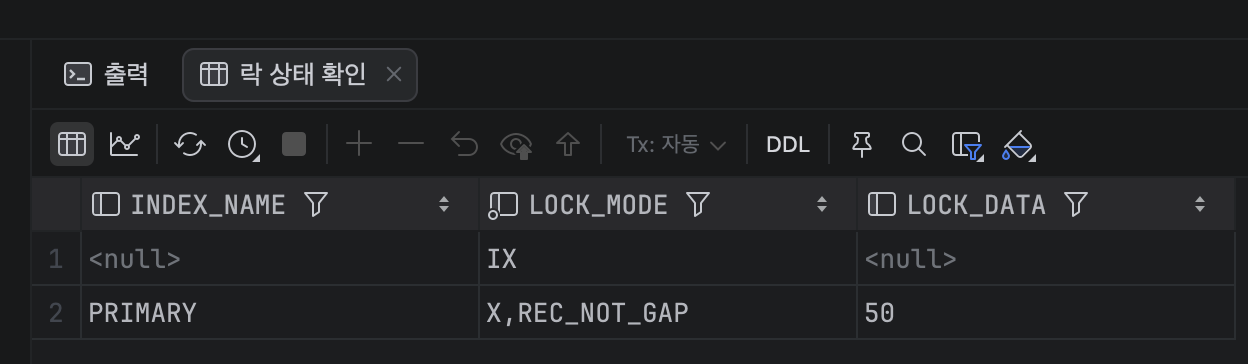
performance_schema.data_locks 테이블을 통해 왼쪽 세션이 락을 획득한 이후의 상황을 모니터링 해보면, 아래 사진과 같이 Primary index(pk) = 50 인 레코드에 대해 X-Lock 을 획득한 것을 알 수 있다.
코드를 통해 실험해보기
InnoDB 에서 제공하는 락이 구체적으로 어떻게 동작하는지 확인해보기 위해 직접 코드를 통해 실험해보면서 알아보자. (전체 코드는 여기에 있습니다.)
실험 환경
MySQL 8.0 InnoDB
Spring Boot 3.5.3
Kotlin 1.9.25
격리수준 : Repeatable Read
테스트 환경 : TestRestTemplate
실험 설명
이번에도 간단한 재고 테이블을 준비한다.
해당 테이블에서 각 레코드에 락을 걸고 상황별로 어떻게 락이 걸리는지 실험해보고
실험 결과를 분석하면서 원리를 파악해 볼 것이다.
CREATE TABLE stock
(
id BIGINT AUTO_INCREMENT PRIMARY KEY,
product_id BIGINT NOT NULL,
quantity INT NOT NULL,
version INT NOT NULL DEFAULT 0,
created_at DATETIME(6) NOT NULL,
updated_at DATETIME(6) NOT NULL,
UNIQUE INDEX uk_product_id (product_id)
);interface PessimisticLockStockRepository : JpaRepository<Stock, Long> {
@Query("SELECT s FROM Stock s WHERE s.productId = :productId")
fun getStockByProductId(@Param("productId") productId: Long): Stock
// lock 모드 PESSIMISTIC_WRITE 지정시 => jpa가 `for update` 추가해줌
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("SELECT s FROM Stock s WHERE s.id = :id")
fun findByIdWithLock(@Param("id") id: Long): Optional<Stock>
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("SELECT s FROM Stock s WHERE s.productId = :productId")
fun findByProductIdWithLock(@Param("productId") productId: Long): Optional<Stock>
}기본적으로 InnoDB 락은 SELECT ~~ FOR UPDATE 쿼리를 통해 실행되므로
JPA 에서 제공하는 @Lock 을 통해 자동으로 추가된다.
(자세한 내용은 아래 서술한 로직에 의해 락 모드가 자동 설정되며, 이 글에서는 해당 설정을 통해 실험을 진행할 것이다.)
@Lock 을 통한 락 모드 설정 메커니즘
@Lock메커니즘을 지정하면Spring Data Jpa에서 해당 에너테이션을 인식후 특정 옵션에 맞는 락 모드 지정- Hibernate 구현체가 해당 락 모드 설정값에 따른 쿼리문 추가
1. 락 모드 지정
Hibernate-core/.../LockModeConverter.getForUpdateString(LockMode lockMode, Timeout timeout)
public static LockModeType convertToLockModeType(LockMode lockMode) {
return switch ( lockMode ) {
case NONE, READ -> LockModeType.NONE; // no exact equivalent in JPA
case OPTIMISTIC -> LockModeType.OPTIMISTIC;
case OPTIMISTIC_FORCE_INCREMENT -> LockModeType.OPTIMISTIC_FORCE_INCREMENT;
case PESSIMISTIC_READ -> LockModeType.PESSIMISTIC_READ;
case PESSIMISTIC_WRITE, UPGRADE_NOWAIT, UPGRADE_SKIPLOCKED -> LockModeType.PESSIMISTIC_WRITE; // no exact equivalent in JPA
case WRITE, PESSIMISTIC_FORCE_INCREMENT -> LockModeType.PESSIMISTIC_FORCE_INCREMENT;
};
}2. 실제 락 모드에 따른 쿼리 생성 메서드
Hibernate-core/.../dialect/Dialect.getForUpdateString(LockMode lockMode, Timeout timeout)
public String getForUpdateString(LockMode lockMode, int timeout) {
return switch ( lockMode ) {
case PESSIMISTIC_READ -> getReadLockString( timeout );
case PESSIMISTIC_WRITE -> getWriteLockString( timeout );
case UPGRADE_NOWAIT, PESSIMISTIC_FORCE_INCREMENT -> getForUpdateNowaitString();
case UPGRADE_SKIPLOCKED -> getForUpdateSkipLockedString();
default -> "";
};
}Hibernate-core/.../dialect/Dialect.getForUpdateString()
public String getForUpdateString() {
return " for update";
}실험 1 : Record Lock 확인
위에서 쿼리 콘솔을 통해 진행한 내용을 테스트 코드를 통해 실행해본다.
두개의 쓰레드를 준비하고, 첫번째 쓰레드에서 트랜잭션을 열고 id = 1 인 레코드에 락을 건 이후 다른 쓰레드에서 해당 레코드 접근이 제한되는지 확인해본다.
