N줄 요약
Named Lock은 MySQL의 애플리케이션 레벨의 락으로 커넥션들을 Blocking 하여 여러 요청을 동기화 한다.- Spring 에서 하나의 메서드에
@Transational이 없으면 메서드 내부 쿼리들에 같은 커넥션을 사용함을 보장하지 않는다.- 락 해제는 비즈니스 로직의 트랜잭션 commit 이후 시점에 처리되어야 한다.
- 락 획득과 해제는 반드시 하나의 커넥션 안에서 이루어져야 한다.
- 비즈니스 로직의 트랜잭션 커넥션과 Named Lock 획득/해제 커넥션은 분리하여 사용하자.
Named Lock 이 뭐지?
이에 관해 MySQL 8.0 공식문서 에는 다음과 같이 적혀있다.

지정된 문자열로 이름을 지정하고 - str
시간 제한 - timeout 초
을 설정하여 잠금을 획득하려고 시도합니다.
음수 timeout 값은 시간 제한이 무한대임을 의미합니다.
이 잠금은 배타적입니다. 한 세션이 잠금을 보유한 동안 다른 세션은 동일한 이름의 잠금을 획득할 수 없습니다.
Named Lock은 MySQL에서 제공하는 다른 락과 다르게 테이블이나 레코드에 대한 락이 아닌,
특정 문자열을 선택후, 해당 문자열 기반으로 락을 획득 할 수 있다.
또한, 특정 레코드나 테이블 레벨로 적용되는 락이 아닌 데이터베이스 애플리케이션 레벨의 락이기 때문에 InnoDB, MyISAM 등 모든 데이터베이스 스토리지 엔진에서 사용할 수 있다.
Named Lock을 컨트롤 할 수 있는 함수는 위 사진의 5가지 함수가 있으며 함수 정의는 아래와 같다.
GET_LOCK(str,timeout): 락 획득 메서드 => str : 락 문자열, timeout 락 획득 타임아웃 값
타임아웃값 동안 대기하다가 락 획득하지 못하면 0 리턴, 획득 성공하면 1 리턴IS_FREE_LOCK(str): str 값의 락이 사용중인지 확인, 락 점유중이면 1 비어있으면 0 리턴IS_USED_LOCK(str): str 락이 사용 중인지 여부를 확인하고,
사용 중이면 사용중인 커넥션 아이디를 반환RELEASE_ALL_LOCKS(): 현재 커넥션에서 획득한 모든 락을 해제RELEASE_LOCK(str): str 값의 락을 해체
특정 문자열로 락을 걸고 해당 락을 얻기 위해 커넥션들이 Blocking 형식으로 대기하게 되는 메커니즘으로 보인다.
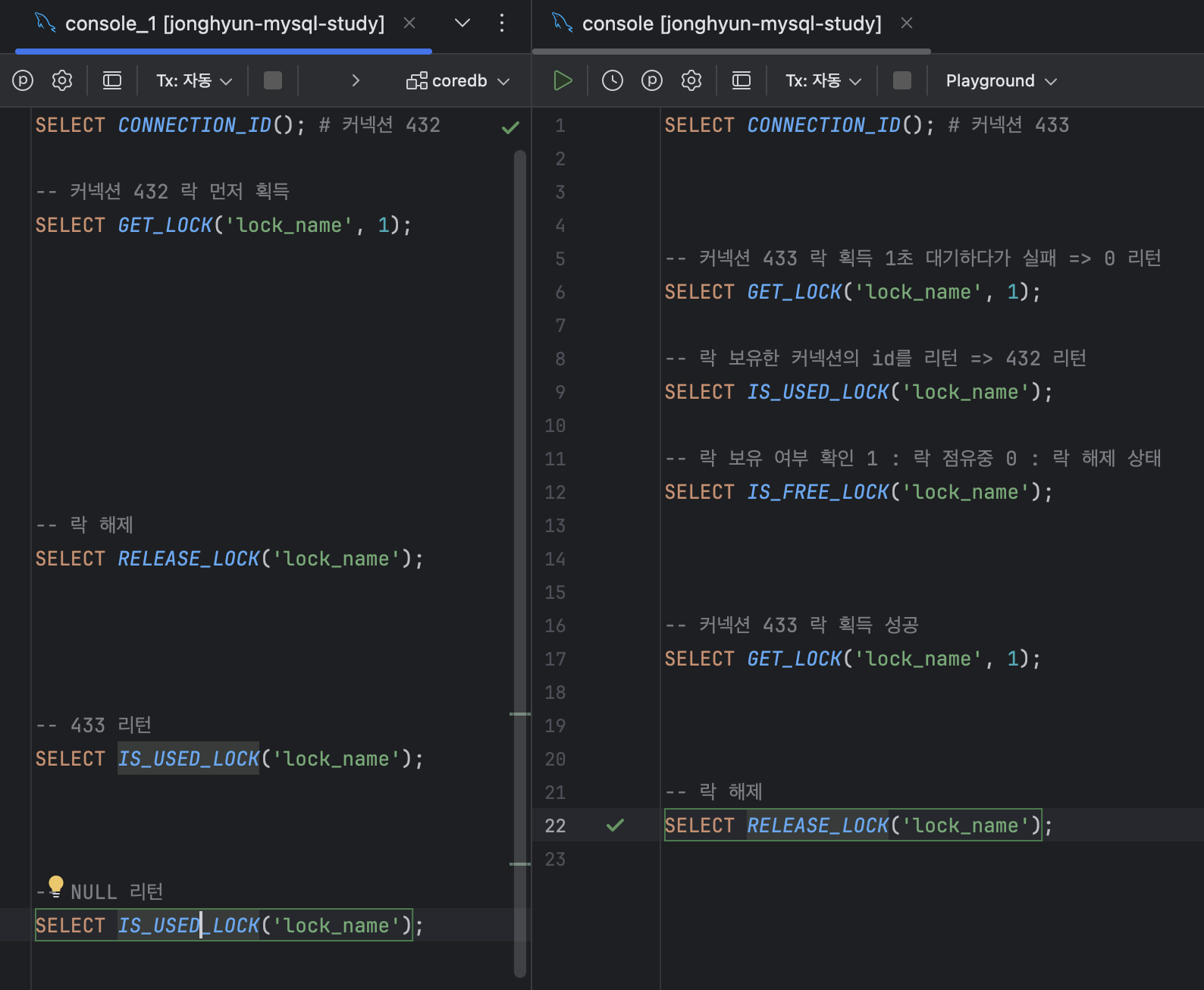
테스트를 위해 두개의 콘솔을 띄워놓고 순서대로 쿼리를 실행해보면 lock_name 문자열에 대한 Named Lock이 어떻게 동작하는지 확인해 볼 수 있다.
