pandas.merge
- key를 기준으로 두 개의 데이터 프레임을 병합(join)하는 함수
left : 통합 대상 데이터프레임1
right : 통합 대상 데이터프레임2
on : 통합 기준 key 변수 및 변수 리스트 (명시하지 않을 경우 이름이 같은 변수를 key로 식별)
left_on: 데이터프레임1의 key변수 및 변수 리스트
right_on: 데이터프레임2의 key변수 및 변수 리스트
left_index: 데이터 프레임1의 인덱스를 key 변수로 사용할 지 여부
right_index: 데이터 프레임2의 인덱스를 key 변수로 사용할 지 여부
pandas.merge: on
- 병합하려는 데이터프레임이 공통된 이름의 열을 가지고 있을 경우
df1.head()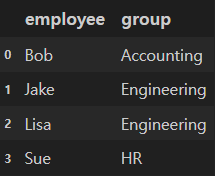
df2.head()
merged_df = pd.merge(df1, df2, on = "employee")
# merged_df = pd.merge(df1, df2, on = ["employee"])
merged_df.head()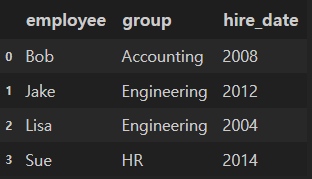
on을 이용하여 key를 지정하지 않아도 동일한 "employee" column을 key로 인식하여 병합됨
pandas.merge: left_on, right_on
- 병합기준 열이 서로 다른 이름을 가지고 있을 경우
df1.head()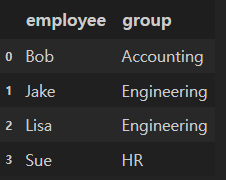
df2.head()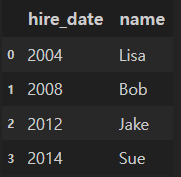
df1의 "employee" df2의 "name"을 key로 병합
merged_df = pd.merge(df1, df2, left_on="employee", right_on ="name")
merged_df.drop("name", axis=1, inplace=True) # 두개의 열 중 하나 제거
merged_df.head()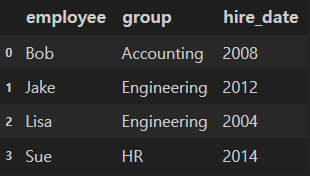
pandas.merge: right_index
- 열 인덱스를 기준으로 병합가능
df2.head()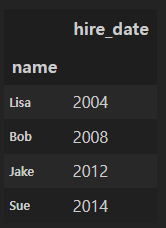
merged_df = pd.merge(df1, df2, left_on = "employee", right_index = True)
merged_df.head()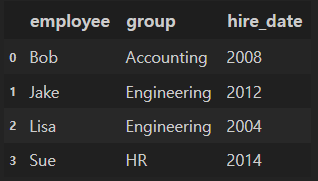
pandas.concat
- 여러 데이터프레임을 하나의 데이터프레임으로 합칠 때 사용
axis=0: 행단위 위-아래로 합쳐짐(default)
axis=1: 열단위 왼쪽-오른쪽으로 합쳐짐
df1 = pd.DataFrame({"A":[1,2,3,4], "B":[1,2,3,4]})
df2 = pd.DataFrame({"A":[5,6,7,8], "B":[5,6,7,8]})
merged_df = pd.concat([df1, df2], axis = 0, ignore_index = True)
merged_df
df1 = pd.DataFrame({"A":[1,2,3,4], "B":[5,6,7,8]})
df2 = pd.DataFrame({"C":[1,2,3,4], "D":[5,6,7,8]})
merged_df = pd.concat([df1, df2], axis = 1, ignore_index = False)
merged_df
여러 파일을 하나의 데이터프레임으로 불러오기
- for 문을 이용한 방법: 코드가 길고 상대적으로 비효율적. 메모리 문제가 생길 가능성 적음
- list comprehension을 이용한 방법: 코드가 짧고 효율적이나 메모리 문제가 발생할 가능성 높음
-
경로 내 여러 파일을 불러올 경우 : os.listdir(path)
--> os.listdir(path)로 path상의 모든 파일을 리스트로 불러 온 뒤 concat을 이용하여 병합 -
하나의 엑셀 파일에 여러 sheet가 있는 경우: xlrd 모듈 이용
import xlrd
wb = xlrd.openworkbook(file, on_demand=True)
sheetnames = wb.sheet_names()-> wb.sheet_names() : 파일 내 sheet names를 리스트로 반환
pandas.pivot_table
- pivot tabel : 조건에 따른 변수들의 통계량을 요약한 테이블
pandas.pivot_table(data, index, columns, values, aggfunc)data : dataframe
index : 행에 들어갈 조건
columns : 열에 들어갈 조건
vlaues : 집계 대상 컬럼 목록
aggfunc : 집계 함수
df.head()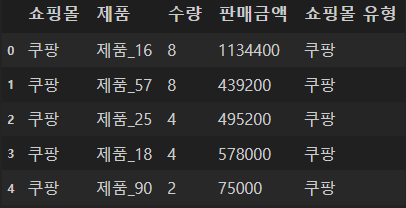
pt1 = pd.pivot_table(df, index="제품", columns="쇼핑몰 유형", values="판매금액", aggfunc="mean")- 제품(index)과 쇼핑몰 유형(columns)에 따른 판매금액(values)의 평균(aggfunc)을 보여주는 pivot table 생성
pt1.head()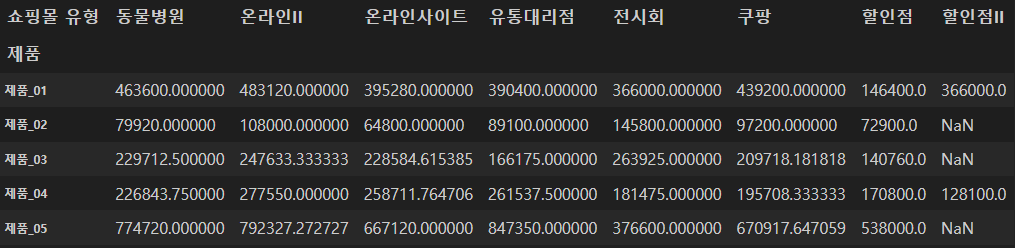
pt2 = pd.pivot_table(df, index = ['제품'], columns = ['쇼핑몰 유형'], values = ['판매금액', '수량'], aggfunc = 'max')
pt2.head()
DataFrame.groupby
- DataFrame을 분할 기준 컬럼을 기준으로 나누는 함수
- pivot이랑 동일한 기능이지만 출력 구조의 차이가 있으므로 상황에 맞게 선택하여 사용
df.groupby(분할기준컬럼)[적용기준컬럼].집계함수by : 분할 기준 컬럼(목록)
as_index : 분할 기준 컬럼들을 인덱스로 사용할 지 여부
df.groupby(['쇼핑몰 유형'])['수량'].mean()--> 쇼핑몰 유형에 따른 수량의 평균
df.groupby(['쇼핑몰 유형'])['수량', '판매금액'].agg(['mean', 'max'])--> 2개 이상의 함수를 사용하려면 .agg() 사용
패스트캠퍼스 - 데이터전처리 ch4 일부 요약