서비스, 레포지토리 코드
// lock 모드 PESSIMISTIC_WRITE 지정시 => jpa가 `for update` 추가해줌
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("SELECT s FROM Stock s WHERE s.id = :id")
fun findByIdWithLock(@Param("id") id: Long): Optional<Stock> @Transactional
fun lockByPrimaryKey(id: Long, holdLockSeconds: Int = 0): Stock? {
val stock = stockRepository.findByIdWithLock(id).orElse(null)
if (holdLockSeconds > 0 && stock != null) {
Thread.sleep(holdLockSeconds * 1000L)
}
return stock
}락 정보 확인 코드
아래의 메서드를 통해 테스트 중간에 performance_schema.data_locks 테이블의 정보를 통해 락 정보를 확인해본다.
fun getCurrentLocks(): List<LockInfo> {
val sql = """
SELECT
ENGINE_LOCK_ID,
LOCK_TYPE,
LOCK_MODE,
LOCK_STATUS,
LOCK_DATA,
OBJECT_SCHEMA,
OBJECT_NAME,
INDEX_NAME
FROM performance_schema.data_locks
WHERE OBJECT_SCHEMA = 'coredb'
ORDER BY ENGINE_LOCK_ID
""".trimIndent()
return jdbcTemplate.query(sql) { rs, _ ->
LockInfo(
engineLockId = rs.getString("ENGINE_LOCK_ID"),
lockType = rs.getString("LOCK_TYPE"),
lockMode = rs.getString("LOCK_MODE"),
lockStatus = rs.getString("LOCK_STATUS"),
lockData = rs.getString("LOCK_DATA"),
objectSchema = rs.getString("OBJECT_SCHEMA"),
objectName = rs.getString("OBJECT_NAME"),
indexName = rs.getString("INDEX_NAME")
)
}
}테스트 코드
@Test
@DisplayName("Record Lock (PK) - 동일 레코드 락 시 대기 발생")
fun testRecordLockByPrimaryKey() {
// given
val stockId = 1L
val executor = Executors.newFixedThreadPool(2)
val latch = CountDownLatch(2)
val durations = mutableListOf<Long>()
// when: Thread-1이 3초 락 유지
executor.submit {
try {
val start = System.currentTimeMillis()
val headers = HttpHeaders().apply { contentType = MediaType.APPLICATION_JSON }
val request = HttpEntity(LockByIdRequest(id = stockId, holdLockSeconds = 3), headers)
testRestTemplate.postForEntity("/pessimistic-lock/lock-by-primary-key", request, String::class.java)
durations.add(System.currentTimeMillis() - start)
} finally {
latch.countDown()
}
}
Thread.sleep(100) // Thread-1이 먼저 락 획득하도록
// performance_schema에서 Record Lock 확인
val locks = testRestTemplate.getForObject("/pessimistic-lock/locks", LockMonitoringResponse::class.java)!!
assertThat(locks.locks).anyMatch { it.lockType == "RECORD" && it.lockMode.contains("X") }
// when: Thread-2가 동일 레코드 락 시도
executor.submit {
try {
val start = System.currentTimeMillis()
val headers = HttpHeaders().apply { contentType = MediaType.APPLICATION_JSON }
val request = HttpEntity(LockByIdRequest(id = stockId), headers)
testRestTemplate.postForEntity("/pessimistic-lock/lock-by-primary-key", request, String::class.java)
durations.add(System.currentTimeMillis() - start)
} finally {
latch.countDown()
}
}
// then
latch.await(10, TimeUnit.SECONDS)
executor.shutdown()
assertThat(durations[0]).isLessThan(3500) // Thread-1: ~3초
assertThat(durations[1]).isGreaterThan(2900) // Thread-2: 3초 이상 대기
}실험 1 결과
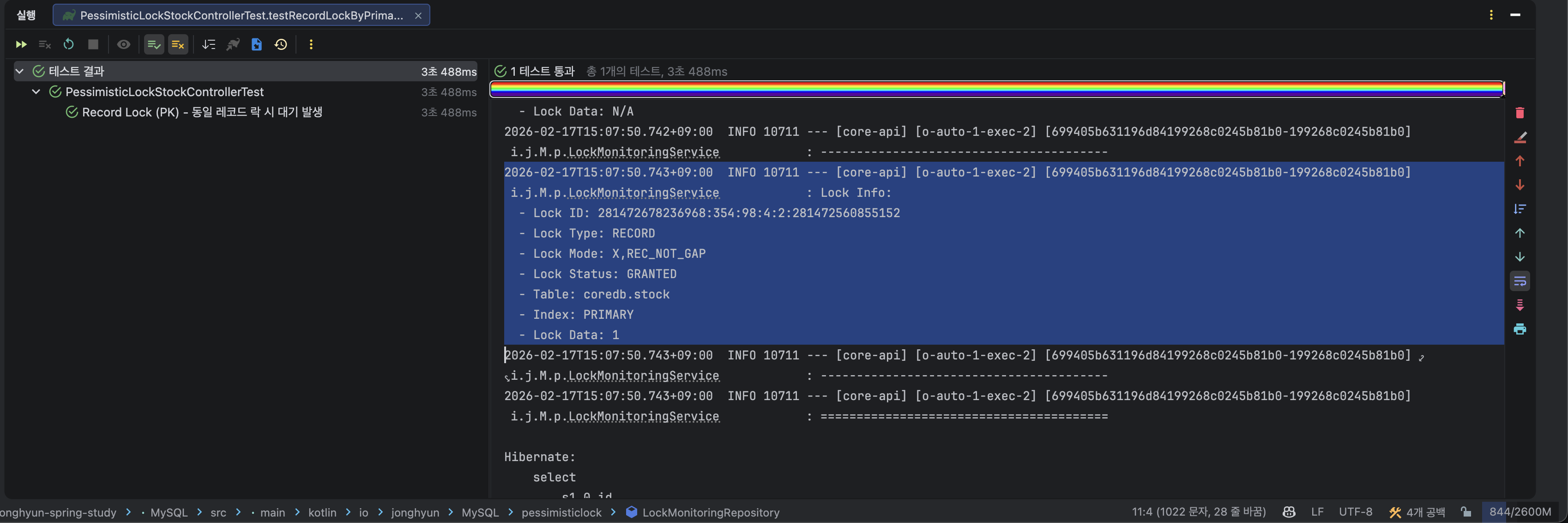
- 첫번째 쓰레드는 트랜잭션을 열고 id = 1인 레코드 조회와 락을 획득후 내부적으로 3초 대기
- 두번째 쓰레드는 첫번째 쓰레드가 락 획득 시점에 Blocking 되고 해당 레코드를 획득하지 못함
- 중간에 출력한
performance_schema.data_locks테이블의 정보를 통해 락 정보를 확인해 볼 수 있다.
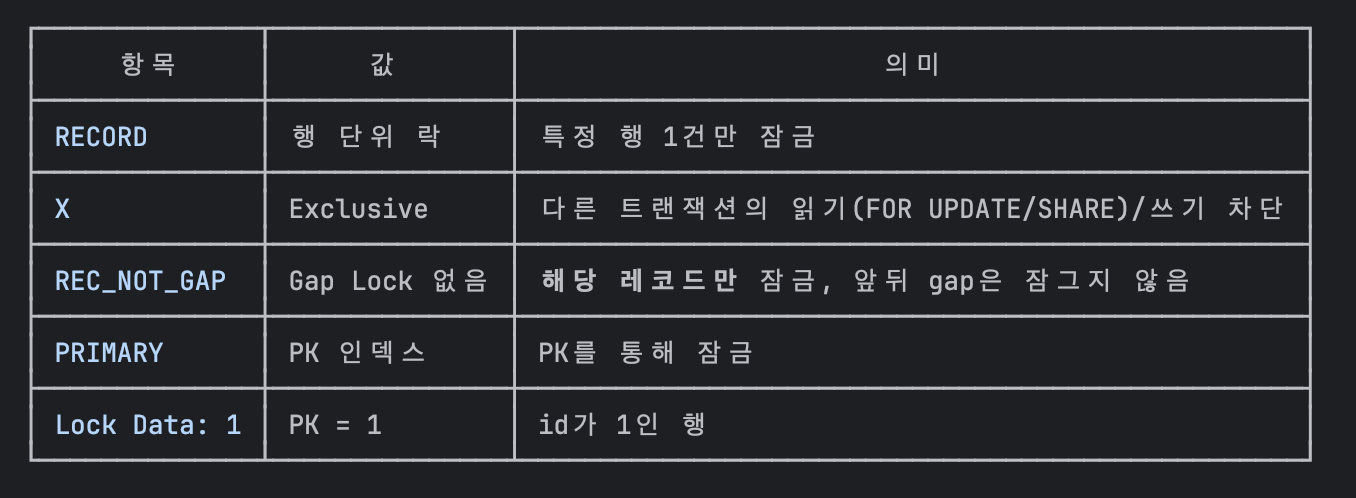
첫번째 쓰레드에서 의도한 대로 pk = 1 인 레코드에 대해 락이 제대로 걸리는 것을 확인해볼 수 있다.