(또한, timeout에 음수를 넣으면 타임아웃을 무한대로 설정할 수 있다.)
이제 기본적인 Named Lock에 대해 대략적으로 알았으니 실제 코드를 통해 Named Lock을 통해서 락을 걸고 애플리케이션이 어떻게 정합성을 보장하게 할 수 있을지 테스트 해보자.
실험 설명
상황
재고를 동시에 차감하는 간단한 상황을 준비
CREATE TABLE stock
(
id BIGINT AUTO_INCREMENT PRIMARY KEY,
product_id BIGINT NOT NULL,
quantity INT NOT NULL,
created_at DATETIME(6) NOT NULL,
updated_at DATETIME(6) NOT NULL,
UNIQUE INDEX uk_product_id (product_id)
);위와 같은 테이블에 100개의 레코드를 insert 하고 동시에 100건의 차감 함수를 호출한다.
실험 환경
MySQL 8.0 InnoDB
Spring Boot 3.5.3
Kotlin 1.9.25
격리수준 : Repeatable Read
실험을 위한 코드
Named Lock을 통해 동기화하는 과정을 확인해보기 위해 간단한 코드를 준비한다.
(전체 코드는 여기에 있습니다.)
@Entity
@Table(name = "stock")
class Stock(
@Column(nullable = false)
val productId: Long,
@Column(nullable = false)
var quantity: Int
) : BaseEntity() {
fun decrease(amount: Int) {
if (quantity < amount) {
throw IllegalArgumentException("재고가 부족합니다. 현재: $quantity, 요청: $amount")
}
quantity -= amount
}
fun increase(amount: Int) {
quantity += amount
}
}interface StockRepository : JpaRepository<Stock, Long> {
fun findByProductId(productId: Long): Stock?
fun getStockByProductId(productId: Long): Stock =
findByProductId(productId) ?: throw IllegalArgumentException("No stock found for productId=$productId")
}@Service
class StockService(
private val stockRepository: StockRepository,
) {
@Transactional
fun decreaseStockWithOutLock(productId: Long, amount: Int) {
val stock = stockRepository.getStockByProductId(productId)
stock.decrease(amount)
stockRepository.save(stock)
}
}실험 1 : 락 없이 동시에 100건 재고 차감
@Test
fun `락 없이 동시에 100건 재고 차감을 수행한다`() {
// given
val threadCount = 100
val executor = Executors.newFixedThreadPool(threadCount)
val latch = CountDownLatch(threadCount)
// when
repeat(threadCount) {
executor.submit {
try {
val headers = HttpHeaders().apply {
contentType = MediaType.APPLICATION_JSON
}
val request = HttpEntity(StockRequest(productId = PRODUCT_ID, amount = 1), headers)
testRestTemplate.postForEntity("/stock-without-lock", request, Void::class.java)
} catch (e: Exception) {
logger.error("Error during concurrent request", e)
} finally {
latch.countDown()
}
}
}
latch.await()
executor.shutdown()
// then
val stock = stockRepository.getStockByProductId(PRODUCT_ID)
logger.info("Final quantity: ${stock.quantity}, Expected: 0")
// 락이 없으므로 동시성 문제로 인해 0이 아닐 것으로 예상
assertThat(stock.quantity).isNotEqualTo(0)
}실험 1 실행 결과 - Lost Update 발생


quantity 100 인 데이터가 존재하는 레코드를 동시에 차감하는 api를 100건 실행한 결과로 73이 나온다.
해당 상황은 어떤 상황일까? 아래의 그림을 보자.
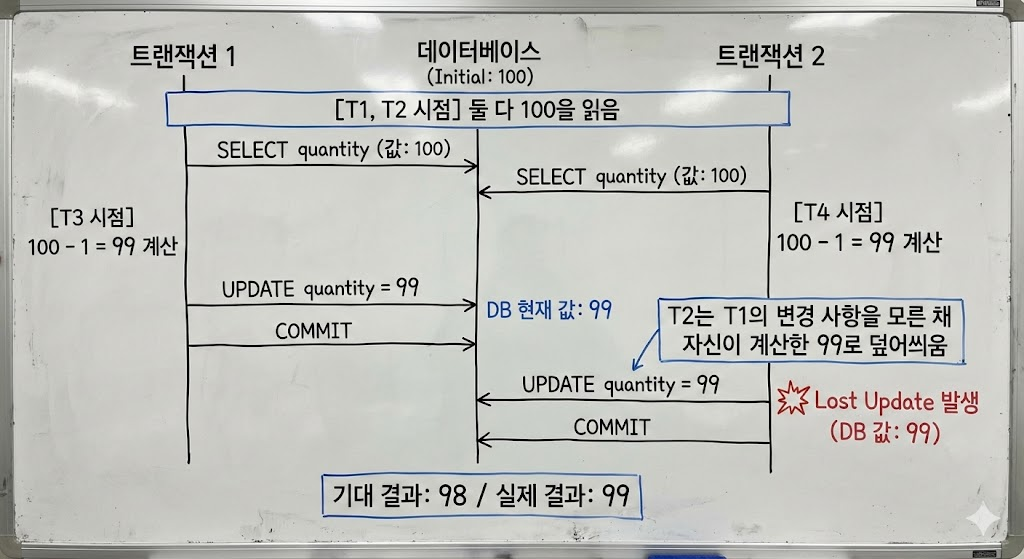
- 동시에 두개의 트랜잭션이 요청 시작
- T1 의 트랜잭션이 select 쿼리로 데이터 read
- T2 의 트랜잭션이 select 쿼리로 데이터 read
- T1 의 트랜잭션이 값 -1 update 이후 commit
- T2 의 트랜잭션이 값 -1 update 이후 commit
즉, T1의 차감 로직(Update)이 사라지는(Lost) Lost Update 현상이 발생하였다.
