pandas 출력 설정
pd.set_option("display.max_rows", None) # 모든 행 보이기
pd.set_option("display.max_columns", None) # 모든 열 보이기None 위치에 정수를 넣으면 정수 만큼의 행/열을 출력. default : 10
csv, tsv 데이터 불러오기
df = pd.read_csv("data.csv")
df = pd.read_csv("data.txt", sep="\t")
df = pd.read_csv("data.csv", header = None) # 헤더가 없을 경우큰 규모의 데이터
df = pd.read_csv("big_data.csv",
usecols = [0, 1, 2, 3], # column 명으로도 불러올 수 있음
index_col = "ID", # usecols 를 사용하는 경우 반드시 포함
nrows = 1000)csv 파일 저장
df.to_csv("index_false.csv", sep=",", index=False) # 인덱스 제외
df.to_csv("index_true.csv", sep=",", index=True)excel 데이터 불러오기
pd.read_excel(filepath, sheet_name, header, index_col, usecols, nrows, skiprows=range(6)) # 1~6행 제외- sheet_name : 지정하지 않으면 첫번째 시트를 기본으로 불러온다.
- skiprows : 불러오지 않을 행을 지정할 수 있다.
excel 저장
df.to_excel(filepath, index, sheet_name, mode)여러 시트를 생성해야 하는 경우 - ExcelWriter
with pd.ExcelWriter("xlsx_file.xlsx") as writer:
df1.to_excel(writer, sheet_name="sheet1")
df2.to_excel(writer, sheet_name="sheet2")loc
명시적 인덱스 참조. 마지막 값 포함
딕셔너리처럼 key를 이용하여 value를 찾는 것과 같음
iloc
암묵적 인덱스 참조. 마지막 값 미포함
Series 정렬
S.sort_values(ascending=True, key=None, na_position="first") # na_position={"first","last"}Series 요약 함수
S.value_counts() # 데이터의 빈도를 파악
S.unique() # 범주형 변수와 연속형 변수를 판단하는데 사용Series.str
str accessor로 string 관련 내장 함수를 자유롭게 이용 가능
- S.str.strip()
- S.str.contaions(s)
- S.str.split(sep, expand=True)
+ expand={True:새로운 열 생성, False:새로운 열 생성하지 않고 df 반환}
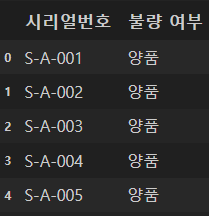
df['시리얼번호'].str.split('-', expand = True).head() # 하이픈 기준 분할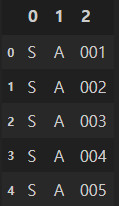
Series.astype
- 시리즈 타입 변경
S.astype(str)DataFrame 정렬
df.sort_values(by = columns, ascending = True, key=None, na_position='first', inplace=False)DataFrame 중복 제거
df.drop_duplicates(subset = columns, keep="first") - subset : 중복을 판단할 기준 컬럼 (목록)
- keep : {"first", "last", "false"} : 중복이 있는 행의 어느 부분을 남길 것인지 설정
- first : 첫 번째 행을 남김
- last : 마지막 행을 남김
- false : 중복 행을 모두 제거

메모하는 습관