실험 2 : Gap Lock 확인
이번에는 Stock 테이블에 존재하지 않는 Id에 락을 걸고 해당 id들로 insert를 수행하는 테스트를 작성했다.
아래의 테스트는 다음과 같이 수행된다.
- Stock 테이블에 id : 1~6 까지의 레코드를 넣어놓는다.
- 첫번째 쓰레드에서 id 7~9까지의 범위에 락을 지정한다. (select 범위 쿼리로 락 획득)
- 두번째 쓰레드에서 새로운 레코드 insert (id = 7 번의 새로운 레코드 인서트) 수행
레포지토리 코드
// select 쿼리로 범위를 지정 + for update 를 통해 해당 범위의 레코드들의 락을 모두 획득할 수 있다.
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("SELECT s FROM Stock s WHERE s.id BETWEEN :startId AND :endId")
fun findByIdBetweenWithLock(
@Param("startId") startId: Long,
@Param("endId") endId: Long
): List<Stock>테스트 코드
@Test
@DisplayName("존재하지 않는 범위 조회 시 INSERT Blocking")
fun testGapLock() {
// given: 현재 id = 1,2,3,4,5,6 존재
val executor = Executors.newFixedThreadPool(2)
val latch = CountDownLatch(2)
val results = mutableListOf<String>()
// when: Thread-1이 id 7~9 범위 락 (존재하지 않는 범위 -> Gap Lock)
executor.submit {
try {
val headers = HttpHeaders().apply { contentType = MediaType.APPLICATION_JSON }
val request = HttpEntity(LockByRangeRequest(startId = 7, endId = 9, holdLockSeconds = 3), headers)
val response = testRestTemplate.postForEntity("/pessimistic-lock/lock-by-range", request, String::class.java)
val actualJson = response.body!!
val expectedJson = """
{
"success": true,
"message": "Range lock: 7~9, found 0 records",
"stocks": []
}
"""
JSONAssert.assertEquals(expectedJson, actualJson, JSONCompareMode.LENIENT)
results.add("Thread-1: Gap Lock acquired (0 records)")
} finally {
latch.countDown()
}
}
Thread.sleep(100)
// performance_schema에서 Record Lock 확인
val locks = testRestTemplate.getForObject("/pessimistic-lock/locks", LockMonitoringResponse::class.java)!!
assertThat(locks.locks).anyMatch { it.lockType == "RECORD" && it.lockMode.contains("X") }
// when: Thread-2가 Gap Lock 범위에 INSERT 시도 → Gap Lock에 의해 차단되어야 함
executor.submit {
try {
val start = System.currentTimeMillis()
val headers = HttpHeaders().apply { contentType = MediaType.APPLICATION_JSON }
val request = HttpEntity(CreateStockRequest(productId = 999, quantity = 10), headers)