T1의 트랜잭션이 Select 쿼리 Read ~ Update 쿼리 차감사이에 T2 트랜잭션이 값을 읽음- T2 트랜잭션이
T1이 커밋하기전의 값으로 차감 시도 - T1이 먼저 차감했으나, 그 이후 T2의 차감으로 인해 T1의 차감은 사라짐
실험 2 : Named Lock을 활용하여 동시에 100건 재고 차감
이러한 Lost Update를 막는 방식에는 여러가지 동기화 기법이 있지만, 이번 글에서는 Named Lock에 대해 다루고 있으니 해당 락을 통해 여러 동시성 요청의 동기화를 통해 Lost Update를 막는 작업을 수행해보자.
Named Lock을 활용하여 동시에 100건 재고차감하는 상황을 살펴본다.
interface StockRepository : JpaRepository<Stock, Long> {
//... 다른 코드 생략
@Query(value = "select GET_LOCK(:key, :timeoutSeconds)", nativeQuery = true)
fun getNamedLock(key: String, timeoutSeconds: Int): Int?
@Query(value = "select RELEASE_LOCK(:key)", nativeQuery = true)
fun releaseNamedLock(key: String): Int?
}우선 Named Lock을 사용하기 위한 레포지토리 인터페이스 메서드를 정의 후
@Service
class StockService(
private val stockRepository: StockRepository,
) {
// ... 다른 코드 생략
@Transactional
fun decreaseStockWithNamedLockWrongTransaction(productId: Long, amount: Int) {
val lockKey = "stock:$productId"
val lockTimeOutTime = 10
try {
val lockResult = stockRepository.getNamedLock(lockKey, lockTimeOutTime) // 락 획득 성공하면 1 리턴
logger.info("GET_LOCK [$lockKey] result: $lockResult")
// 락 획득 실패 시 예외 발생
if (lockResult != 1) {
throw IllegalStateException("Failed to acquire lock: $lockKey")
}
// 비즈니스 로직
val stock = stockRepository.getStockByProductId(productId)
stock.decrease(amount)
stockRepository.save(stock)
} finally {
val releaseResult = stockRepository.releaseNamedLock(lockKey)
logger.info("RELEASE_LOCK [$lockKey] result: $releaseResult") // 락이 제대로 해제 됐으면 1 리턴
}
}
}해당 Named Lock을 획득하고 해제하는 로직을 추가한다.
이때, 주의해야할 점은 Named Lock은 트랜잭션이 커밋되었다고 해서 해제되는것이 아니기 때문에 별도로 finally block을 통해 획득한 락을 해제 하는 작업을 수행한다.
@Test
fun `잘못된 트랜잭션과 Named Lock을 통해 동시에 100건 재고 차감을 수행한다`() {
// given
val threadCount = 100
val executor = Executors.newFixedThreadPool(threadCount)
val latch = CountDownLatch(threadCount)
// when
repeat(threadCount) {
executor.submit {
try {
val headers = HttpHeaders().apply {
contentType = MediaType.APPLICATION_JSON
}
val request = HttpEntity(StockRequest(productId = PRODUCT_ID, amount = 1), headers)
testRestTemplate.postForEntity("/stock-with-named-lock", request, Void::class.java)
} catch (e: Exception) {
logger.error("Error during concurrent request", e)
} finally {
latch.countDown()
}
}
}
latch.await()
executor.shutdown()
// then
val stock = stockRepository.getStockByProductId(PRODUCT_ID)
logger.info("Final quantity: ${stock.quantity}, Expected: 0")
// Named Lock을 통해 락을 얻고 동시성 요청이 동기적으로 수행되므로 0이 됨
assertThat(stock.quantity).isEqualTo(0)
}위의 테스트에 방금 추가한 서비스 로직을 연동한 코드로 실행한다.
결과는?