testRestTemplate.postForEntity("/pessimistic-lock/stocks", request, String::class.java)
val duration = System.currentTimeMillis() - start
results.add("Thread-2: INSERT waited ${duration}ms (Gap Lock)")
// Gap Lock으로 인해 약 3초 대기해야 함
assertThat(duration).isGreaterThan(2900)
} finally {
latch.countDown()
}
}
// then
latch.await(10, TimeUnit.SECONDS)
executor.shutdown()
println("Gap Lock 테스트 결과:")
results.forEach { println(" $it") }
}실험 2 결과
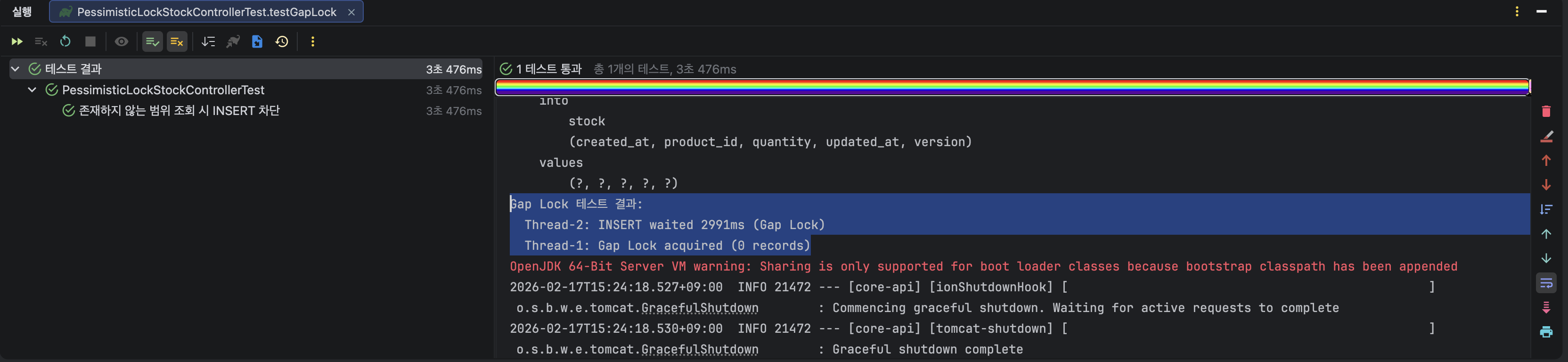
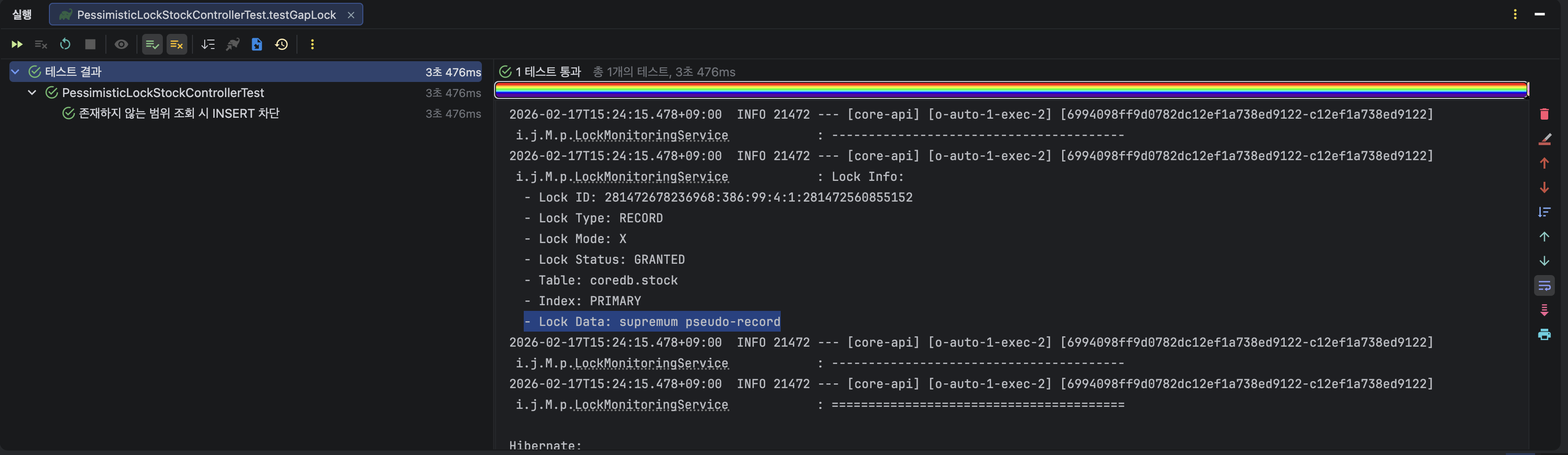
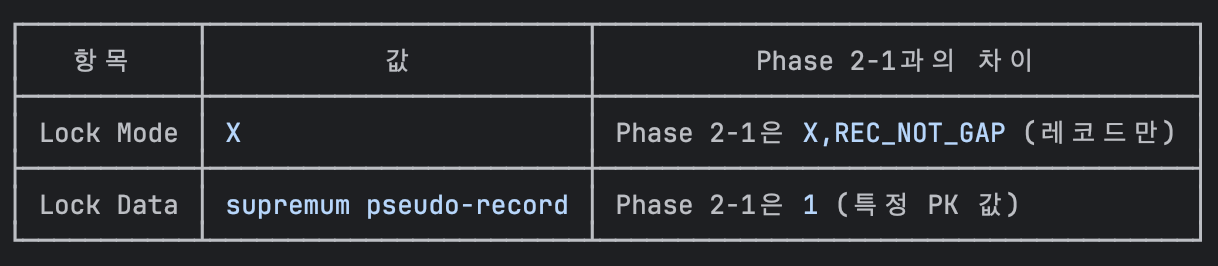
실험 2의 결과로 쓰레드 1에서는 존재하지 않는 레코드를 조회하였지만, supremum pseudo-record 락을 통해 존재하지 않는 레코드에 락이 잡힌것을 확인 할 수 있다.
Gap Lock 과 supremum pseudo-record
이와 관련하여 MySQL 공식문서에는 다음과 같이 언급하고 있다.

pseudo-record : 인덱스에 생성되는 인위적인 레코드로, 현재 존재하지 않는 키 값 또는 범위를 잠그는 데 사용됩니다.

supremum record :인덱스에서 가장 큰 값보다 큰 간격 을 나타내는 가상 레코드입니다. 예를 들어, 트랜잭션에
<input>과 같은 구문이 있고 해당 열의 가장 큰 값이 20인 경우, 이는 가장 큰 레코드에 대한 잠금으로, 다른 트랜잭션이 50, 100 등과 같은 더 큰 값을 삽입하는 것을 방지합니다.
SELECT ... FROM ... WHERE col > 10 FOR UPDATE;

Gap Lock : 인덱스 레코드 사이의 간격 , 즉 첫 번째 또는 마지막 인덱스 레코드 앞의 간격에 대한 잠금입니다. 예를 들어, 범위 내 모든 기존 값 사이의 간격이 잠겨 있으므로 다른 트랜잭션이 해당 열에 15라는 값을 삽입하는 것을 방지합니다 . 이는 해당 열에 이미 15라는 값이 있는지 여부와 관계없이 적용됩니다. 레코드 잠금 및 다음 키 잠금 과 구별됩니다 .
SELECT c1 FROM t WHERE c1 BETWEEN 10 and 20 FOR UPDATE;t.c1
즉, MySQL 내부적으로 존재하지 않는 가상의 레코드를 추가하여 특정 상황에 해당 가상 레코드를 통해 락을 걸 수 있으며 이러한 존재하지 않는 가상의 레코드에 추가하는 락을 Gap Lock이라고 한다.
실험 2 결과 해석
이에 관한 내용을 토대로 위의 실험 2의 상황을 다시 복기해보면 다음과 같은 그림이 될것이다.
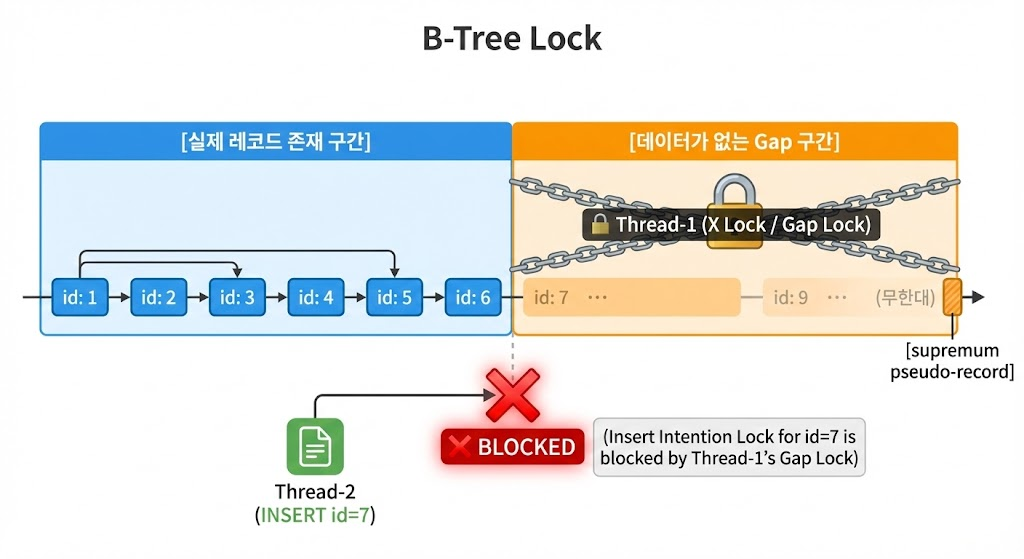
- id 1~6 까지의 레코드가 존재
- 쓰레드 1에서 id 7~9 까지의 존재하지 않는 레코드에 락을 획득
(이때,supremum pseudo-record를 통해 가상의 레코드를 생성하고 해당 레코드로 락을 획득하게 됨)- 쓰레드 2가 쓰레드 1의 락 점유에 의해 Blocking
즉, MySQL 의 락은 존재하는 레코드 뿐만 아니라 존재하지 않는 레코드도 가상의 레코드를 통해 락을 점유할수 있으며 이를 통해 새로운 레코드를 insert 하는 로직에도 Thread-safe 하게 작업을 수행할 수 있다.
실험 3 : 인덱스 없는 컬럼으로 락을 걸었을때 락 상태 확인
이번에는 조금 다른 케이스를 통해 인덱스 여부에 따라 Record Lock, Gap Lock 이 어떤식으로 동작하는지 확인해보자.
결론부터 말하자면, InnoDB의 Record Lock은 실제로 인덱스에 락이 걸리기 때문에 컬럼의 Index 상태에 따라 락의 범위가 달라질 수 있다.
레포지토리 코드
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("SELECT s FROM Stock s WHERE s.quantity = :quantity")
fun findByQuantityWithLock(@Param("quantity") quantity: Int): List<Stock>다음과 같이 quantity로 조회하는 메서드를 추가로 구현하고 해당 메서드로 Stock 레코드를 조회 및 락을 획득하는 테스트를 작성한다.
Stock 테이블의 quantity 컬럼은 어떠한 인덱스도 존재하지 않는 컬럼이다.
테스트 코드
@Test
@DisplayName("인덱스 없는 컬럼 조회 - 전체 테이블 락")
fun testFullTableLockWithoutIndex() {
// given: quantity 컬럼에 인덱스 없음
val executor = Executors.newFixedThreadPool(2)
val latch = CountDownLatch(2)
// when: Thread-1이 quantity=100 조회 (인덱스 없어서 전체 테이블 스캔 -> 전체 락)
executor.submit {
try {
val headers = HttpHeaders().apply { contentType = MediaType.APPLICATION_JSON }
val request = HttpEntity(LockByQuantityRequest(quantity = 100, holdLockSeconds = 3), headers)
val response = testRestTemplate.postForEntity("/pessimistic-lock/lock-by-quantity", request, String::class.java)
val actualJson = response.body!!
// quantity=100인 레코드는 2개 (productId=1,2)
val expectedStocks = stockRepository.findAll().filter { it.quantity == 100 }.sortedBy { it.productId }
val expectedJson = """
{
"success": true,
"message": "Lock by quantity=100, found 2 records",
"stocks": [
{"id": ${expectedStocks[0].id}, "productId": 1, "quantity": 100, "version": 0},
{"id": ${expectedStocks[1].id}, "productId": 2, "quantity": 100, "version": 0}
]
}
"""
JSONAssert.assertEquals(expectedJson, actualJson, JSONCompareMode.LENIENT)
} finally {
latch.countDown()
}
}
Thread.sleep(100)
// performance_schema에서 Record Lock 확인
val locks = testRestTemplate.getForObject("/pessimistic-lock/locks", LockMonitoringResponse::class.java)!!
assertThat(locks.locks).anyMatch { it.lockType == "RECORD" && it.lockMode.contains("X") }
// when: Thread-2가 quantity=50인 다른 레코드 업데이트 시도
// 인덱스가 없으면 전체 테이블 스캔으로 모든 레코드에 락이 걸리므로 대기해야 함
executor.submit {
try {
val start = System.currentTimeMillis()
val stock3 = stockRepository.findAll().find { it.productId == 3L }!! // quantity=50
val headers = HttpHeaders().apply { contentType = MediaType.APPLICATION_JSON }
val request = HttpEntity(LockByIdRequest(id = stock3.id!!), headers)
testRestTemplate.postForEntity("/pessimistic-lock/lock-by-primary-key", request, String::class.java)
val duration = System.currentTimeMillis() - start
// 전체 테이블 락으로 인해 약 3초 대기
assertThat(duration).isGreaterThan(2900) // <- 해당 부분에서 실패처리가 될것
println("인덱스 없는 컬럼 조회: quantity=50 레코드도 ${duration}ms 대기 (전체 테이블 락)")
} finally {
latch.countDown()
}
}
// then
latch.await(10, TimeUnit.SECONDS)
executor.shutdown()
}이번 테스트도 역시 다른 포맷은 동일하되, 레코드를 조회하는 조건만 quantity = 100 으로 변경하여 락을 획득한다.
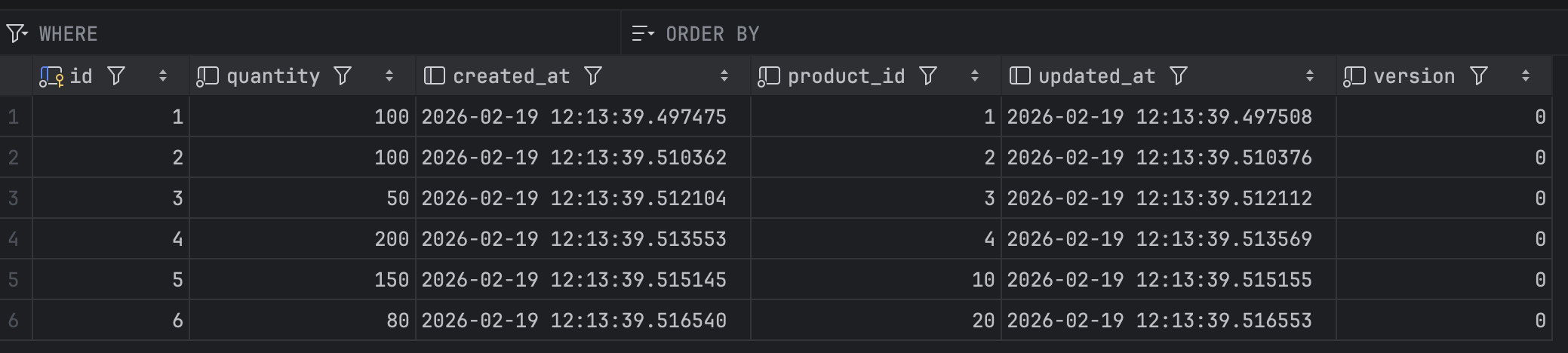
데이터는 이렇게 6개의 레코드가 존재하므로 쓰레드 1에서 id = 1, 2에만 락을 획득하고
쓰레드 2에서 id = 3 을 조회하므로 락이 걸리지 않고 3초보다 빠르게 처리되어 테스트가 실패할것 같다.
// 전체 테이블 락으로 인해 약 3초 대기
assertThat(duration).isGreaterThan(2900) // <- 해당 부분에서 실패처리가 될것
실제로는 어떻게 동작할까?