실험 2 실행 결과 - Lost Update 발생
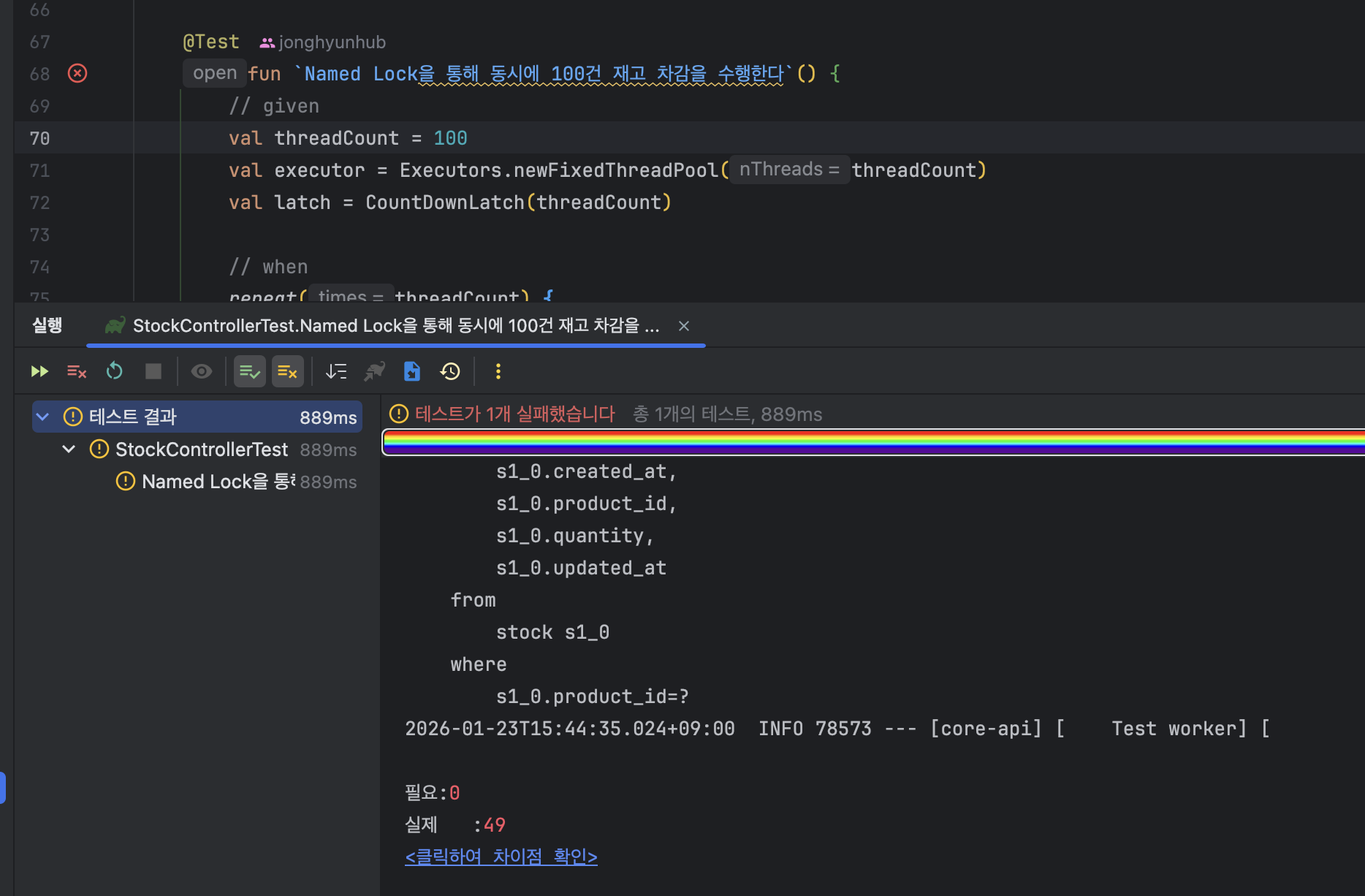

100개의 재고 차감 로직을 Named Lock을 통해 동기화 작업을 수행하였는데, 의도와는 달리 기대하는 0건이 아닌 49건으로 실험 1과 동일한 Lost Update 현상이 발생한 것으로 보인다.
왜 이런일이 발생한 것일까?
그 이유는 트랜잭션과 락의 순서 에 있다.
원인 : 락을 열고 닫는 범위 안에 차감 로직 트랜잭션이 있지 않다. => 락 해제 이후에 커밋이 실행
서비스 쪽의 코드를 다시 확인해보자.
@Transactional
fun decreaseStockWithNamedLockWrongTransaction(productId: Long, amount: Int) {
val lockKey = "stock:$productId"
val lockTimeOutTime = 10
try {
val lockResult = stockRepository.getNamedLock(lockKey, lockTimeOutTime) // 락 획득 성공하면 1 리턴
logger.info("GET_LOCK [$lockKey] result: $lockResult")
// 락 획득 실패 시 예외 발생
if (lockResult != 1) {
throw IllegalStateException("Failed to acquire lock: $lockKey")
}
// 비즈니스 로직
val stock = stockRepository.getStockByProductId(productId)
stock.decrease(amount)
stockRepository.save(stock)
} finally {
val releaseResult = stockRepository.releaseNamedLock(lockKey)
logger.info("RELEASE_LOCK [$lockKey] result: $releaseResult") // 락이 제대로 해제 됐으면 1 리턴
}
}해당 메서드 단위로 @Transactional 이 걸려있다.
이 말이 의미하는것은 해당 메서드가 시작/종료 생명주기와 동일하게 트랜잭션이 시작되고 종료된다는 의미이다.
그러면 무슨일이 일어나게 될까?
- 해당 메서드 실행시 Spring AOP 가 제어를 가로 챈 이후 Start Transcation 실행
- productId 기반 Named Lock 획득
- 재고 조회 및 차감 수행
- Named Lock 해제
- commit 후 트랜잭션 종료 <- 이 시점에 실제 차감 로직 반영
이 순서로 실행되게 된다. 그러면 무슨일이 일어나기에 Lost Update 가 일어날까? 아래의 그림을 보자.
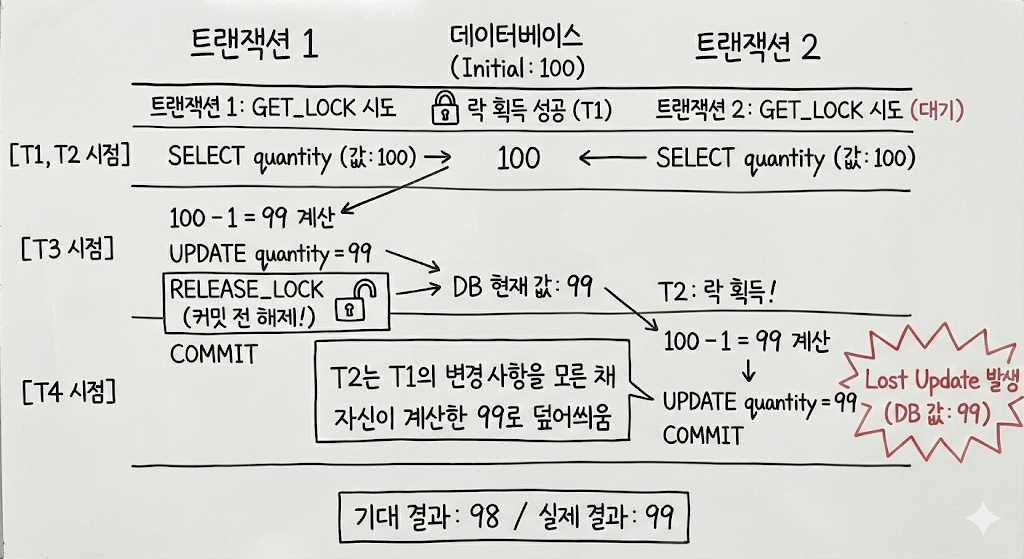
- 트랜잭션 1,2 가 동시에 요청을 시작
- 먼저 수행된 트랜잭션 1이 락을 먼저 획득
- 트랜잭션 1이 커밋 이전에 락을 해제
- 트랜잭션 2가 트랜잭션 1이 커밋되기 전에 락을 획득하고 작업을 수행
- 결과적으로 트랜잭션 1이 수행한 업데이트는 사라짐 (Lost Update) 발생
즉, Named Lock을 통해 트랜잭션을 완벽히 제어 하려면
락을 얻음 -> 트랜잭션 수행 -> 트랜잭션 종료 -> 락 해제
의 순서로 실행되어야 원래 의도하던대로 락을 통한 동시성 제어가 가능하다.
실험 3 : @Transactional 없이 Named Lock을 활용하여 동시에 100건 차감
그러면 자연스럽게, @Transactional 이 없이 메서드를 작성하여 수행하면 되겠지? 라는 생각이 들 수 있다. 하지만, 이런 방식도 특정 문제를 야기할 수 있다.
이 방식의 문제는 같은 커넥션이 재활용 되지 않을수도 있다 는 것인데, 해당 문제를 직접 확인해보기 위해 일부러 비즈니스 로직에 다음과 같은 지연이 발생한 상황을 가정하여 다음과 같은 코드를 준비한다.
interface StockRepository : JpaRepository<Stock, Long> {
//... 위와 동일, 락 획득 및 커넥션 정보 확인을 위한 메서드
@Query(
value = "SELECT GET_LOCK(:key, :timeout) as lock_result, CONNECTION_ID() as conn_id",
nativeQuery = true
)
fun getNamedLockWithConnectionId(
@Param("key") key: String,
@Param("timeout") timeout: Int
): LockResult
@Query(
value = "SELECT RELEASE_LOCK(:key) as release_result, CONNECTION_ID() as conn_id",
nativeQuery = true
)
fun releaseNamedLockWithConnectionId(@Param("key") key: String): LockResult
} fun decreaseStockWithNamedLockWithOutTransactional(productId: Long, amount: Int) {
val lockKey = "stock:$productId"
val lockTimeOutTime = 10
try {
val lockResult = stockRepository.getNamedLockWithConnectionId(lockKey, lockTimeOutTime)
logger.info("GET_LOCK - connId: ${lockResult.connId}, result: ${lockResult.lockResult}")
// 락 획득 실패 시 예외 발생
if (lockResult.lockResult != 1L) {
throw IllegalStateException("Failed to acquire lock: $lockKey")
}
// 비즈니스 로직
val stock = stockRepository.getStockByProductId(productId)
Thread.sleep(100) // 비즈니스 로직에서 지연 발생
stock.decrease(amount)
stockRepository.save(stock)
} finally {
val releaseResult = stockRepository.releaseNamedLockWithConnectionId(lockKey)
logger.info("RELEASE_LOCK - connId: ${releaseResult.connId}, result: ${releaseResult.lockResult}") // 락이 제대로 해제 됐으면 1 리턴
}
}위와 같이 코드를 작성하고 실험 2와 동일한 테스트를 실행한다.
어떻게 될까?
실험 3 실행 결과 - Lost Update + 데드락 발생


차감이 수행되다가 테스트가 멈추는 현상이 발생하였고, DB의 재고 데이터도 5건으로 남아있게 된다.
왜 이런 일이 발생한 것일까? 로그를 살펴보자.
2026-01-23T20:02:42.053+09:00 INFO 1499 --- [core-api][o-auto-1-exec-8] [6973555180588c70cbaa10545b9d6b15-cbaa10545b9d6b15] io.jonghyun.MySQL.lock.StockService : RELEASE_LOCK - connId: 1533, result: 0
2026-01-23T20:02:42.174+09:00 INFO 1499 --- [core-api][-auto-1-exec-10] [69735552909a39a2a3c590fc81c7c6ea-a3c590fc81c7c6ea] io.jonghyun.MySQL.lock.StockService : RELEASE_LOCK - connId: 1533, result: 0
다음의 두 쓰레드에서 같은 커넥션으로 락 해제에 실패한 것 을 확인해볼 수 있다.
그러면, 해당 쓰레드에서 어떤 일이 일어났기에 데드락이 발생하게 된 것일까?
해당 쓰레드들의 락 획득 로그를 다시 확인해보자.
2026-01-23T20:02:41.937+09:00 INFO 1499 --- [core-api][o-auto-1-exec-8] [6973555180588c70cbaa10545b9d6b15-cbaa10545b9d6b15] io.jonghyun.MySQL.lock.StockService : GET_LOCK - connId: 1531, result: 1
2026-01-23T20:02:42.057+09:00 INFO 1499 --- [core-api][-auto-1-exec-10] [69735552909a39a2a3c590fc81c7c6ea-a3c590fc81c7c6ea] io.jonghyun.MySQL.lock.StockService : GET_LOCK - connId: 1531, result: 1
해당 로그를 통해 어떤일이 일어났는지 그림으로 그리면 다음과 같다.