실험 3 결과
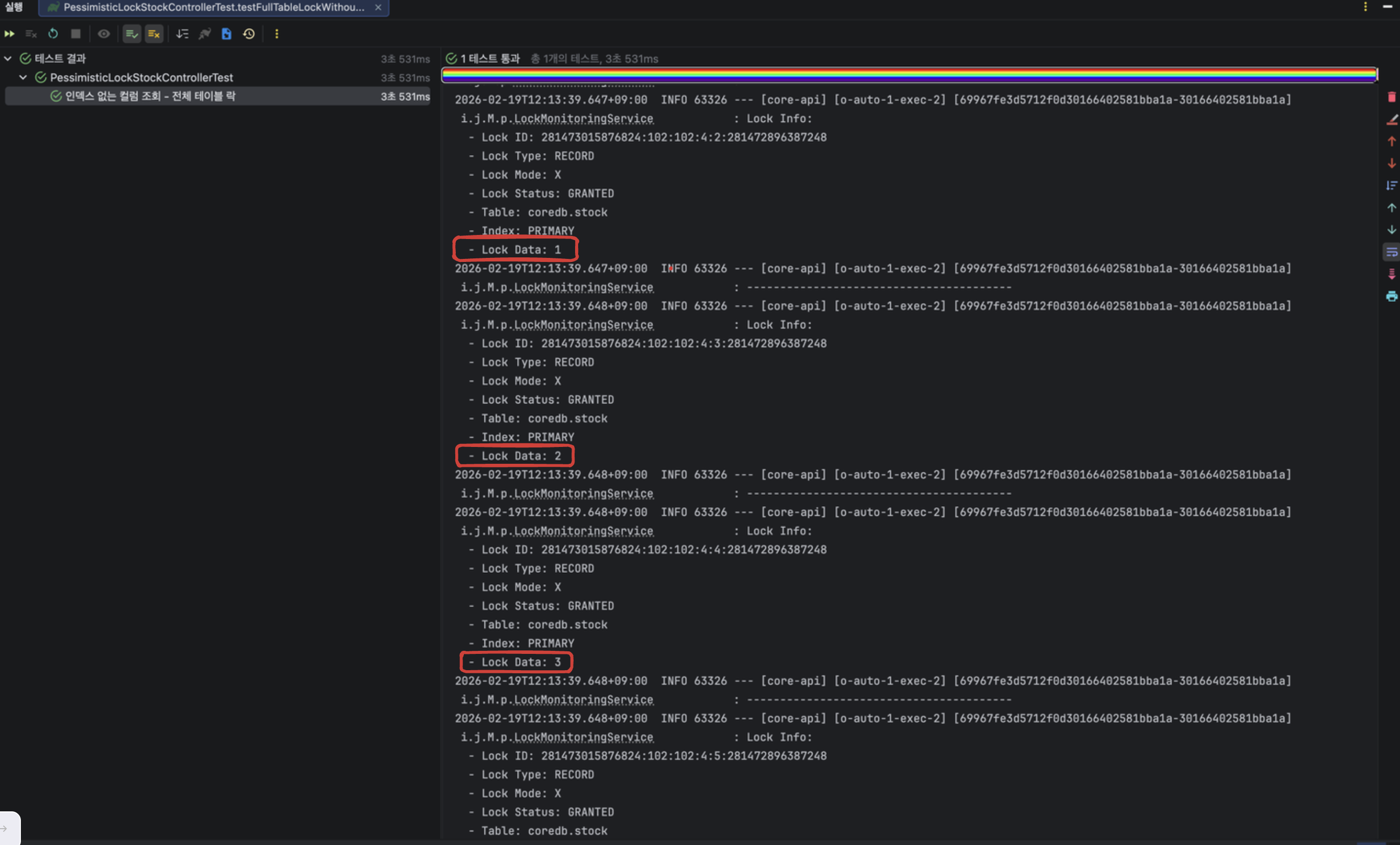
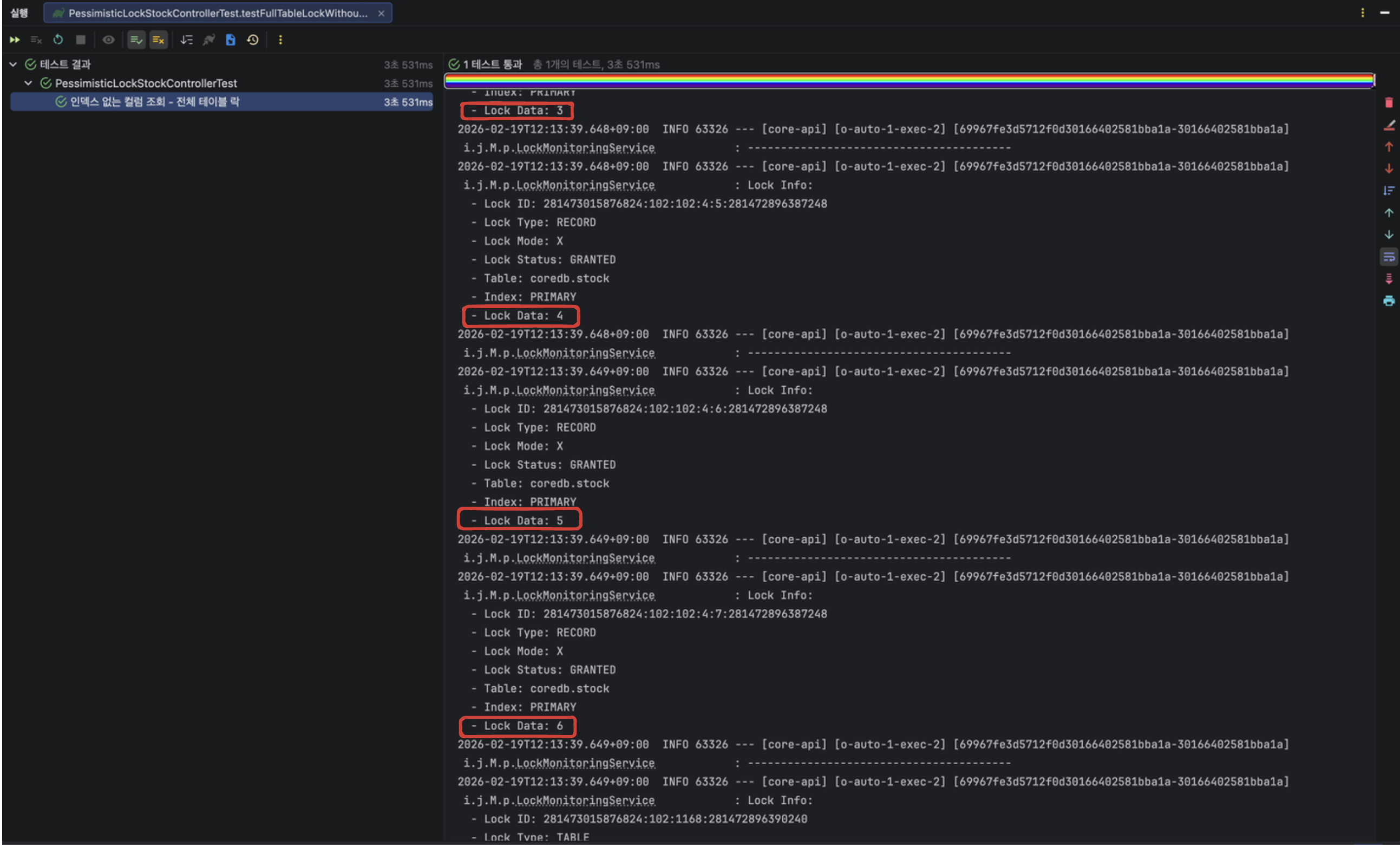
예상과는 다르게 테스트가 성공하였고 쓰레드 1(quantity = 100인 레코드 락 획득)로 인해 발생한 락 정보를 확인해보니 id = 1,2 뿐만 아니라 id = 3,4,5,6 인 모든 레코드에 락이 걸린 것을 확인해볼 수 있다.
이유가 무엇일까?
InnoDB 레코드 기반 락은 인덱스의 레코드(Index Record)를 잠근다.
위와 같은 결과가 나온 이유는 InnoDB에서 Record 기반 락은 실제 레코드가 아닌 Index Record 를 잠그고 탐색과정에서 만나는 모든 인덱스 레코드의 락을 획득하기 때문이다.
해당 의미를 좀 더 이해하기 위해 MySQL 공식문서를 보면

출처 : MySQL 8.0 공식문서 - innodb-locks-set
읽기 잠금 , 읽기 전용 잠금 UPDATE또는 DELETE 일반적으로 설정된 레코드 잠금은 SQL 문 처리 중에 스캔되는 모든
인덱스 레코드에 적용됩니다. WHERE문에 해당 행을 제외하는 조건이 있는지 여부는 중요하지 않습니다.