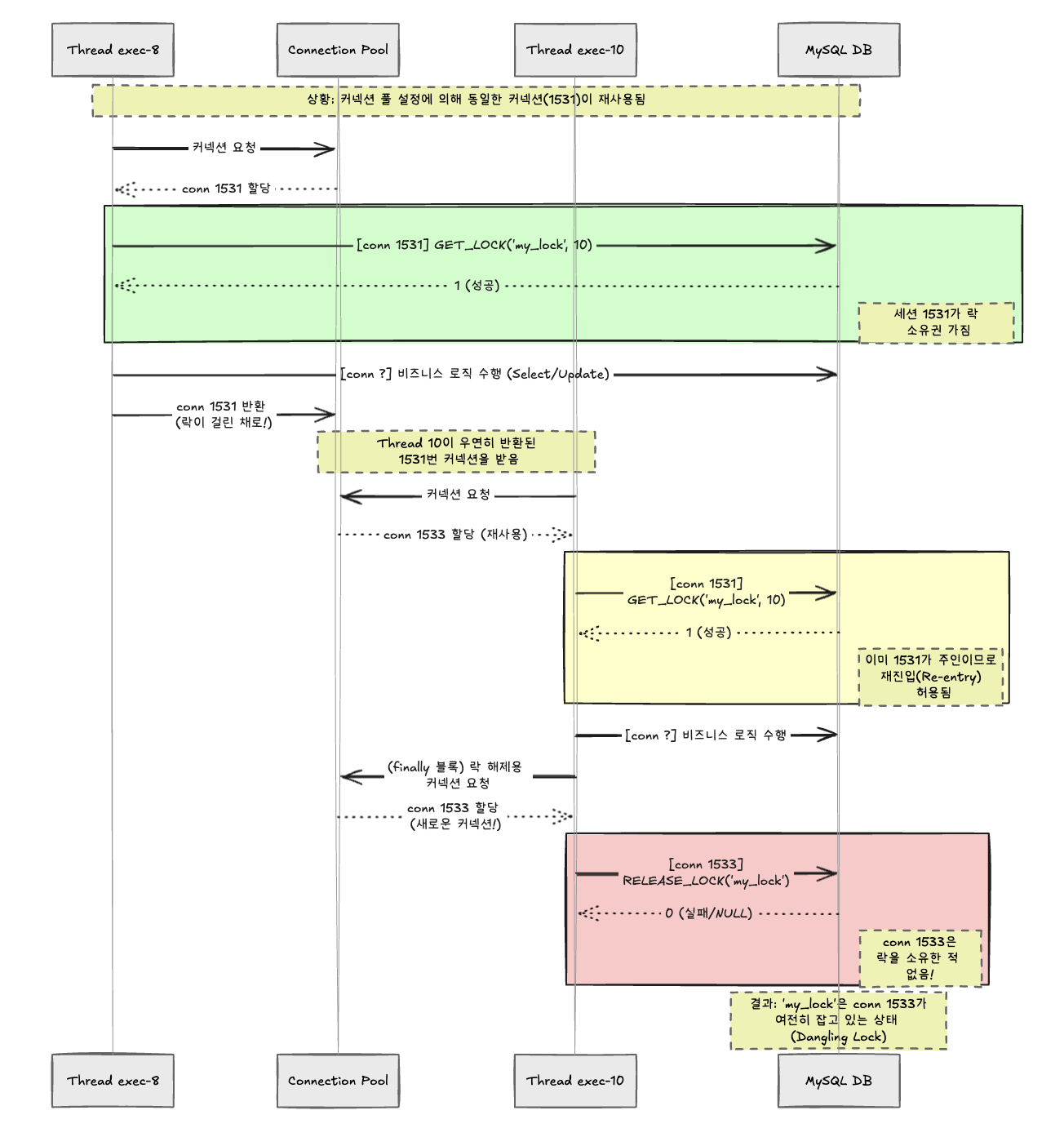
즉, 다음과 같은 일이 일어났고
1.Thread 8 이 connId = 1531이 커넥션을 얻음
2.connId = 1531을 Thread 8이 락 해제 이전에 Thread 10 이 얻고 비즈니스 로직 수행
3. Thread 8 이 connId = 1533 을 획득하고 락 해제 시도(connId = 1533은 락이 없음)
Lost Update문제와데드락문제 두가지의 문제를 야기할수 있는 상황이 된다.
해당 쓰레드들은 놀랍게도 GET_LOCK 과 RELEASE_LOCK의 커넥션 아이디가 다르다.
왜 이런일이 일어났을까?
원인 : 스프링에서 @Transactional이 없을 때 같은 커넥션을 사용하도록 보장하지 않는다.
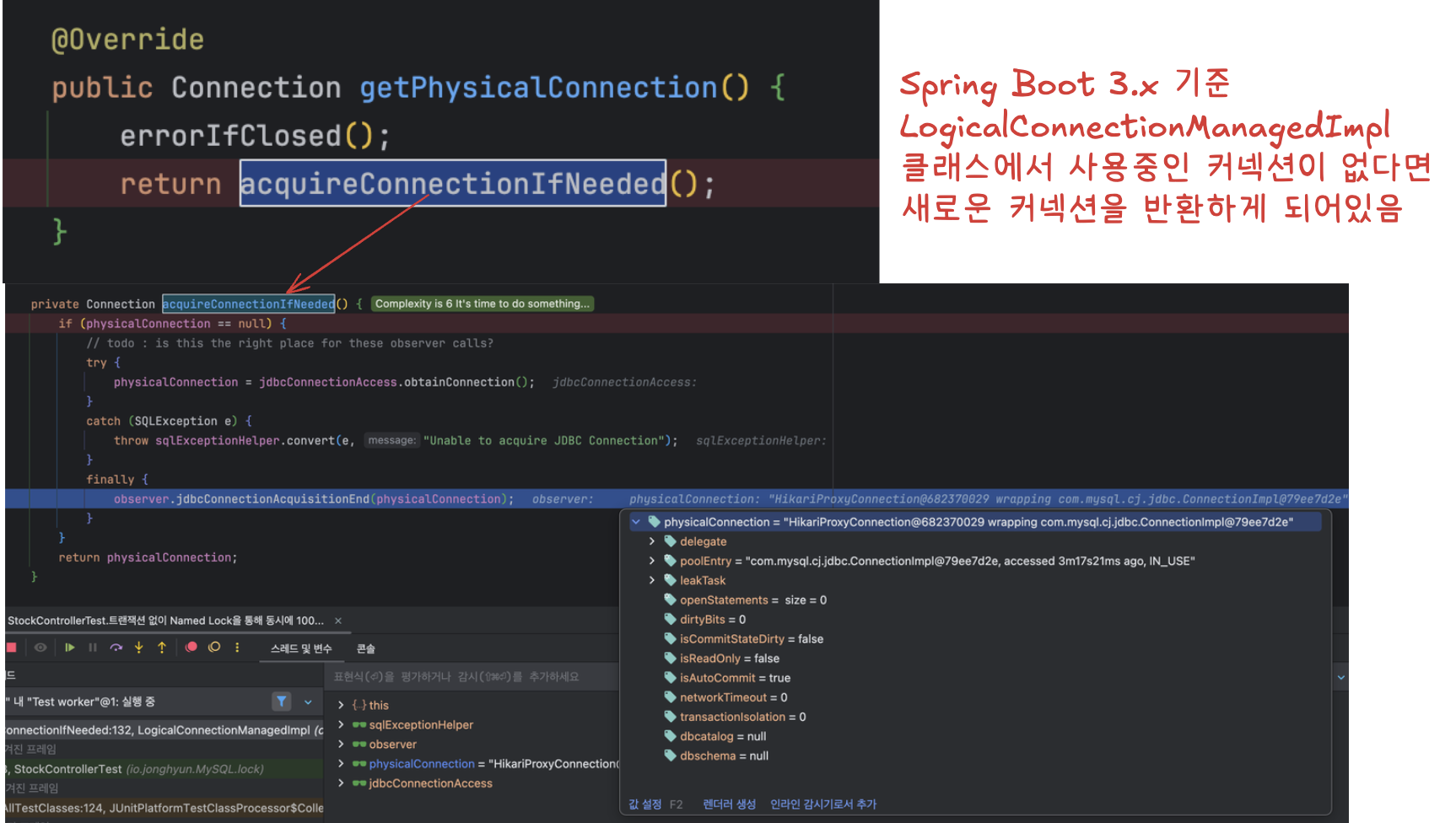
Spring Boot 3.x Hibernate 기준
LogicalConnectionManagedImpl.acquireConnectionIfNeeded() 메서드에서 실제 쿼리 호출시 커넥션을 처리하는 로직이 존재하는데,
쓰레드 로컬에 매핑된 커넥션이 없다면 호출시마다 새로운 커넥션을 가져오도록 동작한다.
즉, 이러한 일이 일어난 이유는
fun decreaseStockWithNamedLockWithOutTransactional(productId: Long, amount: Int) {
....
// 여기서 connId=1531 사용
val lockResult = stockRepository.getNamedLockWithConnectionId(lockKey, lockTimeOutTime)
...
// 비즈니스 로직
// 이 로직도 어떤 커넥션을 사용할지 모름 => connId = 1531, 1533을 보장하지 않음
val stock = stockRepository.getStockByProductId(productId)
Thread.sleep(100) // 비즈니스 로직에서 지연발생
stock.decrease(amount)
stockRepository.save(stock)
} finally {
// 여기서 connId=1533 사용
val releaseResult = stockRepository.releaseNamedLockWithConnectionId(lockKey)
}
}
@Transactional이 없는 경우 각 쿼리 메서드에서 사용하는 커넥션을 공유하도록 강제하지 않는다
는 것이 주요 시사점이다.
따라서 해당 문제를 해결하기 위해서는 트랜잭션으로 묶어 락의 획득과 해제를 같은 커넥션으로 묶는 작업이 필요하다.
그럼 어떻게 사용해야 하나?
위의 과정을 거치면 결국 두가지를 신경써서 사용해야 한다는 것이 된다.
- 비즈니스 로직의 트랜잭션이 완전히 커밋된 후 락이 해제되어야한다.
- 락 획득,해제는 같은 DB 커넥션(세션)에서 수행되어야한다.
쓰레드와 커넥션은 서로 다르게 관리되기 때문에 이 점에 유의해야겠다.
여기까지 왔으니 스프링 애플리케이션에서 Named Lock을 통해 올바르게 사용하는 방법에 대해 알아보자.
여러 레퍼런스를 찾아보니 결국 이러한 상황에서의 베스트 프렉티스는
비즈니스 로직의 커넥션과 락을 커넥션을 분리하고 락 커넥션을 명시적으로 관리한다.
인듯 싶다.
관련하여 레디스를 사용한 분산락을 사용하면 별도로 커넥션을 발라낼 필요가 없어서 편다는 내용이 많지만,
해당 내용은 이 아티클의 주제와 어긋나니 추후에 다뤄보도록 하자.
실험 4 : 비즈니스 로직과 락 커넥션을 분리하여 사용
@Component
class NamedLockExecutor(
private val dataSource: DataSource
) {
...