레코드 잠금은 인덱스 레코드 에 적용된다고 적혀있다. 이 말의 의미는 무엇일까?
InnoDB의 레코드 저장 방식
이 말을 이해하기 위해서는 사전 지식으로 InnoDB에서 레코드를 저장하는 방식을 이해해야 한다.
결론부터 말하면 InnoDB는 레코드 자체를 저장하는게 아닌 인덱스 기반으로 데이터를 저장한다.
이 역시 공식문서를 통해 관련 내용을 찾아보면

출처 : MySQL 8.0 공식문서 - Clustered and Secondary Indexes
각 InnoDB테이블에는 행 데이터를 저장하는
클러스터형 인덱스라는 특수한 인덱스가 있습니다. 일반적으로 클러스터형 인덱스는 기본 키와 동일합니다.
해당 설명을 보면 모든 레코드는 Clustered Index 라는 것으로 저장된다고 명시되어있다.
이해를 위해 다음의 그림을 한번 보자.
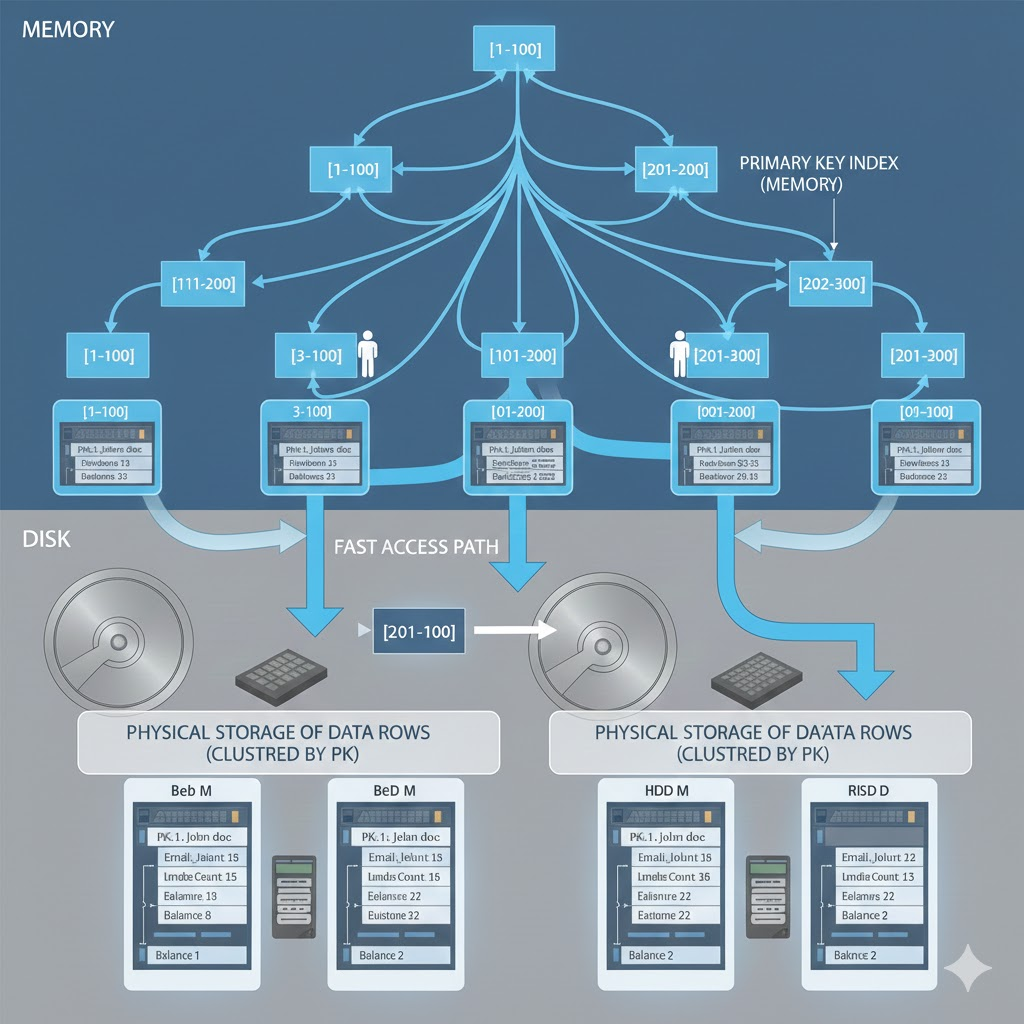
(출처 : 구글 제미나이)
기본적으로 MySQL은 디스크의 데이터를 메모리에 로드하여 빠르게 읽기가 가능한 작업을 한다.
이때 데이터를 조회할때 메모리에 해당 데이터가 존재하면 디스크를 탐색하지 않고 메모리상의 InnoDB 버퍼풀에서 데이터를 리턴하게 된다.
그림의 메모리의 Leaf 노드가 실제 레코드 데이터가 존재하게 되고 데이터를 조회하게 되면 그림의 Leaf 노드를 조회하게 된다.
즉, InnoDB 상에서 실제 데이터가 존재하는 곳은 Cluster Index라고 부르는 Leaf Node가 되고 해당 노드에서 데이터를 가져온다.
실험 3 결과 해석
그러면 다시 실험 3에서 왜 pk 로 조회했을때와 다르게 index가 없는 quantity 컬럼으로 조회했을때 모든 레코드에 Record Lock 걸린것인지에 대한 이유를 알아보자.
결론부터 말하면 레코드 탐색시 인덱스(Secondary Index) 를 통해 실제 Clustered Index 를 탐색하게 되는데 탐색 과정에서 만나는 모든 인덱스 레코드에 락을 걸기 때문이다.
무슨 의미일까? 다음 그림을 보자.