// @Transactional <- 이 메서드에 트랜잭셔널 추가하면 락 획득/해제 커넥션과 비즈니스 커넥션을 동일하게 고정시켜 버리니 주의!
fun <T> executeWithLock(lockKey: String, timeout: Int = 10, action: () -> T): T {
// 커넥션을 직접 획득해서 들고 있음
val connection = dataSource.connection
try {
// 같은 connection 객체로 락 획득
val acquired = acquireLock(connection, lockKey, timeout)
if (!acquired) {
throw IllegalStateException("Failed to acquire lock: $lockKey")
}
// 비즈니스 로직 실행 (별도 트랜잭션)
return action()
} finally {
// 같은 connection 객체로 락 해제 → 동일 커넥션 보장
releaseLock(connection, lockKey)
connection.close() // 풀에 반환
}
}
}@Service
class StockFacade(
private val namedLockExecutor: NamedLockExecutor,
private val stockService: StockService
) {
fun decreaseStock(productId: Long, amount: Int) {
val lockKey = "stock:$productId"
namedLockExecutor.executeWithLock(lockKey) {
// 이 블록은 별도 트랜잭션에서 실행됨
stockService.decreaseStockWithOutLock(productId, amount)
}
}
}해당 방식은 말 그대로
- 비즈니스 로직을 처리하기 위한 커넥션(세션)과
- Named Lock 을 획득하는 커넥션
을 분리하고, 1의 트랜잭션이 커밋된 이후 락을 해제하는 방식이다.
또한, NamedLockExecutor 에서는 @Transactional 을 별도로 사용하지 않았는데
그 이유로 해당 에너테이션을 사용하게 되면 내부적으로 커넥션을 매핑해버리기 때문에 해당 에너테이션을 사용하지 않았다.
NamedLockExecutor 에서는 @Transactional 을 사용하게 되면 실험 2와 동일하게 동작하게 된다.
스프링 트랜잭션이 락 획득 커넥션과 내부 메서드 커넥션을 고정시켜버려서, 락 획득 시점보다 트랜잭션 커밋 시점이 늦어지게 되니 이것에 주의하자.)
MySQL을 이용한 분산락으로 여러 서버에 걸친 동시성 관리 해당 블로그에도 이러한 방식을 통해 해결 방법을 제시하였으며, 직접 테스트 해본 결과 해당 방식이 가장 구현하기 간단하고 용이한 듯 싶다.
물론, 해당 글에서는 AOP로 처리하는 작업도 수행하였으나 AOP가 핵심이라기 보다는
비즈니스 로직의 트랜잭션의 앞뒤로 락 획득 로직을 두고 비즈니스 트랜잭션의 커넥션과 락 획득 커넥션을 분리
하는게 핵심이기 때문에 추가하지 않았다.
(어차피 AOP 자체가 스프링이 마법같이 가로채서 별도의 로직을 수행해주는 것이기 때문이기도 하니)
실험 4 실행 결과
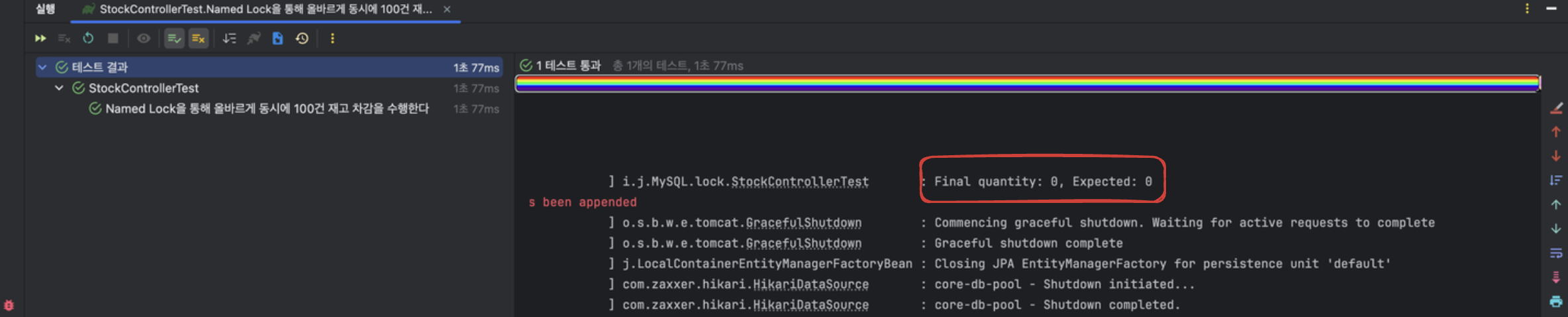
드디어 의도한 대로 동시에 100건 차감 로직 호출시에 정합성을 보장하는데 성공했다.
실험 4 부록 - Hikari-cp 커넥션 설정 주의
동일한 코드로 실행해도 특정 설정에 따라 테스트가 실패할 수 있는데, 바로 Hikari-cp 의 커넥션의 수를 적게 설정하면 커넥션 획득에 실패하여 JDBC 커넥션 타임아웃이 발생할 수 있다는 점이다.

maximum-pool-size: 5 과 같이 너무 적은 풀 사이즈로 실행하면

사진과 같이 중간에 커넥션 획득 타임아웃 JDBCConnectionException 이 발생한다.
Caused by: org.hibernate.exception.JDBCConnectionException: Unable to acquire JDBC Connection [core-db-pool - Connection is not available, request timed out after 1105ms (total=5, active=5, idle=0, waiting=0)] [n/a]
레슨런
Named Lock 을 직접 실험해보면서 사용해본적은 처음인데 역시 여러가지로 실험해보고 먹어보는것과 대충 ai가 이렇게 하세요 라는것을 보는것과는 매우 다른것을 배웠습니다.
특히나, Thread, Connection이 서로 다르게 관리되어서 꼬일수도 있다. 는 것을 배운게 가장 큰 레슨런인 것 같습니다.
레퍼런스
MySQL Named Lock 공식 문서
MySQL을 이용한 분산락으로 여러 서버에 걸친 동시성 관리
MySQL 네임드락 알고 쓰자