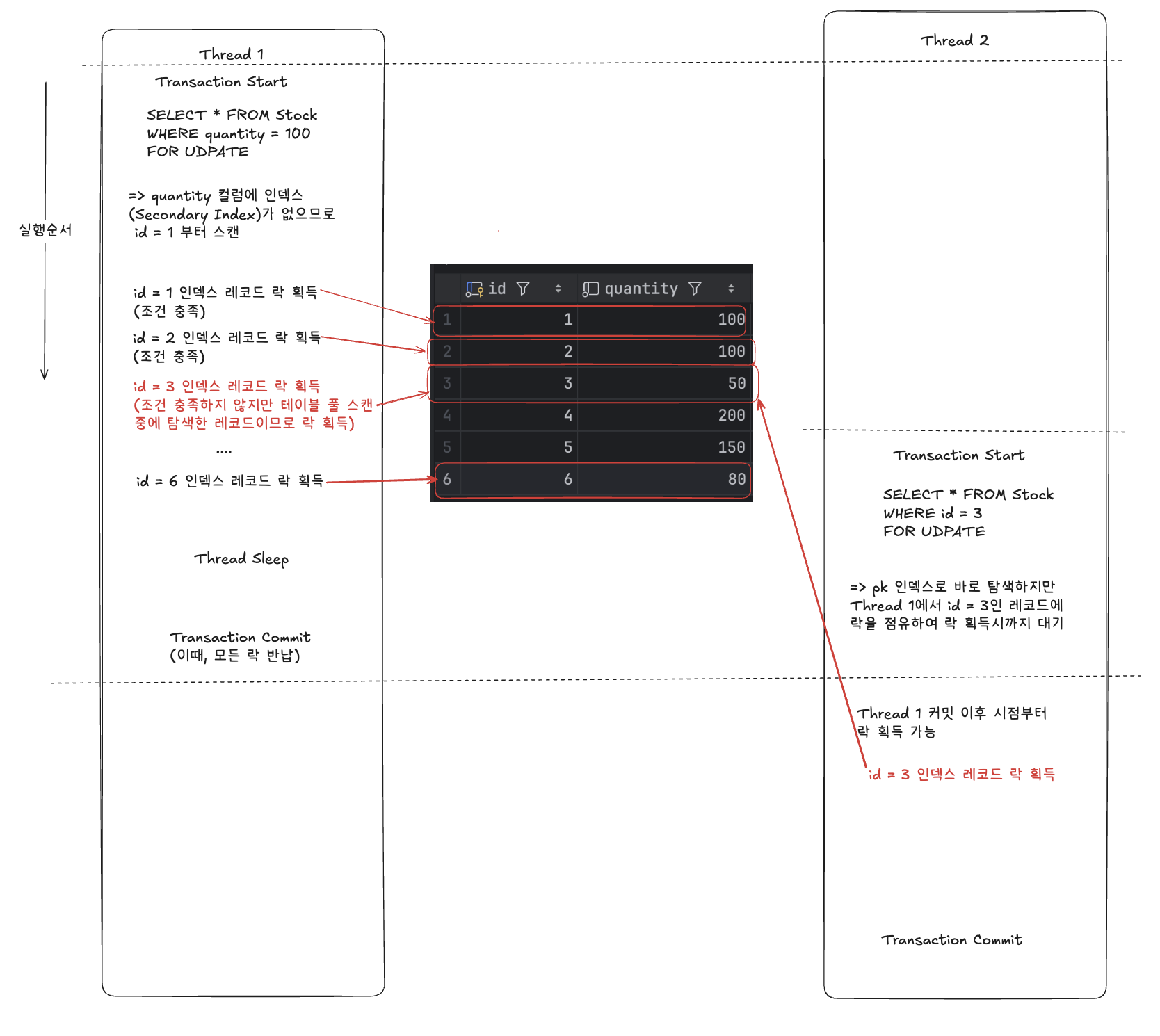
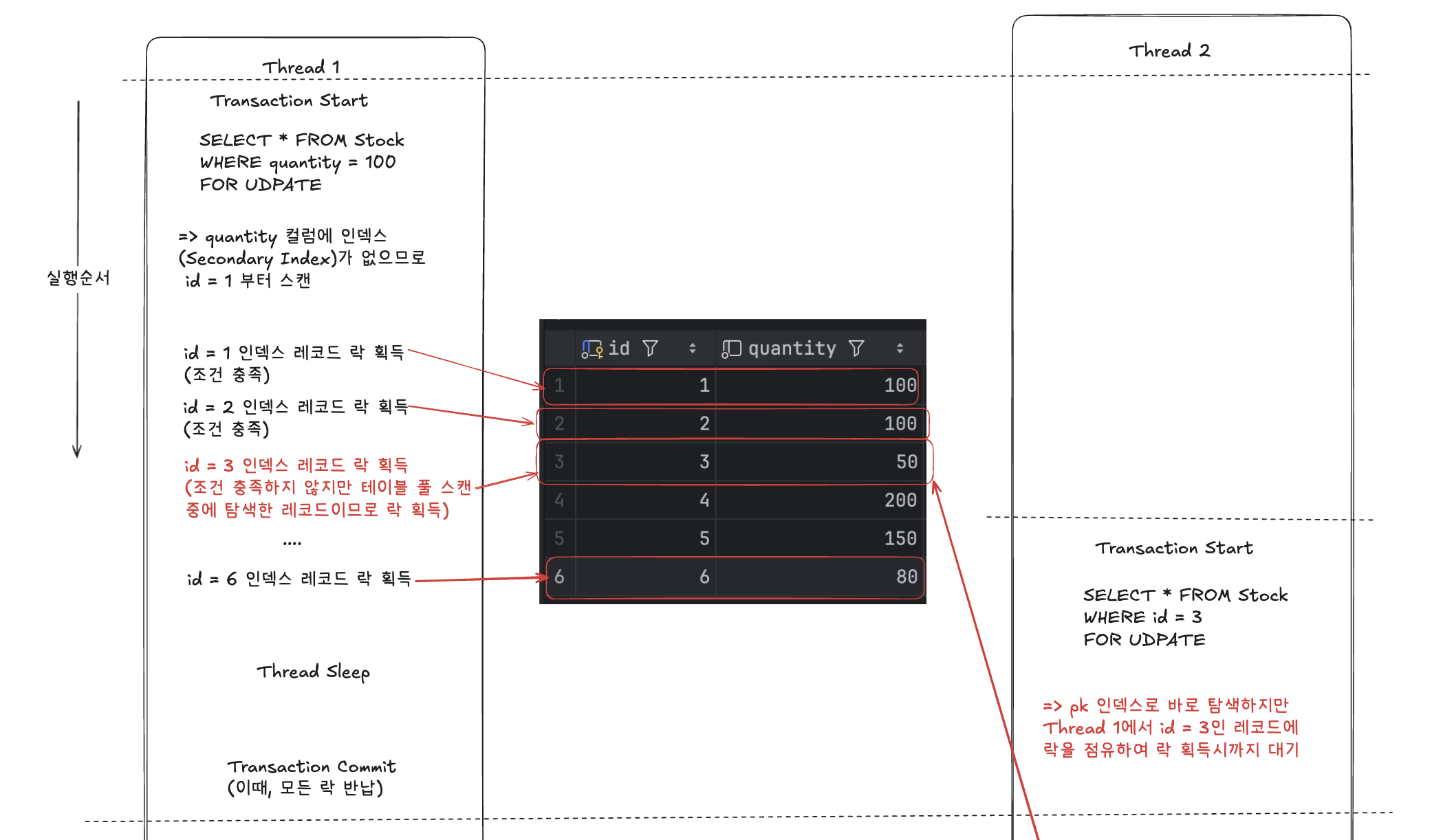
- 쓰레드 1이 트랜잭션을 열고 index가 없는 quantity 컬럼으로 테이블 풀 스캔 실행
- 이때, 스캔하면서 조건에 만족하지 않는 레코드들 id = 3,4,5,6 도 모두 락 점유
- 쓰레드 2는 쓰레드 1이 락을 점유하므로 대기
- 쓰레드 2가 쓰레드 1이 커밋이후 id = 3인 레코드 접근 및 락 획득
즉, 인덱스가 없는 컬럼으로 FOR UPDATE 컬럼을 통해 레코드 락을 획득하면 스캔하면서 만나는 조건에 맞지 않는 레코드도 락을 점유하기 때문에 해당 내용에 처리 속도 및 동시성이 매우 떨어질 수 있다.
레슨런
Record 락과 관련하여 InnoDB에서 레코드를 어떻게 저장하고 락을 획득하는지에 대한 제 나름의 큰 그림을 그려볼 수 있었습니다. 특히, 해당 락 기법을 사용할때는 적절한 인덱스가 있는 컬럼에 사용해야 성능이 떨어지지 않는게 시사점인것 같습니다.
